Dans l'article, je vais vous expliquer comment nous avons abordé le problème de tolérance aux pannes de PostgreSQL, pourquoi cela est devenu important pour nous et ce qui s'est finalement produit.
Nous avons un service très chargé: 2,5 millions d'utilisateurs dans le monde, plus de 50 000 utilisateurs actifs chaque jour. Les serveurs sont situés à Amazone dans une région de l'Irlande: il y a constamment plus de 100 serveurs différents en fonctionnement, dont près de 50 avec des bases de données.
L'ensemble du backend est une grande application Java monolithique avec état qui maintient une connexion websocket constante au client. Grâce au travail simultané de plusieurs utilisateurs sur une même carte, ils voient tous les changements en temps réel, car nous enregistrons chaque changement dans la base de données. Nous avons environ 10 000 requêtes par seconde dans nos bases de données. Au pic de charge dans Redis, nous écrivons à 80-100K requêtes par seconde.

Pourquoi nous sommes passés de Redis à PostgreSQL
Au départ, notre service fonctionnait avec Redis, un référentiel de valeurs-clés qui stocke toutes les données dans la RAM du serveur.
Avantages de Redis:
- Taux de réponse élevé, comme tout est stocké en mémoire;
- Commodité de sauvegarde et de réplication.
Contre Redis pour nous:
- Il n'y a pas de transactions réelles. Nous avons essayé de les simuler au niveau de notre application. Malheureusement, cela n'a pas toujours bien fonctionné et a nécessité l'écriture de code très complexe.
- La quantité de données est limitée par la quantité de mémoire. À mesure que la quantité de données augmente, la mémoire augmentera et, à la fin, nous rencontrerons les caractéristiques de l'instance sélectionnée, ce qui dans AWS nécessite l'arrêt de notre service pour changer le type d'instance.
- Il est nécessaire de maintenir constamment un faible niveau de latence, Nous avons un très grand nombre de demandes. Le niveau de retard optimal pour nous est de 17-20 ms. Au niveau de 30 à 40 ms, nous obtenons de longues réponses aux demandes de notre application et à la dégradation du service. Malheureusement, cela s'est produit avec nous en septembre 2018, lorsque l'une des instances de Redis pour une raison quelconque a reçu une latence 2 fois plus élevée que d'habitude. Pour résoudre le problème, nous avons arrêté le service en milieu de journée pour une maintenance imprévue et remplacé l'instance Redis problématique.
- Il est facile d'obtenir une incohérence des données même avec des erreurs mineures dans le code, puis de passer beaucoup de temps à écrire du code pour corriger ces données.
Nous avons pris en compte les inconvénients et réalisé que nous devons passer à quelque chose de plus pratique, avec des transactions normales et moins de dépendance à la latence. A mené une étude, analysé de nombreuses options et choisi PostgreSQL.
Nous évoluons vers une nouvelle base de données depuis 1,5 ans et n'avons transféré qu'une petite partie des données, nous travaillons donc simultanément avec Redis et PostgreSQL. Plus d'informations sur les étapes de déplacement et de commutation des données entre les bases de données sont écrites dans un
article de mon collègue .
