
Salut, habrozhiteli! Nous avons récemment remis un livre de
Chris Richardson à l'imprimerie, dont le but est d'enseigner le développement d'applications réussies à l'aide d'une architecture de microservices. Le livre traite non seulement des avantages, mais aussi des inconvénients des microservices. Vous apprendrez dans quelles situations il est judicieux de les appliquer et quand il vaut mieux penser à une approche monolithique.
Le livre se concentre sur l'architecture et le design. Il est conçu pour toute personne dont les responsabilités incluent l'écriture et la livraison de logiciels, y compris les développeurs, les architectes, les directeurs techniques et les chefs des départements de développement.
Ce qui suit est un extrait du livre Utilisation de la messagerie asynchrone
Utilisation de la messagerie asynchrone pour améliorer la disponibilité
Comme vous l'avez vu, les différents mécanismes IPC vous poussent à divers compromis. L'un d'eux est lié à la façon dont l'IPC affecte l'accessibilité. Dans cette section, vous apprendrez que l'interaction synchrone avec d'autres services dans le cadre du traitement des demandes réduit la disponibilité de l'application. À cet égard, lors de la conception de vos services, vous devez utiliser la messagerie asynchrone autant que possible.
Voyons d'abord quels problèmes l'interaction synchrone crée et comment elle affecte l'accessibilité.
3.4.1. L'interaction synchronisée réduit la disponibilité
REST est un moteur IPC extrêmement populaire. Vous pourriez être tenté de l'utiliser pour la communication interservices. Mais le problème avec REST est qu'il s'agit d'un protocole synchrone: le client HTTP doit attendre que le service renvoie une réponse. Chaque fois que les services communiquent entre eux via un protocole synchrone, cela réduit la disponibilité de l'application.
Pour comprendre pourquoi cela se produit, considérez le scénario illustré à la Fig. 3.15. Le service Order dispose d'une API REST pour créer des commandes. Pour vérifier la commande, il se tourne vers les services Grand Public et Restaurant, qui disposent également d'une API REST.
La création d'une commande comprend cette séquence d'étapes.
- Le client fait une requête HTTP POST / Orders au service Order.
- Le service de commande récupère les informations client en effectuant une demande HTTP GET / consommateurs / id auprès du service consommateur.
- Le service de commande récupère les informations du restaurant en exécutant une demande HTTP GET / restaurant / id au service de restaurant.
- La prise de commande vérifie la demande en utilisant les informations sur le client et le restaurant.
- La prise de commande crée une commande.
- La prise de commande envoie une réponse HTTP au client.
Étant donné que ces services utilisent HTTP, tous doivent être accessibles pour que FTGO traite la demande CreateOrder. Il ne pourra pas créer de commande si au moins un des services n'est pas disponible. D'un point de vue mathématique, la disponibilité d'une opération système est un produit de la disponibilité des services qui y sont impliqués. Si le service Order et les deux services qu'il appelle ont une disponibilité de 99,5%, alors leur disponibilité globale sera de 99,5% 3 = 98,5%, ce qui est beaucoup plus faible. Chaque service ultérieur participant à la demande rend l'opération moins accessible.
Ce problème n'est pas propre aux interactions basées sur REST. La disponibilité diminue chaque fois qu'un service doit recevoir des réponses d'autres services pour répondre à un client. Même la transition vers un style d'interaction demande / réponse en plus des messages asynchrones n'aidera pas ici. Par exemple, si le service Order envoie un message au service Consumer via un courtier et commence à attendre une réponse, sa disponibilité se détériorera.
Si vous souhaitez maximiser l'accessibilité, minimisez la quantité d'interaction synchrone. Voyons comment faire.
3.4.2. Débarrassez-vous de l'interaction synchrone
Il existe plusieurs façons de réduire la quantité d'interaction synchrone avec d'autres services lors du traitement des demandes synchrones. Premièrement, pour éviter complètement ce problème, tous les services peuvent être fournis avec des API exclusivement asynchrones. Mais ce n'est pas toujours possible. Par exemple, les API publiques adhèrent généralement à la norme REST. Par conséquent, certains services doivent disposer d'API synchrones.
Heureusement, pour traiter des requêtes synchrones, il n'est pas nécessaire de les exécuter vous-même. Parlons de ces options.
Utilisation de styles d'interaction asynchronesIdéalement, toutes les interactions devraient se produire dans le style asynchrone décrit plus haut dans ce chapitre. Imaginez, par exemple, que le client d'application FTGO utilise un style d'interaction demande / réponse asynchrone pour créer des commandes. Pour créer une commande, il envoie un message de demande au service Commande. Ensuite, ce service échange de manière asynchrone des messages avec d'autres services et renvoie éventuellement une réponse au client (Fig. 3.16).
