Bonjour, Habr! Je vous présente la traduction de l'article
«Image Similarity using Deep Ranking» par Akarsh Zingade.
Algorithme de classement profond
Le concept de "
similitude de deux images " n'a pas été introduit, introduisons donc ce concept au moins dans le cadre de l'article.
La similitude des deux images résulte de la comparaison de deux images selon certains critères. Sa mesure quantitative détermine le degré de similitude entre les diagrammes d'intensité de deux images. À l'aide d'une mesure de similitude, certaines fonctionnalités décrivant les images sont comparées. Comme mesure de similitude, la distance de Hamming, la distance euclidienne, la distance de Manhattan, etc.
Deep Ranking - étudie la similitude de l'image à grain fin, caractérisant le rapport de similitude de l'image finement divisée à l'aide d'un ensemble de triplets.
Qu'est-ce qu'un triplet?
Le triplet contient l'image de la demande, l'image positive et négative. Où une image positive ressemble plus à une image de demande qu'à une image négative.
Un exemple d'un ensemble de triplets:
La première, la deuxième et la troisième ligne correspondent à l'image de la demande. La deuxième ligne (images positives) ressemble plus à des images de demande que la troisième (images négatives).
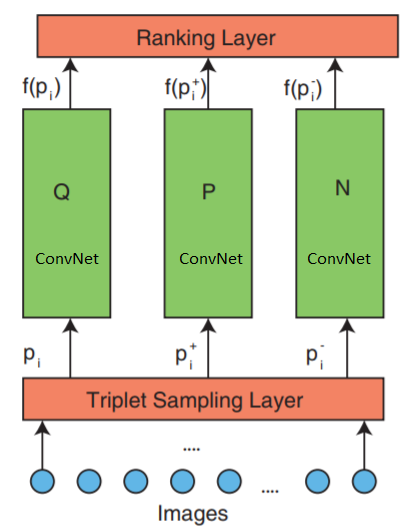
Architecture de réseau de classement profond
Le réseau se compose de 3 parties: l'échantillonnage en triplets, ConvNet et une couche de classement.
Le réseau accepte des triplets d'images en entrée. Un triplet d'images contient une image de demande
$ inline $ p_i $ inline $ image positive
$ en ligne $ p_i ^ + $ en ligne $ et image négative
$ inline $ p_i ^ - $ inline $ qui sont transmis indépendamment à trois réseaux de neurones profonds identiques.
La couche de classement la plus élevée - évalue la fonction de perte de triplet. Cette erreur est corrigée dans les couches inférieures afin de minimiser la fonction de perte.
Examinons maintenant de plus près la couche intermédiaire:
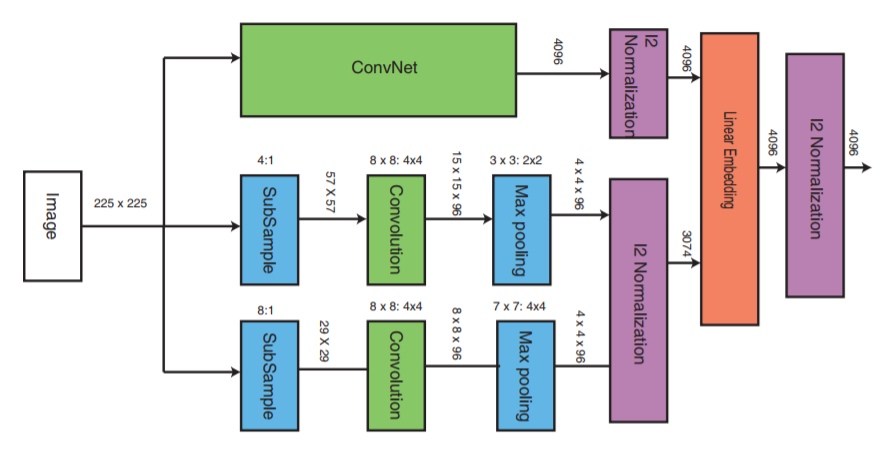
ConvNet peut être n'importe quel réseau neuronal profond (cet article traitera de l'une des implémentations du réseau neuronal convolutionnel VGG16). ConvNet contient des couches convolutives, une couche de pool maximum, des couches de normalisation locale et des couches entièrement connectées.
