
Salut, habrozhiteli! Ce livre convient à tout développeur qui souhaite comprendre le traitement en streaming. Comprendre la programmation distribuée vous aidera à mieux comprendre Kafka et Kafka Streams. Ce serait bien de connaître le framework Kafka lui-même, mais ce n'est pas nécessaire: je vais vous dire tout ce dont vous avez besoin. Grâce à ce livre, les développeurs Kafka expérimentés, comme les novices, apprendront à créer des applications de streaming intéressantes à l'aide de la bibliothèque Kafka Streams. Les développeurs Java intermédiaires et de haut niveau familiarisés avec des concepts tels que la sérialisation apprendront à appliquer leurs compétences pour créer des applications Kafka Streams. Le code source du livre est écrit en Java 8 et utilise essentiellement la syntaxe des expressions lambda de Java 8, donc la possibilité de travailler avec des fonctions lambda (même dans un autre langage de programmation) vous est utile.
Extrait. 5.3. Opérations d'agrégation et de fenêtres
Dans cette section, nous passons aux parties les plus prometteuses de Kafka Streams. Jusqu'à présent, nous avons couvert les aspects suivants des flux Kafka:
- créer une topologie de traitement;
- utilisation de l'état dans les applications de streaming;
- établir des connexions de flux de données;
- différences entre les flux d'événements (KStream) et les flux de mise à jour (KTable).
Dans les exemples suivants, nous allons rassembler tous ces éléments. De plus, vous serez initié aux opérations sur les fenêtres - une autre grande fonctionnalité des applications de streaming. Notre premier exemple sera l'agrégation simple.
5.3.1. Agrégation des ventes d'actions par industrie
L'agrégation et le regroupement sont des outils essentiels pour travailler avec des données en streaming. L'examen des dossiers individuels sur une base d'admission n'est souvent pas suffisant. Pour extraire des informations supplémentaires des données, leur regroupement et leur combinaison sont nécessaires.
Dans cet exemple, vous devez essayer la combinaison d'un trader intrajournalier qui doit suivre le volume des ventes d'actions de sociétés dans plusieurs secteurs. En particulier, vous vous intéressez aux cinq sociétés qui réalisent les plus grandes parts de ventes dans chaque industrie.
Pour une telle agrégation, vous aurez besoin de plusieurs des étapes suivantes pour traduire les données sous la forme souhaitée (en termes généraux).
- Créez une source thématique qui publie des informations brutes sur les transactions boursières. Nous devrons mapper un objet de type StockTransaction à un objet de type ShareVolume. Le fait est que l'objet StockTransaction contient des métadonnées de vente, et nous n'avons besoin que de données sur le nombre d'actions vendues.
- Groupez les données de volume de partage par symboles boursiers. Après avoir regroupé par symboles, vous pouvez réduire ces données en sous-totaux des ventes d'actions. Il convient de noter que la méthode KStream.groupBy renvoie une instance de type KGroupedStream. Et vous pouvez obtenir une instance de KTable en appelant la méthode KGroupedStream.reduce plus tard.
Qu'est-ce que l'interface KGroupedStream
Les méthodes KStream.groupBy et KStream.groupByKey renvoient une instance de KGroupedStream. KGroupedStream est une représentation intermédiaire du flux d'événements après regroupement par clé. Il n'est pas du tout destiné à fonctionner directement avec lui. Au lieu de cela, KGroupedStream est utilisé pour les opérations d'agrégation, dont le résultat est toujours KTable. Et comme le résultat des opérations d'agrégation est KTable et qu'elles utilisent le stockage d'état, il est possible que toutes les mises à jour en conséquence ne soient pas envoyées plus loin dans le pipeline.
La méthode KTable.groupBy renvoie un KGroupedTable similaire - une représentation intermédiaire du flux de mises à jour regroupées par clé.
Prenons une courte pause et regardons la fig. 5.9, qui montre ce que nous avons accompli. Cette topologie devrait déjà vous être familière.
Voyons maintenant le code de cette topologie (il se trouve dans le fichier src / main / java / bbejeck / chapter_5 / AggregationsAndReducingExample.java) (Listing 5.2).
