Objectifs et exigences pour tester la "comptabilité 1C"
L'objectif principal des tests est de comparer le comportement du système 1C sur deux SGBD différents dans d'autres conditions identiques. C'est-à-dire la configuration des bases de données 1C et la population de données initiale doivent être les mêmes lors de chaque essai.
Les principaux paramètres à obtenir lors des tests:
- Le temps d'exécution de chaque test (supprimé par le Département Développement 1C)
- La charge sur le SGBD et l'environnement du serveur pendant le test est supprimée par les administrateurs du SGBD, ainsi que par l'environnement du serveur par les administrateurs système
Les tests du système 1C doivent être effectués en tenant compte de l'architecture client-serveur.Par conséquent, il est nécessaire d'émuler un utilisateur ou plusieurs utilisateurs dans le système en élaborant l'entrée d'informations dans l'interface et en stockant ces informations dans la base de données. Dans le même temps, il est nécessaire qu'une grande quantité d'informations périodiques soit publiée sur une longue période de temps pour créer des totaux dans les registres d'accumulation.
Pour effectuer les tests, un algorithme a été développé sous la forme d'un script pour les tests de script, pour la configuration de 1C Accounting 3.0, dans lequel l'entrée en série des données de test dans le système 1C est effectuée. Le script vous permet de spécifier divers paramètres pour les actions effectuées et la quantité de données de test. Description détaillée ci-dessous.
Description des paramètres et des caractéristiques des environnements testés
Chez Fortis, nous avons décidé de revérifier les résultats, notamment en utilisant le
test bien connu de
Gilev .
Nous avons également été encouragés à tester, notamment certaines publications sur les résultats des changements de performances lors de la transition de MS SQL Server à PostgreSQL. Tels que:
1C Battle: PostgreSQL 9.10 vs MS SQL 2016 .
Voici donc l'infrastructure de test:
Les serveurs pour MS SQL et PostgreSQL étaient virtuels et étaient exécutés alternativement pour le test souhaité. 1C se tenait sur un serveur distinct.
DétailsSpécifications de l'hyperviseur:Modèle: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 @ 2.40GHz (2 chaussettes * 16 CPU HT = 32CPU)
RAM: 212 Go
Système d'exploitation: VMWare ESXi 6.5
PowerProfile: performances
Sous-système de disque d'hyperviseur:Contrôleur: Adaptec 6805, Taille du cache: 512 Mo
Volume: RAID 10, 5,7 To
Taille de bande: 1024 Ko
Cache d'écriture: activé
Cache de lecture: désactivé
Roues: 6 pcs. HGST HUS726T6TAL,
Taille du secteur: 512 octets
Cache d'écriture: activé
PostgreSQL a été configuré comme suit:- postgresql.conf:
Les réglages de base ont été effectués à l'aide de la calculatrice - pgconfigurator.cybertec.at , les paramètres énormes_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost ont changé en fonction des informations reçues des sources mentionnées à la fin de la publication. La valeur du paramètre temp_buffers a augmenté, basée sur la suggestion que 1C utilise activement des tables temporaires:
listen_addresses = '*' max_connections = 1000
- Noyau, paramètres OS:
Les paramètres sont définis dans le format de fichier de profil pour le démon réglé:
[sysctl]
- Système de fichiers:
Tout le contenu du fichier postgresql.conf:
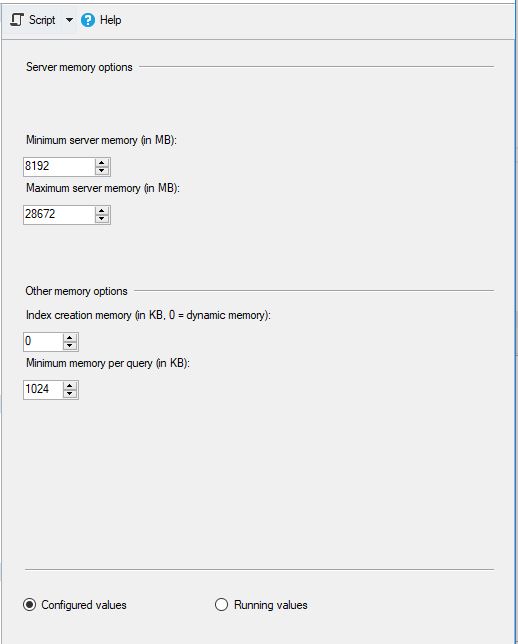
MS SQL a été configuré comme suit: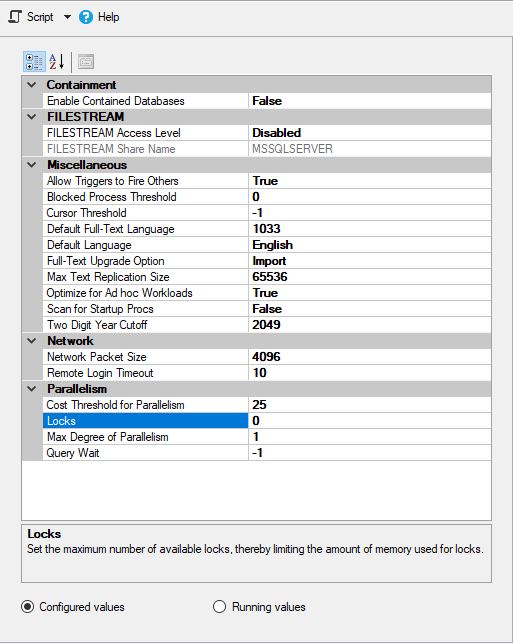
et
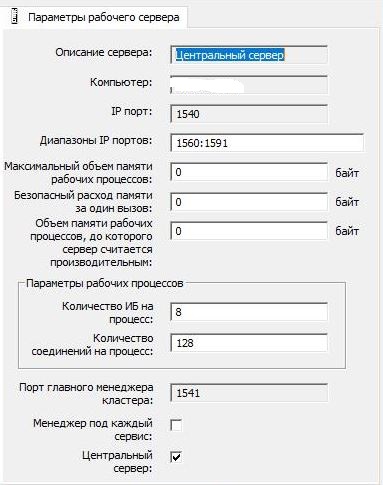
Les paramètres du cluster 1C sont restés standard:

et
Il n'y avait aucun programme antivirus sur les serveurs et rien de tiers n'a été installé.
Pour MS SQL, tempdb a été déplacé vers un lecteur logique distinct. Toutefois, les fichiers de données et les fichiers journaux de transactions des bases de données se trouvaient sur le même lecteur logique (c'est-à-dire que les fichiers de données et les journaux de transactions n'étaient pas divisés en lecteurs logiques distincts).
L'indexation des lecteurs dans Windows, où se trouvait MS SQL Server, a été désactivée sur tous les lecteurs logiques (comme c'est la coutume de le faire dans la plupart des cas dans les environnements prodovskih).
Description de l'algorithme principal du script pour les tests automatisésLa période d'essai principale estimée est de 1 an, au cours de laquelle des documents et des informations de référence sont créés pour chaque jour en fonction des paramètres spécifiés.
Chaque jour d'exécution, des blocs d'informations d'entrée et de sortie sont lancés:
- Bloc 1 "_" - "Réception de biens et services"
- Ouverture du répertoire des contreparties
- Un nouvel élément du répertoire «Contractors» est créé avec une vue de «Supplier»
- Un nouvel élément du répertoire «Contrats» est créé avec la vue «Avec fournisseur» pour une nouvelle contrepartie
- Le répertoire "Nomenclature" s'ouvre
- Un ensemble d'éléments du répertoire «Nomenclature» est créé avec le type «Produit»
- Un ensemble d'éléments du répertoire «Nomenclature» est créé avec le type «Service»
- La liste des documents «Réceptions de biens et services» s'ouvre.
- Un nouveau document «Entrée de biens et services» est créé dans lequel les parties tabulaires «Biens» et «Services» sont remplies avec les ensembles de données créés
- Le rapport «Account Card 41» est généré pour le mois en cours (si l'intervalle de formation supplémentaire est indiqué)
- Bloc 2 "_" - "Ventes de biens et services"
- Ouverture du répertoire des contreparties
- Un nouvel élément du répertoire «Contreparties» est créé avec la vue «Acheteur»
- Un nouvel élément du répertoire «Contrats» est créé avec la vue «Avec l'acheteur» pour une nouvelle contrepartie
- Une liste de documents «Ventes de biens et services» s'ouvre.
