L'écosystème TensorFlow contient un certain nombre de compilateurs et d'optimiseurs travaillant à différents niveaux de la pile logicielle et matérielle. Pour ceux qui utilisent Tensorflow quotidiennement, cette pile multi-niveaux peut générer des erreurs difficiles à comprendre, à la fois au moment de la compilation et à l'exécution, associées à l'utilisation de différents types de matériel (GPU, TPU, plateformes mobiles, etc.)
Ces composants, à commencer par le graphique Tensorflow, peuvent être représentés sous la forme d'un tel diagramme:
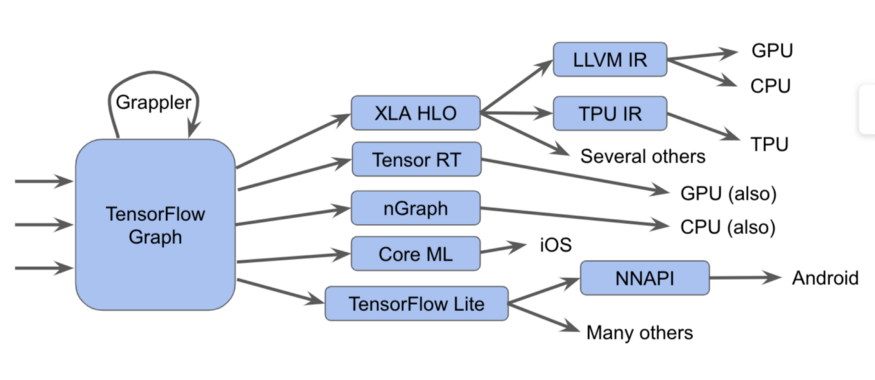 C'est en fait plus difficile
C'est en fait plus difficileDans ce diagramme, nous pouvons voir que les graphiques Tensorflow peuvent être exécutés de plusieurs manières différentes.
une noteDans TensorFlow 2.0, les graphiques peuvent être implicites; l'exécution gourmande peut exécuter des opérations individuellement, en groupes ou sur un graphique complet. Ces graphiques ou fragments de graphique doivent être optimisés et exécutés.
Par exemple:
- Nous envoyons les graphiques à l'exécuteur Tensorflow, qui appelle des noyaux manuscrits spécialisés
- Convertissez-les en XLA HLO (représentation XLA High-Level Optimizer) - une représentation de haut niveau de l'optimiseur XLA, qui, à son tour, peut appeler le compilateur LLVM pour le CPU ou le GPU, ou continuer à utiliser XLA pour TPU , ou les combiner.
- Nous les convertissons en TensorRT , nGraph ou un autre format pour un jeu d'instructions spécialisé implémenté dans le matériel.
- Nous les convertissons au format TensorFlow Lite , exécutés dans le runtime TensorFlow Lite, ou convertis en code pour les exécuter sur le GPU ou le DSP via l' API Android Neural Networks (NNAPI) ou similaire.
Il existe également des méthodes plus complexes, notamment de nombreuses passes d'optimisation sur chaque couche, comme, par exemple, dans le cadre Grappler, qui optimise les opérations dans TensorFlow.
Bien que ces diverses implémentations de compilateurs et de représentations intermédiaires améliorent les performances, leur diversité pose un problème aux utilisateurs finaux, comme la confusion des messages d'erreur lors du couplage de ces sous-systèmes. De plus, les créateurs de nouvelles piles logicielles et matérielles doivent ajuster les passages d'optimisation et de conversion pour chaque nouveau cas.
Et en vertu de tout cela, nous sommes heureux d'annoncer MLIR, une représentation intermédiaire à plusieurs niveaux. Il s'agit d'un format de vue intermédiaire et de bibliothèques de compilation à utiliser entre une vue de modèle et un compilateur de bas niveau qui génère du code dépendant du matériel. En introduisant MLIR, nous voulons céder la place à de nouvelles recherches dans le développement d'optimisation de compilateurs et la mise en œuvre de compilateurs basés sur des composants de qualité industrielle.
Nous prévoyons que le MLIR intéressera de nombreux groupes, notamment:
- les chercheurs de compilateurs, ainsi que les praticiens qui souhaitent optimiser les performances et la consommation de mémoire des modèles d'apprentissage automatique;
- les fabricants de matériel à la recherche d'un moyen de combiner leur matériel avec Tensorflow, comme les TPU, les neuroprocesseurs mobiles dans les smartphones et d'autres ASIC personnalisés;
- les personnes qui souhaitent donner aux langages de programmation les avantages procurés par l'optimisation des compilateurs et des accélérateurs matériels;
Qu'est-ce que le MLIR?
