Salut, Khabrovites! La traduction de l'article suivant a été préparée spécialement pour les étudiants du cours sur la
plate-forme d'infrastructure basée sur Kubernetes , qui commencera les cours demain. Commençons.

Autoscaling dans Kubernetes
La mise à l'échelle automatique vous permet d'augmenter et de réduire automatiquement les charges de travail en fonction de l'utilisation des ressources.
La mise à l'échelle automatique de Kubernetes a deux dimensions:
- Cluster Autoscaler, qui est responsable de la mise à l'échelle des nœuds;
- Horizontal Pod Autoscaler (HPA), qui met automatiquement à l'échelle le nombre de foyers dans un ensemble de déploiement ou de réplique.
La mise à l'échelle automatique de cluster peut être utilisée conjointement avec la mise à l'échelle automatique du foyer horizontal pour contrôler dynamiquement les ressources informatiques et le degré de concurrence système requis pour se conformer aux accords de niveau de service (SLA).
La mise à l'échelle automatique du cluster dépend fortement des capacités du fournisseur d'infrastructure cloud hébergeant le cluster, et HPA peut fonctionner indépendamment du fournisseur IaaS / PaaS.
Développement HPA
La mise à l'échelle automatique du foyer horizontal a subi des changements majeurs depuis l'introduction de Kubernetes v1.1. La première version des foyers à échelle HPA basée sur la consommation mesurée du processeur, puis sur l'utilisation de la mémoire. Kubernetes 1.6 a introduit une nouvelle API appelée métriques personnalisées, qui a fourni un accès HPA aux métriques personnalisées. Kubernetes 1.7 a ajouté un niveau d'agrégation qui permet aux applications tierces d'étendre l'API Kubernetes en s'enregistrant en tant que modules complémentaires d'API.
Grâce à l'API Custom Metrics et au niveau d'agrégation, les systèmes de surveillance tels que Prometheus peuvent fournir des mesures spécifiques à l'application au contrôleur HPA.
La mise à l'échelle automatique du foyer horizontal est implémentée sous la forme d'une boucle de contrôle qui interroge périodiquement l'API de mesure des ressources (API de mesure des ressources) pour des mesures clés, telles que l'utilisation du processeur et de la mémoire, et l'API de mesures personnalisées (API de mesures personnalisées) pour des mesures d'application spécifiques.
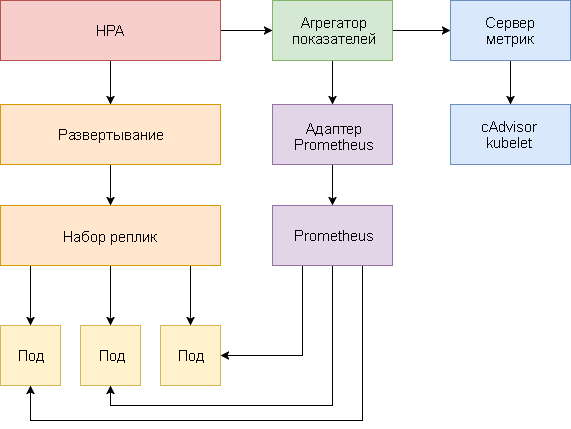
Vous trouverez ci-dessous un guide étape par étape pour configurer HPA v2 pour Kubernetes 1.9 et versions ultérieures.
- Installez le complément Metrics Server, qui fournit des mesures clés.
- Lancez une application de démonstration pour voir comment fonctionne la mise à l'échelle automatique du foyer en fonction de l'utilisation du processeur et de la mémoire.
- Déployez Prometheus et le serveur d'API personnalisé. Enregistrez un serveur API personnalisé au niveau d'agrégation.
- Configurez HPA à l'aide de mesures personnalisées fournies par l'application de démonstration.
Avant de commencer, vous devez installer Go version 1.8 (ou ultérieure) et cloner le
référentiel k8s-prom-hpa dans
GOPATH :
cd $GOPATH git clone https:
1. Configuration du serveur de métriques
Kubernetes
Metric Server est l'agrégateur de données d'utilisation des ressources intra-cluster qui remplace
Heapster . Le serveur de métriques collecte des informations d'utilisation du processeur et de la mémoire pour les nœuds et les foyers à partir de
kubernetes.summary_api . L'API récapitulative est une API à faible consommation de mémoire pour transmettre des métriques de données Kubelet / cAdvisor à un serveur.
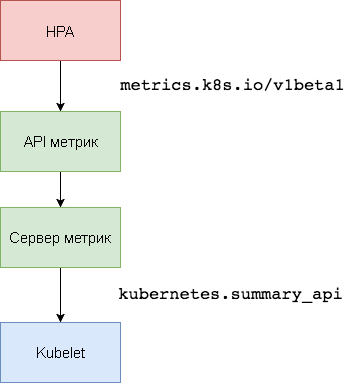
Dans la première version de HPA, un agrégateur Heapster était nécessaire pour obtenir le CPU et la mémoire. Dans HPA v2 et Kubernetes 1.8, seul un serveur métrique est requis avec
horizontal-pod-autoscaler-use-rest-clients activés. Cette option est activée par défaut dans Kubernetes 1.9. GKE 1.9 est livré avec un serveur de métriques préinstallé.
Développez le serveur de métriques dans l'espace de noms
kube-system :
kubectl create -f ./metrics-server
Après 1 minute, le
metric-server commencera à transmettre des données sur le CPU et l'utilisation de la mémoire par les nœuds et les pods.
