Bonjour, Habr! Je m'appelle Sasha et je suis développeur backend. Pendant mon temps libre, j'étudie le ML et je m'amuse avec les données hh.ru.
Cet article explique comment nous avons automatisé le processus d'affectation de tâches de routine pour les testeurs à l'aide de l'apprentissage automatique.
Hh.ru dispose d'un service interne pour lequel des tâches sont créées dans Jira (au sein de l'entreprise, elles s'appellent HHS) si quelqu'un ne fonctionne pas ou ne fonctionne pas correctement. De plus, ces tâches sont gérées manuellement par le chef d'équipe QA Alexey et attribuées à l'équipe dont le domaine de responsabilité comprend le dysfonctionnement. Lesha sait que les tâches ennuyeuses doivent être effectuées par des robots. Par conséquent, il s'est tourné vers moi pour obtenir de l'aide concernant ML.

Le graphique ci-dessous montre le montant de HHS par mois. Nous grandissons et le nombre de tâches augmente. Les tâches sont principalement créées pendant les heures de travail, quelques-unes par jour, et cela doit être constamment distrait.
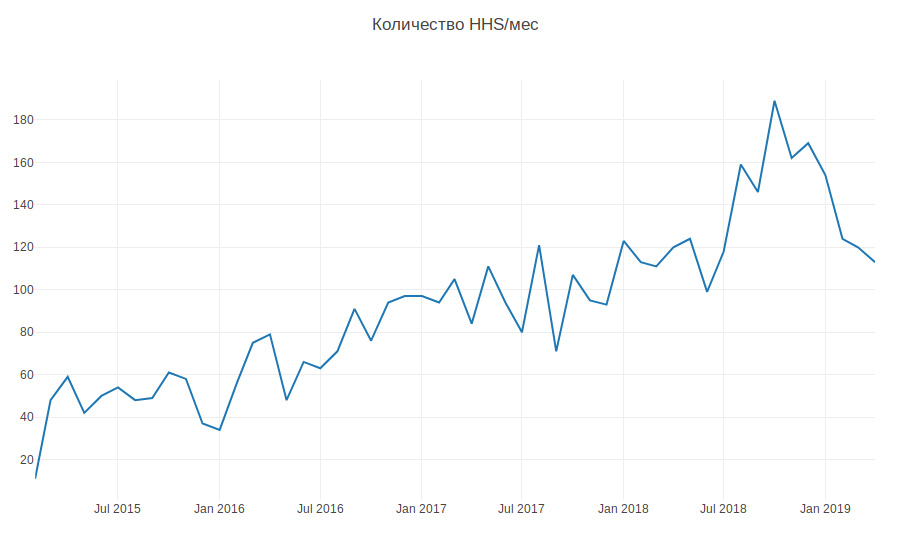
Ainsi, selon les données historiques, il est nécessaire d'apprendre à déterminer l'équipe de développement à laquelle appartient HHS. Il s'agit d'une tâche de classification multi-classes.
Les données
Dans les tâches d'apprentissage automatique, la chose la plus importante est la qualité des données. Le résultat de la solution du problème en dépend. Par conséquent, toute tâche d'apprentissage automatique doit commencer par étudier les données. Depuis le début de 2015, nous avons accumulé environ 7000 tâches qui contiennent les informations utiles suivantes:
- Résumé - titre, brève description
- Description - une description complète du problème
- Étiquettes - une liste de balises liées au problème
- Reporter est le nom du créateur de HHS. Cette fonctionnalité est utile car les gens travaillent avec un ensemble limité de fonctionnalités.
- Créé - Date de création
- Le cessionnaire est la personne à laquelle la tâche est affectée. La variable cible sera générée à partir de cet attribut.
Commençons par la variable cible. Premièrement, chaque équipe a des domaines de responsabilité. Parfois, ils se croisent, parfois une équipe peut se croiser en développement avec une autre. La décision sera basée sur l'hypothèse que le cessionnaire, qui était resté avec la tâche au moment de la clôture, est responsable de sa solution. Mais nous devons prédire non pas une personne en particulier, mais une équipe. Heureusement, toutes les équipes de Jira sont conservées et peuvent être cartographiées. Mais avec la définition d'une équipe selon une personne, il y a un certain nombre de problèmes:
- tous les HHS ne sont pas liés à des problèmes techniques, et nous ne sommes intéressés que par les tâches qui peuvent être attribuées à l'équipe de développement. Par conséquent, vous devez supprimer les tâches lorsque le cessionnaire ne fait pas partie du service technique
- parfois, les équipes cessent d'exister. Ils sont également supprimés de l'ensemble de formation.
