Les utilisateurs de ClickHouse savent que son principal avantage est la grande vitesse de traitement des requêtes analytiques. Mais comment pouvons-nous faire de telles déclarations? Cela devrait être pris en charge par des tests de performances fiables. Nous en parlerons aujourd'hui.
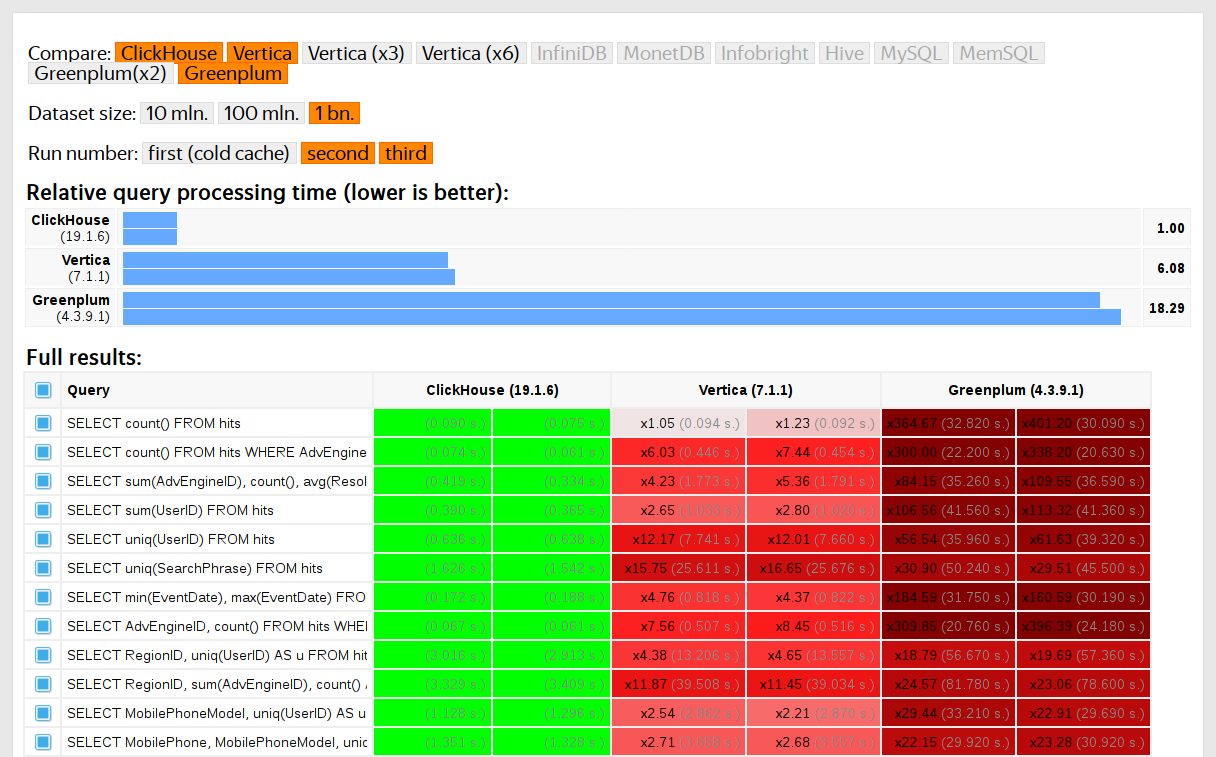
Nous avons commencé à réaliser de tels tests en 2013, bien avant que le produit ne soit disponible en open source. Comme maintenant, nous étions plus intéressés par la vitesse du service de données Yandex.Metrica. Nous avons déjà stocké des données dans ClickHouse depuis janvier 2009. Une partie des données a été écrite dans la base de données depuis 2012, et une partie - a été
convertie à partir de
OLAPServer et Metrage - structures de données qui étaient utilisées dans Yandex.Metrica auparavant. Par conséquent, pour les tests, nous avons pris le premier sous-ensemble disponible d'un milliard de données de pages vues. Il n'y avait pas encore de requêtes dans Metric, et nous avons trouvé des requêtes qui nous intéressent le plus (toutes sortes de filtrage, d'agrégation et de tri).
