Dans cet article, je parlerai de la façon dont le projet dans lequel je travaille s'est transformé d'un grand monolithe en un ensemble de microservices.
Le projet a commencé son histoire il y a longtemps, au début de 2000. Les premières versions ont été écrites en Visual Basic 6. Au fil du temps, il est devenu clair que le développement de ce langage à l'avenir serait difficile à prendre en charge, car l'IDE et le langage lui-même sont peu développés. À la fin des années 2000, il a été décidé de passer à un C # plus prometteur. La nouvelle version a été écrite en parallèle avec le raffinement de l'ancienne, progressivement le code était de plus en plus sur .NET. Le backend en C # s'est initialement concentré sur l'architecture de service, cependant, pendant le développement, des bibliothèques partagées avec logique ont été utilisées et les services ont été lancés en un seul processus. Il s'est avéré que l'application, que nous avons appelé le «monolithe de service».
L'un des rares avantages de cet ensemble était la capacité des services à s'appeler via une API externe. Il y avait des conditions préalables évidentes pour la transition vers un service plus correct et, à l'avenir, une architecture de microservices.
Nous avons commencé notre travail de décomposition vers 2015. Nous n'avons pas encore atteint un état idéal - il y a des parties d'un grand projet qui sont difficiles à appeler des monolithes, mais elles ne ressemblent pas non plus à des microservices. Cependant, les progrès sont substantiels.
Je vais parler de lui dans l'article.
Table des matières
Architecture et problèmes de la solution existante
Initialement, l'architecture ressemblait à ceci: l'interface utilisateur est une application distincte, la partie monolithique est écrite en Visual Basic 6, l'application en .NET était un ensemble de services associés qui fonctionne avec une base de données assez importante.
Inconvénients de la solution précédentePoint de défaillance uniqueNous avions un seul point de défaillance: l'application .NET a fonctionné en un seul processus. Si l'un des modules tombait en panne, l'application entière échouait et vous deviez la redémarrer. Étant donné que nous automatisons un grand nombre de processus pour différents utilisateurs, en raison d'une défaillance de l'un d'entre eux, certains n'ont pas pu fonctionner pendant un certain temps. Et avec une erreur logicielle, la redondance n'a pas aidé non plus.
La gamme d'améliorationsCette faille est plutôt organisationnelle. Notre application compte de nombreux clients, et ils souhaitent tous la finaliser dans les meilleurs délais. Auparavant, il était impossible de le faire en parallèle et tous les clients faisaient la queue. Ce processus a eu un effet négatif sur l'entreprise, car ils devaient prouver que leur tâche était valable. Et l'équipe de développement a passé du temps à organiser cette programmation. Cela a pris beaucoup de temps et d'efforts, et le produit n'a donc pas pu changer aussi rapidement qu'il l'aurait été de lui.
Utilisation inappropriée des ressourcesLorsque vous placez des services dans un seul processus, nous copions toujours complètement la configuration d'un serveur à l'autre. Nous voulions placer les services les plus chargés séparément pour ne pas gaspiller les ressources et obtenir une gestion plus flexible de notre schéma de déploiement.
Il est difficile d'introduire la technologie moderneUn problème familier à tous les développeurs: il y a une volonté d'introduire des technologies modernes dans le projet, mais il n'y a aucune possibilité. Avec une grande solution monolithique, toute mise à jour de la bibliothèque actuelle, sans parler de la transition vers une nouvelle, devient une tâche plutôt banale. Il faut beaucoup de temps pour prouver au chef d'équipe qu'il apportera plus de bonus que de nerfs épuisés.
Difficulté à émettre des modificationsC'était le problème le plus grave - nous avons publié des versions tous les deux mois.
Chaque version s'est transformée en un véritable désastre pour la banque, malgré les tests et les efforts des développeurs. Les entreprises ont compris qu'au début de la semaine, certaines fonctionnalités ne fonctionneraient pas pour lui. Et les développeurs ont compris qu'ils attendaient une semaine d'incidents graves.
Tout le monde avait envie de changer la situation.
Attentes en matière de microservices
Livraison des composants selon disponibilité. Livraison des composants à mesure qu'ils deviennent disponibles en raison de la décomposition de la solution et de la séparation des différents processus.
Petites équipes alimentaires. Ceci est important car une grande équipe travaillant sur un ancien monolithe était difficile à gérer. Une telle équipe a été contrainte de travailler selon un processus strict, mais je voulais plus de créativité et d'indépendance. Seules de petites équipes pouvaient se le permettre.
Isolement des services dans des processus séparés. Idéalement, je voulais isoler dans des conteneurs, mais un grand nombre de services écrits dans le .NET Framework s'exécutent uniquement sous Windows. Il existe maintenant des services sur .NET Core, mais jusqu'à présent, ils sont peu nombreux.
Flexibilité de déploiement. Je voudrais combiner les services selon nos besoins, et non comme les forces du code.
Utilisation des nouvelles technologies. C'est intéressant pour tout programmeur.
Problèmes de transition
Bien sûr, s'il était simple de casser un monolithe en microservices, vous n'auriez pas à en parler lors de conférences et à écrire des articles. Dans ce processus, il y a de nombreux pièges, je décrirai les principaux qui nous ont gênés.
Le premier problème est typique de la plupart des monolithes: la cohérence de la logique métier. Lorsque nous écrivons un monolithe, nous voulons réutiliser nos classes afin de ne pas écrire de code supplémentaire. Et lors du passage aux microservices, cela devient un problème: tout le code est assez étroitement connecté, et il est difficile de séparer les services.
