(première partie ici: https://habr.com/en/post/456446/ )
Ceph
Présentation
Le réseau étant l'un des éléments clés de Ceph, et un peu spécifique à notre entreprise, nous allons d'abord vous en parler un peu.
Il y aura beaucoup moins de descriptions de Ceph lui-même, principalement une infrastructure de réseau. Seuls les serveurs Ceph et certaines fonctionnalités des serveurs de virtualisation Proxmox seront décrits.
Donc: La topologie du réseau elle-même est conçue comme Leaf-Spine. L'architecture classique à trois niveaux est un réseau où se trouvent le noyau (routeurs principaux), l' agrégation (routeurs d'agrégation) et directement connecté aux clients Access (routeurs d'accès):
Schéma à trois niveaux
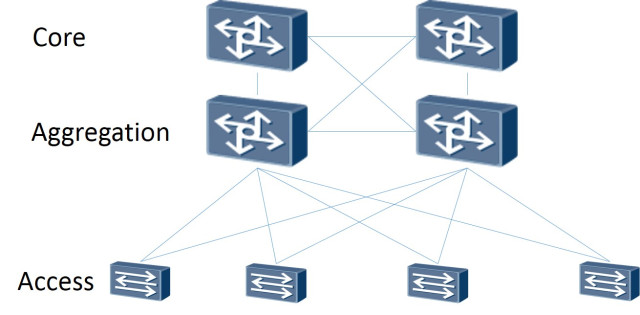
La topologie Leaf-Spine se compose de deux niveaux: Spine (grosso modo le routeur principal) et Leaf (branches).
Schéma à deux niveaux

Tout le routage interne et externe est construit sur BGP. Le système principal qui traite du contrôle d'accès, des annonces et plus est XCloud.
Les serveurs, pour la réservation de canal (et aussi pour son expansion) sont connectés à deux commutateurs L3 (la plupart des serveurs sont connectés aux commutateurs Leaf, mais certains serveurs avec une charge réseau accrue sont connectés directement à la colonne vertébrale du commutateur), et via BGP, annoncer leur adresse de monodiffusion, ainsi que l'adresse anycast pour le service si plusieurs serveurs desservent le trafic de service et que l'équilibrage ECMP leur suffit. Une caractéristique distincte de ce schéma, qui nous a permis d'économiser sur les adresses, mais a également obligé les ingénieurs à se familiariser avec le monde IPv6, était l'utilisation de la norme BGP non numérotée basée sur la RFC 5549. Pendant un certain temps, Quagga a été utilisé pour les serveurs en BGP pour ce schéma pour les serveurs et périodiquement. il y avait des problèmes avec la perte des fêtes et de la connectivité. Mais après le passage à FRRouting (dont les contributeurs actifs sont nos fournisseurs d'équipements réseau: Cumulus et XCloudNetworks), nous n'avons plus observé de tels problèmes.
Pour plus de commodité, nous appelons tout ce schéma général une "usine".
Recherche de chemin
Options de configuration du réseau de cluster:
1) Deuxième réseau sur BGP
2) Le deuxième réseau sur deux commutateurs empilés séparés avec LACP
3) Deuxième réseau sur deux commutateurs isolés séparés avec OSPF
Les tests
Les tests ont été effectués en deux types:
a) réseau utilisant les utilitaires iperf, qperf, nuttcp
b) tests internes Ceph ceph-gobench, banc rados, créé rbd et testé sur eux en utilisant dd dans un ou plusieurs threads, en utilisant fio
Tous les tests ont été effectués sur des machines de test avec des disques SAS. Les chiffres de la performance rbd n'ont pas été beaucoup examinés, ils ont été utilisés uniquement à des fins de comparaison. Intéressé par des changements en fonction du type de connexion.
Première option
Les cartes réseau sont connectées au BGP configuré en usine.
L'utilisation de ce schéma pour le réseau interne n'a pas été considérée comme le meilleur choix:
Tout d'abord, le nombre excessif d'éléments intermédiaires sous forme de commutateurs donnant une latence supplémentaire (c'était la raison principale).
Deuxièmement, au départ, pour diffuser des données statiques via s3, ils ont utilisé une adresse anycast élevée sur plusieurs machines avec radosgateway. Cela a entraîné le fait que le trafic des machines frontales vers RGW n'était pas réparti uniformément, mais passait par le chemin le plus court - c'est-à-dire que Nginx frontal se tournait toujours vers le même nœud avec RGW qui était connecté à la feuille partagée avec lui (cela, bien sûr, était pas l'argument principal - nous avons simplement refusé par la suite à partir des adresses anycast de retourner statique). Mais pour la pureté de l'expérience, ils ont décidé de mener des tests sur un tel schéma afin d'avoir des données à comparer.
Nous avions peur d'exécuter des tests pour toute la bande passante, car l'usine est utilisée par les serveurs prod, et si nous bloquions les liens entre les feuilles et la colonne vertébrale, cela nuirait à certaines ventes.
En fait, c'était une autre raison de rejeter un tel régime.
Des tests Iperf avec une limite BW de 3Gbps de 1, 10 et 100 flux ont été utilisés pour la comparaison avec d'autres schémas.