Le client et le service communiquent de manière asynchrone, envoyant des messages via des canaux. Aucun des participants à cette interaction n'est bloqué en attente d'une réponse.
Une telle architecture serait extrêmement robuste, car le courtier met en mémoire tampon les messages jusqu'à ce que leur consommation soit possible. Mais le problème est que les services ont souvent une API externe qui utilise un protocole synchrone comme REST et, par conséquent, doit immédiatement répondre aux demandes.
Si le service dispose d'une API synchrone, l'accessibilité peut être améliorée grâce à la réplication des données. Voyons comment cela fonctionne.
Réplication de donnéesUne façon de minimiser l'interaction synchrone pendant le traitement des requêtes consiste à répliquer les données. Le service stocke une copie (réplique) des données dont il a besoin pour traiter les demandes. Pour maintenir la réplique à jour, il souscrit aux événements publiés par les services auxquels appartiennent ces données. Par exemple, un service Commande peut stocker une copie des données appartenant aux services Consommateur et Restaurant. Cela lui permettra de traiter les demandes de création de commandes sans avoir recours à ces services. Une telle architecture est illustrée à la fig. 3.17.
Les services Consumer et Restaurant publient des événements chaque fois que leurs données changent. Le service de commande s'abonne à ces événements et met à jour sa réplique.
Dans certains cas, la réplication de données est une bonne solution. Par exemple, le chapitre 5 décrit comment le service de commande réplique les données du service de restaurant pour pouvoir vérifier les éléments de menu. L'un des inconvénients de cette approche est qu'elle nécessite parfois de copier de grandes quantités de données, ce qui est inefficace. Par exemple, si nous avons de nombreux clients, le stockage d'une réplique des données appartenant au service Consommateur peut s'avérer peu pratique. Un autre inconvénient de la réplication réside dans le fait qu'elle ne résout pas le problème de mise à jour des données appartenant à d'autres services.
Pour résoudre ce problème, un service peut retarder l'interaction avec d'autres services jusqu'à ce qu'il réponde à son client. Ceci sera discuté plus loin.
Terminer le traitement après avoir renvoyé une réponseUne autre façon d'éliminer l'interaction synchrone pendant le traitement des requêtes consiste à effectuer ce traitement sous la forme des étapes suivantes.
- Le service vérifie la demande uniquement à l'aide des données disponibles localement.
- Il met à jour sa base de données, y compris en ajoutant des messages à la table OUTBOX.
- Renvoie la réponse à son client.
Pendant le traitement de la demande, le service n'accède à aucun autre service de manière synchrone. Au lieu de cela, il leur envoie des messages asynchrones. Cette approche offre une mauvaise connectivité des services. Comme vous le verrez dans le chapitre suivant, ce processus est souvent implémenté comme un récit.
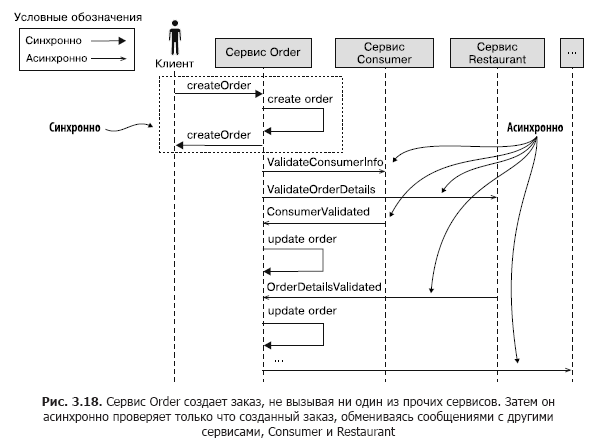
Imaginez que le service Order agisse de cette manière. Il crée une commande avec le statut PENDING puis la vérifie en échangeant des messages asynchrones avec d'autres services. Dans la fig. La figure 3.18 montre ce qui se passe lorsque l'opération createOrder () est appelée. La chaîne d'événements ressemble à ceci.
- Le service Commande crée une commande avec le statut EN ATTENTE.
- Le service de commande renvoie une réponse avec l'ID de commande à son client.
- Le service Order envoie un message ValidateConsumerInfo au service Consumer.
- Le service Order envoie un message ValidateOrderDetails au service Restaurant.
- Le service Consumer reçoit un message ValidateConsumerInfo, vérifie si le client peut passer une commande et envoie un message ConsumerValidated au service Order.
- Le service de restauration reçoit un message ValidateOrderDetails, vérifie l'exactitude des éléments du menu et la capacité du restaurant à livrer une commande à une adresse donnée, et envoie un message OrderDetailsValidated au service de commande.