Le code donné diffère par sa brièveté et un grand volume d'actions effectuées sur plusieurs lignes. Dans le premier paramètre de la méthode builder.stream, vous pouvez remarquer quelque chose de nouveau par vous-même: la valeur du type énuméré AutoOffsetReset.EARLIEST (il existe également LATEST), définie à l'aide de la méthode Consumed.withOffsetResetPolicy. En utilisant ce type énuméré, vous pouvez spécifier une stratégie de réinitialisation des décalages pour chacun de KStream ou KTable; il a priorité sur le paramètre de réinitialisation des décalages de la configuration.
GroupByKey et GroupBy
L'interface KStream propose deux méthodes de regroupement des enregistrements: GroupByKey et GroupBy. Les deux renvoient KGroupedTable, vous pourriez donc avoir une question légitime: quelle est la différence entre eux et quand utiliser lequel?
La méthode GroupByKey est utilisée lorsque les clés de KStream sont déjà non vides. Et surtout, l'indicateur «nécessite une nouvelle partition» n'a jamais été défini.
La méthode GroupBy suppose que vous avez modifié les clés de regroupement, donc l'indicateur de re-partitionnement est défini sur true. Effectuer des connexions, des agrégations, etc. après la méthode GroupBy entraînera un re-partitionnement automatique.
Résumé: Vous devez utiliser GroupByKey plutôt que GroupBy dans la mesure du possible.
Ce que font les méthodes mapValues et groupBy est compréhensible, alors jetez un œil à la méthode sum () (elle se trouve dans le fichier src / main / java / bbejeck / model / ShareVolume.java) (Listing 5.3).
La méthode ShareVolume.sum renvoie le sous-total du volume des ventes d'actions et le résultat de toute la chaîne de calcul est un objet KTable <String, ShareVolume>. Vous comprenez maintenant quel rôle joue KTable. Lorsque les objets ShareVolume arrivent, la dernière mise à jour actuelle est enregistrée dans le KTable correspondant. Il est important de ne pas oublier que toutes les mises à jour sont reflétées dans le précédent shareVolumeKTable, mais toutes ne sont pas envoyées plus loin.
De plus, avec l'aide de ce tableau, nous effectuons une agrégation (par le nombre d'actions vendues) afin d'obtenir les cinq sociétés avec les ventes d'actions les plus élevées dans chaque industrie. Nos actions dans ce cas seront similaires aux actions lors de la première agrégation.
- Effectuez une autre opération groupBy pour regrouper des objets ShareVolume individuels par secteur.
- Passez à résumer les objets ShareVolume. Cette fois, l'objet d'agrégation est une file d'attente prioritaire de taille fixe. Seules cinq sociétés avec le plus grand nombre d'actions vendues sont conservées dans une telle file d'attente de taille fixe.
- Affichez les lignes du paragraphe précédent dans une valeur de chaîne et retournez les cinq meilleures ventes par le nombre d'actions par industrie.
- Écrivez les résultats sous forme de chaîne dans la rubrique.
Dans la fig. 5.10 montre un graphique de la topologie du mouvement des données. Comme vous pouvez le voir, le deuxième cycle de traitement est assez simple.
Maintenant, après avoir bien compris la structure de ce deuxième cycle de traitement, vous pouvez vous référer à son code source (vous le trouverez dans le fichier src / main / java / bbejeck / chapter_5 / AggregationsAndReducingExample.java) (Listing 5.4).
Il existe une variable fixedQueue dans cet initialiseur. Il s'agit d'un objet personnalisé - un adaptateur pour java.util.TreeSet, qui est utilisé pour suivre les résultats les plus élevés dans l'ordre décroissant du nombre de parts vendues.
Vous avez déjà rencontré des appels à groupBy et mapValues, nous ne nous arrêterons donc pas sur eux (nous appelons la méthode KTable.toStream, car la méthode KTable.print est déconseillée). Mais vous n'avez pas encore vu la version KTable de la méthode d'agrégat (), nous allons donc passer un peu de temps à en discuter.
