Toloka est la plus grande source de données étiquetées par machine pour les tâches d'apprentissage automatique. Chaque jour à Tolok, des dizaines de milliers d'artistes produisent plus de 5 millions de notes. Pour toute recherche et expérience liée à l'apprentissage automatique, de grands volumes de données de qualité sont nécessaires. Par conséquent, nous commençons à publier des ensembles de données ouverts pour la recherche universitaire dans divers domaines.
Aujourd'hui, nous partagerons des liens vers les premiers ensembles de données publics et parlerons de leur assemblage. Nous vous montrerons également où mettre le stress au nom de notre plateforme.
Un fait intéressant: plus la technologie de l'intelligence artificielle est complexe, plus elle a besoin de l'aide humaine. Les gens catégorisent les images pour former la vision par ordinateur; Les utilisateurs évaluent la pertinence des pages pour les requêtes de recherche. les gens convertissent la parole en texte pour que l'assistant vocal apprenne à comprendre et à parler. La machine a besoin d'évaluations humaines pour fonctionner plus loin sans personne et mieux que les personnes.
Auparavant, de nombreuses entreprises collectaient ces évaluations exclusivement avec l'aide d'employés spécialement formés - des évaluateurs. Mais au fil du temps, il y avait trop de tâches dans le domaine de l'apprentissage automatique, et pour la plupart, les tâches elles-mêmes ont cessé d'exiger des connaissances et une expérience particulières. Il y avait donc une demande d'aide de la «foule» (foule). Mais seuls, tout le monde ne peut pas trouver un grand nombre d'interprètes aléatoires et travailler avec eux. Les plateformes de crowdsourcing résolvent ce problème.
Yandex.Toloka (correctement prononcé de cette façon, en mettant l'accent sur la dernière syllabe) est l'une des plus grandes plateformes de crowdsourcing au monde. Nous avons plus de 4 millions d'utilisateurs enregistrés. Chaque jour, plus de 500 projets collectent des évaluations avec notre aide. Fait agréable: cette année à la section Data Labelling de la conférence Data Fest, les six conférenciers de différentes entreprises ont mentionné Toloka comme source de balisage pour leurs projets.
On a beaucoup parlé de l'utilisation de Toloka dans les affaires. Aujourd'hui, nous allons parler de notre autre domaine, que nous considérons non moins utile.
Recherche à Tolok
Le crowdsourcing et, en général, la tâche de rassembler en masse des annotations humaines, sont à peu près les mêmes que l'application industrielle de l'apprentissage automatique. C'est un domaine dans lequel toutes les entreprises technologiques dépensent beaucoup d'argent. Mais en même temps, pour une raison quelconque, c'est elle qui est fortement sous-investie en termes de recherche: sur le travail avec la foule, contrairement à d'autres domaines du ML, relativement peu d'études sérieuses et d'articles.
Nous aimerions changer cela. Notre équipe voit Toloka non seulement comme un outil pour résoudre des problèmes appliqués, mais aussi comme une plate-forme pour la recherche scientifique dans divers domaines.
Toloka Public Datasets
Nous voulons soutenir la communauté scientifique et attirer des chercheurs à Toloka, nous commençons donc à publier des ensembles de données à des fins académiques non commerciales. Ils peuvent intéresser les chercheurs de différentes directions: voici des robots de discussion et des données pour tester des modèles d'agrégation de verdicts de tolkers, pour la recherche linguistique, et pour des tâches de vision par ordinateur. Parlons-en:
Toloka Persona Chat RusUn ensemble de données de 10 000 dialogues aidera les chercheurs des systèmes de dialogue à élaborer des approches de formation des robots de discussion. Nous l'avons préparé en collaboration avec
iPavlov , un projet du Neural Systems and Deep Learning Laboratory du MIPT, qui mène des recherches dans le domaine de l'intelligence artificielle conversationnelle et développe
DeepPavlov , une bibliothèque ouverte pour créer des assistants interactifs. L'ensemble de données Persona Chat Rus contient des profils décrivant la personnalité d'une personne et des dialogues entre les participants à l'étude.