- Un nouveau document «Ventes de biens et services» est créé dans lequel les parties tabulaires «Biens» et «Services» sont remplies selon les paramètres spécifiés à partir des données précédemment créées
- Le rapport «Account Card 41» est généré pour le mois en cours (si l'intervalle de formation supplémentaire est indiqué)
- Le rapport «Carte de compte 41» pour le mois en cours est généré
A la fin de chaque mois au cours duquel la création des documents a été effectuée, des blocs d'entrée et de sortie d'informations sont effectués:
- Le rapport «Account Card 41» est généré du début de l'année à la fin du mois
- Le rapport «Bilan de Chiffre d'Affaires» est généré du début de l'année à la fin du mois
- La procédure de réglementation «Clôture du mois» est en cours.
Le résultat de l'exécution donne des informations sur la durée du test en heures, minutes, secondes et millisecondes.
Caractéristiques clés du script de test:- Possibilité de désactiver / activer des unités individuelles
- Possibilité de spécifier le nombre total de documents pour chacun des blocs
- Possibilité de spécifier le nombre de documents pour chaque bloc par jour
- Possibilité d'indiquer la quantité de biens et services dans les documents
- Possibilité de définir des listes d'indicateurs quantitatifs et de prix pour l'enregistrement. Sert à créer différents ensembles de valeurs dans les documents
Le plan de test de base pour chacune des bases de données:- "Le premier test." Sous un seul utilisateur, un petit nombre de documents avec des tableaux simples sont créés, des «fermetures mensuelles» sont formées
- — 20 . 1 . : 50 «», 50 «», 100 «», 50 «» + «», 50 «» + «», 2 « ». 1 1
- « ». ,
- — 50-60 . 3 . : 90 «», 90 «», 540 «», 90 «» + «», 90 «» + «», 3 « ». 3 3
- « ». . .
- — 40-60 . 2 . : 50 «», 50 «», 300 «», 50 «» + «», 50 «» + «». 3 3
:- , :
- « » « »
- 1 "*.dt"
- « »
Résultats
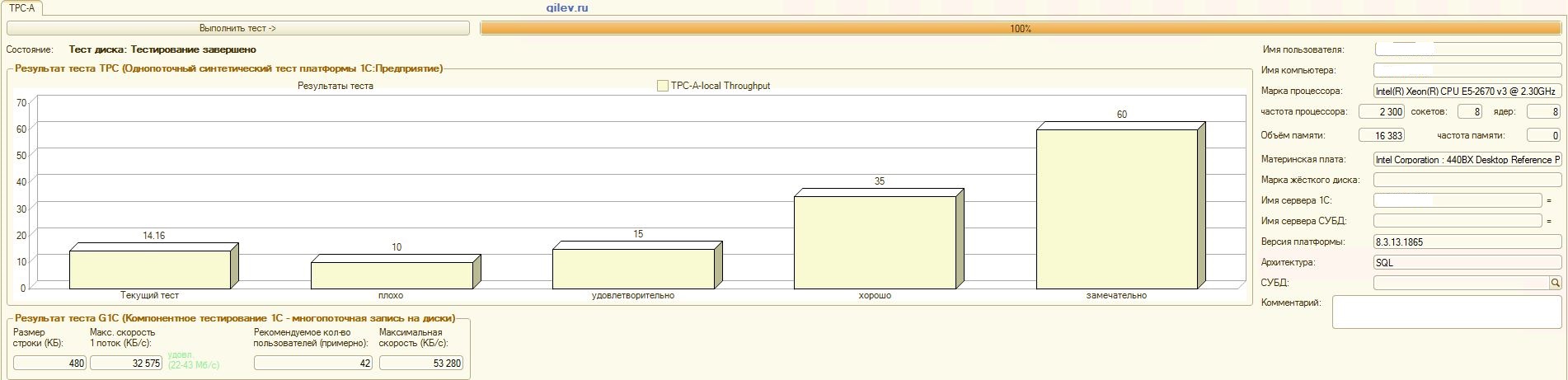
Et maintenant, les résultats les plus intéressants sur le SGBD MS SQL Server:Détails:
:
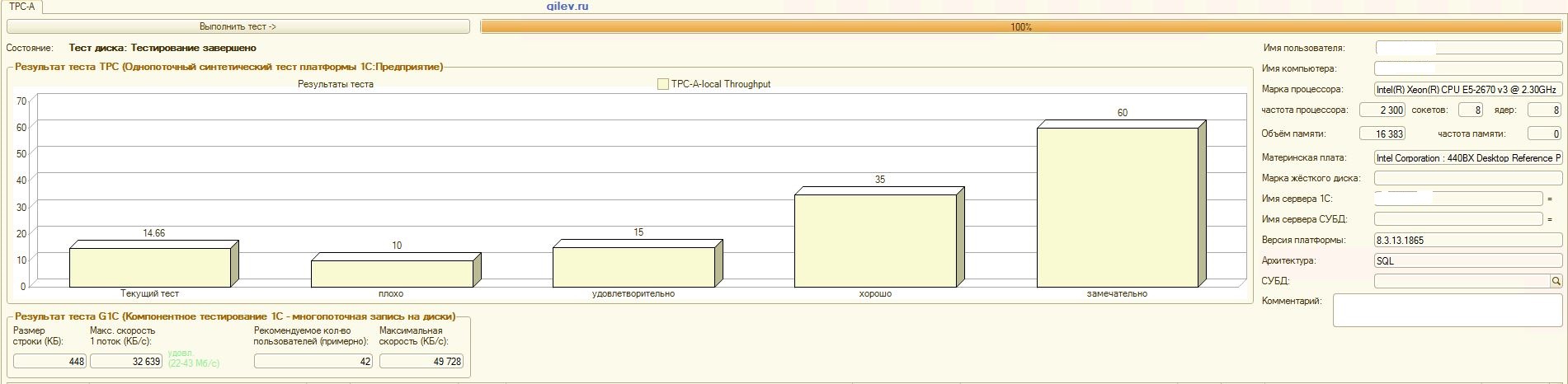
:

PostgreSQL,
, , , :
:
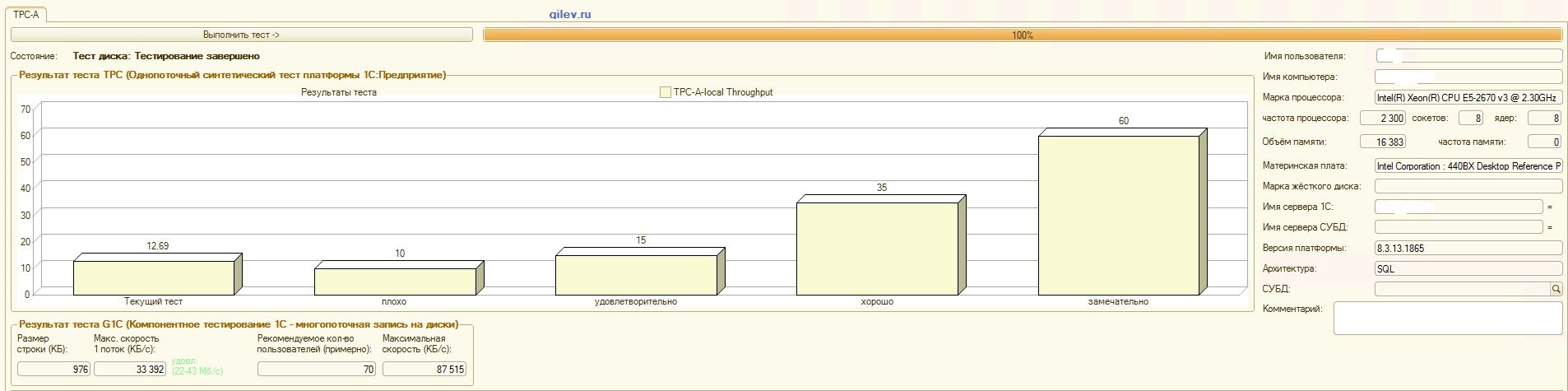
:
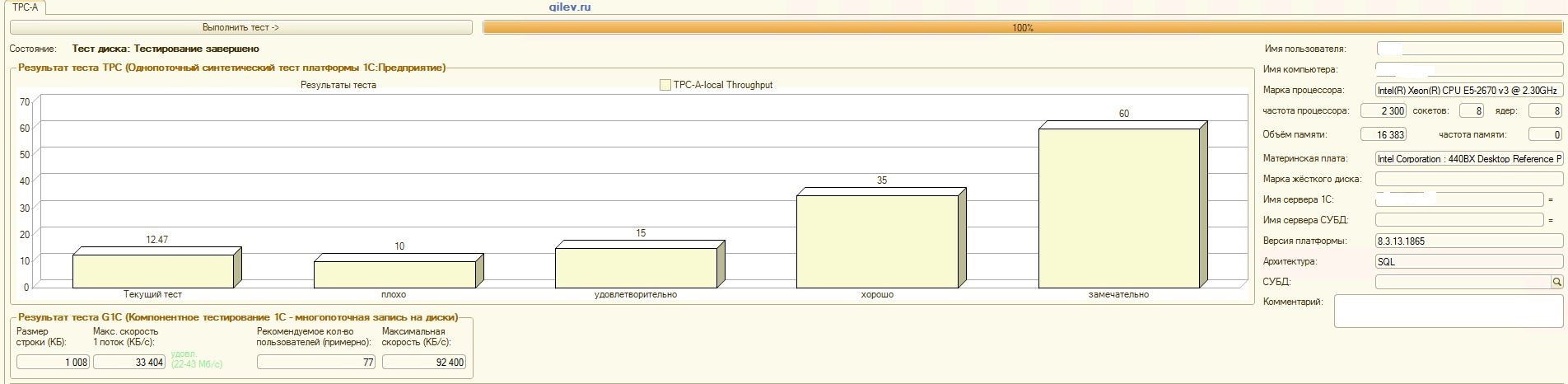
:

Test de Gilev:Comme le montrent les résultats, PostgreSQL a perdu en moyenne 14,82% des performances moyennes des SGBD MS SQL dans le test synthétique général . Cependant, selon les deux derniers indicateurs, PostgreSQL a montré un résultat nettement meilleur que MS SQL.Tests spécialisés pour la comptabilité 1C:Comme le montrent les résultats, 1C Accounting fonctionne à peu près de la même manière sur MS SQL et PostgreSQL avec les paramètres indiqués ci-dessus.Dans les deux cas, le SGBD a fonctionné de manière stable.Bien sûr, vous devrez peut-être un réglage plus subtil à la fois du SGBD et du système d'exploitation et du système de fichiers. Tout a été fait pendant la diffusion des publications, ce qui a indiqué qu'il y aurait une augmentation significative de la productivité ou à peu près la même lors du passage de MS SQL à PostgreSQL. De plus, lors de ces tests, un certain nombre de mesures ont été prises pour optimiser le système d'exploitation et le système de fichiers pour CentOS lui-même, qui sont décrits ci-dessus.Il convient de noter que le test Gilev a été exécuté plusieurs fois pour PostgreSQL - les meilleurs résultats sont donnés. Le test Gilev a été exécuté sur MS SQL 3 fois, de sorte qu'ils n'ont pas fait d'optimisation sur MS SQL. Toutes les tentatives ultérieures ont été d'amener l'éléphant aux métriques MS SQL.Après avoir atteint la différence optimale dans le test synthétique Gilev entre MS SQL et PostgreSQL, des tests spécialisés ont été effectués pour 1C Accounting, décrits ci-dessus.La conclusion générale est que, malgré la baisse significative des performances du test synthétique Gilev du SGBD PostgreSQL par rapport à MS SQL, avec les paramètres appropriés indiqués ci-dessus, 1C Accounting peut être installé sur MS SQL DBMS et PostgreSQL DBMS .Remarques
Il convient de noter tout de suite que cette analyse a été effectuée uniquement pour comparer les performances 1C dans différents SGBD.Cette analyse et cette conclusion ne sont correctes que pour 1C Accounting dans les conditions et versions logicielles décrites ci-dessus. Sur la base de l'analyse obtenue, il est impossible de conclure exactement ce qui se passera avec d'autres paramètres et versions de logiciel, ainsi qu'avec une configuration 1C différente.Cependant, le résultat du test Gilev suggère que sur toutes les configurations de 1C version 8.3 et ultérieures, avec des paramètres appropriés, le rabattement maximal des performances ne devrait pas dépasser 15% pour les SGBD PostgreSQL par rapport aux SGBD MS SQL. Il convient également de considérer que tout test détaillé pour une comparaison précise prend beaucoup de temps et de ressources. Sur cette base, nous pouvons faire une hypothèse plus probable que1C version 8.3 et versions ultérieures peuvent être migrées de MS SQL vers PostgreSQL avec une perte de performances maximale allant jusqu'à 15%. Il n'y avait pas d'obstacles objectifs à la transition, t à ces 15% peuvent ne pas apparaître, et en cas de leur manifestation, il suffit d'acheter un équipement un peu plus puissant si nécessaire.Il est également important de noter que les bases de données testées étaient petites, c'est-à-dire nettement inférieures à 100 Go en taille de données, et que le nombre maximal de threads s'exécutant simultanément était de 4. Cela signifie que pour les grandes bases de données dont la taille est nettement supérieure à 100 Go (par exemple, environ 1 To) , ainsi que pour les bases de données avec accès intensifs (dizaines et centaines de flux actifs simultanés), ces résultats peuvent être incorrects.Pour une analyse plus objective, il sera utile à l'avenir de comparer le développeur MS SQL Server 2019 et PostgreSQL 12 installés sur le même système d'exploitation CentOS, ainsi que lorsque MS SQL est installé sur la dernière version du système d'exploitation Windows Server. Maintenant, personne ne met PostgreSQL sur Windows, donc la baisse des performances des SGBD PostgreSQL sera très importante.Bien sûr, le test Gilev parle généralement de performances et pas seulement pour 1C. Cependant, pour le moment, il est trop tôt pour dire que le SGBD MS SQL sera toujours bien meilleur que le SGBD PostgreSQL, car il n'y a pas assez de faits. Pour confirmer ou infirmer cette affirmation, vous devez effectuer un certain nombre d'autres tests. Par exemple, pour .NET, vous devez écrire à la fois des actions atomiques et des tests complexes, les exécuter à plusieurs reprises et dans des conditions différentes, fixer le temps d'exécution et prendre la valeur moyenne. Comparez ensuite ces valeurs. Ce sera une analyse objective.Pour le moment, nous ne sommes pas prêts à mener une telle analyse, mais à l'avenir, il est tout à fait possible de la mener. Ensuite, nous écrirons plus en détail sous quelles opérations PostgreSQL est meilleur que MS SQL et combien en pourcentage, et où MS SQL est meilleur que PostgreSQL et combien en