ClickHouse a été testé en comparaison avec des systèmes similaires, par exemple Vertica et MonetDB. Pour être honnête, elle a été menée par un employé qui n'était pas auparavant un développeur ClickHouse, et des cas particuliers dans le code n'ont pas été optimisés jusqu'à ce que les résultats soient obtenus. De même, nous avons obtenu un ensemble de données pour les tests fonctionnels.
Après que ClickHouse ait rejoint l'open source en 2016, il y avait plus de questions pour les tests.
Inconvénients des tests sur des données propriétaires
Tests de performance:
- Ils ne sont pas reproductibles de l'extérieur, car leur lancement nécessite des données fermées qui ne peuvent pas être publiées. Pour la même raison, certains tests fonctionnels ne sont pas disponibles pour les utilisateurs externes.
- Ne se développe pas. Il y a un besoin pour une expansion significative de leur ensemble, de sorte qu'il est possible de vérifier de manière isolée les changements de vitesse des différentes parties du système.
- Ils ne s'exécutent pas de manière fiable pour les demandes de pool, les développeurs externes ne peuvent pas vérifier leur code pour la régression des performances.
Vous pouvez résoudre ces problèmes - jetez les anciens tests et faites-en de nouveaux en fonction des données ouvertes. Parmi les données ouvertes, vous pouvez prendre des
données sur les vols vers les États-Unis , les
trajets en taxi à New York ou utiliser des références prédéfinies TPC-H, TPC-DS,
Star Schema Benchmark . L'inconvénient est que ces données sont loin des données Yandex.Metrica, et je voudrais enregistrer les demandes de test.
Il est important d'utiliser des données réelles.
Vous devez tester les performances du service uniquement sur des données réelles issues de la production. Regardons quelques exemples.
Exemple 1Supposons que vous remplissiez une base de données avec des nombres pseudo-aléatoires uniformément répartis. Dans ce cas, la compression des données ne fonctionnera pas. Mais la compression des données est une propriété importante pour les SGBD analytiques. Choisir le bon algorithme de compression et la bonne façon de l'intégrer dans le système est une tâche non triviale dans laquelle il n'y a pas de solution correcte, car la compression des données nécessite un compromis entre la vitesse de compression et de décompression et le taux de compression potentiel. Les systèmes qui ne savent pas comment compresser les données sont garantis. Mais si nous utilisons des nombres pseudo-aléatoires uniformément distribués pour les tests, ce facteur n'est pas pris en compte et tous les autres résultats seront déformés.
Conclusion: les données de test doivent avoir un taux de compression réaliste.
À propos de l'optimisation des algorithmes de compression de données dans ClickHouse dont j'ai parlé dans un
post précédent .
Exemple 2Intéressons-nous à la vitesse de la requête SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Il s'agit d'une demande typique pour Yandex.Metrica. Qu'est-ce qui est important pour sa vitesse?
- Comment est exécuté GROUP BY ?
- Quelle structure de données est utilisée pour calculer la fonction d'agrégation uniq.
- Combien de RegionIDs différents et combien de RAM chaque état de la fonction uniq nécessite.
Mais il est également très important que la quantité de données pour les différentes régions soit répartie de manière inégale. (Probablement, il est distribué selon la loi de puissance. J'ai construit un graphique dans l'échelle log-log, mais je ne suis pas sûr.) Et si c'est le cas, il est important pour nous que les états de la fonction d'agrégation uniq avec un petit nombre de valeurs utilisent peu de mémoire. Lorsqu'il existe de nombreuses clés d'agrégation différentes, le décompte va aux unités d'octets. Comment obtenir les données générées qui ont toutes ces propriétés? Bien sûr, il vaut mieux utiliser des données réelles.
De nombreux SGBD implémentent la structure de données HyperLogLog pour le calcul approximatif de COUNT (DISTINCT), mais ils fonctionnent tous relativement mal car cette structure de données utilise une quantité fixe de mémoire. Et ClickHouse a une fonction qui utilise une
combinaison de trois structures de données différentes , selon la taille de l'ensemble.