Comment les données ont été collectéesDans un premier temps, avec l'aide des utilisateurs de Toloka, nous avons collecté des profils contenant des informations sur une personne, ses loisirs, sa profession, sa famille et les événements de sa vie, et sélectionné ceux qui conviennent aux dialogues.
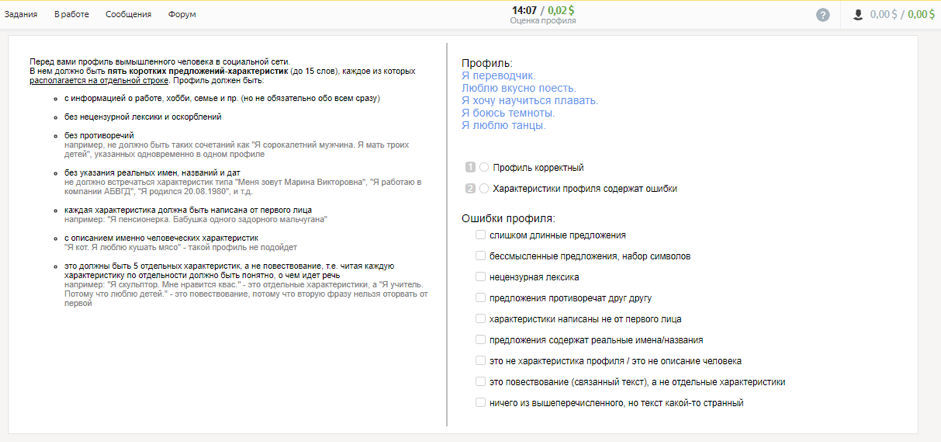
À la deuxième étape, nous avons invité les participants à jouer le rôle de la personne décrite par l'un de ces profils et à communiquer entre eux dans le messager. Le but du dialogue est d'en savoir plus sur l'interlocuteur et de parler de vous. Les dialogues résultants ont été vérifiés par d'autres interprètes.

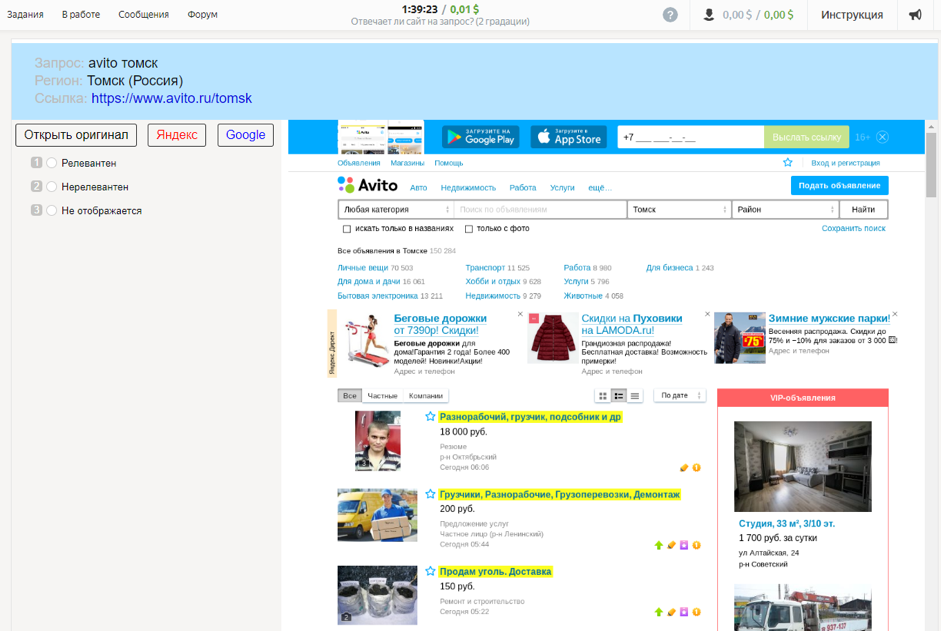
Pertinence de l'agrégation de Toloka 2L'ensemble de données vous permet d'explorer les méthodes de contrôle qualité dans le cadre du crowdsourcing. Il contient près d'un demi-million d'évaluations anonymes d'interprètes recueillies sur le projet «Pertinence (2 graduations)» en 2016. Vous trouverez ici à la fois des évaluations anonymisées de tolokers et des évaluations de référence qui aideront à mesurer la qualité des réponses. L'étude de ces données nous permettra de déterminer comment les opinions des artistes interprètes ou exécutants affectent la qualité de l'évaluation finale, quelles méthodes d'agrégation des résultats sont mieux utilisées et combien d'opinions doivent être collectées afin d'obtenir une réponse fiable.