Comme vous vous en souvenez, KTable se distingue par le fait que les enregistrements avec les mêmes clés sont considérés comme des mises à jour. KTable remplace l'ancien enregistrement par le nouveau. L'agrégation se déroule de la même manière: les derniers enregistrements avec une clé sont agrégés. Lorsqu'un enregistrement arrive, il est ajouté à une instance de la classe FixedSizePriorityQueue à l'aide d'un additionneur (le deuxième paramètre de l'appel à la méthode d'agrégation), mais si un autre enregistrement avec la même clé existe déjà, l'ancien enregistrement est supprimé à l'aide du soustracteur (le troisième paramètre de l'appel à la méthode d'agrégation).
Cela signifie que notre agrégateur, FixedSizePriorityQueue, n'agrège pas toutes les valeurs avec une seule clé, mais stocke la somme mobile des quantités N des types de stocks les plus vendus. Chaque entrée contient le nombre total d'actions vendues jusqu'à présent. KTable vous fournira des informations sur les actions des sociétés qui sont actuellement les plus vendues; l'agrégation continue de chaque mise à jour n'est pas requise.
Nous avons appris à faire deux choses importantes:
- regrouper les valeurs dans KTable par une clé qui leur est commune;
- Effectuez des opérations utiles telles que la convolution et l'agrégation sur ces valeurs groupées.
La capacité d'effectuer ces opérations est importante pour comprendre la signification des données qui transitent par l'application Kafka Streams et déterminer quelles informations elles contiennent.
Nous avons également rassemblé certains des concepts clés discutés plus haut dans ce livre. Au chapitre 4, nous avons parlé de l'importance d'un état local à sécurité intégrée pour une application de streaming. Le premier exemple de ce chapitre a montré pourquoi l'État local est si important - il permet de suivre les informations que vous avez déjà vues. L'accès local évite les retards réseau, rendant l'application plus productive et résistante aux erreurs.
Lorsque vous effectuez une opération de convolution ou d'agrégation, vous devez spécifier le nom du magasin d'état. Les opérations de convolution et d'agrégation renvoient une instance de KTable, et KTable utilise un magasin d'état pour remplacer les anciens résultats par de nouveaux. Comme vous l'avez vu, toutes les mises à jour ne sont pas envoyées plus loin dans le pipeline, ce qui est important, car les opérations d'agrégation sont conçues pour obtenir les informations finales. Si l'état local n'est pas appliqué, KTable enverra en outre tous les résultats d'agrégation et de convolution.
Ensuite, nous examinons l'exécution d'opérations telles que l'agrégation, dans une période de temps spécifique - les opérations dites de fenêtrage.
5.3.2. Opérations de fenêtre
Dans la section précédente, nous avons introduit la convolution et l'agrégation «roulante». L'application a effectué une convolution continue des ventes d'actions avec l'agrégation subséquente des cinq actions les plus vendues.
Parfois, une telle agrégation continue et convolution des résultats est nécessaire. Et parfois, vous devez effectuer des opérations uniquement sur une période de temps donnée. Par exemple, calculez combien de transactions boursières ont été effectuées avec des actions d'une entreprise particulière au cours des 10 dernières minutes. Ou combien d'utilisateurs ont cliqué sur une nouvelle bannière publicitaire au cours des 15 dernières minutes. Une application peut effectuer de telles opérations plusieurs fois, mais avec des résultats liés uniquement à des intervalles de temps spécifiés (fenêtres de temps).
Comptage des transactions d'échange par acheteur
Dans l'exemple suivant, nous serons engagés dans le suivi des transactions de change pour plusieurs commerçants - soit de grandes organisations, soit de simples financiers intelligents.
Il y a deux raisons possibles à ce suivi. L'un d'eux est la nécessité de savoir ce que les leaders du marché achètent / vendent. Si ces grands acteurs et investisseurs avertis voient des opportunités par eux-mêmes, il est logique de suivre leur stratégie. La deuxième raison est le désir de remarquer tout signe possible de transactions illégales utilisant des informations privilégiées. Pour ce faire, vous devrez analyser la corrélation des fortes hausses des ventes avec les communiqués de presse importants.
Un tel suivi comprend des étapes telles que:
- créer un flux pour la lecture du sujet des transactions boursières;
- regroupement des enregistrements entrants par ID client et symbole boursier du stock. Un appel à la méthode groupBy renvoie une instance de la classe KGroupedStream;
- KGroupedStream.windowedBy renvoie un flux de données délimité par une fenêtre temporaire, qui permet l'agrégation de fenêtres. Selon le type de fenêtre, TimeWindowedKStream ou SessionWindowedKStream est renvoyé;
- Comptage des transactions pour une opération d'agrégation. Le flux de données de fenêtre détermine si un enregistrement particulier est pris en compte dans ce calcul;
- écrire des résultats dans une rubrique ou les afficher sur la console pendant le développement.