Conclusion: les données de test doivent représenter les propriétés de la distribution des valeurs dans les données - la cardinalité (le nombre de valeurs dans les colonnes) et la cardinalité mutuelle de plusieurs colonnes différentes.
Exemple 3Eh bien, testons les performances non pas du SGBD analytique ClickHouse, mais de quelque chose de plus simple, par exemple, des tables de hachage. Pour les tables de hachage, choisir la bonne fonction de hachage est très important. Pour std :: unordered_map, il est légèrement moins important, car il s'agit d'une table de hachage basée sur une chaîne et un nombre premier est utilisé comme taille du tableau. Dans l'implémentation de bibliothèque standard dans gcc et clang, une fonction de hachage triviale est utilisée comme fonction de hachage par défaut pour les types numériques. Mais std :: unordered_map n'est pas le meilleur choix lorsque nous voulons obtenir une vitesse maximale. Lorsque vous utilisez des tables de hachage à adressage ouvert, le bon choix de la fonction de hachage devient un facteur décisif, et nous ne pouvons pas utiliser la fonction de hachage triviale.
Il est facile de trouver des tests de performance de table de hachage sur des données aléatoires, sans tenir compte des fonctions de hachage utilisées. Il est également facile de trouver des tests de fonction de hachage en mettant l'accent sur la vitesse de calcul et certains critères de qualité, cependant, indépendamment des structures de données utilisées. Mais le fait est que les tables de hachage et HyperLogLog nécessitent des critères de qualité différents pour les fonctions de hachage.
En savoir plus à ce sujet dans le rapport
«Comment les tables de hachage dans ClickHouse sont organisées» . Il est un peu dépassé car il ne prend pas en compte les
tables suisses .
Défi
Nous voulons obtenir les données pour les tests de performances sur la structure de la même manière que les données Yandex.Metrica, pour lesquelles toutes les propriétés importantes pour les benchmarks sont stockées, mais pour qu'il n'y ait aucune trace de visiteurs réels du site dans ces données. Autrement dit, les données doivent être anonymisées et les éléments suivants doivent être stockés:
- taux de compression
- cardinalité (nombre de valeurs différentes),
- cardinalités mutuelles de plusieurs colonnes différentes,
- propriétés des distributions de probabilité avec lesquelles vous pouvez simuler des données (par exemple, si nous pensons que les régions sont distribuées selon une loi de puissance, l'exposant - paramètre de distribution - pour les données artificielles devrait être à peu près le même que pour le réel).
Et que faut-il pour que les données aient un taux de compression similaire? Par exemple, si LZ4 est utilisé, alors les sous-chaînes dans les données binaires doivent être répétées à environ les mêmes distances et les répétitions doivent être approximativement de la même longueur. Pour ZSTD, une correspondance d'entropie d'octet est ajoutée.
L'objectif maximum: mettre un outil à la disposition de personnes externes, avec lequel chacun peut anonymiser son jeu de données pour publication. Afin que nous déboguions et testions les performances sur les données d'autres personnes de manière similaire aux données de production. Et je voudrais que ce soit intéressant de regarder les données générées.
Il s'agit d'une déclaration informelle du problème. Cependant, personne n'allait faire de déclaration officielle.
Tentatives de résolution
L'importance de cette tâche ne doit pas être exagérée pour nous. En fait, ce n'était jamais dans les plans et personne n'allait même le faire. Je n'ai tout simplement pas renoncé à espérer que quelque chose se produirait, et tout à coup, je serais de bonne humeur et beaucoup de choses pourraient être reportées à plus tard.
Modèles probabilistes explicites
La première idée est de sélectionner une famille de distributions de probabilité qui la modélise pour chaque colonne du tableau. Ensuite, en fonction des statistiques des données, sélectionnez les paramètres d'ajustement du modèle et générez de nouvelles données à l'aide de la distribution sélectionnée. Vous pouvez utiliser un générateur de nombres pseudo-aléatoires avec une graine prédéfinie pour obtenir un résultat reproductible.
Pour les champs de texte, vous pouvez utiliser des chaînes de Markov - un modèle compréhensible pour lequel vous pouvez effectuer une implémentation efficace.
