À propos de l'article
Ce message est une courte note conçue pour les programmeurs qui souhaitent en savoir plus sur la façon dont le GPU gère les branchements. Vous pouvez le considérer comme une introduction à ce sujet. Je recommande de commencer par [
1 ], [
2 ] et [
8 ] pour avoir une idée de l'apparence générale du modèle d'exécution GPU, car nous ne considérerons qu'un seul détail distinct. Pour les lecteurs curieux, il y a tous les liens à la fin de l'article. Si vous trouvez des erreurs, contactez-moi.
Table des matières
- À propos de l'article
- Table des matières
- Vocabulaire
- En quoi le noyau GPU est-il différent du noyau CPU?
- Qu'est-ce que la cohérence / divergence?
- Exemples de traitement de masque d'exécution
- ISA fictif
- AMD GCN ISA
- AVX512
- Comment faire face à l'écart?
- Les références
Vocabulaire
- GPU - Unité de traitement graphique, GPU
- Classification de Flynn
- SIMD - Données multiples à instruction unique, flux d'instructions unique, flux de données multiples
- SIMT - Une seule instruction, plusieurs threads, un seul flux d'instructions, plusieurs threads
- Wave (SIM) - un flux exécuté en mode SIMD
- Ligne (voie) - un flux de données distinct dans le modèle SIMD
- SMT - Multithreading simultané, multithreading simultané (Intel Hyper-threading) [ 2 ]
- Plusieurs threads partagent les principales ressources informatiques
- IMT - Multithreading entrelacé, multithreading alterné [ 2 ]
- Plusieurs threads partagent les ressources informatiques totales du noyau, mais un seul
- BB - Basic Block, un bloc de base - une séquence linéaire d'instructions avec un seul saut à la fin
- ILP - Parallélisme au niveau de l'instruction, parallélisme au niveau de l'instruction [ 3 ]
- ISA - Instruction Set Architecture, architecture du jeu d'instructions
Dans mon article, j'adhérerai à cette classification inventée. Cela ressemble grosso modo à l'organisation d'un GPU moderne.
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
Autres noms:
- Le noyau peut être appelé CU, SM, EU
- Une onde peut être appelée un front d'onde, un thread matériel (thread HW), une chaîne, un contexte
- Une ligne peut être appelée un thread de programme (thread SW)
En quoi le noyau GPU est-il différent du noyau CPU?
Toute génération actuelle de cœurs GPU est moins puissante que les processeurs centraux: simple ILP / multi-issue [
6 ] et prefetch [
5 ], pas de prévision ou prédiction de transitions / retours. Tout cela, avec de minuscules caches, libère une zone assez grande sur la puce, qui est remplie de nombreux cœurs. Les mécanismes de chargement / stockage de la mémoire sont capables de faire face à la largeur du canal d'un ordre de grandeur plus grand (cela ne s'applique pas aux GPU intégrés / mobiles) que les processeurs conventionnels, mais vous devez payer pour cela avec des latences élevées. Pour masquer la latence, le GPU utilise SMT [
2 ] - tandis qu'une vague est inactive, d'autres utilisent les ressources informatiques gratuites du noyau. Habituellement, le nombre d'ondes traitées par un cœur dépend des registres utilisés et est déterminé dynamiquement en allouant un fichier de registre fixe [
8 ]. La planification de l'exécution des instructions est hybride - dynamique-statique [
6 ] [
11 4.4]. Les noyaux SMT exécutés en mode SIMD atteignent des valeurs FLOPS élevées (opérations en virgule flottante par seconde, flops, nombre d'opérations en virgule flottante par seconde).
 Tableau de légende. Noir - inactif, blanc - actif, gris - éteint, bleu - inactif, rouge - en attenteFigure 1. Historique d'exécution 4: 2
Tableau de légende. Noir - inactif, blanc - actif, gris - éteint, bleu - inactif, rouge - en attenteFigure 1. Historique d'exécution 4: 2L'image montre l'historique du masque d'exécution, où l'axe x montre le temps allant de gauche à droite, et l'axe y montre l'identifiant de la ligne allant de haut en bas. Si vous ne comprenez toujours pas cela, revenez au dessin après avoir lu les sections suivantes.
Ceci est une illustration de la façon dont l'historique d'exécution du cœur du GPU peut ressembler dans une configuration fictive: quatre vagues partagent un échantillonneur et deux ALU. Le planificateur de vagues de chaque cycle émet deux instructions à partir de deux vagues. Lorsqu'une onde est inactive lors d'un accès à la mémoire ou d'une longue opération ALU, le planificateur passe à une autre paire d'ondes, en raison de laquelle l'ALU est constamment occupée à près de 100%.
Figure 2. Historique d'exécution 4: 1Un exemple avec la même charge, mais cette fois dans chaque cycle de l'instruction, une seule vague émet. Notez que le deuxième ALU est affamé.
Figure 3. Historique d'exécution 4: 4Cette fois, quatre instructions sont émises à chaque cycle. Notez qu'il y a trop de demandes à ALU, donc deux vagues attendent presque toujours (en fait, c'est une erreur de l'algorithme de planification).
Mise à jour Pour plus d'informations sur les difficultés de planification de l'exécution des instructions, voir [
12 ].
Dans le monde réel, les GPU ont différentes configurations de cœur: certains peuvent avoir jusqu'à 40 ondes par cœur et 4 ALU, d'autres ont 7 ondes fixes et 2 ALU. Tout cela dépend de nombreux facteurs et est déterminé grâce au processus minutieux de simulation d'architecture.
De plus, les vrais ALU SIMD peuvent avoir une largeur plus étroite que les ondes qu'ils servent, puis il faut plusieurs cycles pour traiter une instruction émise; le facteur est appelé la longueur "carillon" [
3 ].
Qu'est-ce que la cohérence / divergence?
Jetons un coup d'œil à l'extrait de code suivant:
Exemple 1
uint lane_id = get_lane_id(); if (lane_id & 1) {
Nous voyons ici un flux d'instructions dans lequel le chemin d'exécution dépend de l'identifiant de la ligne en cours d'exécution. De toute évidence, différentes lignes ont des significations différentes. Que va-t-il se passer? Il existe différentes approches pour résoudre ce problème [
4 ], mais au final, elles font toutes la même chose. Une telle approche est le masque d'exécution, que je couvrirai. Cette approche a été utilisée dans les GPU Nvidia avant Volta et dans les GPU AMD GCN. Le point principal du masque d'exécution est que nous stockons un peu pour chaque ligne de l'onde. Si le bit d'exécution de ligne correspondant est 0, aucun registre ne sera affecté pour l'instruction suivante émise. En fait, la ligne ne doit pas ressentir l'influence de l'ensemble de l'instruction exécutée, car son bit d'exécution est 0. Cela fonctionne comme suit: l'onde se déplace le long du graphique de flux de contrôle dans l'ordre de recherche de profondeur, sauvegardant l'historique des transitions sélectionnées jusqu'à ce que les bits soient définis. Je pense qu'il vaut mieux le montrer avec un exemple.
Supposons que nous ayons des vagues d'une largeur de 8. Voici à quoi ressemble le masque d'exécution pour le fragment de code:
Exemple 1. Historique du masque d'exécution
Considérons maintenant des exemples plus complexes:
Exemple 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
Exemple 3
uint lane_id = get_lane_id(); if (lane_id < 16) {
Vous remarquerez peut-être que l'histoire est nécessaire. Lors de l'utilisation de l'approche du masque d'exécution, l'équipement utilise généralement une sorte de pile. L'approche naïve consiste à stocker une pile de tuples (exec_mask, address) et à ajouter des instructions de convergence qui récupèrent le masque de la pile et modifient le pointeur d'instructions pour l'onde. Dans ce cas, l'onde aura suffisamment d'informations pour contourner l'intégralité du CFG pour chaque ligne.
En termes de performances, il suffit de quelques boucles pour traiter une instruction de flux de contrôle en raison de tout ce stockage de données. Et n'oubliez pas que la pile a une profondeur limitée.
Mettre à jour. Grâce à
@craigkolb, j'ai lu un article [
13 ], qui note que les instructions AMD GCN fork / join sélectionnent d'abord un chemin parmi moins de threads [
11 4.6], ce qui garantit que la profondeur de la pile de masques est égale à log2.
Mettre à jour. De toute évidence, il est presque toujours possible de tout incorporer dans un shader / structurer des CFG dans un shader, et donc de stocker tout l'historique des masques d'exécution dans des registres et de planifier le contournement / la convergence statique des CFG [
15 ]. Après avoir examiné le backend LLVM pour AMDGPU, je n'ai trouvé aucune preuve de gestion de pile constamment émise par le compilateur.
Prise en charge matérielle du masque d'exécution
Jetez maintenant un œil à ces graphiques de flux de contrôle de Wikipedia:
Figure 4. Certains types de graphiques de flux de contrôleQuel est l'ensemble minimal d'instructions de contrôle de masque dont nous avons besoin pour gérer tous les cas? Voici à quoi cela ressemble dans mon ISA artificiel avec parallélisation implicite, contrôle de masque explicite et synchronisation entièrement dynamique des conflits de données:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
Jetons un œil au cas d).
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
Je ne suis pas un spécialiste de l'analyse des flux de contrôle ou de la conception d'ISA, donc je suis sûr qu'il y a un cas où mon ISA artificiel ne sera pas en mesure de faire face, mais ce n'est pas important, car un CFG structuré devrait être suffisant pour tout le monde.
Mettre à jour. En savoir plus sur la prise en charge de GCN pour les instructions de flux de contrôle ici: [
11 ] ch.4, et sur l'implémentation de LLVM ici: [
15 ].
Conclusion:
- Divergence - la différence résultante dans les chemins choisis par différentes lignes de la même onde
- Cohérence - pas de divergence.
Exemples de traitement de masque d'exécution
ISA fictif
J'ai compilé les extraits de code précédents dans mon ISA artificiel et les ai exécutés sur un simulateur dans SIMD32. Découvrez comment il gère le masque d'exécution.
Mettre à jour. Notez qu'un simulateur artificiel choisit toujours le vrai chemin, et ce n'est pas la meilleure façon.
Exemple 1
 Figure 5. L'historique de l'exemple 1
Figure 5. L'historique de l'exemple 1Avez-vous remarqué une zone noire? Cette perte de temps. Certaines lignes attendent que d'autres terminent l'itération.
Exemple 2
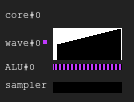 Figure 6. Historique de l'exemple 2
Figure 6. Historique de l'exemple 2Exemple 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 Figure 7. Historique de l'exemple 3
Figure 7. Historique de l'exemple 3AMD GCN ISA
Mettre à jour. GCN utilise également un traitement de masque explicite, plus d'informations à ce sujet ici: [
11 4.x]. J'ai décidé de montrer quelques exemples de leur ISA, grâce à l'
aire de jeux shader, c'est facile à faire. Peut-être qu'un jour je trouverai un simulateur et arriverai à obtenir des diagrammes.
Gardez à l'esprit que le compilateur est intelligent, vous pouvez donc obtenir d'autres résultats. J'ai essayé de tromper le compilateur pour qu'il n'optimise pas mes branches en y mettant des boucles de pointeur puis en nettoyant le code assembleur; Je ne suis pas un spécialiste GCN, donc quelques
nop importants pourraient être ignorés.