Les tests ont montré les résultats suivants:
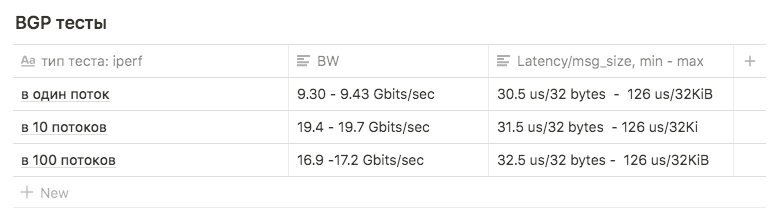
en 1 flux, environ 9,30 - 9,43 Gbits / sec (dans ce cas, le nombre de retransmissions croît fortement, à 39148 ). Le chiffre avéré proche du maximum d'une interface suggère que l'une des deux est utilisée. Le nombre de retransmissions est d'environ 500 à 600.
10 flux de 9,63 Gbits / s par interface, tandis que le nombre de retransmissions est passé à une moyenne de 17045.
en 100 threads, le résultat était pire qu'en 10 , alors que le nombre de retransmissions est moindre: la valeur moyenne est de 3354
Deuxième option
Lacp
Il y avait deux commutateurs Juniper EX4500. Ils les ont rassemblés sur la pile, ont connecté le serveur avec les premiers liens à un commutateur, le second au second.
La configuration de liaison initiale était la suivante:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000
Les tests iperf et qperf ont montré Bw jusqu'à 16 Gbits / sec. Nous avons décidé de comparer différents types de mod:
rr, balance-xor et 802.3ad. Nous avons également comparé différents types de hachage layer2 + 3 et layer3 + 4 (en espérant gagner un avantage sur le hash computing).
Nous avons également comparé les résultats pour différentes valeurs sysctl de la variable net.ipv4.fib_multipath_hash_policy, (enfin, nous avons joué un peu avec net.ipv4.tcp_congestion_control , bien que cela n'ait rien à voir avec la liaison . Il y a un bon article ValdikSS sur cette variable)).
Mais dans tous les tests, cela n'a pas fonctionné pour dépasser le seuil de 18 Gbits / s (ce chiffre a été obtenu en utilisant balance-xor et 802.3ad , il n'y avait pas beaucoup de différence entre les résultats du test) et cette valeur a été atteinte "en saut" par les rafales.
Troisième option
OSPF
Pour configurer cette option, LACP a été supprimé des commutateurs (l'empilement a été laissé, mais il a été utilisé uniquement pour la gestion). Sur chaque commutateur, nous avons collecté un vlan distinct pour un groupe de ports (en pensant à l'avenir que les serveurs QA et PROD seront coincés dans les mêmes commutateurs).
Configuré deux réseaux privés plats pour chaque vlan (une interface par commutateur). En plus de ces adresses se trouve l'annonce d'une autre adresse du troisième réseau privé, qui est le réseau de clusters du CEPH.
Comme le réseau public (via lequel nous utilisons SSH) fonctionne sur BGP, nous avons utilisé frr pour configurer OSPF, qui est déjà sur le système.
10.10.10.0/24 et 20.20.20.0/24 - deux réseaux plats sur les commutateurs
172.16.1.0/24 - réseau pour annonce
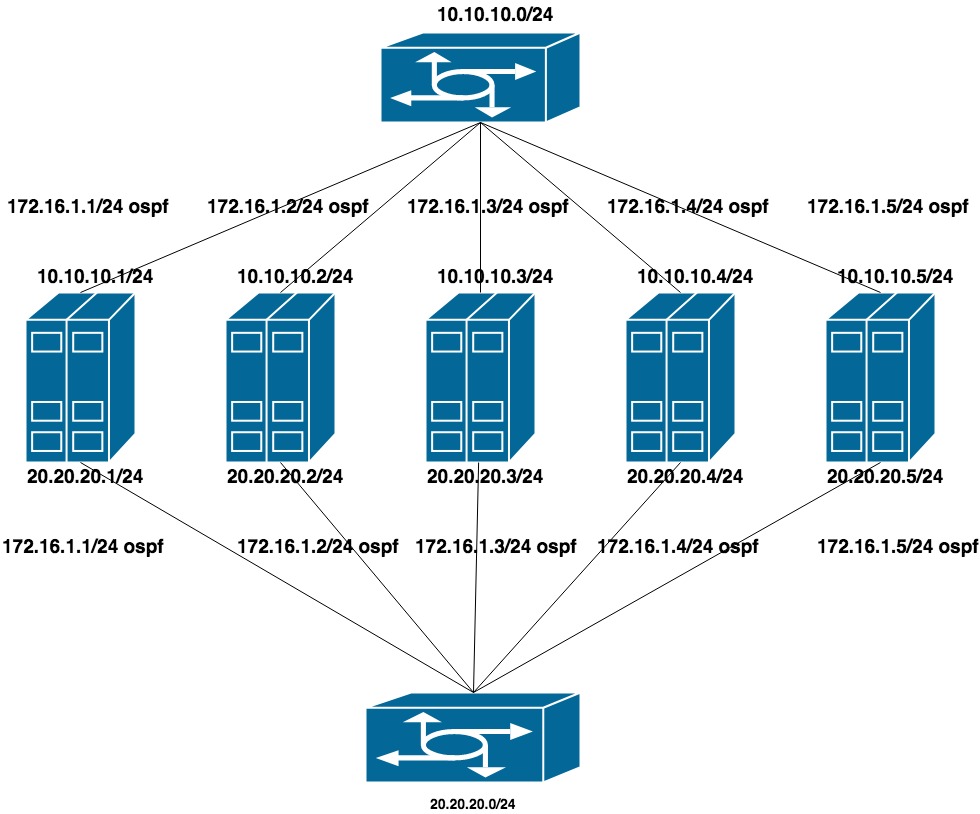
Configuration de la machine:
interfaces ens1f0 ens1f1 regarder un réseau privé
interfaces ens4f0 ens4f1 regarder le réseau public
La configuration réseau sur la machine ressemble à ceci:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32
Les configurations de Frr ressemblent à ceci:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty !
Sur ces paramètres, le réseau teste iperf, qperf, etc. a montré une utilisation maximale des deux canaux à 19,8 Gbit / s, tandis que la latence a chuté à 20us
Champ Bgp router-id: utilisé pour identifier le nœud lors du traitement des informations de routage et de la création de routes. Si elle n'est pas spécifiée dans la configuration, l'une des adresses IP de l'hôte est sélectionnée. Différents fabricants de matériel et de logiciels peuvent avoir des algorithmes différents, dans notre cas, FRR a utilisé la plus grande adresse IP de bouclage. Cela a conduit à deux problèmes:
1) Si nous avons essayé de raccrocher une autre adresse (par exemple, privée du réseau 172.16.0.0) plus que celle actuelle, cela a conduit à un changement d' ID de routeur et, par conséquent, à réinstaller les sessions en cours. Cela signifie une courte interruption et une perte de connectivité réseau.
2) Si nous avons essayé de raccrocher une adresse anycast partagée par plusieurs machines et qu'elle a été sélectionnée en tant qu'ID de routeur , deux nœuds avec le même ID de routeur sont apparus sur le réseau .
2e partie
Après avoir testé QA, nous avons commencé à mettre à niveau le combat Ceph.
RÉSEAU
Passer d'un réseau à deux
Le paramètre réseau du cluster est l'un de ceux qui ne peuvent pas être modifiés à la volée en spécifiant l'OSD via ceph tell osd. * Injectargs. Le changer dans la configuration et redémarrer le cluster entier est une solution tolérable, mais je ne voulais vraiment pas avoir même un petit temps d'arrêt. Il est également impossible de redémarrer un OSD avec un nouveau paramètre réseau - à un moment donné, nous aurions eu deux demi-clusters - d'anciens OSD sur l'ancien réseau, de nouveaux sur le nouveau. Heureusement, le paramètre réseau du cluster (ainsi que public_network, soit dit en passant) est une liste, c'est-à-dire que vous pouvez spécifier plusieurs valeurs. Nous avons décidé de nous déplacer progressivement - ajoutez d'abord un nouveau réseau aux configurations, puis supprimez l'ancien. Ceph passe en revue la liste des réseaux de manière séquentielle - OSD commence à travailler en premier avec le réseau qui est répertorié en premier.
La difficulté était que le premier réseau fonctionnait via bgp et était connecté à un commutateur, et le second - à ospf et connecté à d'autres qui n'étaient pas physiquement connectés au premier. Au moment de la transition, il était nécessaire d'avoir temporairement accès au réseau entre les deux réseaux. La particularité de la configuration de notre usine était que les ACL ne peuvent pas être configurées sur le réseau si elles ne figurent pas dans la liste des publicités (dans ce cas, elles sont «externes» et les ACL car elles ne peuvent être créées qu'en externe. Elle a été créée en Espagne, mais n'est pas arrivée sur feuilles).
La solution était une béquille, compliquée, mais cela a fonctionné: pour annoncer le réseau interne via bgp, simultanément avec ospf.
La séquence de transition est la suivante:
1) Configurer le réseau de cluster pour ceph sur deux réseaux: via bgp et via ospf
Dans les configurations FRR, il n'était pas nécessaire de changer quoi que ce soit, une ligne
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
cela ne nous limite pas dans les adresses annoncées, l'adresse du réseau interne lui-même a été relevée sur l'interface de bouclage, il suffisait de configurer la réception de l'annonce de cette adresse sur les routeurs.
2) Ajoutez un nouveau réseau à la configuration ceph.conf
cluster network = 172.16.1.0/24, 55.66.77.88/27
et commencez à redémarrer l'OSD un par un jusqu'à ce que tout le monde passe au réseau 172.16.1.0/24.
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done
3) Ensuite, nous supprimons le réseau en excès de la configuration
cluster network = 172.16.1.0/24
et répétez la procédure.
C'est tout, nous avons déménagé en douceur vers un nouveau réseau.
Références:
https://shalaginov.com/2016/03/26/network-topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench