Malgré le fait que la plupart de l'industrie informatique implémente des solutions d'infrastructure basées sur des conteneurs et des solutions cloud, il est nécessaire de comprendre les limites de ces technologies. Traditionnellement, Docker, Linux Containers (LXC) et Rocket (rkt) ne sont pas vraiment isolés car ils partagent le cœur du système d'exploitation parent dans leur travail. Oui, ils sont efficaces en termes de ressources, mais le nombre total de vecteurs d'attaque estimés et les pertes potentielles dues au piratage sont toujours importants, en particulier dans le cas d'un environnement cloud multi-locataire dans lequel se trouvent des conteneurs.

La racine de notre problème réside dans la faible délimitation des conteneurs au moment où le système d'exploitation hôte crée une zone utilisateur virtuelle pour chacun d'eux. Oui, des recherches et développements ont été menés pour créer de véritables «conteneurs» avec un bac à sable à part entière. Et la plupart des solutions qui en résultent conduisent à une restructuration des frontières entre les conteneurs pour améliorer leur isolation. Dans cet article, nous examinerons quatre projets uniques d'IBM, Google, Amazon et OpenStack, respectivement, qui utilisent différentes méthodes pour atteindre le même objectif: créer un isolement fiable. Ainsi, IBM Nabla déploie des conteneurs au-dessus d'Unikernel, Google gVisor crée un noyau invité spécialisé, Amazon Firecracker utilise un hyperviseur extrêmement léger pour les applications sandbox et OpenStack place les conteneurs dans une machine virtuelle spécialisée optimisée pour les outils d'orchestration.
Aperçu de la technologie moderne des conteneurs
Les conteneurs sont un moyen moderne de regrouper, de partager et de déployer une application. Contrairement à une application monolithique, dans laquelle toutes les fonctions sont regroupées dans un seul programme, les applications de conteneur ou les microservices sont destinés à une utilisation étroite ciblée et sont spécialisés dans une seule tâche.
Un conteneur comprend toutes les dépendances (par exemple, packages, bibliothèques et fichiers binaires) dont une application a besoin pour effectuer sa tâche spécifique. Par conséquent, les applications conteneurisées sont indépendantes de la plate-forme et peuvent s'exécuter sur n'importe quel système d'exploitation, quelle que soit la version ou les packages installés. Cette commodité sauve les développeurs d'un énorme travail sur l'adaptation de différentes versions de logiciels pour différentes plates-formes ou clients. Bien que conceptuellement pas tout à fait exact, de nombreuses personnes aiment considérer les conteneurs comme des «machines virtuelles légères».
Lorsqu'un conteneur est déployé sur un hôte, les ressources de chaque conteneur, telles que son système de fichiers, son processus et sa pile réseau, sont placées dans un environnement pratiquement isolé auquel les autres conteneurs ne peuvent pas accéder. Cette architecture permet à des centaines et des milliers de conteneurs de s'exécuter simultanément dans un seul cluster, et chaque application (ou microservice) peut ensuite être facilement mise à l'échelle en répliquant un grand nombre d'instances.
Dans ce cas, la disposition du conteneur est basée sur deux «blocs de construction» clés: l'espace de noms Linux et les groupes de contrôle Linux (cgroups).
L'espace de noms crée un espace utilisateur pratiquement isolé et fournit à l'application des ressources système dédiées telles que le système de fichiers, la pile réseau, l'ID de processus et l'ID utilisateur. Dans cet espace utilisateur isolé, l'application contrôle le répertoire racine du système de fichiers et peut être exécutée en tant que root. Cet espace abstrait permet à chaque application de fonctionner indépendamment, sans interférer avec d'autres applications vivant sur le même hôte. Six espaces de noms sont actuellement disponibles: montage, communication inter-processus (ipc), système de partage de temps UNIX (uts), identifiant de processus (pid), réseau et utilisateur. Il est proposé de compléter cette liste par deux espaces de noms supplémentaires: time et syslog, mais la communauté Linux n'a pas encore décidé des spécifications finales.
Les groupes de contrôle assurent la limitation des ressources matérielles, la priorisation, la surveillance et le contrôle des applications. Un exemple des ressources matérielles qu'ils peuvent contrôler est le processeur, la mémoire, le périphérique et le réseau. Lors de la combinaison de l'espace de noms et des groupes de contrôle, nous pouvons exécuter en toute sécurité plusieurs applications sur le même hôte, chaque application dans son propre environnement isolé - qui est la propriété fondamentale du conteneur.
La principale différence entre une machine virtuelle (VM) et un conteneur est que la machine virtuelle est la virtualisation au niveau matériel et le conteneur est la virtualisation au niveau du système d'exploitation. L'hyperviseur VM émule l'environnement matériel de chaque machine, où le runtime du conteneur émule déjà à son tour le système d'exploitation pour chaque objet. Les machines virtuelles partagent le matériel physique de l'hôte et les conteneurs partagent à la fois le matériel et le cœur du système d'exploitation. Étant donné que les conteneurs partagent généralement plus de ressources avec l'hôte, leur travail avec les cycles de stockage, de mémoire et de processeur est beaucoup plus efficace qu'avec une machine virtuelle. Cependant, l'inconvénient de cet accès partagé réside dans les problèmes de sécurité de l'information, car trop de confiance s'établit entre les conteneurs et l'hôte. La figure 1 illustre la différence architecturale entre un conteneur et une machine virtuelle.
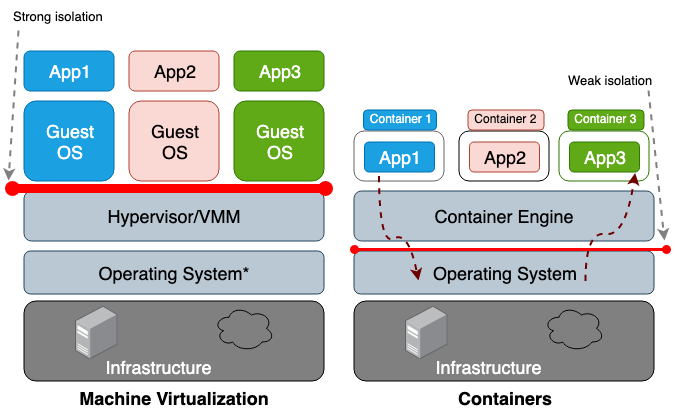
En général, l'isolement des équipements virtualisés crée un périmètre de sécurité beaucoup plus solide que la simple isolation d'un espace de noms. Le risque qu'un attaquant quitte avec succès un processus isolé est beaucoup plus élevé que la chance de quitter avec succès la machine virtuelle. La raison du risque plus élevé d'aller au-delà de l'environnement de conteneur limité est la mauvaise isolation créée par l'espace de noms et les groupes de contrôle. Linux les implémente en associant de nouveaux champs de propriété à chaque processus. Ces champs du système de fichiers
/proc indiquent au système d'exploitation hôte si un processus peut en voir un autre ou la quantité de ressources processeur / mémoire qu'un processus particulier peut utiliser. Lors de l'affichage des processus et des threads en cours d'exécution à partir du système d'exploitation parent (par exemple, la commande top ou ps), le processus de conteneur ressemble à n'importe quel autre. En règle générale, les solutions traditionnelles, telles que LXC ou Docker, ne sont pas considérées comme entièrement isolées car elles utilisent le même cœur au sein du même hôte. Par conséquent, il n'est pas surprenant que les conteneurs présentent un nombre suffisant de vulnérabilités. Par exemple, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 et CVE-2019-5736 pourraient permettre à un attaquant d'accéder aux données en dehors du conteneur.
La plupart des exploits du noyau créent un vecteur pour une attaque réussie, car ils entraînent généralement une escalade de privilèges et permettent à un processus compromis de prendre le contrôle en dehors de son espace de noms prévu. En plus d'attaquer les vecteurs dans le contexte des vulnérabilités logicielles, une configuration incorrecte peut également jouer un rôle. Par exemple, le déploiement d'images avec des privilèges excessifs (CAP_SYS_ADMIN, accès privilégié) ou des points de montage critiques (
/var/run/docker.sock ) peut entraîner une fuite. Compte tenu de ces conséquences potentiellement catastrophiques, vous devez comprendre le risque que vous prenez lors du déploiement du système dans un espace multi-locataire ou lors de l'utilisation de conteneurs pour stocker des données sensibles.
Ces problèmes incitent les chercheurs à créer des périmètres de sécurité plus solides. L'idée est de créer un véritable conteneur sandbox aussi isolé que possible du système d'exploitation principal. La plupart de ces solutions incluent le développement d'une architecture hybride qui utilise une distinction stricte entre l'application et la machine virtuelle, et se concentre sur l'amélioration de l'efficacité des solutions de conteneurs.
Au moment d'écrire ces lignes, aucun projet ne pouvait être qualifié de suffisamment mûr pour être accepté comme standard, mais à l'avenir, les développeurs accepteront sans aucun doute certains de ces concepts comme étant les principaux.
Nous commençons notre examen avec Unikernel, le plus ancien système hautement spécialisé qui regroupe une application dans une image en utilisant un ensemble minimal de bibliothèques de système d'exploitation. Le concept d'Unikernel lui-même s'est avéré fondamental pour de nombreux projets dont l'objectif était de créer des images sûres, compactes et optimisées. Après cela, nous allons passer à IBM Nabla, un projet de lancement d'applications Unikernel, y compris des conteneurs. De plus, nous avons Google gVisor, un projet de lancement de conteneurs dans l'espace du noyau utilisateur. Ensuite, nous passerons à des solutions de conteneurs basées sur des machines virtuelles - Amazon Firecracker et OpenStack Kata. Pour résumer ce message en comparant toutes les solutions ci-dessus.
Unikernel
Le développement des technologies de virtualisation nous a permis de passer au cloud computing. Des hyperviseurs comme Xen et KVM ont jeté les bases de ce que nous connaissons aujourd'hui sous le nom d'Amazon Web Services (AWS) et de Google Cloud Platform (GCP). Et bien que les hyperviseurs modernes soient capables de travailler avec des centaines de machines virtuelles combinées en un seul cluster, les systèmes d'exploitation à usage général traditionnels ne sont pas trop adaptés et optimisés pour fonctionner dans un tel environnement. Le système d'exploitation à usage général est d'abord destiné à prendre en charge et à travailler avec autant d'applications différentes que possible.Par conséquent, leurs noyaux incluent toutes sortes de pilotes, bibliothèques, protocoles, planificateurs, etc. Cependant, la plupart des machines virtuelles qui sont maintenant déployées quelque part dans le cloud sont utilisées pour exécuter une seule application, par exemple, pour fournir DNS, un proxy ou une sorte de base de données. Puisqu'une telle application prise séparément ne dépend dans son travail que d'une partie spécifique et petite du noyau du système d'exploitation, toutes ses autres «jupes» gaspillent simplement les ressources du système et, du fait même de leur existence, elles augmentent le nombre de vecteurs pour une attaque potentielle. En effet, plus la base de code est grande, plus il est difficile d'éliminer tous les défauts, et plus les vulnérabilités, erreurs et autres faiblesses potentielles sont nombreuses. Ce problème encourage les spécialistes à développer des systèmes d'exploitation hautement spécialisés avec un ensemble minimum de fonctionnalités du noyau, c'est-à-dire à créer des outils pour prendre en charge une application spécifique.
Pour la première fois, l'idée d'Unikernel est née dans les années 90. Il a ensuite pris la forme d'une image spécialisée d'une machine avec un seul espace d'adressage pouvant fonctionner directement sur des hyperviseurs. Il regroupe les applications et les fonctions dépendantes du noyau et du noyau dans une seule image. Nemesis et Exokernel sont les deux premières versions de recherche du projet Unikernel. Le processus de mise en package et de déploiement est illustré à la figure 2.
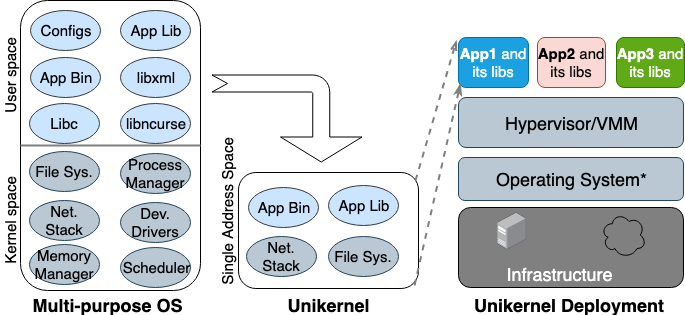 Figure 2. Systèmes d'exploitation polyvalents conçus pour prendre en charge tous les types d'applications, de nombreuses bibliothèques et pilotes sont donc chargés à l'avance. Les Unikernels sont des systèmes d'exploitation hautement spécialisés conçus pour prendre en charge une application spécifique.