Certes, quelques astuces sont nécessaires:
- Nous voulons préserver la continuité des séries chronologiques - ce qui signifie que pour certains types de données, il est nécessaire de modéliser non pas la valeur elle-même, mais la différence entre les valeurs voisines.
- Afin de simuler la cardinalité conditionnelle des colonnes (par exemple, qu'il y a généralement peu d'adresses IP par identifiant de visiteur), vous devrez également noter explicitement les dépendances entre les colonnes (par exemple, pour générer une adresse IP, un hachage à partir de l'identifiant de visiteur est utilisé, mais aussi quelques autres données pseudo-aléatoires sont ajoutées).
- Il n'est pas clair comment exprimer la dépendance qu'un visiteur à peu près au même moment visite souvent des URL avec des domaines correspondants.
Tout cela est présenté sous la forme d'un programme dans lequel toutes les distributions et dépendances sont codées en dur - le soi-disant «script C ++». Cependant, les modèles de Markov sont toujours calculés à partir de la somme des statistiques, lissage et rugosité à l'aide du bruit. J'ai commencé à écrire ce script, mais pour une raison quelconque, après avoir explicitement écrit le modèle pour dix colonnes, il est soudain devenu insupportablement ennuyeux. Et dans le tableau des résultats de Yandex.Metrica en 2012, il y avait plus de 100 colonnes.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Cette approche de la tâche a été un échec. Si je l'ai approchée avec plus de diligence, c'est sûr que le scénario aurait été écrit.
Avantages:
Inconvénients:
- la complexité de la mise en œuvre,
- la solution implémentée ne convient qu'à un seul type de données.
Et je voudrais une solution plus générale - afin qu'elle puisse être appliquée non seulement aux données Yandex.Metrica, mais aussi pour obscurcir toutes les autres données.
Cependant, des améliorations sont possibles ici. Vous ne pouvez pas sélectionner manuellement des modèles, mais implémenter un catalogue de modèles et choisir le meilleur parmi eux (meilleur ajustement + une sorte de régularisation). Ou peut-être pouvez-vous utiliser des modèles de Markov pour tous les types de champs, et pas seulement pour le texte. Les dépendances entre les données peuvent également être comprises automatiquement. Pour ce faire, vous devez calculer les
entropies relatives (quantité relative d'informations) entre les colonnes, ou plus simplement, les cardinalités relatives (quelque chose comme «combien de valeurs A différentes en moyenne pour une valeur B fixe») pour chaque paire de colonnes. Cela indiquera clairement, par exemple, que URLDomain dépend entièrement de l'URL, et non l'inverse.
Mais j'ai également refusé cette idée, car il y a trop d'options pour ce qui doit être pris en compte, et cela prendra beaucoup de temps à écrire.
Réseaux de neurones
J'ai déjà dit à quel point cette tâche est importante pour nous. Personne n'a même pensé à faire la moindre rampe à sa mise en œuvre. Heureusement, le collègue Ivan Puzyrevsky a ensuite travaillé comme enseignant au HSE et développait en même temps le noyau YT. Il m'a demandé si j'avais des tâches intéressantes à proposer aux étudiants comme sujet de diplôme. Je lui ai proposé celui-ci et il m'a assuré qu'il convenait. J'ai donc confié cette tâche à une bonne personne «de la rue» - Sharif Anvardinov (le NDA est signé pour travailler avec les données).
Il lui a parlé de toutes ses idées, mais surtout, il a expliqué que le problème peut être résolu de n'importe quelle manière. Et une bonne option serait d'utiliser ces approches que je ne comprends pas du tout: par exemple, générer un vidage de données texte à l'aide de LSTM. Cela semblait encourageant grâce à l'
article L'efficacité déraisonnable des réseaux de neurones récurrents , qui a ensuite attiré mon attention.
La première caractéristique de la tâche est que vous devez générer des données structurées, pas seulement du texte. Il n'était pas évident qu'un réseau de neurones récurrent serait capable de générer des données avec la structure souhaitée. Il existe deux façons de résoudre ce problème. La première consiste à utiliser des modèles distincts pour générer la structure et pour le «remplissage»: le réseau neuronal ne devrait générer que des valeurs. Mais cette option a été reportée à plus tard, après quoi ils ne l'ont jamais fait. La deuxième façon consiste simplement à générer un vidage TSV sous forme de texte. La pratique a montré que dans le texte, une partie des lignes ne correspondra pas à la structure, mais ces lignes peuvent être supprimées lors du chargement.