Comment les données ont été collectéesLe contractant s'est vu proposer la demande et la région de l'utilisateur qui l'a définie, une capture d'écran du document et un lien vers celui-ci, la possibilité d'utiliser des moteurs de recherche et des options de réponse: «Pertinent», «Non pertinent», «Non affiché».
Pertinence de l'agrégation de Toloka 5Cet ensemble de données est le même que le précédent, seules les estimations ici ont été collectées non pas sur un binaire, mais sur une échelle de cinq points dans le projet «Pertinence (5 gradations)». L'ensemble de données contient plus d'un million de notes.
Comment les données ont été collectéesL'évaluation des documents pour cinq grades est plus complexe et nécessite plus de qualifications. Le contractant s'est vu proposer la demande et la région de l'utilisateur qui l'a défini, une capture d'écran du document et un lien vers celui-ci, des boutons pour utiliser les moteurs de recherche et cinq options de réponse: «Vital», «Utile», «Relevant +», «Relevant -», «Irrelevant».

Le principal indicateur de qualité est la précision des réponses agrégées, estimée sur la base des tâches de contrôle (goldensets). Certaines tâches de l'ensemble de données n'ont pas une, mais plusieurs réponses correctes. Chacune de ces réponses est considérée comme correcte. Précision des principales méthodes d'agrégation:
● L'opinion majoritaire est de 89,92%.
● Dawid-Skene - 90,72%.
● GLAD - 90,16%.
Relations lexicales de la sagesse de la foule (LRWC)L'ensemble de données contient les opinions des locuteurs natifs de la langue russe sur la relation genre-espèce entre les mots: le lien entre le général (hyperonyme) et le privé (hyponyme). Recueilli par le chercheur Dmitry Ustalov en 2017.
Comment les données ont été collectéesPour l'étude, 300 des noms les plus utilisés dans les noms russes modernes ont été pris. En utilisant des thésaurus (RuTez, RuWordNet) et des méthodes automatisées pour la formation d'hyperonymes (Watset, Hyperstar), 10 600 paires de genres-espèces (de type «chaton» - «mammifère») ont été obtenues. Les participants à l'étude devaient répondre à la question: «Est-il vrai qu'un chaton est une espèce de mammifère?» Pour formuler correctement la question, des hyperonymes ont été mis dans le cas génitif à l'aide d'un analyseur morphologique et d'un générateur de pymorphy2.