pourcentage.De plus, notre test n'a pas appliqué de méthodes d'optimisation pour MS SQL, qui sont décrites ici . Peut - être que cet article a juste oublié de désactiver l'indexation des disques Windows.Lors de la comparaison de deux SGBD, un autre point important doit être gardé à l'esprit: le SGBD PostgreSQL est gratuit et ouvert, tandis que le SGBD MS SQL est payant et a un code source fermé.Maintenant, aux dépens du test Gilev lui-même. En dehors des tests, les traces du test synthétique (le premier test) et de tous les autres tests ont été supprimées. Le premier test interroge principalement les opérations atomiques (insertion, mise à jour, suppression et lecture) et complexes (en référence à plusieurs tables, ainsi que la création, la modification et la suppression de tables dans la base de données) avec différentes quantités de données de traitement. Par conséquent, le test synthétique de Gilev peut être considéré comme assez objectif pour comparer les performances moyennes unifiées de deux environnements (y compris le SGBD) l'un par rapport à l'autre. Les valeurs absolues elles-mêmes ne disent rien, mais leur rapport de deux médias différents est assez objectif.Au détriment d'autres tests Gilev. La trace montre que le nombre maximum de threads était de 7, mais la conclusion sur le nombre d'utilisateurs était supérieure à 50. De plus, sur demande, il n'est pas entièrement clair comment les autres indicateurs sont calculés. Par conséquent, les autres tests ne sont pas objectifs et sont extrêmement variés et approximatifs. Seuls des tests spécialisés tenant compte des spécificités non seulement du système lui-même, mais également du travail des utilisateurs eux-mêmes donneront des valeurs plus précises.Remerciements
- effectué la configuration 1C et lancé les tests Gilev, et a également contribué de manière significative à la création de cette publication:
- Roman Buts - chef d'équipe 1C
- Alexander Gryaznov - programmeur 1C
- Collègues Fortis qui ont apporté une contribution significative à l'optimisation de l'optimisation pour CentOS, PostgreSQL, etc., mais qui souhaitaient rester incognito
Merci également à uaggster et BP1988 pour quelques conseils sur MS SQL et Windows.Postface
Une curieuse analyse a également été faite dans cet article .Et quels résultats avez-vous obtenus et comment avez-vous testé?Les sources