Afficher les métriques du nœud:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
Afficher les indicateurs de fréquence cardiaque:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. Mise à l'échelle automatique basée sur l'utilisation du processeur et de la mémoire
Pour tester l'auto-scaling horizontal du foyer (HPA), vous pouvez utiliser une petite application Web basée sur Golang.
Développez
podinfo dans l'espace de noms
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
Contactez
podinfo utilisant le service NodePort à
http://<K8S_PUBLIC_IP>:31198 .
Spécifiez un HPA qui servira au moins deux répliques et évoluera jusqu'à dix répliques si l'utilisation moyenne du processeur dépasse 80% ou si la consommation de mémoire est supérieure à 200 Mio:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
Créer HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
Après quelques secondes, le contrôleur HPA contactera le serveur métrique et recevra des informations sur l'utilisation du processeur et de la mémoire:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
Pour augmenter l'utilisation du processeur, effectuez un test de charge avec rakyll / hey:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
Vous pouvez surveiller les événements HPA comme suit:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Supprimez podinfo temporairement (vous devrez le redéployer dans l'une des prochaines étapes de ce guide).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. Configuration du serveur de métriques personnalisées
Pour une mise à l'échelle basée sur des mesures personnalisées, deux composants sont nécessaires. La première - la base de données de séries chronologiques
Prometheus - recueille les mesures d'application et les enregistre. Le deuxième composant, l'
adaptateur k8s-prometheus , complète l'API Custom Metrics Kubernetes avec des métriques fournies par le constructeur.
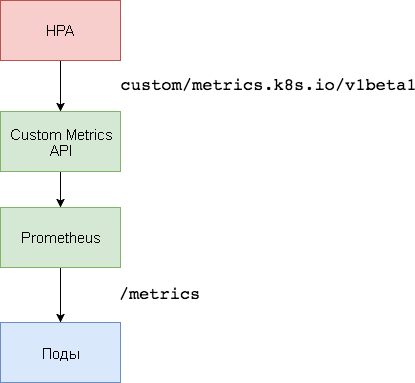
Un espace de noms dédié est utilisé pour déployer Prometheus et l'adaptateur.
Créez un espace de noms de
monitoring :
kubectl create -f ./namespaces.yaml
Développez Prometheus v2 dans l'espace de noms de
monitoring :
kubectl create -f ./prometheus
Générez les certificats TLS requis pour l'adaptateur Prometheus:
make certs
Déployez l'adaptateur Prometheus pour l'API de métriques personnalisées:
kubectl create -f ./custom-metrics-api
Obtenez une liste des mesures spéciales fournies par Prometheus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
Ensuite, extrayez les données d'utilisation du système de fichiers pour tous les pods dans l'espace de noms de
monitoring :
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. Mise à l'échelle automatique basée sur des mesures personnalisées
Créez le service podinfo
podinfo et déployez-le dans l'espace de noms
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
L'application
podinfo passera la métrique spéciale
http_requests_total . L'adaptateur Prometheus supprimera le suffixe
_total et marquera cette métrique comme compteur.
Obtenez le nombre total de requêtes par seconde à partir de l'API Custom Metrics:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
La lettre
m signifie
milli-units , donc, par exemple,
901m est 901 milliseconde.
Créez un HPA qui étendra le déploiement de podinfo si le nombre de demandes dépasse 10 demandes par seconde:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
Développez HPA
podinfo dans l'espace de noms
default :
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
Après quelques secondes, le HPA obtiendra la valeur
http_requests de l'API métrique:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
Appliquez la charge pour le service podinfo avec 25 requêtes par seconde:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
Après quelques minutes, le HPA commencera à dimensionner le déploiement:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Avec le nombre actuel de requêtes par seconde, le déploiement n'atteindra jamais un maximum de 10 pods. Trois répliques suffisent pour que le nombre de requêtes par seconde pour chaque pod soit inférieur à 10.
Une fois les tests de charge terminés, HPA réduira l'échelle de déploiement au nombre initial de répliques:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Vous avez peut-être remarqué que l'auto-scaler ne répond pas immédiatement aux changements de métriques. Par défaut, ils sont synchronisés toutes les 30 secondes. En outre, la mise à l'échelle se produit uniquement s'il n'y a pas eu d'augmentation ou de diminution de la charge de travail au cours des 3 à 5 dernières minutes. Cela permet d'éviter les décisions conflictuelles et laisse le temps de connecter l'auto-scaler du cluster.
Conclusion
Tous les systèmes ne peuvent pas appliquer la conformité SLA basée uniquement sur l'utilisation du processeur ou de la mémoire (ou les deux). La plupart des serveurs Web et des serveurs mobiles pour gérer les pics de trafic nécessitent une mise à l'échelle automatique en fonction du nombre de demandes par seconde.
Pour les applications ETL (à partir de Eng. Extract Transform Load - «extraction, transformation, chargement»), la mise à l'échelle automatique peut être déclenchée, par exemple, lorsque la longueur de seuil spécifiée de la file d'attente des travaux est dépassée.
Dans tous les cas, l'instrumentation des applications à l'aide de Prometheus et la mise en évidence des indicateurs nécessaires à la mise à l'échelle automatique vous permettent d'affiner les applications pour améliorer le traitement des pics de trafic et assurer une haute disponibilité de l'infrastructure.
Des idées, des questions, des commentaires? Rejoignez la discussion à
Slack !
Voici un tel matériau. Nous attendons vos commentaires et à bientôt sur le
parcours !