La deuxième caractéristique - un réseau de neurones récurrent génère une séquence de données, et les dépendances dans les données ne peuvent suivre que dans l'ordre de cette séquence. Mais dans nos données, l'ordre des colonnes est peut-être inversé par rapport aux dépendances entre elles. Nous n'avons rien fait avec cette fonctionnalité.
Vers l'été, le premier script Python fonctionnel est apparu et a généré des données. À première vue, la qualité des données est décente:
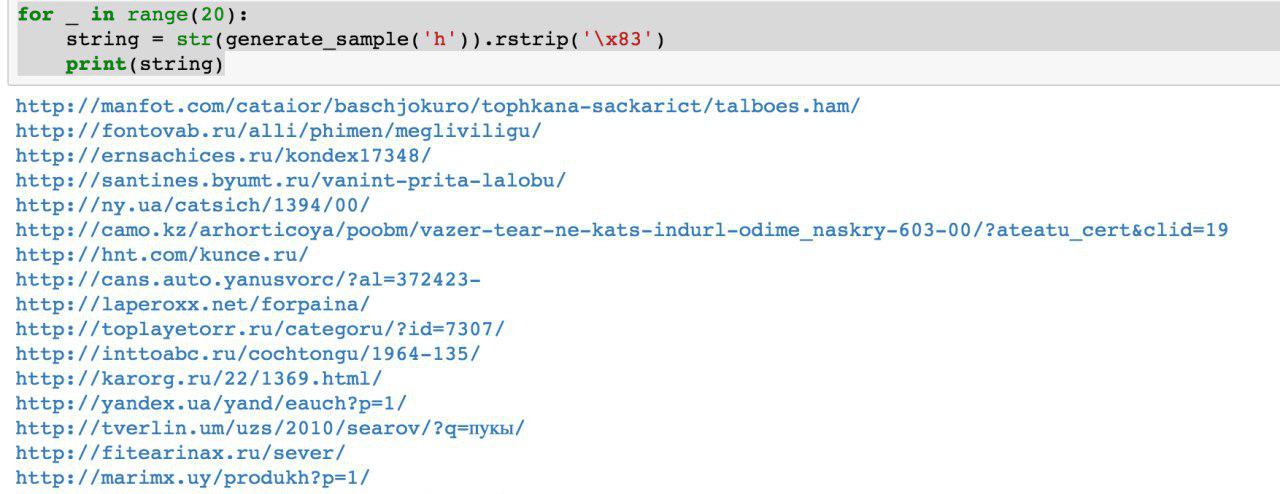
Certes, des difficultés ont été révélées:
- La taille du modèle est d'environ un gigaoctet. Et nous avons essayé de créer un modèle pour des données dont la taille était de l'ordre de plusieurs gigaoctets (pour commencer). Le fait que le modèle résultant soit si grand soulève des inquiétudes: il sera soudainement possible d'obtenir des données réelles sur lesquelles il a été formé. Probablement pas. Mais je ne comprends pas l'apprentissage automatique et les réseaux de neurones et je n'ai pas lu le code Python de cette personne, alors comment en être sûr? Ensuite, il y avait des articles sur la façon de compresser les réseaux de neurones sans perte de qualité, mais cela n'a pas été implémenté. D'une part, cela ne ressemble pas à un problème - vous pouvez refuser de publier le modèle et publier uniquement les données générées. En revanche, dans le cas d'une reconversion, les données générées peuvent contenir une partie des données source.
- Sur une seule machine dotée d'un processeur, le taux de génération de données est d'environ 100 lignes par seconde. Nous avions une tâche - générer au moins un milliard de lignes. Le calcul a montré que cela ne pouvait se faire avant la soutenance du diplôme. Et l'utilisation d'un autre matériel n'est pas pratique, car j'avais un objectif - rendre l'outil de génération de données disponible pour une large utilisation.