- Le service de commande reçoit les messages ConsumerValidated et OrderDetailsValidated et change le statut de la commande en VALIDATED.
Et ainsi de suite ...
Le service de commande peut recevoir des messages ConsumerValidated et OrderDetailsValidated dans n'importe quelle commande. Pour savoir lequel il a reçu en premier, il modifie le statut de la commande. Si le premier message est ConsumerValidated, le statut de la commande passe à CONSUMER_VALIDATED et si OrderDetailsValidated devient ORDER_DETAILS_VALIDATED. Après avoir reçu le deuxième message, le service Order définit le statut de la commande sur VALIDATED.
Après avoir vérifié la commande, le service Order effectue les étapes restantes pour la créer, dont nous parlerons dans le chapitre suivant. Une grande partie de cette approche est que le service Commande peut créer une commande et répondre au client, même si le service Consommateur n'est pas disponible. Tôt ou tard, le service Consommateur récupérera et traitera tous les messages en attente, ce qui achèvera la vérification des commandes.
L'inconvénient de renvoyer une réponse avant que la demande ne soit complètement traitée est qu'elle rend le client plus complexe. Par exemple, lorsque le service Order renvoie une réponse, il donne des garanties minimales sur le statut de la commande qui vient d'être créée. Il répond immédiatement, avant même de vérifier la commande et d'autoriser la carte bancaire du client. Ainsi, pour savoir si la commande a bien été créée, le client doit périodiquement demander des informations ou le service Commande doit lui envoyer un message de notification. Malgré la complexité de cette approche, dans de nombreux cas, il vaut la peine de la préférer, en particulier parce qu'elle prend en compte les problèmes de gestion des transactions distribuées, dont nous discuterons au chapitre 4. Dans les chapitres 4 et 5, je vais démontrer cette technique en utilisant l'exemple du service Order.
Résumé
- L'architecture de microservices est distribuée, la communication interprocessus y joue donc un rôle clé.
- Le développement du service API doit être abordé avec soin et prudence. Il est plus facile d'effectuer des modifications rétrocompatibles, car elles n'affectent pas la façon dont les clients travaillent. Lorsque vous apportez des modifications de rupture à l'API de service, vous devez généralement conserver à la fois l'ancienne et la nouvelle version jusqu'à la mise à jour des clients.
- Il existe de nombreuses technologies IPC, chacune ayant ses propres forces et faiblesses. La décision clé au stade de la conception est le choix entre l'appel de procédure distante synchrone et les messages asynchrones. Les plus simples à utiliser sont les protocoles synchrones comme REST, basés sur l'appel de procédures distantes. Mais idéalement, pour augmenter l'accessibilité, les services devraient communiquer en utilisant la messagerie asynchrone.
- Pour éviter une accumulation de type avalanche de défaillances dans le système, un client utilisant un protocole synchrone doit être capable de gérer des défaillances partielles - le fait que le service appelé soit soit indisponible soit présente une latence élevée. En particulier, lors de l'exécution des demandes, il est nécessaire de compter le temps d'attente, de limiter le nombre de demandes en retard et d'appliquer le modèle «Fuse» afin d'éviter les appels au service défaillant.
- Une architecture utilisant des protocoles synchrones doit inclure un mécanisme de découverte afin que les clients puissent déterminer l'emplacement réseau des instances de service. Le moyen le plus simple est de se concentrer sur le mécanisme de découverte fourni par la plate-forme de déploiement: sur les modèles «Découverte côté serveur» et «Enregistrement tiers». Une approche alternative est l'implémentation de la découverte de service au niveau de l'application: les modèles de découverte du client et d'auto-enregistrement. Cette méthode nécessite plus d'efforts, mais convient aux situations où les services s'exécutent sur plusieurs plates-formes de déploiement.
- Le modèle de message et de canal résume les détails de la mise en œuvre du système de messagerie et devient un bon choix lors de la conception de ce type d'architecture. Plus tard, vous pouvez lier votre architecture à une infrastructure de messagerie spécifique, qui utilise généralement un courtier.
- Une difficulté majeure dans la messagerie est la publication et la mise à jour de la base de données. Une bonne solution consiste à utiliser le modèle de publication d'événements: le message est écrit dans la base de données au tout début dans le cadre de la transaction. Un processus distinct récupère ensuite le message de la base de données à l'aide du modèle Interrogating Publisher ou Transactional Log Tracking et le transmet au courtier.
»Plus d'informations sur le livre sont disponibles sur
le site Web de l'éditeur»
Contenu»
ExtraitPour Khabrozhiteley 30% de réduction sur les livres de précommande sur un coupon -
Microservices