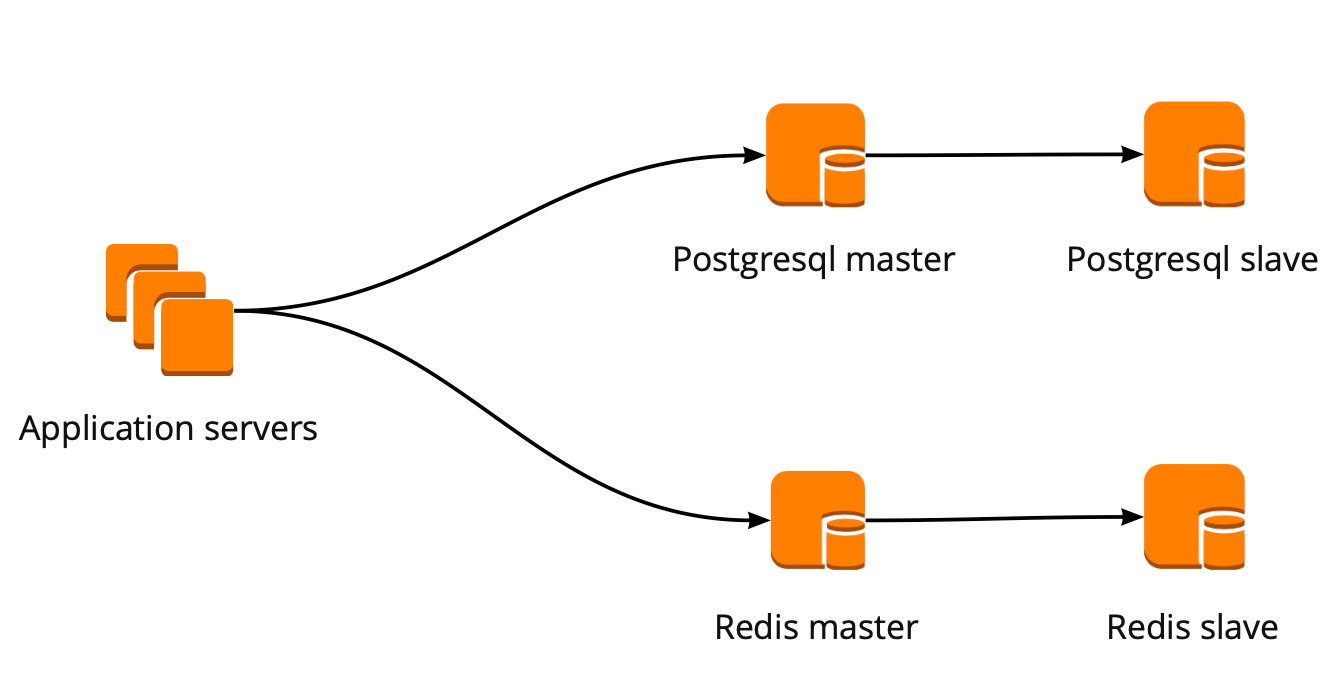
Lorsque nous avons commencé à déménager, notre application a travaillé directement avec la base de données et s'est tournée vers l'assistant Redis et PostgreSQL. Le cluster PostgreSQL était composé d'un maître et d'une réplique de réplique asynchrone. Voici à quoi ressemblait le schéma de fonctionnement de la base de données:
Déploiement de PgBouncer
Pendant que nous déménagions, le produit a également évolué: le nombre d'utilisateurs et le nombre de serveurs fonctionnant avec PostgreSQL ont augmenté et nous avons commencé à manquer des connexions. PostgreSQL crée un processus distinct pour chaque connexion et consomme des ressources. Vous pouvez augmenter le nombre de connexions jusqu'à un certain point, sinon il y a une chance d'obtenir un fonctionnement de base de données non optimal. L'option idéale dans cette situation serait le choix d'un gestionnaire de connexion qui se tiendra devant la base.
Nous avions deux options pour le gestionnaire de connexions: Pgpool et PgBouncer. Mais le premier ne prend pas en charge le mode transactionnel de travail avec la base de données, nous avons donc choisi PgBouncer.
Nous avons mis en place le schéma de fonctionnement suivant: notre application accède à un PgBouncer, suivi de Masters PostgreSQL, et derrière chaque maître, une réplique avec réplication asynchrone.

Dans le même temps, nous ne pouvions pas stocker la totalité des données dans PostgreSQL, et la vitesse de travail avec la base de données était importante pour nous, nous avons donc commencé à partager PostgreSQL au niveau de l'application. Le schéma décrit ci-dessus est relativement pratique pour cela: lors de l'ajout d'un nouveau fragment PostgreSQL, il suffit de mettre à jour la configuration de PgBouncer et l'application peut immédiatement fonctionner avec le nouveau fragment.