Sharif a essayé d'étudier la qualité des données en comparant les statistiques. Par exemple, j'ai calculé la fréquence à laquelle différents symboles apparaissent dans la source et dans les données générées. Le résultat a été époustouflant - les personnages les plus courants sont Ð et Ñ.
Ne vous inquiétez pas - il a parfaitement défendu son diplôme, après quoi nous avons oublié ce travail en toute sécurité.
Mutation des données compressées
Supposons que l'énoncé du problème soit réduit à un point: vous devez générer des données pour lesquelles les taux de compression seront exactement les mêmes que les données d'origine, tandis que les données doivent être développées exactement à la même vitesse. Comment faire Besoin de modifier directement les octets de données compressées! Ensuite, la taille des données compressées ne changera pas, mais les données elles-mêmes changeront. Oui, et tout fonctionnera rapidement. Lorsque cette idée est apparue, j'ai immédiatement voulu la mettre en œuvre, malgré le fait qu'elle résout un autre problème au lieu de l'original. Ça arrive toujours.
Comment éditer un fichier compressé directement? Supposons que nous ne soyons intéressés que par LZ4. Les données compressées à l'aide de LZ4 se composent de deux types d'instructions:
- Littéraux: copiez les N octets suivants tels quels.
- Correspondance (correspondance, la longueur de répétition minimale est de 4): répéter N octets qui se trouvaient dans le fichier à une distance de M.
Données sources:
Hello world Hello .
Données compressées (conditionnellement):
literals 12 "Hello world " match 5 12 .
Dans le fichier compressé, laissez la correspondance telle quelle, et dans les littéraux, nous changerons les valeurs d'octet. Par conséquent, après décompression, nous obtenons un fichier dans lequel toutes les séquences répétitives d'au moins 4 longueurs sont également répétées et répétées aux mêmes distances, mais en même temps se composent d'un ensemble d'octets différent (au sens figuré, pas un seul octet n'a été extrait du fichier d'origine dans le fichier modifié )
Mais comment changer les octets? Cela n'est pas évident car, en plus des types de colonnes, les données ont également leur propre structure interne implicite, que nous aimerions conserver. Par exemple, le texte est souvent stocké dans le codage UTF-8 - et nous voulons également un UTF-8 valide dans les données générées. J'ai fait une heuristique simple pour satisfaire plusieurs conditions:
- les octets nuls et les caractères de contrôle ASCII ont été stockés tels quels,
- une ponctuation persistait,
- ASCII a été traduit en ASCII, et pour le reste, le bit le plus significatif a été enregistré (ou vous pouvez explicitement écrire un si défini pour différentes longueurs UTF-8). Parmi une classe d'octets, une nouvelle valeur est sélectionnée de manière uniforme au hasard;
- et aussi pour enregistrer des fragments de
https:// et similaire, sinon tout semble trop idiot.
La particularité de cette approche est que les données initiales elles-mêmes agissent comme un modèle pour les données, ce qui signifie que le modèle ne peut pas être publié. Il vous permet de générer la quantité de données pas plus que l'original. À titre de comparaison, dans les approches précédentes, il était possible de créer un modèle et de générer une quantité illimitée de données sur sa base.
Exemple d'URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Le résultat m'a plu - c'était intéressant de regarder les données. Mais encore, quelque chose n'allait pas. Les URL sont toujours structurées, mais à certains endroits, il était trop facile de deviner yandex ou avito. Fait une heuristique qui réorganise parfois certains octets à certains endroits.
D'autres considérations inquiètent. Par exemple, les informations sensibles peuvent être représentées dans une colonne de type FixedString sous forme binaire et pour une raison quelconque, se composent de caractères de contrôle ASCII et de ponctuation, que j'ai décidé de sauvegarder. Et je ne considère pas les types de données.
Autre problème: si des données de type "longueur, valeur" sont stockées dans une colonne (c'est ainsi que sont stockées les colonnes de type String), alors comment s'assurer que la longueur reste correcte après la mutation? Quand j'ai essayé de le réparer, la tâche est immédiatement devenue sans intérêt.