La topologie de cette application est simple, mais son image visuelle ne fait pas de mal. Jetez un oeil à la photo. 5.11.
De plus, nous considérerons la fonctionnalité des opérations de fenêtre et le code correspondant.
Types de fenêtres
Il existe trois types de fenêtres dans Kafka Streams:
- session
- Tumbling (tumbling);
- glissement / "saut" (glissement / saut).
Le choix dépend des besoins de l'entreprise. Les fenêtres "Tumbling" et "jumping" sont limitées dans le temps, tandis que les restrictions de session sont associées aux actions de l'utilisateur - la durée de la ou des sessions est déterminée uniquement par le comportement actif de l'utilisateur. L'essentiel est de ne pas oublier que tous les types de fenêtres sont basés sur les horodatages des enregistrements et non sur l'heure système.
Ensuite, nous implémentons notre topologie avec chacun des types de fenêtres. Le code complet ne sera donné que dans le premier exemple, rien ne changera pour les autres types de fenêtres, à l'exception du type d'opération de fenêtre.
Fenêtres de session
Les fenêtres de session sont très différentes de tous les autres types de fenêtres. Ils sont limités non pas tant par le temps que par l'activité de l'utilisateur (ou l'activité de l'entité que vous souhaitez suivre). Les fenêtres de session sont délimitées par des périodes d'inactivité.
La figure 5.12 illustre le concept des fenêtres de session. Une session plus petite fusionnera avec la session à sa gauche. Et la session de droite sera séparée, car elle suit une longue période d'inactivité. Les fenêtres de session sont basées sur les actions de l'utilisateur, mais appliquent des horodatages à partir des enregistrements pour déterminer à quelle session l'enregistrement appartient.
Utilisation des fenêtres de session pour suivre les transactions Exchange
Nous utiliserons des fenêtres de session pour capturer des informations sur les transactions d'échange. L'implémentation des fenêtres de session est présentée dans le Listing 5.5 (qui se trouve dans src / main / java / bbejeck / chapter_5 / CountingWindowingAndKTableJoinExample.java).
Vous avez déjà rencontré la plupart des opérations de cette topologie, il n'est donc pas nécessaire de les considérer ici à nouveau. Mais il y a plusieurs nouveaux éléments que nous allons discuter maintenant.
Pour toute opération groupBy, une sorte d'opération d'agrégation (agrégation, convolution ou comptage) est généralement effectuée. Vous pouvez effectuer une agrégation cumulative avec un total cumulé ou une agrégation de fenêtres, dans laquelle les enregistrements sont pris en compte dans une fenêtre de temps donnée.
Le code du Listing 5.5 compte le nombre de transactions dans les fenêtres de session. Dans la fig. 5.13 ces actions sont analysées étape par étape.
En appelant windowedBy (SessionWindows. With (vingt secondes). Jusqu'à (quinze minutes)), nous créons une fenêtre de session avec un intervalle d'inactivité de 20 secondes et un intervalle de rétention de 15 minutes. Un intervalle d'inactivité de 20 secondes signifie que l'application inclura tout enregistrement qui arrive dans les 20 secondes suivant la fin ou le début de la session en cours dans la session en cours (active).
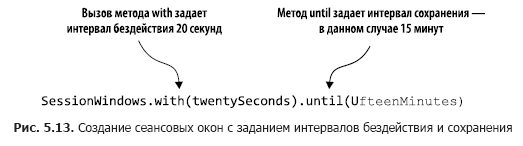
Ensuite, nous indiquons quelle opération d'agrégation effectuer dans la fenêtre de session - dans ce cas, comptez. Si l'enregistrement entrant tombe en dehors de l'intervalle d'inactivité (de chaque côté du cachet de date / heure), l'application crée une nouvelle session. Un intervalle de sauvegarde signifie le maintien d'une session pendant un certain temps et permet des données en retard qui vont au-delà de la période d'inactivité de la session mais peuvent toujours être attachées. De plus, le début et la fin d'une nouvelle session résultant de la fusion correspondent à l'horodatage le plus ancien et le plus récent.
Examinons quelques entrées de la méthode count pour voir comment les sessions fonctionnent (tableau 5.1).
Lors de la réception des enregistrements, nous recherchons les sessions déjà existantes avec la même clé, l'heure de fin est inférieure à la date / heure actuelle - l'intervalle d'inactivité et l'heure de début sont supérieures à la date / heure actuelle + intervalle d'inactivité. Dans cet esprit, quatre enregistrements de la table. 5.1 fusionner en une seule session comme suit.
1. L'enregistrement 1 vient en premier, donc l'heure de début est égale à l'heure de fin et est 00:00:00.
2. Vient ensuite l'enregistrement 2, et nous recherchons des sessions qui se terminent au plus tôt à 23:59:55 et commencent au plus tard à 00:00:35. Recherchez l'enregistrement 1 et combinez les sessions 1 et 2. Prenez l'heure de début de la session 1 (plus tôt) et l'heure de fin de la session 2 (plus tard), de sorte que notre nouvelle session commence à 00:00:00 et se termine à 00:00:15.
3. L'enregistrement 3 arrive, nous recherchons des sessions entre 00:00:30 et 00:01:10 et n'en trouvons aucune. Ajoutez une deuxième session pour la clé 123-345-654, FFBE, commençant et se terminant à 00:00:50.
4. L'enregistrement 4 arrive et nous recherchons des sessions entre 23:59:45 et 00:00:25. Cette fois, il y a deux sessions - 1 et 2. Les trois sessions sont combinées en une seule, avec une heure de début de 00:00:00 et une heure de fin de 00:00:15.
D'après ce qui est dit dans cette section, il convient de se rappeler les nuances importantes suivantes:
- Les sessions ne sont pas des fenêtres de taille fixe. La durée d'une session est déterminée par l'activité dans une période de temps donnée;
- Les horodatages dans les données déterminent si un événement tombe dans une session existante ou dans une période d'inactivité.
Plus loin, nous discuterons du type de fenêtres suivant - les fenêtres de "saut périlleux".
Fenêtres à bascule
Les fenêtres «tumbling» capturent les événements qui se produisent dans une certaine période de temps. Imaginez que vous devez capturer toutes les transactions d'échange d'une entreprise toutes les 20 secondes, afin de collecter tous les événements de cette période. À la fin de l'intervalle de 20 secondes, la fenêtre «bascule» et passe à un nouvel intervalle d'observation de 20 secondes. La figure 5.14 illustre cette situation.
Comme vous pouvez le voir, tous les événements reçus au cours des 20 dernières secondes sont inclus dans la fenêtre. À la fin de cette période, une nouvelle fenêtre est créée.
Le listing 5.6 montre le code qui illustre l'utilisation de fenêtres tumbling pour capturer les transactions d'échange toutes les 20 secondes (vous pouvez le trouver dans src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java).
Grâce à cette petite modification de l'appel à la méthode TimeWindows.of, vous pouvez utiliser la fenêtre tumbling. Dans cet exemple, il n'y a aucun appel à la méthode until (), à la suite de quoi l'intervalle de sauvegarde par défaut de 24 heures sera utilisé.
Enfin, il est temps de passer à la dernière des options de fenêtre - saut de fenêtres.
Fenêtres coulissantes ("sautantes")
Les fenêtres coulissantes / «sautillantes» sont similaires au «culbutage», mais avec une légère différence. Les fenêtres coulissantes n'attendent pas la fin de l'intervalle de temps avant de créer une nouvelle fenêtre pour gérer les événements récents. Ils commencent de nouveaux calculs après un intervalle d'attente plus court que la durée de la fenêtre.
Pour illustrer les différences entre les fenêtres «saut périlleux» et «sautant», revenons à l'exemple du calcul des opérations de change. Notre objectif, comme précédemment, est de compter le nombre de transactions, mais nous ne voudrions pas attendre tout le temps avant de mettre à jour le compteur. Au lieu de cela, nous mettrons à jour le compteur à des intervalles plus courts. Par exemple, nous continuerons à compter le nombre de transactions toutes les 20 secondes, mais à mettre à jour le compteur toutes les 5 secondes, comme le montre la Fig. 5.15. Dans le même temps, nous avons trois fenêtres de résultats avec des données qui se chevauchent.
