L'histoire de l'optimisation des images pour les applications java a commencé avec l'article de blog de printemps Spring Boot in a Container . Il a discuté de divers aspects de la création d'images Docker pour les applications Spring Boot, y compris un problème aussi intéressant que la réduction de la taille des images. Pour nos équipes, cela était pertinent pour plusieurs raisons, nous avons donc décidé d'appliquer cette solution à nos applications.
Comme cela arrive souvent, tout n'a pas décollé la première fois, il y avait des nuances avec les projets multi-modules et une tentative de piloter tout cela sur le système CI, donc dans cet article vous trouverez une solution à ces problèmes.
Le but de l'optimisation est de réduire la différence entre les images résultantes d'un assemblage à l'autre, ce qui donne un bon résultat dans le processus de livraison continue, donc si vous êtes intéressé à minimiser la taille de l'image en tant que telle, vous pouvez vous référer à d' autres articles sur le hub
Si vous n'avez pas à expliquer pourquoi vous devriez faire quelque chose avec une application de démarrage à plusieurs mètres avant de la placer dans l'image, vous pouvez immédiatement passer à la description de l'approche d'optimisation . Si vous avez réussi à vous familiariser avec l'article du blog de printemps, vous pouvez procéder à la résolution des problèmes rencontrés .
Pourquoi est-ce tout, ou le revers du gros pot
Par défaut, le fichier jar produit par Spring Boot est un fichier jar exécutable contenant le code de l'application et toutes ses dépendances.
L'avantage de cette approche est évident: il est pratique de travailler avec un seul fichier, il a tout ce dont vous avez besoin pour exécuter java -jar <myapp>.jar . Dockerfile est trivial et ne présente aucun intérêt.
L'inconvénient est un stockage inefficace. Dans une application de démarrage classique, le rapport entre le code et les bibliothèques n'est clairement pas en faveur de notre code. Par exemple, une application vide avec un composant WebPart et des bibliothèques pour travailler avec la base de données, qui peut être générée via start.spring.io , prendra 20 Mo, dont 98% seront des bibliothèques. Et ce ratio ne change pas beaucoup au cours du processus de développement.
Mais nous collectons l'application plus d'une fois, mais régulièrement sur le serveur CI, puis nous déployons sur une chaîne d'environnements. Ainsi, 10 assemblages croissent à 200 Mo et 100 à 2 Go, dont les modifications prendront très peu.
On peut affirmer que pour le coût de stockage actuel, ce sont des chiffres ridicules et que vous n'avez pas à consacrer du temps à de telles optimisations, mais tout dépend de la taille de l'organisation et du nombre d'applications dont les images doivent être stockées. Les conditions de déploiement peuvent également fortement motiver: lorsque le registre et le serveur sont à proximité, même une différence de 100 Mo n'est pas très perceptible, mais dans les systèmes distribués, cela peut être beaucoup plus important, surtout lorsque vous devez déployer dans des pays spécifiques comme la Chine avec son pare-feu et ses canaux instables. au monde extérieur.
Donc, avec les raisons identifiées, il est temps d'optimiser.
Nous optimisons l'assemblage, ou ce qui peut être appris du blog de printemps
L'article propose une solution raisonnable: au lieu d'une seule couche générée par la commande COPY my-jar.jar app.jar , nous devons créer plusieurs couches.
Une couche contiendra des bibliothèques, la seconde est notre propre code. Pour ce faire, vous devez décompresser le fichier jar et copier le contenu sur différentes couches de l'image.
Le script de préparation du fichier jar ressemble à ceci:
Un dockerfile utilisant une construction en plusieurs étapes pourrait ressembler à ceci
FROM openjdk:8-jdk-alpine as build WORKDIR /wd COPY prepare_for_docker.sh /usr/local/bin/prepare_for_docker COPY target/demo.jar /wd/app.jar RUN prepare_for_docker /wd/app.jar FROM openjdk:8-jdk-alpine COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib COPY --from=build /wd/docker-dist/META-INF /app/META-INF COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]
À la première étape, nous copions tout ce dont nous avons besoin, exécutons notre script pour décompresser le fichier jar, et à la deuxième étape, nous mettons en place des bibliothèques distinctes et notre code séparément dans des couches.
Il est facile de s'assurer de l'opérabilité:
- Collectionner pour la première fois
- Apportez toute modification à notre code.