Permutations aléatoires
Mais le problème n'est pas résolu. Nous avons mené plusieurs expériences et cela n'a fait qu'empirer. Il ne reste plus qu'à ne rien faire et à lire des pages au hasard sur Internet, car l'ambiance est déjà gâtée. Heureusement, sur l'une de ces pages se trouvait une
analyse de l'algorithme pour rendre la scène de la mort du protagoniste dans le jeu Wolfenstein 3D.

Belle animation - l'écran se remplit de sang. L'article explique qu'il s'agit en fait d'une permutation pseudo-aléatoire. Permutation aléatoire - une transformation un-à-un sélectionnée au hasard d'un ensemble. Autrement dit, l'affichage de l'ensemble dans lequel les résultats pour différents arguments ne sont pas répétés. En d'autres termes, c'est une manière d'itérer sur tous les éléments d'un ensemble dans un ordre aléatoire. C'est un tel processus qui est montré dans l'image - nous peignons sur chaque pixel, choisis au hasard parmi tous, sans répétition. Si nous choisissions simplement un pixel aléatoire à chaque étape, cela nous prendrait beaucoup de temps pour peindre la dernière.
Le jeu utilise un algorithme très simple de permutation pseudo-aléatoire -
LFSR (registre à décalage à rétroaction linéaire). Comme les générateurs de nombres pseudo-aléatoires, les permutations aléatoires, ou plutôt leurs familles, paramétrées par la clé, peuvent être cryptographiquement solides - c'est exactement ce dont nous avons besoin pour convertir les données. Bien qu'il puisse y avoir des détails non évidents. Par exemple, le cryptage cryptographiquement fort de N octets en N octets avec une clé pré-fixée et un vecteur d'initialisation, semble-t-il, peut être utilisé comme une permutation pseudo-aléatoire de nombreuses chaînes de N octets. En effet, une telle transformation est biunivoque et semble aléatoire. Mais si nous utilisons la même transformation pour toutes nos données, le résultat peut être soumis à l'analyse, car le même vecteur d'initialisation et les mêmes valeurs clés sont utilisés plusieurs fois. Ceci est similaire au mode de chiffrement par bloc du
livre de codes électronique .
Quels sont les moyens d'obtenir une permutation pseudo-aléatoire? Vous pouvez prendre des transformations simples et un à un et en assembler une fonction assez complexe qui semblera aléatoire. Permettez-moi de vous donner un exemple de certaines de mes transformations biunivoque préférées:
- multiplication par un nombre impair (par exemple un grand premier) dans l'arithmétique du complément à deux,
- xor-shift:
x ^= x >> N , - CRC-N, où N est le nombre de bits de l'argument.
Ainsi, par exemple, à partir de trois multiplications et de deux opérations xor-shift, le finaliseur
murmurhash est
assemblé . Cette opération est une permutation pseudo-aléatoire. Mais juste au cas où, je note que les fonctions de hachage, même N bits sur N bits, ne doivent pas être mutuellement uniques.
Ou voici un autre
exemple intéressant
de la théorie des
nombres élémentaires du site de Jeff Preshing.
Comment pouvons-nous utiliser des permutations pseudo-aléatoires pour notre tâche? Vous pouvez convertir tous les champs numériques en les utilisant. Il sera alors possible de conserver toutes les cardinalités et cardinalités mutuelles de toutes les combinaisons de champs. Autrement dit, COUNT (DISTINCT) renverra la même valeur qu'avant la conversion, et avec tout GROUP BY.
Il convient de noter que la préservation de toutes les cardinalités est légèrement contraire à l'énoncé du problème de l'anonymisation des données. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , ,
.
, . , 10, . ?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . Et ainsi de suite. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c
Hackers News , .
Redis — . ,
.
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . -
- — .: Lore - dfghf — . - ) 473682 -
- ! » - —
- ! » ,
- . c @Mail.Ru -
- , 2010 | .
- ! : 820 0000 ., -
- - DoramaTv.ru - . - ..
- . 2013 , -> 80 .
- - (. , ,
- . 5, 69, W* - ., , World of Tanks
- , . 2 @Mail.Ru
- , .
Résultat
, - , - . , . clickhouse obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
, . , ? , , . , , . , (
--help ) .
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzClickHouse. , ClickHouse .