PgBouncer Fault Tolerance
Ce schéma a fonctionné jusqu'à la mort de la seule instance de PgBouncer. Nous sommes situés dans AWS, où toutes les instances s'exécutent sur du matériel qui s'éteint périodiquement. Dans de tels cas, l'instance se déplace simplement vers le nouveau matériel et fonctionne à nouveau. Cela s'est produit avec PgBouncer, mais il est devenu indisponible. Le résultat de cet automne a été l'inaccessibilité de notre service pendant 25 minutes. AWS recommande d'utiliser la redondance côté utilisateur pour de telles situations, qui n'était pas implémentée avec nous à l'époque.
Après cela, nous avons sérieusement réfléchi à la tolérance aux pannes des clusters PgBouncer et PostgreSQL, car une situation similaire pourrait se reproduire avec n'importe quelle instance de notre compte AWS.
Nous avons construit le schéma de tolérance aux pannes PgBouncer comme suit: tous les serveurs d'applications accèdent au Network Load Balancer, derrière lequel se trouvent deux PgBouncer. Chacun des PgBouncer regarde le même PostgreSQL maître de chaque fragment. Si l'instance AWS se bloque à nouveau, tout le trafic est redirigé via un autre PgBouncer. Tolérance aux pannes Network Load Balancer fournit AWS.
Ce schéma vous permet d'ajouter facilement de nouveaux serveurs PgBouncer.

Création d'un cluster de basculement PostgreSQL
Pour résoudre ce problème, nous avons envisagé différentes options: basculement auto-écrit, repmgr, AWS RDS, Patroni.
Scripts auto-écrits
Ils peuvent surveiller le travail du maître et, en cas de chute, promouvoir la réplique auprès du maître et mettre à jour la configuration de PgBouncer.
Les avantages de cette approche sont une simplicité maximale, car vous écrivez vous-même des scripts et comprenez exactement comment ils fonctionnent.
Inconvénients:
- Le maître peut ne pas mourir; au lieu de cela, une défaillance du réseau peut se produire. Le basculement, sans le savoir, fera avancer la réplique vers le maître, et l'ancien maître continuera de fonctionner. En conséquence, nous obtenons deux serveurs dans le rôle de maître et nous ne savons pas lequel d'entre eux possède les dernières données réelles. Cette situation est également appelée split-brain;
- Nous nous sommes retrouvés sans réplique. Dans notre configuration, le maître et une réplique, après avoir changé de réplique, il se déplace vers le maître et nous n'avons plus de répliques, nous devons donc ajouter manuellement une nouvelle réplique;
- Nous avons besoin d'une surveillance supplémentaire du fonctionnement du basculement, alors que nous avons 12 fragments PostgreSQL, ce qui signifie que nous devons surveiller 12 clusters. Si vous augmentez le nombre de fragments, vous devez toujours vous rappeler de mettre à jour le basculement.
Le basculement auto-écrit semble très compliqué et nécessite un support non trivial. Avec un seul cluster PostgreSQL, ce sera l'option la plus simple, mais elle n'est pas évolutive, donc elle ne nous convient pas.
Repmgr
Replication Manager pour les clusters PostgreSQL, qui peut gérer le fonctionnement d'un cluster PostgreSQL. Dans le même temps, il n'y a pas de basculement automatique «prêt à l'emploi», donc pour le travail, vous devrez écrire votre propre «wrapper» au-dessus de la solution finie. Tout peut donc s'avérer encore plus compliqué qu'avec des scripts auto-écrits, nous n'avons donc même pas essayé Repmgr.
AWS RDS
Il prend en charge tout ce dont vous avez besoin pour nous, sait comment sauvegarder et prend en charge un pool de connexions. Il a une commutation automatique: à la mort du maître, la réplique devient le nouveau maître et AWS change l'enregistrement DNS en nouveau maître, tandis que les répliques peuvent être dans différents AZ.