- Malheureusement, les gens ne travaillent pas éternellement dans l'entreprise, et parfois ils passent d'une équipe à l'autre. Heureusement, nous avons réussi à obtenir un historique des changements dans la composition de toutes les équipes. Ayant la date de création de HHS et du cessionnaire, vous pouvez trouver quelle équipe était engagée dans la tâche à un moment précis.
Après avoir filtré les données non pertinentes, l'échantillon de formation a été réduit à 4900 tâches.
Regardons la répartition des tâches entre les équipes:
Les tâches doivent être réparties entre 22 équipes.
Signes:
Le résumé et la description sont des champs de texte.
Tout d'abord, ils doivent être nettoyés des caractères en excès. Pour certaines tâches, il est logique de laisser dans les lignes des caractères qui portent des informations, par exemple + et #, pour faire la distinction entre c ++ et c #, mais dans ce cas, j'ai décidé de ne laisser que des lettres et des chiffres, car n'a pas trouvé où d'autres caractères pourraient être utiles.
Les mots doivent être lemmatisés. La lemmatisation est la réduction d'un mot à un lemme, sa forme normale (vocabulaire). Par exemple, chats → chat. J'ai également essayé le stemming, mais avec la lemmatisation, la qualité était un peu plus élevée. Le stamming est le processus de recherche de la base d'un mot. Cette base est due à l'algorithme (dans différentes implémentations, ils sont différents), par exemple, par chats → chats. Le sens du premier et du second est de juxtaposer les mêmes mots sous différentes formes. J'ai utilisé le wrapper python pour
Yandex Mystem .
En outre, le texte doit être débarrassé des mots vides qui ne portent pas de charge utile. Par exemple, «était», «moi», «encore». Arrêtez les mots que je prends habituellement de
NLTK .
Une autre approche que j'essaie dans les tâches de travail avec du texte est une fragmentation des mots basée sur les caractères. Par exemple, il y a une «recherche». Si vous le divisez en composants de 3 caractères, vous obtenez les mots "poi", "ois", "action en justice". Cela permet d'obtenir des connexions supplémentaires. Supposons qu'il y ait le mot «recherche». La lemmatisation ne conduit pas à la «recherche» et à la «recherche» sous une forme générale, mais une partition de 3 caractères mettra en évidence la partie commune - «revendication».
J'ai fait deux jetons. Tokenizer est une méthode qui reçoit du texte à l'entrée, et la sortie contient une liste de jetons - les composants du texte. Le premier met en évidence des mots et des chiffres lemmatisés. La seconde ne met en évidence que les mots lemmatisés, qui sont divisés en 3 caractères, c'est-à-dire à la sortie, il a une liste de jetons à trois caractères.
Les Tokenizers sont utilisés dans
TfidfVectorizer , qui est utilisé pour convertir les données texte (et pas seulement) en une représentation vectorielle basée sur
tf-idf . Une liste de lignes lui est fournie en entrée, et en sortie on obtient une matrice M par N, où M est le nombre de lignes et N le nombre de signes. Chaque caractéristique est une réponse en fréquence d'un mot dans un document, où la fréquence est amendée si le mot apparaît plusieurs fois dans tous les documents. Grâce au paramètre ngram_range TfidfVectorizer, j'ai ajouté des
bigrammes et des trigrammes comme attributs.
J'ai également essayé d'utiliser des incorporations de mots obtenues avec Word2vec comme fonctionnalités supplémentaires. L'incorporation est une représentation vectorielle d'un mot. Pour chaque texte, j'ai fait la moyenne des plongements de tous ses mots. Mais cela n'a donné aucune augmentation, j'ai donc refusé ces signes.