Notez également que les instructions S_CBRANCH_I / G_FORK et S_CBRANCH_JOIN ne sont pas utilisées dans ces fragments car elles sont simples et le compilateur ne les prend pas en charge. Par conséquent, malheureusement, il n'a pas été possible de considérer la pile de masques. Si vous savez comment effectuer le traitement de la pile des problèmes du compilateur, dites-le moi.
Mettre à jour. Consultez cet
exposé @ SiNGUL4RiTY sur l'implémentation d'un flux de contrôle vectorisé dans le backend LLVM utilisé par AMD.
Exemple 1
Exemple 2
Exemple 3
AVX512
Mettre à jour. @tom_forsyth m'a fait remarquer que l'extension AVX512 a également un traitement de masque explicite, alors voici quelques exemples. Plus de détails à ce sujet peuvent être trouvés dans [
14 ], 15.x et 15.6.1. Ce n'est pas exactement un GPU, mais il a toujours un vrai SIMD16 avec 32 bits. Les extraits de code ont été créés à l'aide du godbolt ISPC (–target = avx512knl-i32x16) et ont été fortement repensés, de sorte qu'ils peuvent ne pas être 100% vrais.
Exemple 1
Exemple 2
Exemple 3
Comment faire face à l'écart?
J'ai essayé de créer une illustration simple mais complète de la façon dont l'inefficacité résulte de la combinaison de lignes divergentes.
Imaginez un simple morceau de code:
uint thread_id = get_thread_id()
Créons 256 threads et mesurons leur temps d'exécution:
Figure 8. Durée des fils divergentsL'axe x est l'identifiant du flux de programme, l'axe y est les cycles d'horloge; différentes colonnes montrent combien de temps est perdu lors du regroupement de flux avec différentes longueurs d'onde par rapport à l'exécution monothread.
Le temps d'exécution de la vague est égal au temps d'exécution maximal parmi les lignes qu'il contient. Vous pouvez voir que les performances chutent déjà considérablement avec SIMD8, et une nouvelle expansion ne fait qu'aggraver les choses.
Figure 9. Durée d'exécution des threads cohérentsLes mêmes colonnes sont représentées sur cette figure, mais cette fois le nombre d'itérations est trié par identificateurs de flux, c'est-à-dire que les flux avec un nombre similaire d'itérations sont transmis à une seule onde.
Pour cet exemple, l'exécution est potentiellement accélérée d'environ la moitié.
Bien sûr, l'exemple est trop simple, mais j'espère que vous comprenez le point: la divergence à l'exécution découle de la divergence des données, donc les CFG doivent être simples et les données cohérentes.
Par exemple, si vous écrivez un traceur de rayons, il peut être avantageux de regrouper les rayons avec la même direction et la même position, car ils passeront très probablement par les mêmes nœuds dans le BVH. Voir [
10 ] et d'autres articles connexes pour plus de détails.
Il convient également de mentionner qu'il existe des techniques pour traiter les écarts au niveau du matériel, par exemple, Dynamic Warp Formation [
7 ] et l'exécution prévue pour les petites branches.
Les références
[1]
Un voyage à travers le pipeline graphique[2]
Kayvon Fatahalian: INFORMATIQUE PARALLÈLE[3]
L'architecture informatique: une approche quantitative[4]
Reconvergence SIMT sans pile à faible coût[5]
Dissection de la hiérarchie de la mémoire GPU par le biais de micro-benchmarking[6]
Dissection de l'architecture GPU NVIDIA Volta via le micro-benchmarking[7]
Formation et planification de distorsion dynamique pour un flux de contrôle GPU efficace[8]
Maurizio Cerrato: Architectures GPU[9]
Simulateur GPU jouet[10]
Réduire la divergence des branches dans les programmes GPU[11]
Architecture du jeu d'instructions «Vega»[12]
Joshua Barczak: Simulation de l'exécution d'un shader pour GCN[13]
Vecteur tangent: une digression sur la divergence[14]
Intel 64 et IA-32 ArchitecturesSoftware Developer's Manual[15]
Vectorisation du flux de contrôle divergent pour les applications SIMD