- Nous lançons à nouveau la
docker build et voyons les lignes chères Using cache lors de la copie de tout le répertoire lib
... Step 5/10 : RUN prepare_for_docker app.jar ---> Running in c8e422491eb2 Removing intermediate container c8e422491eb2 ---> c7dcec4ae18a Step 6/10 : FROM openjdk:8-jdk-alpine ---> a3562aa0b991 Step 7/10 : COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib ---> Using cache ---> 01b600d7e350 Step 8/10 : COPY --from=build /wd/docker-dist/META-INF /app/META-INF ---> Using cache ---> 5c0c03a3c8f1 Step 9/10 : COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ---> 5ffed6ee5696 Step 10/10 : ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"] ---> Running in 99957250fe5d Removing intermediate container 99957250fe5d ---> 6735799d9f32 Successfully built 6735799d9f32 Successfully tagged boot2-sample:latest
Une façon évidente d'améliorer cette approche est de construire une petite image de base avec un script afin de ne pas la faire glisser de projet en projet. Ainsi, la première couche devient plus concise.
FROM zeldigas/java-layered-builder as build COPY target/demo.jar app.jar RUN prepare_for_docker app.jar
Nous finalisons la solution
Comme déjà mentionné au début de l'article, la solution fonctionne, mais pendant l'opération, quelques problèmes ont été trouvés qui seront discutés plus tard.
Tous les fichiers de la bibliothèque ne lib également des bibliothèques
Si votre projet est multi-module (au moins il y a le module A, dont dépend le module B, assemblé comme un pot de graisse de printemps), en lui appliquant la solution d'origine, vous constaterez qu'aucune mise en cache de couche ne se produit. Qu'est-ce qui a mal tourné?
Le problème est dans les modules supplémentaires: ils sont des sources de changements constants pour la couche, même si vous n'apportez aucune modification au code du module. Cela est dû à la particularité de créer des fichiers jav maven (avec gradle, la situation est un peu meilleure, mais pas sûre). La tâche d'obtenir des artefacts reproductibles n'est pas le sujet de cet article (bien que, bien sûr, elle soit intéressante et réalisable), nous allons donc passer à une solution assez simple.
Nous distribuons le contenu de lib dans 2 répertoires, après décompression, séparant les modules du projet des autres bibliothèques. Finalisons le script de déballage du gros pot:
En conséquence, le script a commencé à prendre en charge le transfert de paramètres supplémentaires (voir 1 et 2). Si des arguments supplémentaires (3) sont passés, chacun d'eux est considéré comme un préfixe pour le nom du fichier que nous déplaçons (4) dans un répertoire séparé.
Exemple de Dockerfile pour un scénario avec un supplémentaire. shared-module et version 1.0-SNAPSHOT
FROM openjdk:8-jdk-alpine as build COPY target/demo.jar /wd/app.jar RUN prepare_for_docker /wd/app.jar shared-module-1.0 FROM openjdk:8-jdk-alpine COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib COPY --from=build /wd/docker-dist/app-lib /app/lib COPY --from=build /wd/docker-dist/META-INF /app/META-INF COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]
Exécuter sur le serveur CI
Après avoir tout débogué localement, satisfait du résultat, nous avons commencé à exécuter sur le serveur CI et à partir des journaux de construction, nous avons constaté qu'un miracle ne s'était pas produit, ou plutôt que les résultats n'étaient pas constants: dans certains cas, la mise en cache était effectuée et la prochaine fois que toutes les couches étaient nouvelles.
En conséquence, le coupable a été découvert - cache docker, ou plutôt son absence dans le cas de différents agents (notre assemblage n'est pas cloué sur un agent spécifique du système CI). Comme il s'est avéré, s'il n'y a pas de couches appropriées dans le cache docker, alors les couches avec une somme de contrôle différente sont obtenues à partir du même ensemble de fichiers. Vous pouvez le vérifier localement, en exécutant la génération avec l'option --no-cache , ou en --no-cache deuxième fois en supprimant d'abord l'image et toutes les couches intermédiaires. En conséquence, vous obtenez une couche de somme de contrôle complètement différente, ce qui annule tous les efforts précédents.

Il existe plusieurs façons de résoudre le problème:
- Si votre système CI prend cela en charge (par exemple, Circle CI dans la partie plans a une prise en charge intégrée pour le cache partagé pendant les assemblages)
- Mélanger une section avec un cache Docker entre les agents
- Profitez du docker de gestion du cache
--cache-from ( --cache-from )
Nous avons choisi la troisième voie, car dans notre cas, c'était la plus simple. L'option vous permet de dire au démon docker quelles images il doit prendre en compte et d'essayer d'utiliser pour la mise en cache lors de l'assemblage. Vous pouvez spécifier autant d'images que vous le jugez nécessaire, l'essentiel est qu'elles se trouvent sur le système de fichiers. Si l'image spécifiée n'existe pas, elle sera simplement ignorée, vous devez donc tirer avant de construire.