Pour les étiquettes, un
CountVectorizer a été utilisé. Les lignes avec des balises sont alimentées à l'entrée, et à la sortie, nous avons une matrice où les lignes correspondent aux tâches et les colonnes correspondent aux balises. Chaque cellule contient le nombre d'occurrences de la balise dans la tâche. Dans mon cas, c'est 1 ou 0.
LabelBinarizer est venu pour Reporter. Il binarise les attributs un à tous. Il ne peut y avoir qu'un seul créateur pour chaque tâche. À l'entrée de LabelBinarizer, une liste de créateurs de tâches est soumise et la sortie est une matrice, où les lignes sont des tâches et les colonnes correspondent aux noms des créateurs de tâches. Il s'avère que dans chaque ligne, il y a «1» dans la colonne correspondant au créateur, et dans le reste - «0».
Pour Créé, la différence en jours entre la date de création de la tâche et la date actuelle est prise en compte.
En conséquence, les signes suivants ont été obtenus:
- tf-idf pour Résumé en mots et chiffres (4855, 4593)
- tf-idf pour Résumé sur trois partitions de caractères (4855, 15518)
- tf-idf pour Description en mots et en chiffres (4855, 33297)
- tf-idf pour Description sur les partitions à trois caractères (4855, 75359)
- nombre d'entrées pour les étiquettes (4855, 505)
- signes binaires pour Reporter (4855, 205)
- durée de vie de la tâche (4855, 1)
Tous ces signes sont combinés dans une grande matrice (4855, 129478), sur laquelle une formation sera effectuée.
Séparément, il convient de noter les noms des signes. Parce que certains modèles d'apprentissage automatique peuvent identifier les fonctionnalités qui ont le plus grand impact sur la reconnaissance de classe, vous devez l'utiliser. TfidfVectorizer, CountVectorizer, LabelBinarizer ont des méthodes get_feature_names qui affichent une liste de fonctionnalités dont l'ordre correspond aux colonnes des matrices de données.
Sélection du modèle de prédiction
Très souvent,
XGBoost donne de bons résultats. Et il a commencé avec ça. Mais j'ai généré un grand nombre de fonctionnalités, dont le nombre dépasse considérablement la taille de l'échantillon d'apprentissage. Dans ce cas, la probabilité de recycler XGBoost est élevée. Le résultat n'est pas très bon. La dimension élevée est une régression
logistique bien digérée. Elle a montré une meilleure qualité.
J'ai également essayé comme exercice de construire un modèle sur un réseau neuronal dans Tensorflow en utilisant
cet excellent tutoriel, mais cela s'est avéré pire que la régression logistique.
Sélection d'hyperparamètres
J'ai aussi joué avec les hyperparamètres XGBoost et Tensorflow, mais je le laisse en dehors du post, car le résultat de la régression logistique n'a pas été dépassé. Enfin, j'ai tordu tous les stylos qui pouvaient l'être. En conséquence, tous les paramètres sont restés par défaut, à l'exception de deux: solveur = 'liblinéaire' et C = 3,0
Un autre paramètre qui peut affecter le résultat est la taille de l'échantillon d'apprentissage. Parce que Je m'occupe de données historiques, et au cours de plusieurs années, l'histoire peut sérieusement changer, par exemple, la responsabilité de quelque chose peut revenir à une autre équipe, puis des données plus récentes peuvent être plus utiles, et les anciennes données peuvent même diminuer la qualité. À cet égard, j'ai proposé une heuristique: plus les données sont anciennes, moins elles devraient apporter de contribution à la formation par modélisation. Selon l'âge, les données sont multipliées par un certain coefficient, qui est extrait de la fonction. J'ai généré plusieurs fonctions pour atténuer les données et utilisé celle qui a donné la plus grande augmentation des tests.