Figure 2. Systèmes d'exploitation polyvalents conçus pour prendre en charge tous les types d'applications, de nombreuses bibliothèques et pilotes sont donc chargés à l'avance. Les Unikernels sont des systèmes d'exploitation hautement spécialisés conçus pour prendre en charge une application spécifique.
Unikernel divise le noyau en plusieurs bibliothèques et ne met que les composants nécessaires dans l'image. Comme les machines virtuelles classiques, unikernel se déploie et s'exécute sur l'hyperviseur VM. En raison de sa petite taille, il peut se charger rapidement et aussi évoluer rapidement. Les fonctionnalités les plus importantes d'Unikernel sont une sécurité accrue, un encombrement réduit, un degré élevé d'optimisation et un chargement rapide. Étant donné que ces images ne contiennent que des bibliothèques dépendantes de l'application et que le shell du système d'exploitation n'est pas accessible s'il n'était pas connecté de manière ciblée, le nombre de vecteurs d'attaque que les attaquants peuvent utiliser sur eux est minime.
Autrement dit, il est non seulement difficile pour les attaquants de prendre pied dans ces cœurs uniques, mais leur influence est également limitée à une instance principale. Étant donné que la taille des images Unikernel n'est que de quelques mégaoctets, elles sont téléchargées en quelques dizaines de millisecondes et des centaines d'instances peuvent littéralement s'exécuter sur un seul hôte. En utilisant l'allocation de mémoire dans le même espace d'adressage au lieu d'une table de pages à plusieurs niveaux, comme c'est le cas dans la plupart des systèmes d'exploitation modernes, les applications unikernel ont un délai d'accès à la mémoire inférieur à la même application exécutée sur une machine virtuelle standard. Étant donné que les applications sont associées au noyau lors de la création de l'image, les compilateurs peuvent simplement effectuer une vérification de type statique pour optimiser les fichiers binaires.
Unikernel.org maintient une liste de projets unikernel. Mais avec toutes ses caractéristiques et propriétés distinctives, unikernel n'est pas largement utilisé. Lorsque Docker a acquis Unikernel Systems en 2016, la communauté a décidé que l'entreprise y emballerait désormais des conteneurs. Mais trois ans se sont écoulés et il n'y a toujours aucun signe d'intégration. L'une des principales raisons de cette lente implémentation est qu'il n'existe toujours pas d'outil mature pour créer des applications Unikernel, et la plupart de ces applications ne peuvent fonctionner que sur certains hyperviseurs. De plus, le portage d'une application vers unikernel peut nécessiter une réécriture manuelle du code dans d'autres langues, y compris la réécriture des bibliothèques du noyau dépendantes. Il est également important que la surveillance ou le débogage dans unikernels soit impossible ou ait un impact significatif sur les performances.
Toutes ces restrictions empêchent les développeurs de passer à cette technologie. Il convient de noter que le noyau unique et les conteneurs ont de nombreuses propriétés similaires. La première et la seconde sont des images immuables hautement focalisées, ce qui signifie que les composants qu'elles contiennent ne peuvent pas être mis à jour ou corrigés, c'est-à-dire que vous devez toujours créer une nouvelle image pour le correctif d'application. Aujourd'hui, Unikernel est similaire à l'ancêtre de Docker: alors le runtime du conteneur n'était pas disponible, et les développeurs ont dû utiliser les outils de base pour construire un environnement d'application isolé (chroot, unshare et cgroups).