Les deux autres parties reçoivent des images avec un taux d'échantillonnage réduit et effectuent l'étape de convolution et la mise en commun maximale. Ensuite, l'étape de normalisation des trois parties a lieu et à la fin, elles sont combinées avec une couche linéaire avec normalisation ultérieure.
Formation de triplets
Il existe plusieurs façons de créer un fichier triplet, par exemple, utiliser une évaluation d'expert. Mais cet article utilisera l'algorithme suivant:
- Chaque image de la classe forme une image de demande.
- Chaque image, à l'exception de l'image de demande, formera une image positive. Mais vous pouvez limiter le nombre d'images positives pour chaque demande d'image
- Une image négative est sélectionnée au hasard dans n'importe quelle classe qui n'est pas une classe d'image de demande
Fonction de perte de triplet
L'objectif est de former une fonction qui attribue une petite distance pour les images les plus similaires et une grande pour les différentes. Cela peut s'exprimer comme suit:
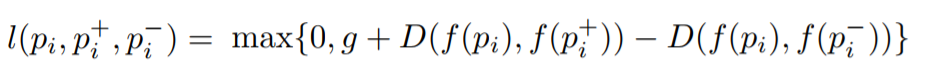
Où
l est le coefficient de perte pour les triplets,
g est le coefficient d'écart entre la distance entre deux paires d'images: (
$ inline $ p_i $ inline $ ,
$ en ligne $ p_i ^ + $ en ligne $ ) et (
$ inline $ p_i $ inline $ ,
$ inline $ p_i ^ - $ inline $ ),
f - fonction d'intégration qui affiche l'image dans un vecteur,
$ inline $ p_i $ inline $ Est l'image de la demande,
$ en ligne $ p_i ^ + $ en ligne $ Est une image positive,
$ inline $ p_i ^ - $ inline $ Est une image négative et
D est la distance euclidienne entre deux points euclidiens.
Implémentation d'un algorithme de classement en profondeur
Implémentation avec Keras.
Trois réseaux parallèles sont utilisés pour la requête, l'image positive et négative.
La mise en œuvre comprend trois parties principales:
- Implémentation de trois réseaux neuronaux multiéchelles parallèles
- Implémentation de la fonction de perte
- Génération de triplets
L'apprentissage de trois réseaux profonds parallèles consommera beaucoup de ressources mémoire. Au lieu de trois réseaux profonds parallèles qui reçoivent une image de demande, une image positive et une image négative, ces images seront transmises séquentiellement à un réseau neuronal profond à l'entrée d'un réseau neuronal. Le tenseur transféré à la couche de perte contiendra une pièce jointe image dans chaque ligne. Chaque ligne correspond à chaque image d'entrée dans un paquet. Étant donné que l'image de demande, l'image positive et l'image négative sont transmises séquentiellement, la première ligne correspondra à l'image de demande, la seconde à l'image positive et la troisième à l'image négative, puis répétée jusqu'à la fin du paquet. Ainsi, la couche de classement reçoit une intégration de toutes les images. Après cela, la fonction de perte est calculée.
Pour implémenter la couche de classement, nous devons écrire notre propre fonction de perte, qui calculera la distance euclidienne entre l'image de demande et l'image positive, ainsi que la distance euclidienne entre l'image de demande et l'image négative.
Implémentation de la fonction de calcul des pertes_EPSILON = K.epsilon() def _loss_tensor(y_true, y_pred): y_pred = K.clip(y_pred, _EPSILON, 1.0-_EPSILON) loss = tf.convert_to_tensor(0,dtype=tf.float32)
La taille du paquet doit toujours être un multiple de 3. Puisqu'un triplet contient 3 images et que les images du triplet sont transmises séquentiellement (nous envoyons chaque image à un réseau neuronal profond séquentiellement)
Le reste du code est ici