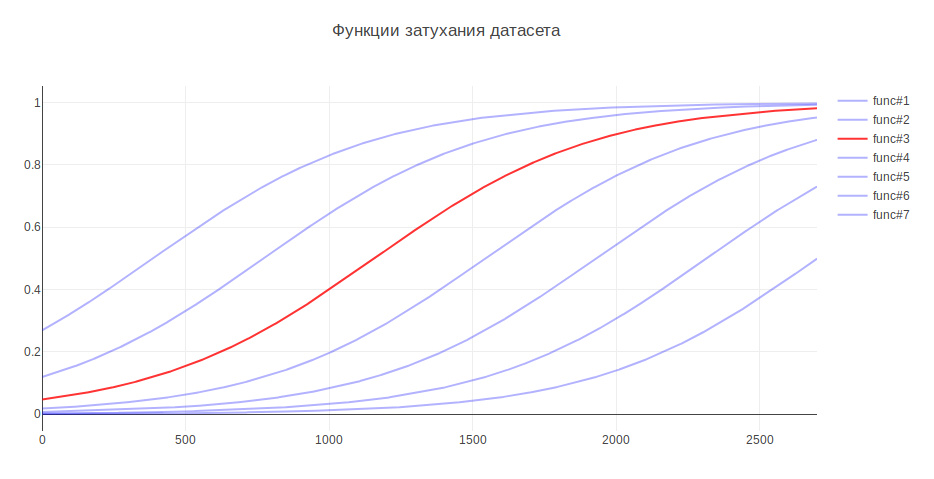
De ce fait, la qualité du classement a augmenté de 3%
Évaluation de la qualité
Dans les problèmes de classification, nous devons réfléchir à ce qui est le plus important pour nous - l'
exactitude ou l'exhaustivité ? Dans mon cas, si l'algorithme est erroné, alors il n'y a rien de mal, nous avons une très bonne connaissance entre les équipes et la tâche sera transférée aux responsables, ou à la principale en QA. De plus, l'algorithme ne fait pas d'erreurs au hasard, mais trouve une commande proche du problème. Par conséquent, il a été décidé de prendre 100% pour l'exhaustivité. Et pour mesurer la qualité, la métrique de précision a été choisie - la proportion de réponses correctes, qui pour le modèle final était de 76%.
En tant que mécanisme de validation, j'ai d'abord utilisé la validation croisée - lorsque l'échantillon est divisé en N parties et que la qualité est vérifiée sur une partie, et la formation est effectuée sur le reste, et donc N fois, jusqu'à ce que chaque partie soit testée. Le résultat est ensuite moyenné. Mais dans mon cas, cette approche ne convenait pas, car l'ordre des données change et, comme cela est déjà connu, la qualité dépend de la fraîcheur des données. Par conséquent, j'ai étudié tout le temps sur les anciens et j'ai été validé sur les nouveaux.
Voyons quelles commandes l'algorithme confond le plus souvent:

En premier lieu, Marketing et Pandora. Ce n'est pas surprenant puisque la deuxième équipe est née de la première et a pris la responsabilité de nombreuses fonctionnalités. Si vous considérez le reste de l'équipe, vous pouvez également voir les raisons associées à la cuisine interne de l'entreprise.
À titre de comparaison, je veux examiner des modèles aléatoires. Si vous attribuez une personne responsable au hasard, alors la qualité sera d'environ 5%, et si la classe la plus courante, alors - 29%
Les signes les plus significatifs
LogisticRegression pour chaque classe renvoie des coefficients d'attribut. Plus la valeur est élevée, plus la contribution de cet attribut à cette classe est grande.