Les inconvénients incluent le manque de paramètres subtils. À titre d'exemple de réglage fin: sur nos instances, il existe des restrictions pour les connexions TCP, ce qui, malheureusement, ne peut pas être effectué dans RDS:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
De plus, le prix AWS RDS est presque deux fois plus élevé que le prix d'instance normal, ce qui était la principale raison du rejet de cette décision.
Patroni
Il s'agit d'un modèle python pour la gestion de PostgreSQL avec une bonne documentation, un basculement automatique et un code source github.
Avantages de Patroni:
- Chaque paramètre de configuration est peint, son fonctionnement est clair;
- Le basculement automatique fonctionne dès la sortie de la boîte;
- Il est écrit en python, et puisque nous écrivons beaucoup en python nous-mêmes, il nous sera plus facile de gérer les problèmes et, éventuellement, même d'aider au développement du projet;
- Il contrôle entièrement PostgreSQL, vous permet de modifier la configuration sur tous les nœuds du cluster à la fois, et si un redémarrage du cluster est nécessaire pour appliquer la nouvelle configuration, cela peut être fait à nouveau à l'aide de Patroni.
Inconvénients:
- D'après la documentation, il n'est pas clair comment travailler avec PgBouncer. Bien qu'il soit difficile de l'appeler un inconvénient, car la tâche de Patroni est de gérer PostgreSQL, et la façon dont les connexions à Patroni se passeront est notre problème;
- Il existe peu d'exemples d'implémentation de Patroni sur de gros volumes, tandis que de nombreux exemples d'implémentation à partir de zéro.
Par conséquent, pour créer un cluster de basculement, nous avons choisi Patroni.
Processus de mise en œuvre des patrons
Avant Patroni, nous avions 12 fragments PostgreSQL en configuration, un maître et une réplique avec réplication asynchrone. Les serveurs d'applications ont accédé aux bases de données via le Network Load Balancer, derrière lequel il y avait deux instances avec PgBouncer, et derrière eux se trouvaient tous les serveurs PostgreSQL.
Pour implémenter Patroni, nous devions sélectionner un référentiel de configuration de cluster distribué. Patroni fonctionne avec des systèmes de stockage de configuration distribuée tels que etcd, Zookeeper, Consul. Nous avons juste un cluster Consul à part entière sur prod qui fonctionne en conjonction avec Vault et nous ne l'utilisons plus. Une excellente raison de commencer à utiliser Consul conformément à sa destination.
Comment Patroni travaille avec le consul
Nous avons un cluster Consul, qui se compose de trois nœuds, et un cluster Patroni, qui se compose d'un chef de file et d'une réplique (dans Patroni, un maître est appelé chef de cluster et les esclaves sont appelés répliques). Chaque instance d'un cluster Patroni envoie constamment des informations sur l'état du cluster au Consul. Par conséquent, auprès de Consul, vous pouvez toujours connaître la configuration actuelle du cluster Patroni et qui est le leader en ce moment.

Pour connecter Patroni à Consul, il suffit d'étudier la documentation officielle, qui dit que vous devez spécifier l'hôte au format http ou https, selon la façon dont nous travaillons avec Consul, et le schéma de connexion, facultatif:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
Cela semble simple, mais ici les écueils commencent. Avec Consul, nous travaillons sur une connexion sécurisée via https et notre configuration de connexion ressemblera à ceci:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Mais ça ne marche pas. Au début, Patroni ne peut pas se connecter à Consul, car il essaie quand même de suivre http.
Le code source de Patroni a aidé à résoudre le problème. Heureusement qu'il est écrit en python. Il s'avère que le paramètre hôte n'est pas analysé du tout et que le protocole doit être spécifié dans le schéma. Voici le bloc de configuration de travail pour travailler avec Consul avec nous:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Modèle de consul
Nous avons donc choisi le stockage pour une configuration. Vous devez maintenant comprendre comment PgBouncer changera de configuration lors du changement de leader dans le cluster Patroni. La documentation ne répond pas à cette question, car là, en principe, le travail avec PgBouncer n'est pas décrit.