MLIR est essentiellement une infrastructure flexible pour les compilateurs d'optimisation modernes. Cela signifie qu'il se compose d'une spécification de représentation intermédiaire (IR) et d'un ensemble d'outils pour transformer cette représentation. Lorsque nous parlons de compilateurs, le passage d'une vue de niveau supérieur à une vue de niveau inférieur est appelé abaissement, et nous utiliserons ce terme à l'avenir.
MLIR est construit sous l'influence du LLVM et lui emprunte sans vergogne de nombreuses bonnes idées. Il a un système de type flexible et est conçu pour représenter, analyser et transformer des graphiques, combinant de nombreux niveaux d'abstraction en un seul niveau de compilation. Ces abstractions incluent les opérations Tensorflow, les régions de boucles polyédriques imbriquées, les instructions LLVM et les opérations et types à point fixe.
Dialectes de MLIR
Afin de séparer les différentes cibles logicielles et matérielles, MLIR dispose de «dialectes», notamment:
- TensorFlow IR, qui inclut tout ce qui peut être fait dans les graphiques TensorFlow
- XLA HLO IR, conçu pour obtenir tous les avantages fournis par le compilateur XLA, dont la sortie nous permet d'obtenir du code pour TPU, et pas seulement.
- Un dialecte d'affinité expérimental conçu spécifiquement pour les représentations et optimisations polyédriques
- LLVM IR, 1: 1 correspondant à la vue LLVM native, permettant à MLIR de générer du code pour le GPU et le CPU à l'aide de LLVM.
- TensorFlow Lite conçu pour générer du code pour les plates-formes mobiles
Chaque dialecte contient un ensemble d'opérations spécifiques, utilisant des invariants, tels que: "c'est un opérateur binaire, et ses entrées et sorties sont du même type".
Extensions MLIR
MLIR n'a pas de liste fixe et intégrée d'opérations intrinsèques mondiales. Les dialectes peuvent définir des types complètement personnalisés, et de cette façon MLIR peut modéliser des choses comme le système de type IR LLVM (ayant des agrégats de première classe), des abstractions de langage de domaine, telles que des types quantifiés, importantes pour les accélérateurs optimisés ML, et, à l'avenir, même un système de type Swift ou Clang.
Si vous souhaitez associer un nouveau compilateur de bas niveau à ce système, vous pouvez créer un nouveau dialecte et descendre du dialecte du graphique TensorFlow vers votre dialecte. Cela simplifie le chemin d'accès pour les développeurs de matériel et les développeurs de compilateurs. Vous pouvez cibler le dialecte à différents niveaux du même modèle, des optimiseurs de haut niveau seront responsables de parties spécifiques de l'IR.
Pour les chercheurs de compilateurs et les développeurs de frameworks, MLIR vous permet de créer des transformations à tous les niveaux, vous pouvez définir vos propres opérations et abstractions en IR, vous permettant de mieux modéliser vos tâches d'application. Ainsi, MLIR est plus qu'une pure infrastructure de compilateur, ce que LLVM est.
Bien que MLIR fonctionne comme un compilateur pour ML, il permet également l'utilisation de technologies d'apprentissage automatique! Ceci est très important pour les ingénieurs qui développent des bibliothèques numériques et ne peut pas prendre en charge la grande variété de modèles et de matériel ML. La flexibilité de MLIR facilite l'exploration de stratégies de descente de code lors du déplacement entre les niveaux d'abstraction.
Et ensuite
Nous avons ouvert un
référentiel GitHub et invitons toutes les personnes intéressées (consultez notre guide!). Nous publierons quelque chose de plus que cette boîte à outils - les spécifications de dialecte TensorFlow et TF Lite, dans les prochains mois. Nous pouvons vous en dire plus, pour en savoir plus, voir la
présentation de Chris Luttner et notre
README sur Github .
Si vous voulez vous tenir au courant de tout ce qui touche au MLIR, rejoignez notre
nouvelle liste de diffusion , qui se concentrera bientôt sur les annonces de futures versions de notre projet. Reste avec nous!