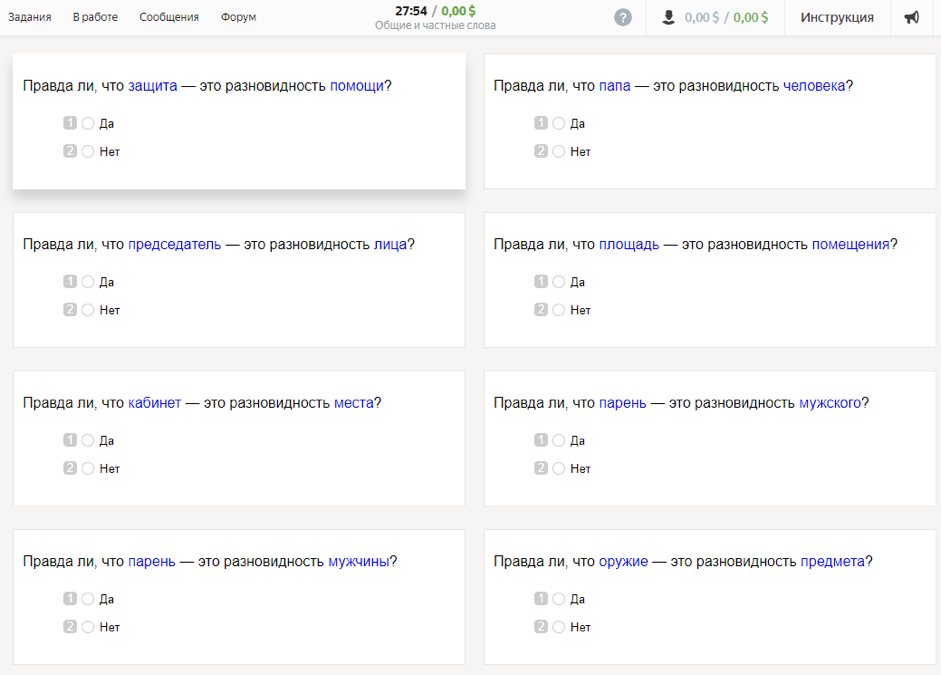
Chaque paire a été marquée par sept artistes russophones âgés de plus de 20 ans. Selon les résultats obtenus après agrégation de toutes les estimations, 4576 paires de mots ont reçu des réponses positives et 6024 - négatives. Fait intéressant, les participants à l'étude étaient plus unanimes à choisir une réponse négative qu'une réponse positive.
Contextes de mots à sens humain et sans ambiguïté pour le russeL'ensemble de données contient 2562 significations contextuelles de 20 mots représentant la plus grande variété de significations sémantiques. L'étude a été réalisée par Dmitry Ustalov en 2017.
Comment les données ont été collectéesOn a montré aux participants à l'étude le mot et un exemple de son utilisation dans la parole. Il était nécessaire de déterminer la signification du mot dans le contexte de l'énoncé et de choisir l'une des options de réponse.

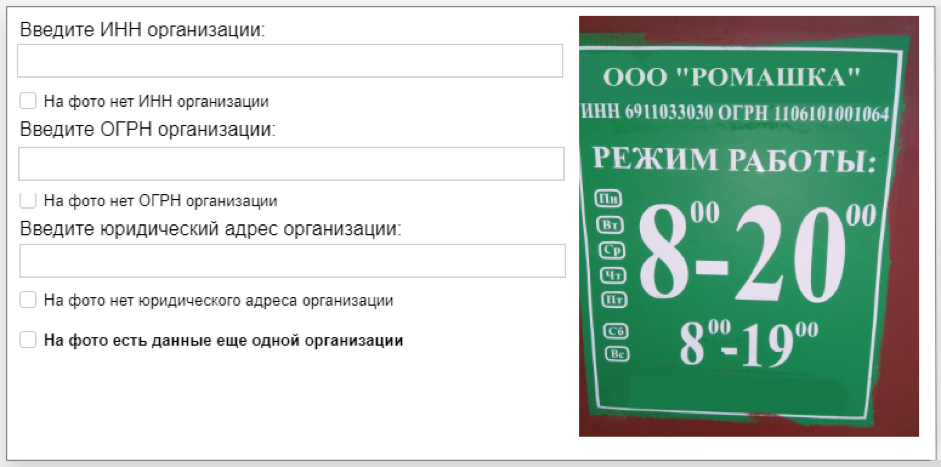
Reconnaissance d'identité d'entreprise TolokaPour cet ensemble de données, nous avons préparé 10 000 photographies de plaques d'information d'organisations et un fichier texte avec des numéros (TIN et PSRN), qui étaient indiqués sur la plaque. Ayant appris de ces données, le modèle de vision par ordinateur sera capable de reconnaître la séquence de nombres dans l'image. L'ensemble de données est fourni par le service Yandex.Directory.