Ibm nabla
Une fois, les chercheurs d'IBM ont proposé le concept de «Unikernel en tant que processus», c'est-à-dire l'application unikernel qui s'exécuterait en tant que processus sur un hyperviseur spécialisé. Le projet IBM «Nabla containers» a renforcé le périmètre de sécurité d'unikernel, en remplaçant l'hyperviseur universel (par exemple, QEMU) par son propre développement appelé Nabla Tender. La logique derrière cette approche est que les appels entre unikernel et l'hyperviseur fournissent toujours le plus de vecteurs d'attaque. C'est pourquoi l'utilisation d'un hyperviseur dédié à unikernel avec moins d'appels système autorisés peut renforcer considérablement le périmètre de sécurité. Nabla Tender intercepte les appels que le noyau achemine vers l'hyperviseur et les traduit déjà en requêtes système. Dans le même temps, la politique seccomp Linux bloque tous les autres appels système qui ne sont pas nécessaires au fonctionnement de Tender. Ainsi, Unikernel en conjonction avec Nabla Tender s'exécute comme un processus dans l'espace utilisateur de l'hôte. Ci-dessous, dans la figure # 3, il est montré comment Nabla crée une interface mince entre unikernel et l'hôte.
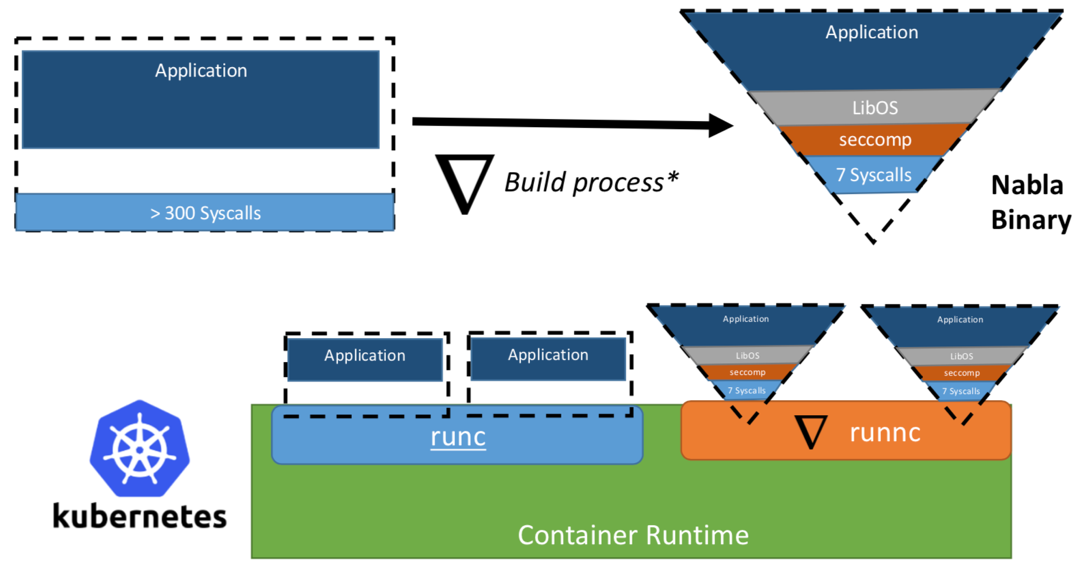 Figure 3. Pour lier Nabla aux plates-formes d'exécution de conteneur existantes, Nabla utilise un environnement compatible OCI, qui à son tour peut être connecté à Docker ou Kubernetes.
Figure 3. Pour lier Nabla aux plates-formes d'exécution de conteneur existantes, Nabla utilise un environnement compatible OCI, qui à son tour peut être connecté à Docker ou Kubernetes.Les développeurs affirment que Nabla Tender utilise moins de sept appels système dans son travail pour interagir avec l'hôte. Puisque les appels système servent de pont entre les processus dans l'espace utilisateur et le noyau du système d'exploitation, moins nous avons d'appels système, plus le nombre de vecteurs disponibles pour attaquer le noyau est petit. Un autre avantage de l'exécution d'unikernel en tant que processus est que vous pouvez déboguer de telles applications à l'aide d'un grand nombre d'outils, par exemple, à l'aide de gdb.
Pour fonctionner avec les plates-formes d'orchestration de conteneurs, Nabla fournit un
runnc dédié qui est implémenté à l'aide de la norme Open Container Initiative (OCI). Ce dernier définit une API entre les clients (par exemple Docker, Kubectl) et l'environnement d'exécution (par exemple, runc). Nabla est également livré avec un constructeur d'images que
runnc pourra plus tard exécuter. Cependant, en raison des différences dans le système de fichiers entre les unikernels et les conteneurs traditionnels, les images Nabla ne répondent pas aux spécifications des images OCI et, par conséquent, les images Docker ne sont pas compatibles avec
runnc . Au moment de la rédaction, le projet en était encore aux premiers stades de développement. Il existe d'autres restrictions, par exemple, le manque de prise en charge pour le montage / accès aux systèmes de fichiers hôtes, l'ajout de plusieurs interfaces réseau (nécessaires pour Kubernetes) ou l'utilisation d'images provenant d'autres images de noyau unique (par exemple, MirageOS).
Google gVisor
Google gVisor est une technologie sandbox utilisant le moteur d'application Google Cloud Platform (GCP), des fonctionnalités cloud et CloudML. À un moment donné, Google a réalisé le risque d'exécuter des applications non fiables dans l'infrastructure de cloud public et l'inefficacité des applications sandbox utilisant des machines virtuelles. En conséquence, un noyau d'espace utilisateur a été développé pour un environnement isolé de telles applications peu fiables. gVisor place ces applications dans le bac à sable, intercepte tous les appels système de celles-ci vers le noyau hôte et les traite dans l'environnement utilisateur à l'aide du noyau gVisor Sentry. En substance, il fonctionne comme une combinaison d'un noyau invité et d'un hyperviseur. La figure 4 montre l'architecture gVisor.
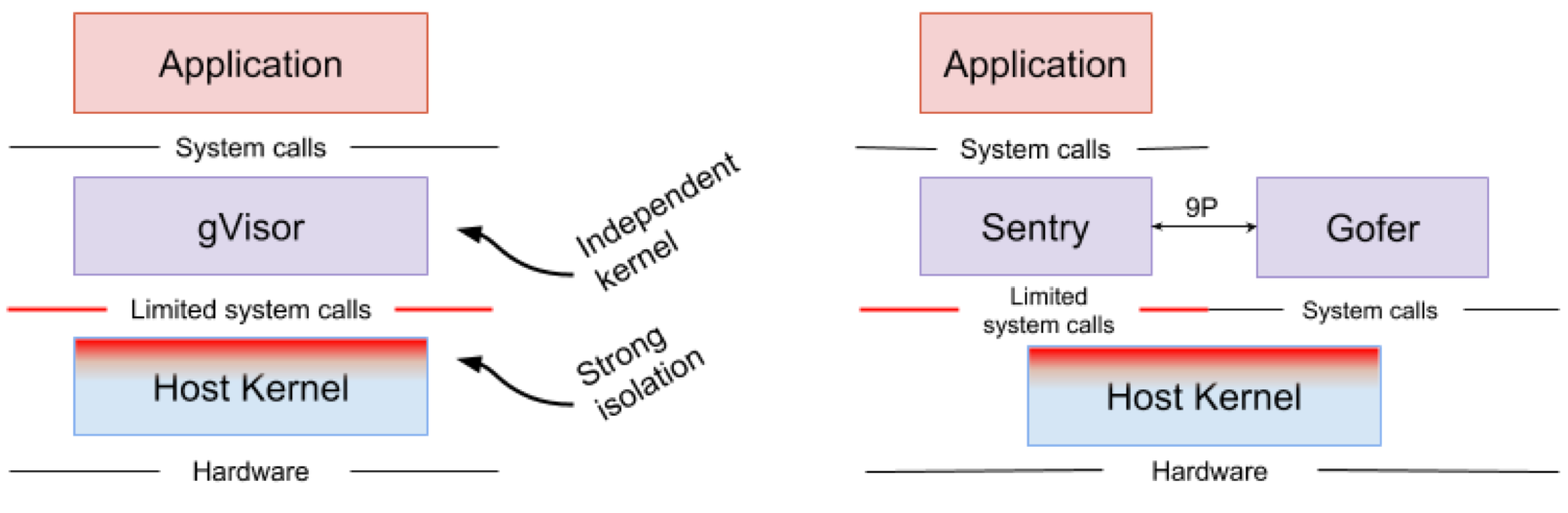 Figure 4. Implémentation du noyau gVisor // Les systèmes de fichiers Sentry et gVisor Gofer utilisent un petit nombre d'appels système pour interagir avec l'hôte
Figure 4. Implémentation du noyau gVisor // Les systèmes de fichiers Sentry et gVisor Gofer utilisent un petit nombre d'appels système pour interagir avec l'hôtegVisor crée un solide périmètre de sécurité entre l'application et son hôte. Il limite les appels système que les applications peuvent utiliser dans l'espace utilisateur. Sans s'appuyer sur la virtualisation, gVisor fonctionne comme un processus hôte qui interagit entre une application autonome et un hôte. Sentry prend en charge la plupart des appels système Linux et les principales fonctions du noyau telles que la livraison du signal, la gestion de la mémoire, la pile réseau et le modèle de flux. Sentry implémente plus de 70% des 319 appels système Linux pour prendre en charge les applications en bac à sable. Cependant, Sentry utilise moins de 20 appels système Linux pour interagir avec le noyau hôte. Il convient de noter que gVisor et Nabla ont une stratégie très similaire: la protection du système d'exploitation hôte et ces deux solutions utilisent moins de 10% des appels système Linux pour interagir avec le noyau. Mais vous devez comprendre que gVisor crée un noyau polyvalent et, par exemple, Nabla s'appuie sur des noyaux uniques. Dans le même temps, les deux solutions lancent un noyau invité spécialisé dans l'espace utilisateur pour prendre en charge les applications isolées auxquelles elles font confiance.