Au moment du début des travaux, le référentiel comptait plus de 500 projets et plus de 700 mille lignes de code. Il s'agit d'une solution assez importante et du
deuxième problème . Il n'était pas possible de simplement le prendre et de le diviser en microservices.
Le troisième problème est le manque d'infrastructures nécessaires. En fait, nous avons participé à la copie manuelle du code source sur les serveurs.
Comment passer du monolith aux microservices
Allocation de microservicesPremièrement, nous avons immédiatement déterminé par nous-mêmes que la séparation des microservices est un processus itératif. Nous avons toujours été tenus de mener en parallèle le développement de tâches commerciales. La façon dont nous procéderons techniquement est déjà notre problème. Par conséquent, nous nous préparions pour le processus itératif. Cela ne fonctionnera pas différemment si vous avez une grande application, et elle n'est pas prête à être réécrite dès le début.
Quelles méthodes utilisons-nous pour isoler les microservices?
La première consiste à porter les modules existants en tant que services. À cet égard, nous avons eu de la chance: il y avait déjà des services formalisés qui fonctionnaient sur le protocole WCF. Ils ont été affichés dans des assemblées distinctes. Nous les avons déplacés séparément, en ajoutant un petit lanceur à chaque assemblage. Il a été écrit à l'aide de la merveilleuse bibliothèque Topshelf, qui vous permet d'exécuter l'application à la fois en tant que service et console. Ceci est pratique pour le débogage, car aucun projet supplémentaire n'est requis dans la solution.
Les services étaient connectés selon la logique métier, car ils utilisaient des assemblages communs et fonctionnaient avec une base de données commune. Il était difficile de les appeler microservices à l'état pur. Néanmoins, nous pourrions émettre ces services séparément, dans différents processus. Cela a déjà permis de réduire leur influence les uns sur les autres, réduisant le problème du développement parallèle et d'un point de défaillance unique.
Construire avec un hôte n'est qu'une ligne de code dans la classe Program. Nous avons caché Topshelf dans une classe d'aide.
namespace RBA.Services.Accounts.Host { internal class Program { private static void Main(string[] args) { HostRunner<Accounts>.Run("RBA.Services.Accounts.Host"); } } }
La deuxième façon d'isoler les microservices: créez-les pour résoudre de nouveaux problèmes. Si le monolithe ne croît pas en même temps, c'est déjà excellent, ce qui signifie que nous allons dans la bonne direction. Pour résoudre de nouveaux problèmes, nous avons essayé de faire des services séparés. S'il y avait une telle opportunité, alors nous avons créé plus de services «canoniques» qui contrôlent complètement leur modèle de données, une base de données distincte.
Comme beaucoup, nous avons commencé avec les services d'authentification et d'autorisation. Ils sont parfaits pour cela. Ils sont indépendants, en règle générale, ils ont un modèle de données distinct. Ils n'interagissent pas eux-mêmes avec le monolithe, seulement il se tourne vers eux pour résoudre certains problèmes. Sur ces services, vous pouvez commencer la transition vers une nouvelle architecture, déboguer l'infrastructure sur ceux-ci, essayer certaines approches liées aux bibliothèques réseau, etc. Dans notre organisation, il n'y a pas d'équipes qui n'ont pas pu faire un service d'authentification.
La troisième façon d'isoler les microservices que nous utilisons nous est un peu spécifique. Cela extrait la logique métier de la couche d'interface utilisateur. Nous avons la principale interface utilisateur de bureau, comme le backend, elle est écrite en C #. Les développeurs faisaient périodiquement des erreurs et exécutaient les parties de l'interface utilisateur de la logique qui auraient dû exister dans le backend et être réutilisées.
Si vous regardez un exemple réel du code de la partie d'interface utilisateur, vous pouvez voir que la plupart de cette solution contient une logique métier réelle, qui est utile dans d'autres processus, non seulement pour créer un formulaire d'interface utilisateur.
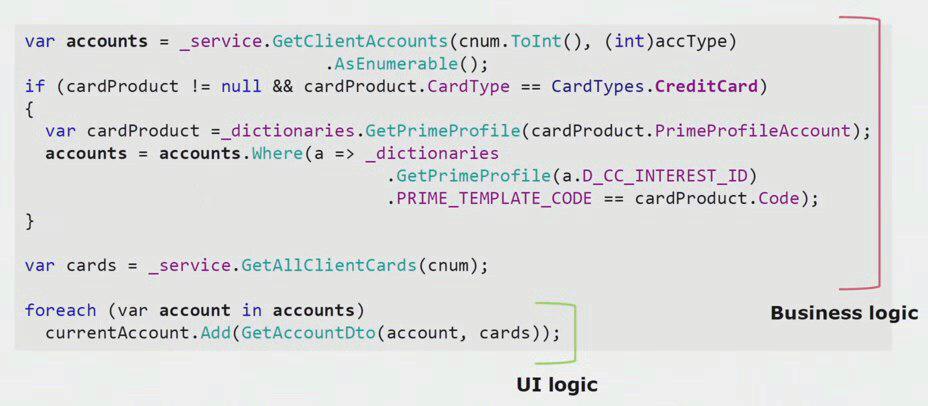
La vraie logique d'interface utilisateur, il n'y a que les deux dernières lignes. Nous l'avons transféré sur le serveur afin de pouvoir le réutiliser, réduisant ainsi l'interface utilisateur et obtenant la bonne architecture.