Sous le becquet, la sortie du haut des panneaux. Les préfixes indiquent l'origine des signes:
- sum - tf-idf pour un résumé en mots et en chiffres
- sum2 - tf-idf pour Résumé sur les divisions à trois caractères
- desc - tf-idf pour Description en mots et en chiffres
- desc2 - tf-idf pour Description sur les partitions à trois caractères
- lab - Champ d'étiquettes
- rep - Field Reporter
SignesA-Team: sum_site (1.28), lab_responses_and_invitations (1.37), lab_failure_to the employeur (1.07), lab_makeup (1.03), sum_work (1.54), lab_hhs (1.19), lab_feedback (1.06), rep_name (1.16), sum_ window (1.13), sum_ break (1.04), rep_name_1 (1.22), lab_responses_seeker (1.0), lab_site (0.92)
API: lab_delete_account (1.12), sum_comment_resume (0.94), rep_name_2 (0.9), rep_name_3 (0.83), rep_name_4 (0.89), rep_name_5 (0.91), lab_measurements_managers (0.87), lab_comments_to_result (1.6), account_6 (0.8) ), sum_view (0.91), desc_comment (1.02), rep_name_6 (0.85), desc_resume (0.86), sum_api (1.01)
Android: sum_android (1.77), lab_ios (1.66), sum_application (2.9), sum_hr_mobile (1.4), lab_android (3.55), sum_hr (1.36), lab_mobile_application (3.33), sum_mobile (1.4), rep_name_2 (1.34), sum2_ril (1.27 ), sum_android_application (1.28), sum2_pril_rilo (1.19), sum2_pril_ril (1.27), sum2_ril_log (1.19), sum2_ril_log_ (1.19)
Facturation: rep_name_7 (3.88), desc_account (3.23), rep_name_8 (3.15), lab_billing_wtf (2.46), rep_name_9 (4.51), rep_name_10 (2.88), sum_account (3.16), lab_billing (2.41), rep_name_11 (2.27), lab_b36 ), sum_service (2.33), lab_payment_services (1.92), sum_act (2.26), rep_name_12 (1.92), rep_name_13 (2.4)
Brandy: lab_talent evaluation (2.17), rep_name_14 (1.87), rep_name_15 (3.36), lab_clickme (1.72), rep_name_16 (1.44), rep_name_17 (1.63), rep_name_18 (1.29), sum_page (1.24), sum_brand (1.39) lab ), sum_constructor (1.59), lab_brand de la page (1.33), sum_description (1.23), sum_description_of the company (1.17), lab_article (1.15)
Clickme: desc_act (0,73), sum_adv_hh (0,65), sum_adv_hh_ru (0,65), sum_hh (0,77), lab_hhs (1,27), lab_bs (1,91), rep_name_19 (1,17), rep_name_20 (1,29), rep_name_21 (1,9), rep_name_ ), sum_advertising (0,67), sum_placing (0,65), sum_adv (0,65), sum_hh_ua (0,64), sum_click_31 (0,64)
Marketing: lab_region (0.9), lab_site_site (1.23), sum_mail (1.32), lab_managers_of vacancies (0.93), sum_calender (0.93), rep_name_22 (1.33), lab_queries (1.25), rep_name_6 (1.53), lab_product_1.55 (repa1_5 ), sum_yandex (1,26), sum_distribution_vacancy (0,85), sum_distribution (0,85), sum_category (0,85), sum_error_function (0,83)
Mercure: lab_services (1.76), sum_captcha (2.02), lab_search_services (1.89), lab_lawyers (2.1), lab_authorization_worker (1.68), lab_proforientation (2.53), lab_ready_summary (2.21), rep_name_24 (1.7725_mail ), sum_user (1.57), rep_name_26 (1.43), lab_moderation_of vacancies (1.58), desc_password (1.39), rep_name_27 (1.36)
Mobile_site: sum_mobile_version (1.32), sum_version_site (1.26), lab_application (1.51), lab_statistics (1.32), sum_mobile_version_site (1.25), lab_mobile_version (5.1), sum_version (1.41), rep_name_28 (1.24), 1 ), lab_jtb (1.07), rep_name_16 (1.12), rep_name_29 (1.05), sum_site (0.95), rep_name_30 (0.92)
TMS: rep_name_31 (1.39), lab_talantix (4.28), rep_name_32 (1.55), rep_name_33 (2.59), sum_valuation_talantix (0.74), lab_search (0.57), lab_search (0.63), rep_name_34 (0.64), lab_port (0.56) ), lab_tms (0,74), sum_hh response (0,57), lab_mailing (0,64), sum_talantix (0,6), sum2_po (0,56)