Voici à quoi ressemble l'assemblage de conteneur avec cette approche:
set -e version=...
Nous essayons de réutiliser les calques uniquement à partir de l'image la plus récente, ce qui est souvent suffisant, mais personne ne se soucie de liquider une logique plus complexe et de retomber sur quelques versions ou de s'appuyer sur l'id des vcs commits.
Nous adaptons cette approche aux capacités de votre CI et obtenons une réutilisation fiable des couches avec des bibliothèques.
Total
La solution montre de bons résultats, en particulier lorsqu'elle est utilisée dans des projets avec un stade de développement actif et un pipeline de CD réglé. Le graphique ci-dessous montre le résultat de l'application de l'optimisation à l'une des applications. On voit clairement que la croissance linéaire est devenue spasmodique à partir du 70e assemblage (les échecs dans les années 60 sont liés précisément au travail de débogage sur les agents de build). Les émissions après sont associées à la mise à jour de l'image de base (élevée) et des bibliothèques (inférieure)
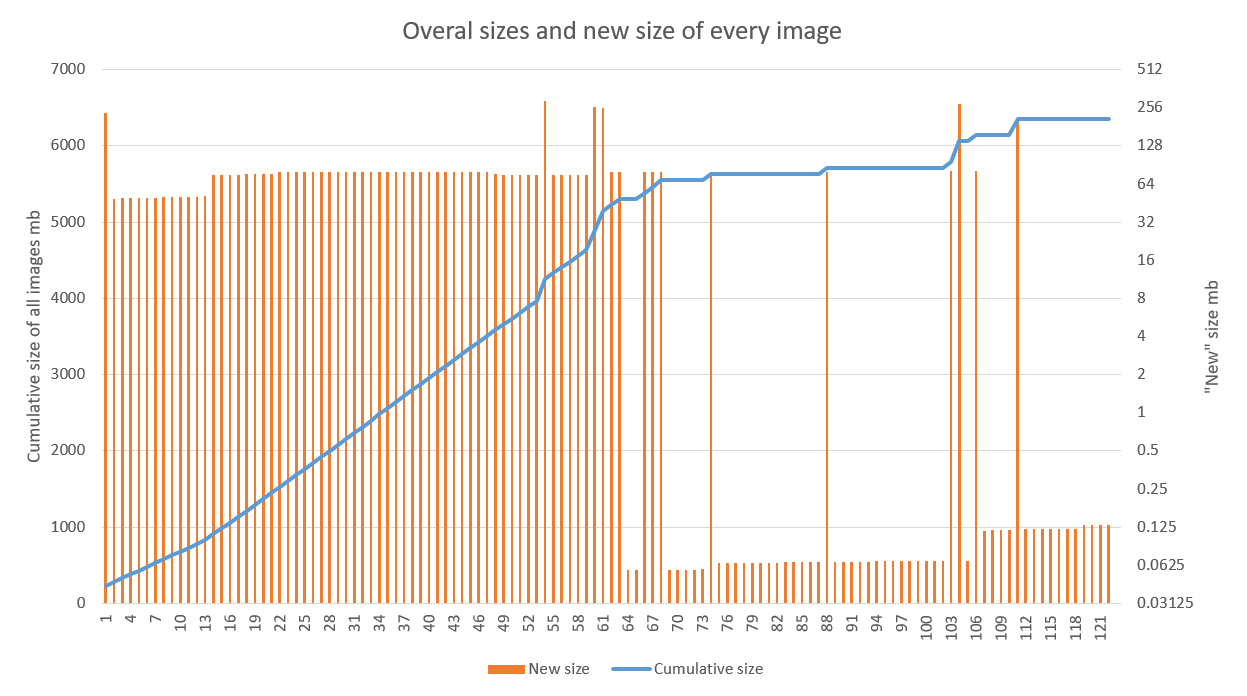
L'optimisation du stockage dans notre cas est un bonus agréable, mais plutôt secondaire. L'accélération du déploiement de la nouvelle version sur l'ancienne dans plusieurs régions est beaucoup plus réjouissante.
Il est à noter que cette technique est tout à fait compatible avec d'autres approches visant à réduire la taille d'une seule image (alpin et autres images basiques légères, runtime personnalisé pour l'application). L'essentiel est de suivre les règles générales d'assemblage de l'image en termes de mise en cache et de s'assurer que le résultat est reproductible.