Le quatrième moyen le plus important d'isoler les microservices , qui vous permet de réduire le monolithe, est la suppression des services existants avec le traitement. Lorsque nous supprimons les modules existants tels quels, le résultat n'est pas toujours agréable pour les développeurs et le processus métier à partir du moment où la fonctionnalité a été créée peut devenir obsolète. Grâce au refactoring, nous pouvons soutenir un nouveau processus métier car les exigences métiers sont en constante évolution. Nous pouvons améliorer le code source, supprimer les défauts connus, créer un meilleur modèle de données. Il y a beaucoup d'avantages.
Le département des services de traitement est inextricablement lié à la notion de contexte limité. Il s'agit d'un concept de conception orientée sujet. Cela signifie une section de modèle de domaine dans laquelle tous les termes d'une seule langue sont définis de manière unique. Prenons le contexte de l'assurance et des factures comme exemple. Nous avons une application monolithique, et il faut travailler avec le compte en assurance. Nous nous attendons à ce que le développeur trouve la classe «Account» existante dans un autre assembly, fasse un lien vers celle-ci à partir de la classe «Insurance» et nous obtiendrons un code de travail. Le principe DRY sera respecté, la tâche grâce à l'utilisation du code existant se fera plus rapidement.
En conséquence, il s'avère que les contextes des comptes et des assurances sont liés. Lorsque de nouvelles exigences apparaissent, cette connexion interfère avec le développement, augmentant la complexité d'une logique métier déjà complexe. Pour résoudre ce problème, vous devez trouver les limites entre les contextes dans le code et supprimer leurs violations. Par exemple, dans le contexte de l'assurance, il est fort possible que le numéro de compte à 20 chiffres de la Banque centrale et la date d'ouverture du compte soient suffisants.
Afin de séparer ces contextes limités les uns des autres et de commencer le processus d'extraction des microservices d'une solution monolithique, nous avons utilisé une approche telle que la création d'API externes au sein de l'application. Si nous savions qu'un module devait devenir un microservice, changer d'une manière ou d'une autre au sein du processus, nous avons immédiatement fait des appels à la logique, qui appartient à un autre contexte limité, via des appels externes. Par exemple, via REST ou WCF.
Nous avons décidé par nous-mêmes que nous n'éviterions pas le code qui nécessiterait des transactions distribuées. Dans notre cas, il s'est avéré assez facile de suivre cette règle. Nous n'avons toujours pas rencontré de telles situations lorsque des transactions distribuées en dur sont vraiment nécessaires - la cohérence finale entre les modules est tout à fait suffisante.
Prenons un exemple spécifique. Nous avons le concept d'un orchestre - convoyeur, qui traite l'essence de la «demande». Il crée à tour de rôle un client, un compte et une carte bancaire. Si le client et le compte ont été créés avec succès et que la création de la carte a échoué, l'application ne passe pas au statut "avec succès" et reste au statut "carte non créée". À l'avenir, l'activité en arrière-plan la récupérera et la terminera. Le système est dans un état d'incohérence depuis un certain temps, mais cela, dans l'ensemble, nous convient.
Si, néanmoins, une situation se présente où il sera nécessaire de sauvegarder systématiquement une partie des données, nous irons très probablement élargir le service afin de le traiter en un seul processus.
Prenons un exemple d'allocation de microservices. Comment peut-il être mis en production en toute sécurité? Dans cet exemple, nous avons une partie distincte du système - le module de service des salaires, une des sections du code dont nous aimerions faire un microservice.
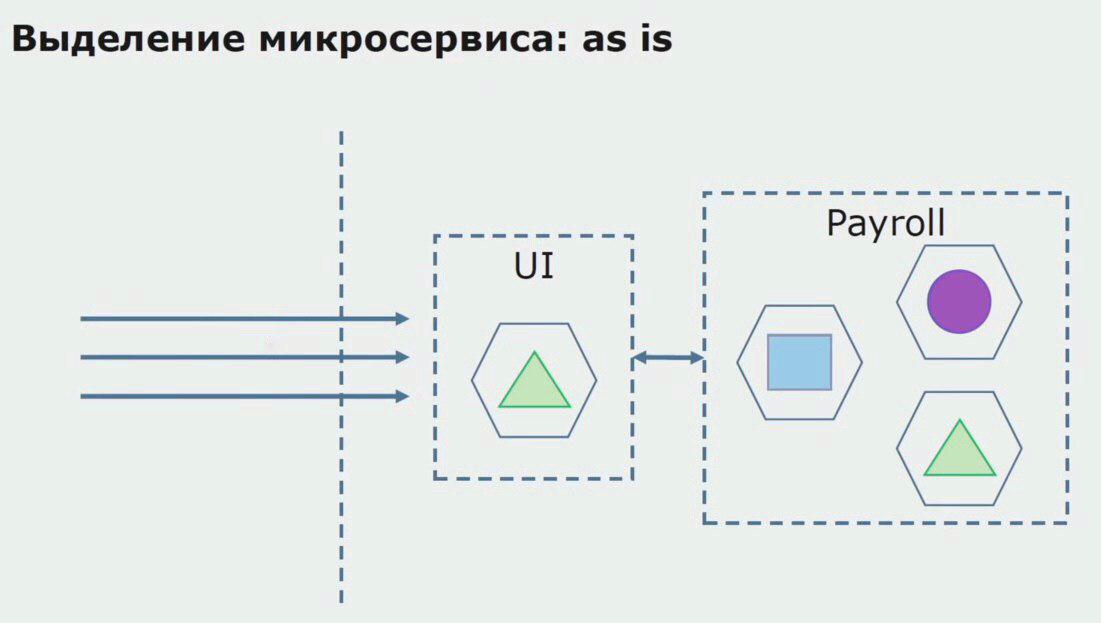
Tout d'abord, nous créons un microservice en réécrivant le code. Nous améliorons certains points qui ne nous convenaient pas. Nous réalisons de nouvelles exigences commerciales du client. Nous ajoutons à l'ensemble entre l'interface utilisateur et le backend API Gateway, qui fournira le transfert d'appel.
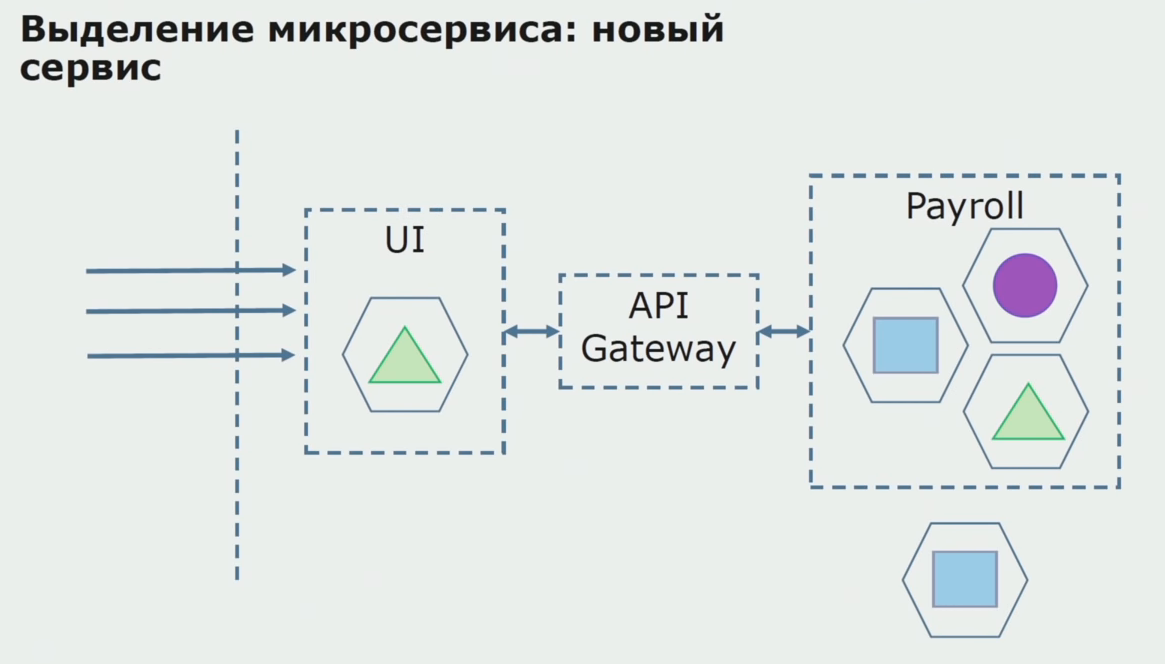
Ensuite, nous libérons cette configuration en fonctionnement, mais dans l'état du pilote. La plupart de nos utilisateurs travaillent toujours avec d'anciens processus métier. Pour les nouveaux utilisateurs, nous développons une nouvelle version d'une application monolithique que ce processus ne contient plus. En fait, nous avons un tas de monolithes et de microservices fonctionnant sous la forme d'un pilote.
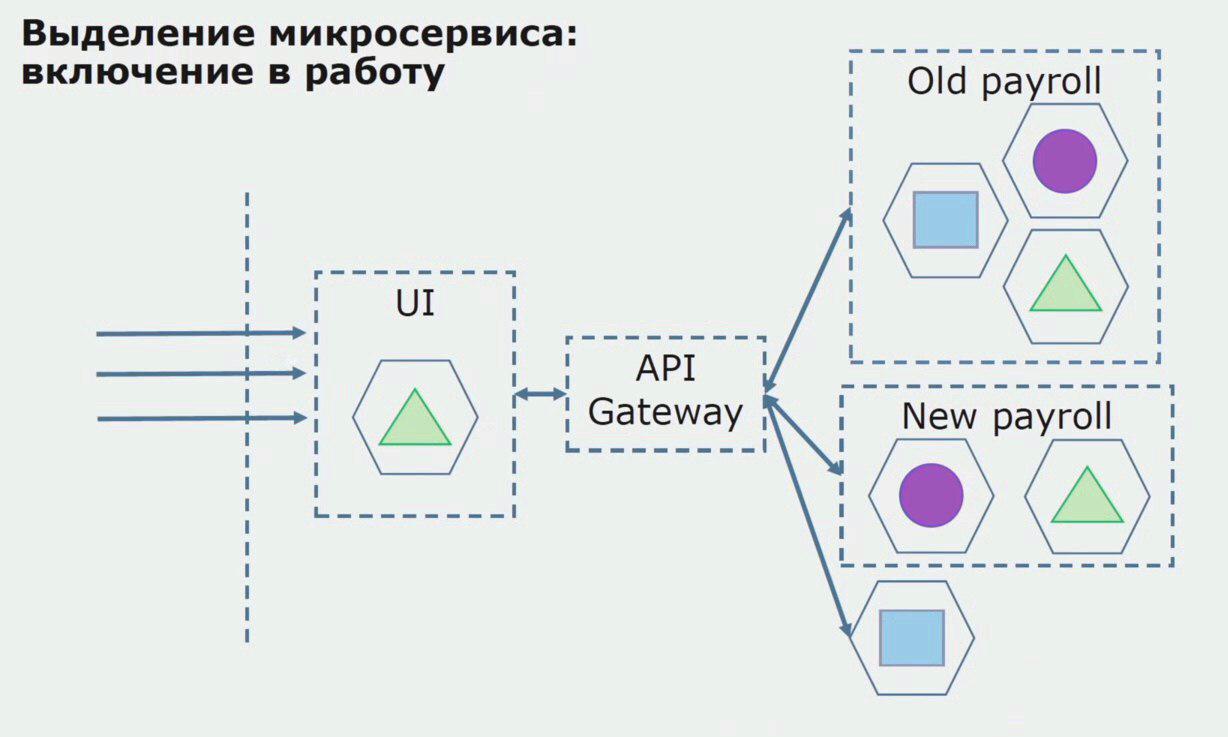
Avec un pilote réussi, nous comprenons que la nouvelle configuration est vraiment opérationnelle, nous pouvons retirer l'ancien monolithe de l'équation et laisser la nouvelle configuration à la place de l'ancienne solution.