Talantix: sum_system (0.86), rep_name_16 (1.37), sum_talantix (1.16), lab_mail (0.94), lab_xor (0.8), lab_talantix (3.19), rep_name_35 (1.07), rep_name_18 (1.33), lab_personal_data (0.79) ), sum_talantics (0,89), sum_proceed (0,78), lab_mail (0,77), sum_response_stop_view (0,73), rep_name_6 (0,72)
WebServices: sum_vacancy (1.36), desc_pattern (1.32), sum_archive (1.3), lab_patterns (1.39), sum_number_phone (1.44), rep_name_36 (1.28), lab_lawyers (2.1), lab_invitation (1.27), lab_invitation (2) ), lab_selected_summages (1.2), lab_key_keys (1.22), sum_find (1.18), sum_phone (1.16), sum_folder (1.17)
iOS: sum_application (1.41), desc_application (1.13), lab_andriod (1.73), rep_name_37 (1.05), lab_mobile_application (1.88), lab_ios (4.55), rep_name_6 (1.41), rep_name_38 (1.35), sum_mobile_application ), sum_mobile (0,98), rep_name_39 (0,74), sum_resum_hide (0,88), rep_name_40 (0,81), lab_Duplication des postes vacants (0,76)
Architecture: sum_statistics_response (1.1), rep_name_41 (1.4), lab_graphics_views_and_responses_ vacancies (1.04), lab_creation_of vacancies (1.16), lab_quotas (1.0), sum_special offre (1.02), rep_name_42 (1.33) 1.01_01_01_01_10_10_ ), rep_name_43 (1.09), sum_dependent (0.83), sum_statistics (0.83), lab_responses_worker (0.76), sum_500ka (0.74)
Banque de salaires: lab_500 (1.18), lab_authorization (0.79), sum_500 (1.04), rep_name_44 (0.85), sum_500_site (1.03), lab_site (1.54), lab_visibility_resume (1.54), lab_price list (1.26), lab_setting_visibility_7_resume (resume) sum_error (0,79), lab_delivered_orders (1,33), rep_name_43 (0,74), sum_ie_11 (0,69), sum_500_error (0,66), sum2_site_ite (0,65)
Produits mobiles: lab_mobile_application (1.69), lab_backs (1.65), sum_hr_mobile (0.81), lab_applicant (0.88), lab_employer (0.84), sum_mobile (0.81), rep_name_45 (1.2), desc_d0 (0.87), rep_name_46 (1.rr), sum_h 0,79), sum_incorrect_search_work (0,61), desc_application (0,71), rep_name_47 (0,69), rep_name_28 (0,61), sum_work_search (0,59)
Pandora: sum_receive (2.68), desc_receive (1.72), lab_sms (1.59), sum_ letter (2.75), sum_notification_response (1.38), sum_password (1.52), lab_recover_password (1.52), lab_mail_mail (1.31, mail, boîte aux lettres (1.91) ), lab_mail (1.72), lab_mail (3.37), desc_mail (1.69), desc_mail (1.47), rep_name_6 (1.32)
Peppers: lab_saving_summary (1.43), sum_summing (2.02), sum_oron (1.57), sum_oron_vacancy (1.66), desc_resum (1.19), lab_summing (1.39), sum_code (1.2), lab_applicant (1.34), sum_index (1.47), sum_ ), lab_creation_summary (1.28), rep_name_45 (1.82), sum_civilness (1.47), sum_save_summum (1.18), lab_invital_index (1.13)
Recherche-1: sum2_poi_is_search (1.86), sum_loop (3.59), lab_questions_o_search (3.86), sum2_poi (1.86), desc_overs (2.49), lab_observing_summary (2.2), lab_observer (2.32), lab_loop (4.3oopropo_1) (1.62), sum_synonym (1.71), sum_sample (1.62), sum2_isk (1.58), sum2_is_isk (1.57), lab_auto-update_sum (1.57)
Recherche-2: rep_name_48 (1.13), desc_d1 (1.1), lab_premium_in_search (1.02), lab_views_of vacancies (1.4), sum_search (1.4), desc_d0 (1.2), lab_show_contacts (1.17), rep_name_49 (1.12950, lab13 (1.05), lab_search_of vacancies (1.62), lab_responses_and_invitations (1.61), sum_response (1.09), lab_selected_results (1.37), lab_filter_of_responses (1.08)
Superproduits: lab_contact_information (1.78), desc_address (1.46), rep_name_46 (1.84), sum_address (1.74), lab_selected_resumes (1.45), lab_reviews_worker (1.29), sum_right_shot (1.29), sum_right_range (1.29) ), sum_error_position (1.33), rep_name_42 (1.32), sum_quota (1.14), desc_address_office (1.14), rep_name_51 (1.09)
Les panneaux reflètent à peu près ce que font les équipes.
Utilisation du modèle
Sur ce point, la construction du modèle est terminée et il est possible de construire un programme sur sa base.