À la recherche d'une solution, nous avons trouvé un article (je ne me souviens pas du nom, malheureusement), où il était écrit que le modèle Consul avait beaucoup aidé à connecter PgBouncer et Patroni. Cela nous a incités à étudier le travail du modèle de consul.
Il s'est avéré que le modèle Consul surveille en permanence la configuration du cluster PostgreSQL dans Consul. Lorsque le leader change, il met à jour la configuration de PgBouncer et envoie une commande pour le redémarrer.
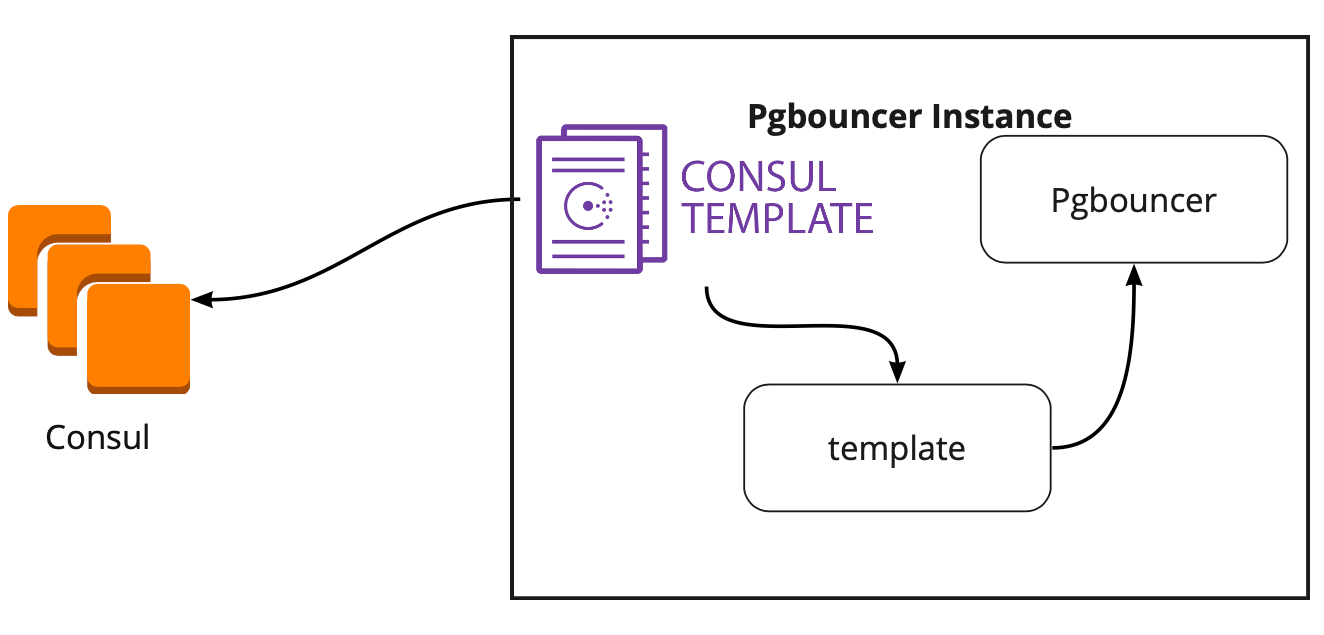
Le gros avantage du modèle est qu'il est stocké sous forme de code, donc lors de l'ajout d'un nouveau fragment, il suffit de faire un nouveau commit et de mettre à jour le modèle en mode automatique, prenant en charge le principe de l'infrastructure en tant que code.
Nouvelle architecture avec Patroni
En conséquence, nous avons obtenu ce schéma de travail:

Tous les serveurs d'applications accèdent à l'équilibreur → deux instances de PgBouncer sont derrière lui → sur chaque instance, un modèle onsul est lancé, qui surveille l'état de chaque cluster Patroni et surveille la pertinence de la configuration PgBouncer, qui envoie des demandes au leader actuel de chaque cluster.