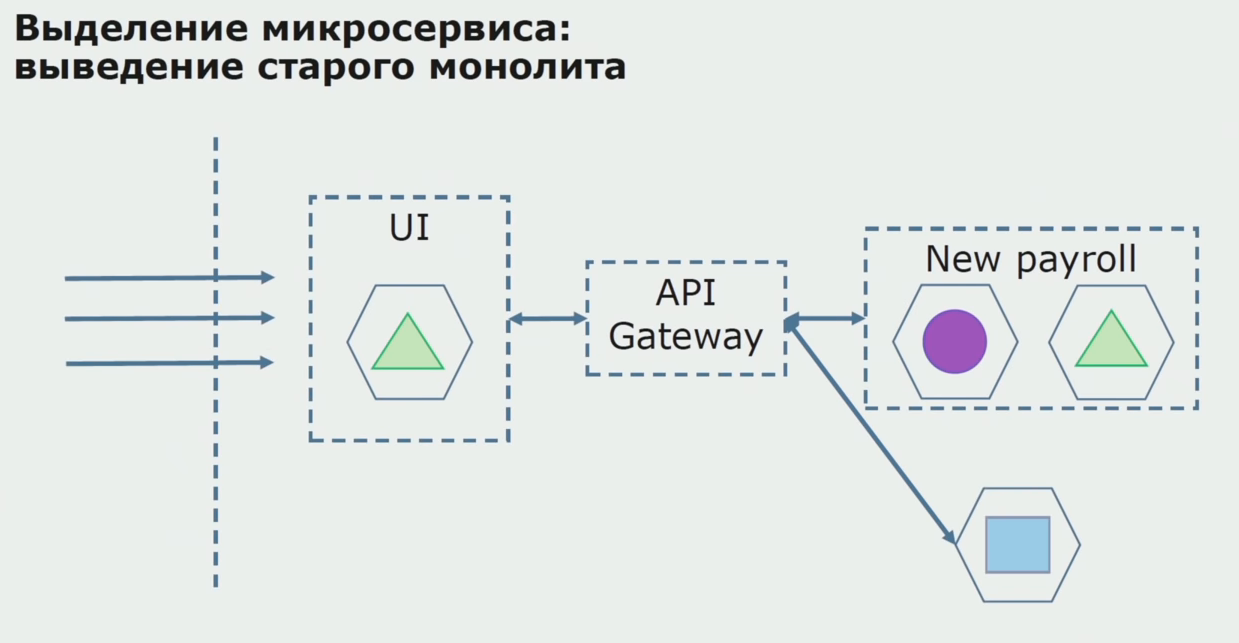
Au total, nous utilisons presque toutes les méthodes existantes pour diviser le code source d'un monolithe. Tous nous permettent de réduire la taille des parties de l'application et de les transférer vers de nouvelles bibliothèques, ce qui améliore le code source.
Travailler avec une base de données
La base de données peut être divisée pire que le code source, car elle contient non seulement le schéma actuel, mais aussi les données historiques accumulées.
Notre base de données, comme beaucoup d'autres, avait un autre inconvénient important - sa taille énorme. Cette base de données a été conçue conformément à la logique métier complexe du monolithe, et des liens se sont accumulés entre des tables de divers contextes limités.
Dans notre cas, en plus de tous les problèmes (une grande base de données, de nombreuses relations, des frontières parfois incompréhensibles entre les tables), un problème est survenu dans de nombreux grands projets: l'utilisation du modèle de base de données partagée. Les données ont été extraites des tables via la vue, la réplication et expédiées à d'autres systèmes où cette réplication est nécessaire. Par conséquent, nous n'avons pas pu retirer les tableaux dans un schéma distinct, car ils étaient activement utilisés.
La séparation nous aide à nous séparer dans des contextes limités dans le code. Cela nous donne généralement une assez bonne idée de la façon dont nous divisons les données au niveau de la base de données. Nous comprenons quels tableaux se rapportent à un contexte limité et lesquels se rapportent à un autre.
Nous avons appliqué deux méthodes globales pour partitionner la base de données: partitionner les tables existantes et partitionner avec le traitement.
La séparation des tables existantes est une méthode qui est bonne à utiliser si la structure des données est de haute qualité, répond aux exigences de l'entreprise et convient à tout le monde. Dans ce cas, nous pouvons sélectionner les tables existantes dans un schéma séparé.
Un département de traitement est nécessaire lorsque le modèle économique a beaucoup changé et que les tableaux ne nous satisfont plus complètement.