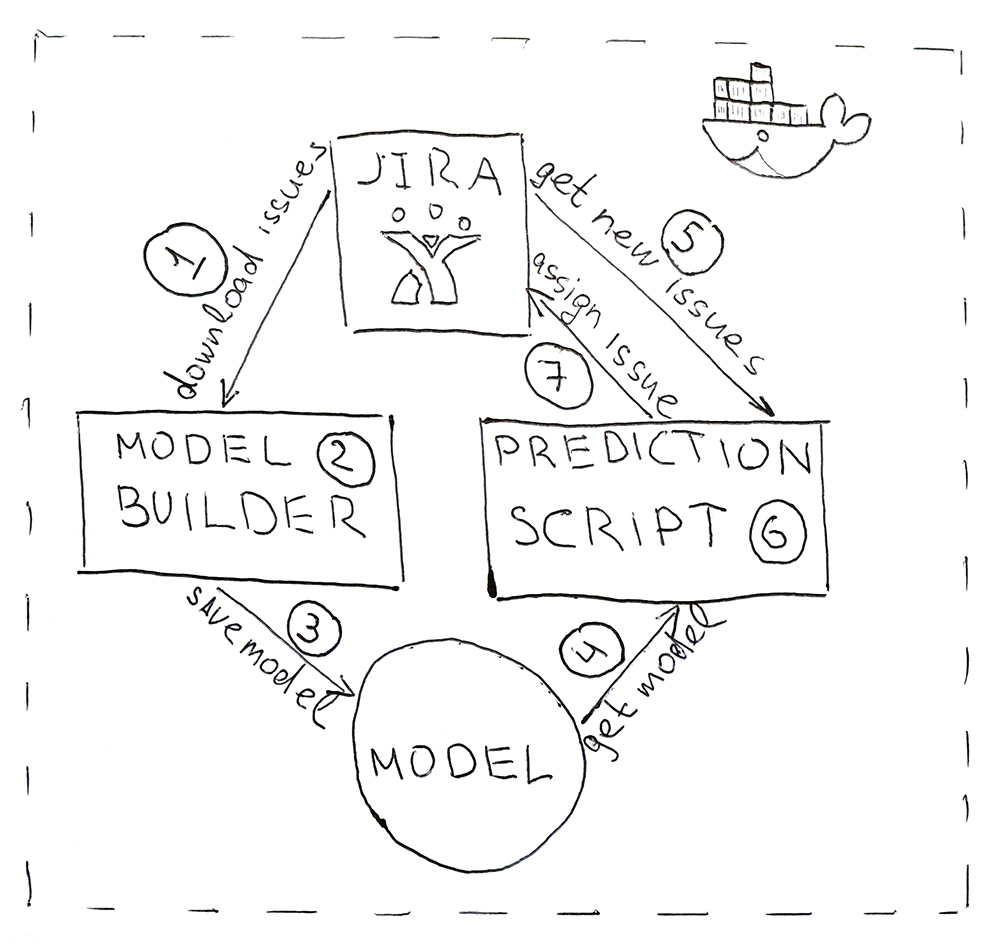
Le programme se compose de deux scripts Python. Le premier construit un modèle et le second fait des prédictions.
- Jira fournit une API grâce à laquelle vous pouvez télécharger des tâches déjà terminées (HHS). Une fois par jour, le script est lancé et les télécharge.
- Les données téléchargées sont converties en balises. Tout d'abord, les données sont battues pour la formation et les tests et soumises au modèle ML pour validation afin de garantir que la qualité ne commence pas à décliner du début au début. Et puis la deuxième fois, le modèle est formé sur toutes les données. L'ensemble du processus prend environ 10 minutes.
- Le modèle formé est enregistré sur le disque dur. J'ai utilisé l'utilitaire aneth pour sérialiser des objets. En plus du modèle lui-même, il est également nécessaire de sauvegarder tous les objets qui ont été utilisés pour obtenir les caractéristiques. Il s'agit d'obtenir des panneaux dans le même espace pour le nouveau HHS.
- dill , 5 .
- Jira HHS.
- , HHS — .
- Jira API. , , — .
, , Docker .
. 76% — , . , , , . ! Hourra!