Test manuel
Avant de lancer le programme, nous avons lancé ce circuit sur un petit environnement de test et vérifié le fonctionnement de la commutation automatique. Ils ont ouvert le tableau, déplacé l'autocollant et à ce moment "tué" le chef du cluster. Dans AWS, désactivez simplement l'instance via la console.

L'autocollant est revenu en 10 à 20 secondes, puis a recommencé à se déplacer normalement. Cela signifie que le cluster Patroni a fonctionné correctement: il a changé de leader, envoyé les informations au consul, et le modèle de consul a immédiatement récupéré ces informations, remplacé la configuration de PgBouncer et envoyé la commande à recharger.
Comment survivre sous une charge élevée et maintenir un temps d'arrêt minimum?
Tout fonctionne très bien! Mais de nouvelles questions se posent: comment fonctionnera-t-il sous une charge élevée? Comment tout mettre en production rapidement et en toute sécurité?
L'environnement de test dans lequel nous effectuons les tests de charge nous aide à répondre à la première question. Il est complètement identique à la production en architecture et a généré des données de test, qui sont approximativement égales en volume à la production. Nous décidons de simplement «tuer» l'un des assistants PostgreSQL pendant le test et de voir ce qui se passe. Mais avant cela, il est important de vérifier le roulement automatique, car dans cet environnement, nous avons plusieurs fragments PostgreSQL, nous obtiendrons donc d'excellents tests de scripts de configuration avant de vendre.
Les deux tâches semblent ambitieuses, mais nous avons PostgreSQL 9.6. Peut-être que nous passerons immédiatement à 11.2?
Nous décidons de le faire en 2 étapes: première mise à niveau vers 11.2, puis lancement de Patroni.
Mise à jour PostgreSQL
Pour mettre à niveau rapidement la version de PostgreSQL, vous devez utiliser l'option
-k , qui crée un lien dur sur le disque et il n'est pas nécessaire de copier vos données. Sur des bases de 300 à 400 Go, la mise à jour prend 1 seconde.
Nous avons beaucoup d'éclats, donc la mise à jour doit être effectuée automatiquement. Pour ce faire, nous avons écrit le playbook Ansible, qui effectue le processus de mise à jour complet pour nous:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
Il est important de noter ici qu'avant de démarrer la mise à niveau, il est nécessaire de l'exécuter avec le paramètre
--check pour être sûr de la possibilité d'une mise à niveau. Notre script effectue également la substitution des configurations pour la mise à niveau. Le script que nous avons terminé en 30 secondes, c'est un excellent résultat.
Lancer Patroni
Pour résoudre le deuxième problème, il suffit de regarder la configuration de Patroni. Dans le référentiel officiel, il existe un exemple de configuration avec initdb, qui est responsable de l'initialisation d'une nouvelle base de données lors du premier lancement de Patroni. Mais comme nous avons une base de données prête à l'emploi, nous venons de supprimer cette section de la configuration.
Lorsque nous avons commencé à installer Patroni sur un cluster PostgreSQL prêt à l'emploi et à l'exécuter, nous avons été confrontés à un nouveau problème: les deux serveurs ont commencé en tant que leader. Patroni ne sait rien de l'état initial du cluster et essaie de démarrer les deux serveurs en tant que deux clusters distincts portant le même nom. Pour résoudre ce problème, supprimez le répertoire de données sur l'esclave:
rm -rf /var/lib/postgresql/
Cela doit être fait uniquement sur l'esclave!Lors de la connexion d'une réplique propre, Patroni crée un leader de sauvegarde de base et le restaure sur la réplique, puis rattrape l'état actuel par wal-logs.
Une autre difficulté que nous avons rencontrée est que tous les clusters PostgreSQL sont appelés main par défaut. Lorsque chaque cluster ne sait rien de l'autre, c'est normal. Mais lorsque vous souhaitez utiliser Patroni, tous les clusters doivent avoir un nom unique. La solution consiste à changer le nom du cluster dans la configuration PostgreSQL.
Test de charge
Nous avons lancé un test qui simule le travail des utilisateurs sur les cartes. Lorsque la charge a atteint notre valeur quotidienne moyenne, nous avons répété exactement le même test, nous avons désactivé une instance avec le leader PostgreSQL. Le basculement automatique a fonctionné comme prévu: Patroni a changé de leader, Consul-template a mis à jour la configuration de PgBouncer et envoyé la commande à recharger. Selon nos graphiques de Grafana, il était clair qu'il y avait des retards de 20 à 30 secondes et une petite quantité d'erreurs des serveurs liées à la connexion à la base de données. Il s'agit d'une situation normale, de telles valeurs sont valables pour notre basculement et certainement meilleures que le temps d'arrêt du service.
Production de Patroni à la production
En conséquence, nous avons obtenu le plan suivant:
- Déployer Consul-template sur le serveur PgBouncer et lancer;
- Mises à jour de PostgreSQL vers la version 11.2;
- Changement de nom de cluster;
- Démarrage d'un cluster Patroni.
Dans le même temps, notre schéma vous permet de créer le premier élément à presque n'importe quel moment, nous pouvons à tour de rôle retirer chaque PgBouncer du travail et effectuer un déploiement et un modèle de consul dessus. Nous l'avons donc fait.
Pour un roulement rapide, nous avons utilisé Ansible, car nous avons déjà vérifié tout le playbook dans un environnement de test, et le temps d'exécution du script complet était de 1,5 à 2 minutes pour chaque fragment. Nous pourrions tout dérouler alternativement pour chaque fragment sans arrêter notre service, mais nous devrons désactiver chaque PostgreSQL pendant quelques minutes. Dans ce cas, les utilisateurs dont les données se trouvent sur ce fragment ne pouvaient pas fonctionner pleinement à ce moment, et cela est inacceptable pour nous.
La solution à cette situation a été l'entretien planifié, qui a lieu tous les 3 mois. Il s'agit d'une fenêtre pour le travail planifié lorsque nous désactivons complètement notre service et mettons à jour les instances de base de données. Il restait une semaine avant la fenêtre suivante, et nous avons décidé d'attendre et de nous préparer davantage. Pendant l'attente, nous nous sommes également assurés: pour chaque fragment PostgreSQL, nous avons généré une réplique de rechange en cas d'échec de l'enregistrement des dernières données, et ajouté une nouvelle instance pour chaque fragment, qui devrait devenir une nouvelle réplique dans le cluster Patroni, afin de ne pas exécuter la commande de suppression des données . Tout cela a permis de minimiser le risque d'erreur.

Nous avons redémarré notre service, tout a fonctionné comme il se doit, les utilisateurs ont continué à travailler, mais sur les graphiques, nous avons remarqué une charge anormalement élevée sur le serveur Consul.
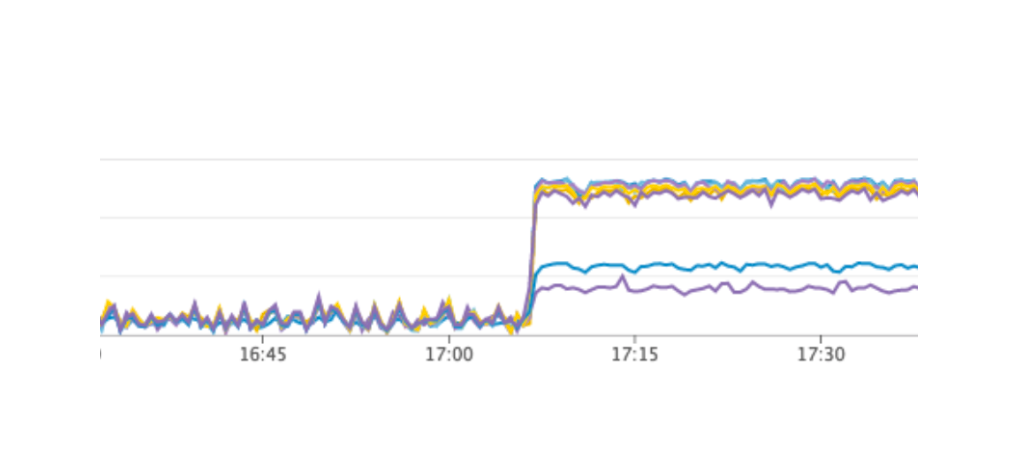
Pourquoi ne l'avons-nous pas vu dans l'environnement de test? Ce problème illustre très bien qu'il est nécessaire de suivre le principe de l'infrastructure en tant que code et d'affiner l'ensemble de l'infrastructure, en commençant par les environnements de test et en terminant par la production. Sinon, il est très facile d'obtenir le genre de problème que nous avons rencontré. Qu'est-il arrivé? Consul est apparu pour la première fois sur la production, puis sur les environnements de test. En conséquence, sur les environnements de test, la version de Consul était supérieure à la production. Juste dans l'une des versions, une fuite de processeur a été résolue lors de l'utilisation de consul-template. Par conséquent, nous venons de mettre à jour Consul, résolvant ainsi le problème.
Redémarrez le cluster Patroni
Cependant, nous avons eu un nouveau problème dont nous n'étions même pas conscients. Lors de la mise à jour de Consul, nous supprimons simplement le nœud Consul du cluster à l'aide de la commande consul Leave → Patroni se connecte à un autre serveur Consul → tout fonctionne. Mais lorsque nous avons atteint la dernière instance du cluster Consul et que nous lui avons envoyé la commande congé consul, tous les clusters Patroni ont simplement redémarré et dans les journaux, nous avons vu l'erreur suivante:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
Le cluster Patroni n'a pas pu obtenir d'informations sur son cluster et a redémarré.
Pour trouver une solution, nous avons contacté les auteurs de Patroni via issue sur github. Ils ont suggéré des améliorations à nos fichiers de configuration:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
Nous avons pu répéter le problème sur un environnement de test et y tester ces paramètres, mais malheureusement, cela n'a pas fonctionné.
Le problème n'est toujours pas résolu. Nous prévoyons d'essayer les solutions suivantes:
- Utilisez Consul-agent sur chaque instance du cluster Patroni;
- Corrigez le problème dans le code.
Nous comprenons l'endroit où l'erreur s'est produite: le problème utilise probablement le délai d'expiration par défaut, qui n'est pas remplacé par le fichier de configuration. Lorsque le dernier serveur Consul est supprimé du cluster, l'ensemble du cluster Consul se bloque pendant plus d'une seconde, car Patroni ne peut pas obtenir l'état du cluster et redémarre complètement l'ensemble du cluster.
Heureusement, nous n'avons plus rencontré d'erreurs.
Résultats de l'utilisation de Patroni
Après le lancement réussi de Patroni, nous avons ajouté une réplique supplémentaire dans chaque cluster. Maintenant, dans chaque cluster, il y a un semblant de quorum: un leader et deux répliques - pour assurer contre le cas de split-brain lors du changement.
Patroni travaille à la production depuis plus de trois mois. Pendant ce temps, il a déjà réussi à nous aider. Récemment, le leader de l'un des clusters est décédé dans AWS, le basculement automatique a fonctionné et les utilisateurs ont continué à travailler. Patroni a terminé sa tâche principale.
Un petit résumé de l'utilisation de Patroni:- Facilité de changement de configuration. Il suffit de modifier la configuration sur une seule instance et elle sera déployée sur l'ensemble du cluster. Si un redémarrage est nécessaire pour appliquer la nouvelle configuration, Patroni le signalera. Patroni peut redémarrer l'ensemble du cluster avec une seule commande, ce qui est également très pratique.
- Le basculement automatique fonctionne et a déjà réussi à nous aider.
- Mise à jour PostgreSQL sans interruption de l'application. Vous devez d'abord mettre à niveau les répliques vers la nouvelle version, puis changer le leader dans le cluster Patroni et mettre à jour l'ancien leader. Dans ce cas, le test nécessaire du basculement automatique se produit.