Quelqu'un peut se demander pourquoi gVisor a besoin de son propre noyau, alors que le noyau Linux est déjà open source et facilement accessible. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
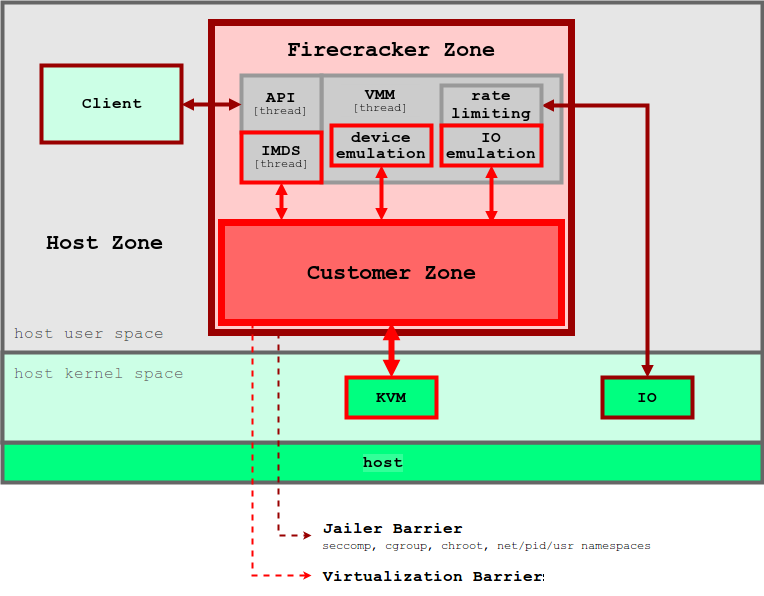 5. Firecracker
5. FirecrackerFirecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
OpenStack Kata
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
qemu-lite . 2017 Clear Containers Hyper RunV, OCI, Kata. Clear Containers, Kata .
Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
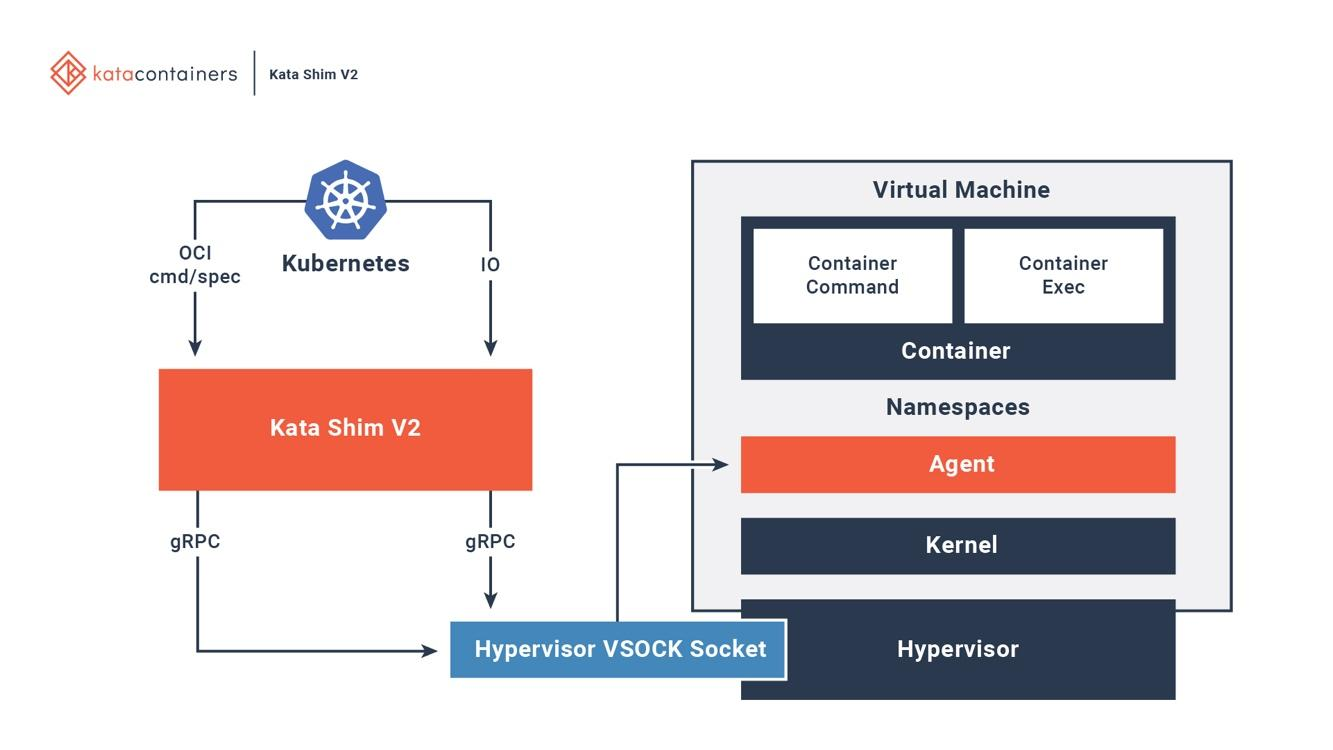 6. Kata Docker Kubernetes
6. Kata Docker KubernetesKata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
Conclusion
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
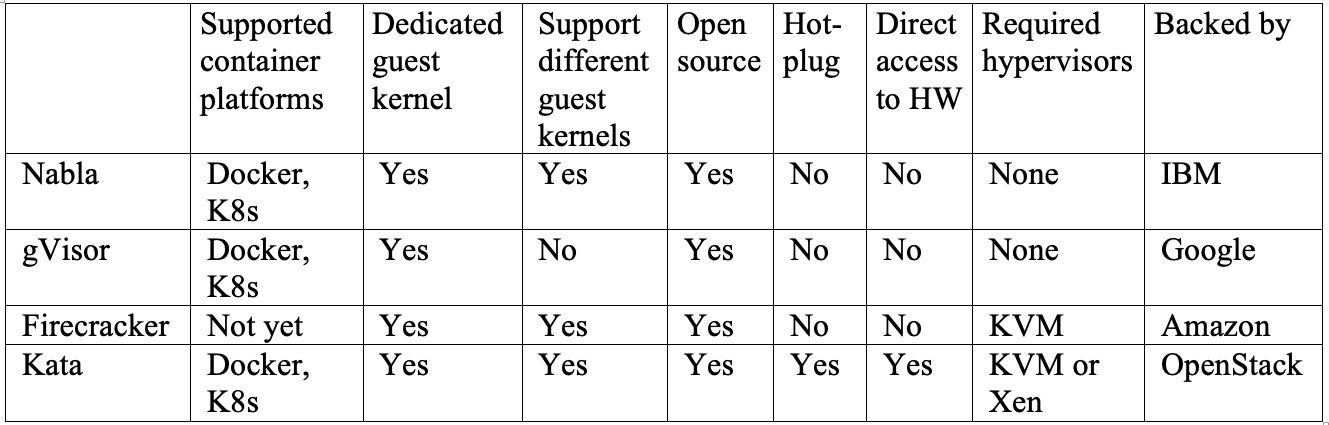
, , , , .