Comment les données ont été collectéesDans un premier temps, nous avons lancé la tâche dans l'application mobile Toloka: les artistes ont été invités à se rendre à l'adresse indiquée sur la carte, à trouver l'organisation et à prendre une photo de sa plaque signalétique. Cette tâche et d'autres tâches sur le terrain aident à maintenir des informations à jour dans Yandex.Directory.
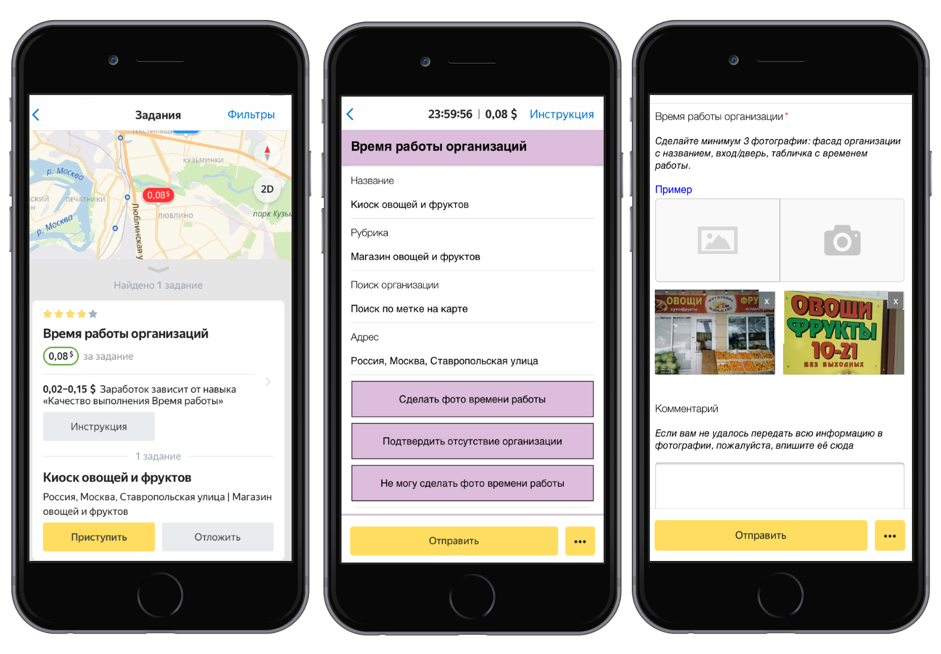
Ensuite, la qualité des tâches terminées a été vérifiée par d'autres interprètes. Nous avons envoyé les photos avec TIN et PSRN pour le décryptage. Tolokers a réimprimé ces chiffres à partir de photos, après quoi nous avons traité les résultats et formé un ensemble de données.
Fonctionnalités d'agrégation TolokaL'ensemble de données contient environ 60 000 évaluations pour 1 000 tâches avec les bonnes réponses pour presque toutes les tâches. Les artistes ont classé les sites en cinq catégories en fonction de la disponibilité du contenu pour adultes. En plus de chaque tâche, 52 indicateurs à valeur réelle sont joints et peuvent être utilisés pour prédire la catégorie.
Vous pouvez sélectionner et télécharger des jeux de données à partir du lien:
https://toloka.yandex.ru/datasets/ . Nous ne prévoyons pas de nous attarder sur ce point et exhortons les chercheurs à prêter attention au crowdsourcing et à parler de leurs projets.