Le listing 5.7 montre le code pour spécifier les fenêtres coulissantes (il peut être trouvé dans src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java).
«» «» advanceBy(). 15 .
, . , , :
, KTable KStream .
5.3.3. KStream KTable
4 KStream. KTable KStream. . KStream — , KTable — , KTable.
. , .
- KTable KStream , , .
- KTable, . KTable .
- .
, .
KTable KStream
KTable KStream .
- KTable.toStream().
- KStream.map , Windowed TransactionSummary.
( src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) ( 5.8).
KStream.map, KStream .
, KTable .
KTable
, KTable ( src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) ( 5.9).
, Serde , Serde. EARLIEST .
— .
. , ( src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) ( 5.10).
leftJoin . 4, JoinWindow , KStream-KTable KTable . : KTable, . : KTable KStream .
KStream.
5.3.4. GlobalKTable
, . 4 KStream, — KStream KTable. . , Kafka Streams . , , ( 4, « » 4.2.4).
— , ; . , , .
, , , . Kafka Streams GlobalKTable.
GlobalKTable , . , , . GlobalKTable . .
KStream GlobalKTable
Dans la sous-section 5.3.2, nous avons procédé à l'agrégation des fenêtres des transactions d'échange par les clients. Les résultats de cette agrégation ressemblaient à ceci:{customerId='074-09-3705', stockTicker='GUTM'}, 17 {customerId='037-34-5184', stockTicker='CORK'}, 16
Bien que ces résultats soient conformes à l'objectif, il serait plus pratique d'afficher également le nom du client et le nom complet de l'entreprise. Pour ajouter le nom d'un client et le nom d'une entreprise, vous pouvez effectuer des connexions normales, mais vous devrez effectuer deux mappages de clés et re-partitionner. Avec GlobalKTable, vous pouvez éviter le coût de telles opérations.
Pour ce faire, nous allons utiliser l'objet countStream du Listing 5.11 (le code correspondant peut être trouvé dans le fichier src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java), en le connectant avec deux objets GlobalKTable.
Nous en avons déjà discuté auparavant, donc je ne le répéterai pas. Mais je note que le code dans la fonction toStream (). Map est abstrait dans l'objet fonction pour des raisons de lisibilité au lieu de l'expression lambda intégrée.
L'étape suivante consiste à déclarer deux instances de GlobalKTable (le code affiché peut être trouvé dans src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java) (Listing 5.12).
Notez que les noms de rubrique sont décrits à l'aide de types énumérés.
Maintenant que nous avons préparé tous les composants, il reste à écrire le code de la connexion (qui se trouve dans le fichier src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java) (Listing 5.13).
Bien qu'il existe deux composés dans ce code, ils sont organisés en chaîne, car aucun de leurs résultats n'est utilisé séparément. Les résultats sont affichés à la fin de toute l'opération.
Lorsque vous démarrez l'opération de connexion ci-dessus, vous obtiendrez les résultats suivants:
{customer='Barney, Smith' company="Exxon", transactions= 17}
L'essence n'a pas changé, mais ces résultats semblent plus clairs.
En comptant le chapitre 4, vous avez déjà vu plusieurs types de connexions en action. Ils sont répertoriés dans le tableau. 5.2. Ce tableau reflète la connectivité pertinente à la version 1.0.0 de Kafka Streams; quelque chose va changer dans les prochaines versions.
En conclusion, je vous rappelle l'essentiel: vous pouvez connecter des flux d'événements (KStream) et des flux de mise à jour (KTable) en utilisant l'état local. De plus, si la taille des données de référence n'est pas trop grande, vous pouvez utiliser l'objet GlobalKTable. GlobalKTable réplique toutes les sections sur chacun des nœuds de l'application Kafka Streams, garantissant ainsi la disponibilité de toutes les données quelle que soit la section à laquelle la clé correspond.
Ensuite, nous verrons la possibilité de flux Kafka, grâce auxquels vous pouvez observer les changements d'état sans consommer les données du sujet Kafka.
5.3.5. Statut de la demande
Nous avons déjà effectué plusieurs opérations impliquant l'état et toujours restituer les résultats à la console (à des fins de développement) ou les écrire dans le sujet (pour une opération industrielle). Lorsque vous écrivez des résultats dans un sujet, vous devez utiliser le consommateur Kafka pour les afficher.
La lecture des données de ces sujets peut être considérée comme une sorte de vues matérialisées. Pour nos tâches, nous pouvons utiliser la définition d'une vue matérialisée de Wikipedia: «... un objet de base de données physique contenant les résultats d'une requête. Par exemple, il peut s'agir d'une copie locale des données supprimées, ou d'un sous-ensemble des lignes et / ou colonnes d'une table ou des résultats de jointure, ou d'un tableau croisé dynamique obtenu à l'aide de l'agrégation »(https://en.wikipedia.org/wiki/Materialized_view).
Kafka Streams vous permet également d'effectuer des requêtes interactives sur les magasins d'état, ce qui vous permet de lire directement ces vues matérialisées. Il est important de noter que la demande au magasin d'état est de la nature d'une opération en lecture seule. Grâce à cela, vous ne pouvez pas avoir peur de rendre accidentellement l'état d'une application incohérente lors du traitement des données.
La possibilité d'interroger directement les magasins d'état est importante. Cela signifie que vous pouvez créer des applications - des tableaux de bord sans avoir à recevoir au préalable les données d'un consommateur Kafka. Il augmente l'efficacité de l'application, car il n'est pas nécessaire d'enregistrer à nouveau les données:
- En raison de la localisation des données, vous pouvez y accéder rapidement;
- La duplication des données est exclue, car elles ne sont pas écrites sur un stockage externe.
La chose principale dont je voudrais que vous vous souveniez: vous pouvez exécuter directement les requêtes d'état depuis l'application. Vous ne pouvez pas surestimer les opportunités que cela vous offre. Au lieu de consommer des données de Kafka et de stocker des enregistrements dans la base de données pour l'application, vous pouvez interroger les magasins d'état avec le même résultat. Les demandes directes aux magasins d'état signifient moins de code (pas de consommateur) et moins de logiciel (pas besoin d'une table de base de données pour stocker les résultats).
Nous avons couvert une quantité considérable d'informations dans ce chapitre, nous allons donc arrêter temporairement notre discussion sur les requêtes interactives aux magasins d'État. Mais ne vous inquiétez pas: au chapitre 9, nous allons créer une application simple - un panneau d'informations avec des requêtes interactives. Pour démontrer les requêtes interactives et les possibilités de les ajouter aux applications Kafka Streams, il utilisera certains des exemples de ce chapitre et des précédents.
Résumé
- Les objets KStream représentent des flux d'événements comparables aux insertions de base de données. Les objets KTable représentent des flux de mise à jour, ils sont plus similaires aux mises à jour de la base de données. La taille de l'objet KTable n'augmente pas; les anciens enregistrements sont remplacés par de nouveaux.
- Les objets KTable sont requis pour les opérations d'agrégation.
- À l'aide des opérations de fenêtre, vous pouvez diviser les données agrégées en paniers de temps.
- Grâce aux objets GlobalKTable, vous pouvez accéder aux données de référence n'importe où dans l'application, indépendamment de la section.
- Les connexions entre les objets KStream, KTable et GlobalKTable sont possibles.
Jusqu'à présent, nous nous sommes concentrés sur la création d'applications Kafka Streams à l'aide du DSL de haut niveau KStream. Bien qu'une approche de haut niveau vous permette de créer des programmes soignés et concis, son utilisation est un compromis certain. Travailler avec DSL KStream signifie augmenter la concision du code en réduisant le degré de contrôle. Dans le chapitre suivant, nous allons examiner l'API de bas niveau des nœuds de gestionnaire et essayer d'autres compromis. Les programmes deviendront plus longs qu'ils ne l'étaient jusqu'à présent, mais nous aurons la possibilité de créer presque tous les nœuds de traitement dont nous pourrions avoir besoin.
→ Plus de détails sur le livre peuvent être trouvés sur
le site Web de l'éditeur→ Pour Khabrozhiteley 25% de réduction sur le coupon -
Kafka Streams→ Lors du paiement de la version papier du livre, un livre électronique est envoyé par e-mail.