Séparez les tables existantes. Nous devons déterminer ce que nous allons séparer. Sans cette connaissance, rien n'en sortira, et ici la séparation de contextes limités dans le code nous aidera. En règle générale, s'il est possible de comprendre les limites des contextes dans le code source, il devient clair quels tableaux doivent être inclus dans la liste pour la séparation.
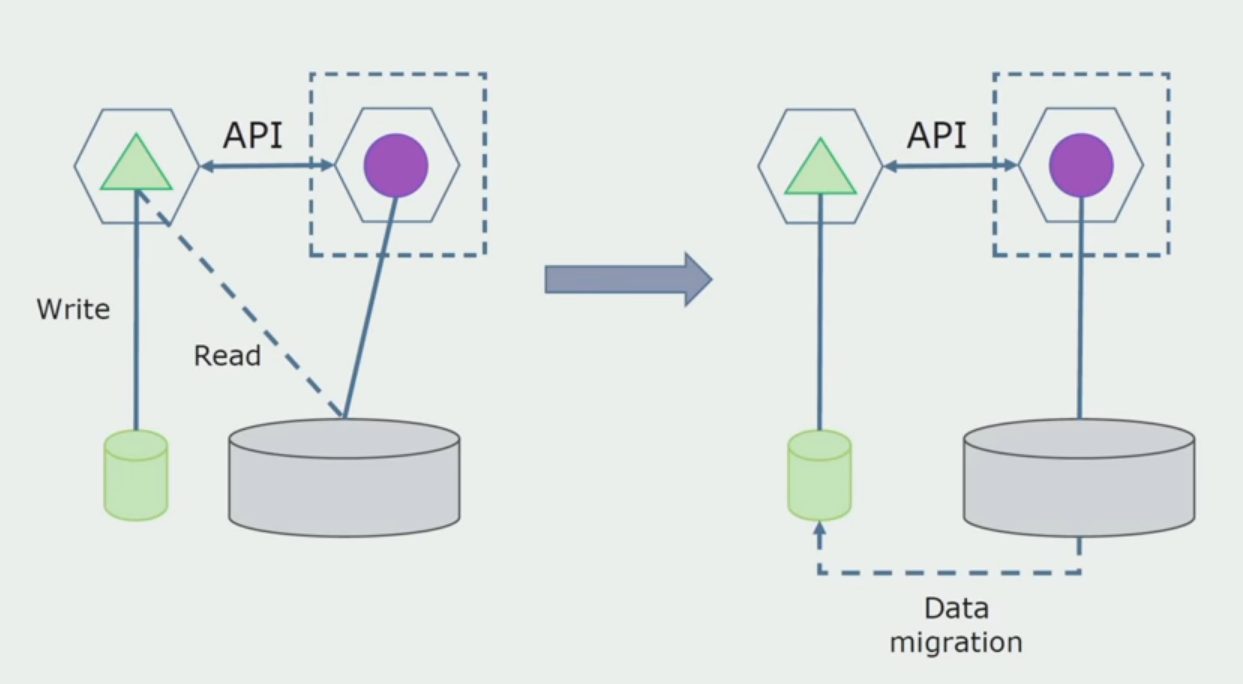
Imaginez que nous ayons une solution dans laquelle deux modules monolithes interagissent avec une base de données. Nous devons nous assurer qu'un seul module interagit avec la partie des tables séparées et que l'autre commence à interagir avec lui via l'API. Pour commencer, il suffit que seule une entrée soit effectuée via l'API. C'est une condition nécessaire pour qu'on puisse parler de l'indépendance des microservices. La lecture des liens peut rester jusqu'à ce qu'il y ait un gros problème.

À l'étape suivante, nous pouvons déjà sélectionner une section de code qui fonctionne avec des tables séparables avec ou sans traitement dans un microservice distinct et l'exécuter dans un processus distinct, un conteneur. Ce sera un service distinct avec communication avec la base de données monolithique et les tables qui ne lui sont pas directement liées. Le monolithe interagit toujours avec la partie détachable pour la lecture.

Plus tard, nous supprimerons cette connexion, c'est-à-dire que la lecture des données de l'application monolithique à partir des tables séparées sera également transférée vers l'API.
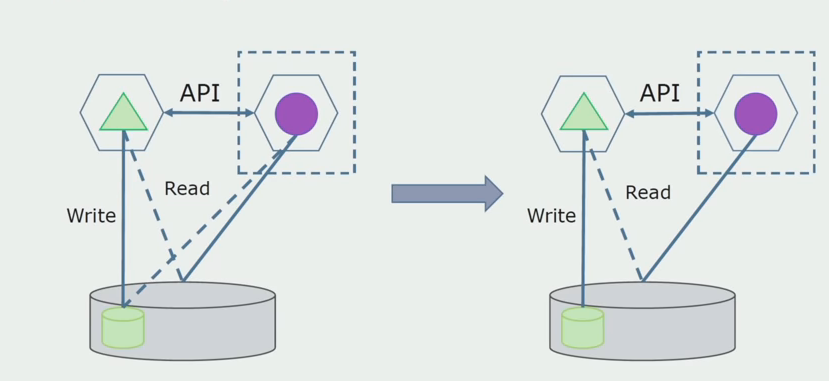
Ensuite, nous sélectionnons dans la base de données générale les tables avec lesquelles seul le nouveau microservice fonctionne. Nous pouvons placer des tables dans un schéma séparé ou même dans une base de données physique distincte. Il y avait une connexion pour la lecture entre le microservice et la base de données monolithique, mais il n'y a rien à craindre, dans cette configuration il peut vivre longtemps.
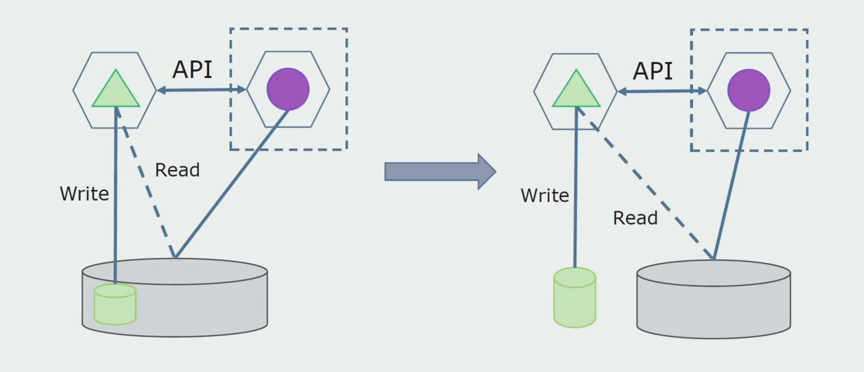
La dernière étape consiste à supprimer complètement toutes les connexions. Dans ce cas, nous devrons peut-être migrer les données de la base de données principale. Parfois, nous voulons réutiliser dans plusieurs bases de données des données ou des répertoires qui sont répliqués à partir de systèmes externes. Nous rencontrons périodiquement cela.
 Département de traitement.
Département de traitement. Cette méthode est très similaire à la première, ne va que dans l'ordre inverse. Nous avons immédiatement une nouvelle base de données et un nouveau microservice qui interagit avec le monolithe via l'API. Mais en même temps, il reste un ensemble de tables de base de données que nous voulons supprimer à l'avenir. Nous n'en aurons plus besoin, dans le nouveau modèle nous l'avons remplacé.
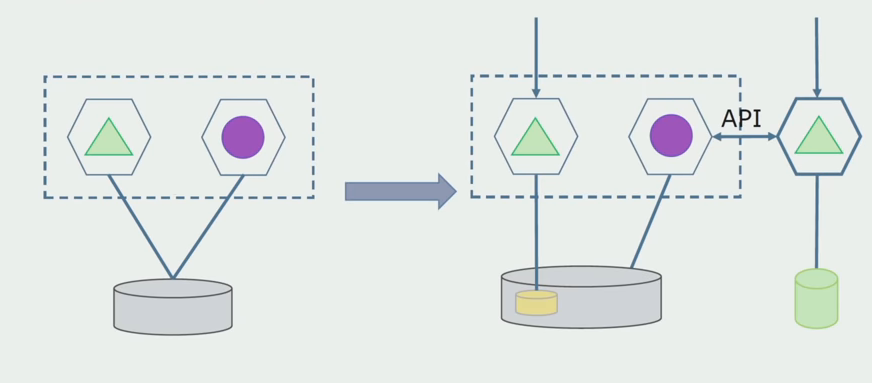
Pour que ce régime fonctionne, nous aurons probablement besoin d'une période de transition.
Il existe deux approches possibles.
Premièrement : nous dupliquons toutes les données dans les nouvelles et anciennes bases de données. Dans ce cas, nous avons une redondance des données, il peut y avoir des problèmes de synchronisation. Mais alors nous pouvons prendre deux clients différents. L'un fonctionnera avec la nouvelle version, l'autre avec l'ancienne.
Deuxièmement : nous partageons les données selon certaines caractéristiques de l'entreprise. Par exemple, dans notre système, 5 produits étaient stockés dans l'ancienne base de données. Le sixième dans le cadre d'une nouvelle tâche commerciale, nous avons mis en place une nouvelle base de données. Mais nous avons besoin de l'API Gateway, qui synchronise ces données et montre au client où et quoi emporter.
Les deux approches fonctionnent, choisissez en fonction de la situation.
Après avoir vérifié que tout fonctionne, la partie du monolithe qui fonctionne avec les anciennes structures de base de données peut être désactivée.
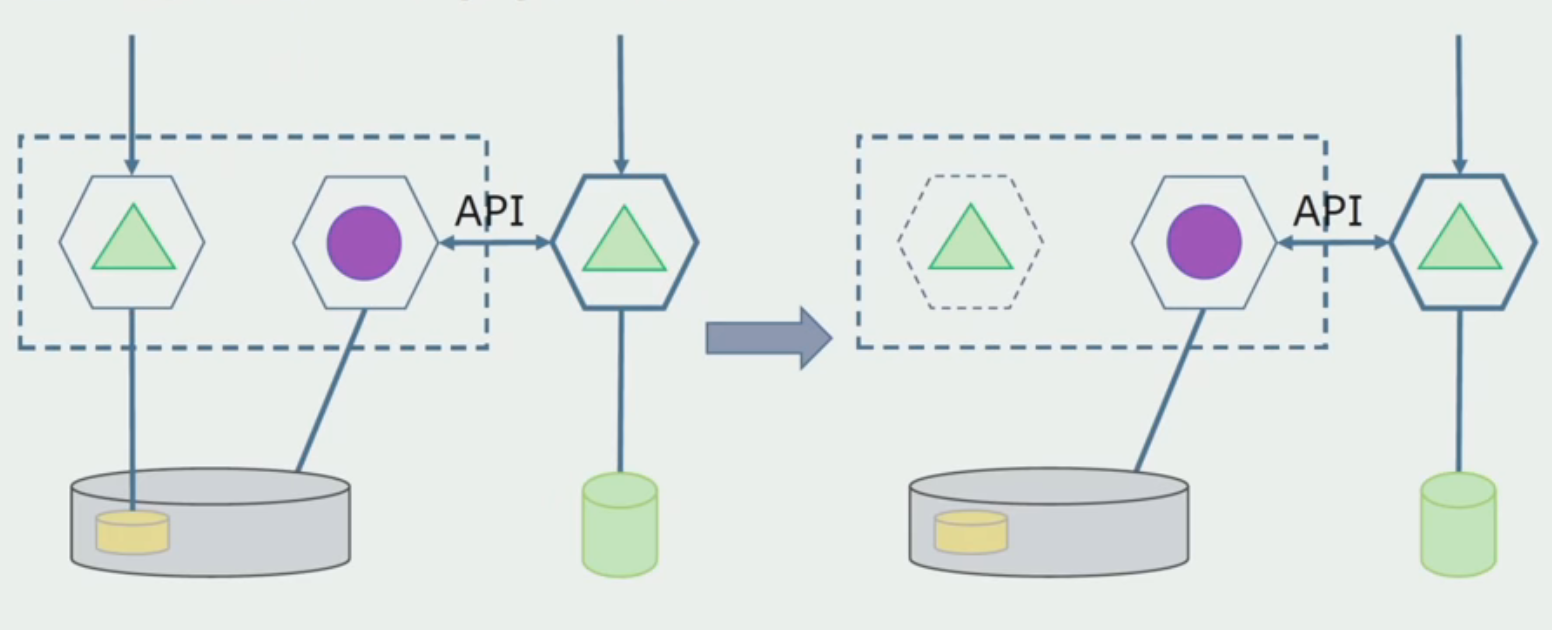
La dernière étape consiste à supprimer les anciennes structures de données.

En résumé, nous pouvons dire que nous avons des problèmes avec la base de données: il est difficile de travailler avec elle par rapport au code source, il est plus difficile de séparer, mais cela peut et doit être fait. Nous avons trouvé quelques moyens qui permettent de le faire en toute sécurité, mais il est plus facile de se tromper avec les données qu'avec le code source.
Travailler avec le code source
Voici à quoi ressemblait le diagramme du code source lorsque nous avons commencé à analyser un projet monolithique.

Elle peut être conditionnellement divisée en trois couches. Il s'agit d'une couche de modules lancés, de plugins, de services et d'activités individuelles. En fait, ce sont les points d'entrée de la solution monolithique. Tous étaient étroitement liés avec une couche commune. Il avait une logique métier partagée entre les services et de nombreuses connexions. Chaque service et plugin utilisait jusqu'à 10 assemblys communs ou plus, selon leur taille et la conscience des développeurs.
Nous avons eu de la chance, nous avions des bibliothèques d'infrastructure qui pouvaient être utilisées séparément.
Parfois, une situation se produisait lorsque certains des objets communs n'appartenaient pas réellement à cette couche, mais étaient des bibliothèques d'infrastructure. Cela a été décidé en renommant.
Les plus préoccupés par les contextes limités. Auparavant, 3-4 contextes se mélangeaient dans un assemblage commun et s'utilisaient les uns les autres au sein des mêmes fonctions métier. Il était nécessaire de comprendre où cela peut être divisé et à quelles limites, et que faire ensuite avec le mappage de cette séparation en assemblages de code source.
Nous avons formulé plusieurs règles pour le processus de séparation de code.
Premièrement : nous ne voulions plus partager la logique métier entre les services, les activités et les plugins. Ils souhaitaient rendre la logique métier indépendante dans le cadre des microservices. En revanche, les microservices, dans le cas idéal, sont perçus comme des services qui existent de manière totalement indépendante. Je pense que cette approche est un peu gaspilleuse, et elle est difficile à réaliser, car, par exemple, les services en C # seront en tout cas connectés par une bibliothèque standard. Notre système est écrit en C #, d'autres technologies n'ont pas encore été utilisées. Par conséquent, nous avons décidé que nous pouvions nous permettre d'utiliser des assemblages techniques communs. L'essentiel est qu'ils n'ont pas de fragments de logique métier. Si vous avez une enveloppe pratique sur l'ORM que vous utilisez, la copier d'un service à l'autre coûte très cher.
Notre équipe est fan de la conception orientée sujet, donc «l'architecture oignon» est parfaite pour nous. La base de nos services n'était pas une couche d'accès aux données, mais un assemblage avec une logique de domaine, qui ne contient que la logique métier et est dépourvu de connexions d'infrastructure. Dans le même temps, nous pouvons modifier indépendamment l'assembly de domaine pour résoudre les problèmes associés aux frameworks.
À ce stade, nous avons rencontré le premier problème grave. Le service était censé se référer à un assemblage de domaine, nous voulions rendre la logique indépendante, et ici le principe DRY interférait fortement avec nous. Pour éviter la duplication, les développeurs ont voulu réutiliser les classes des assemblages voisins et, par conséquent, les domaines ont recommencé à communiquer entre eux. Nous avons analysé les résultats et décidé que le problème réside peut-être également dans le domaine du périphérique de stockage de code source. Nous avions un grand référentiel dans lequel se trouvaient tous les codes sources. La solution pour l'ensemble du projet était très difficile à assembler sur une machine locale. Par conséquent, des petites solutions distinctes ont été créées pour les parties du projet, et personne n'a interdit d'y ajouter un assemblage Common ou de domaine et de les réutiliser. Le seul outil qui ne nous a pas permis de le faire était le code de révision. Mais parfois, il s'est également écrasé.
Ensuite, nous avons commencé à passer à un modèle avec des référentiels distincts. La logique métier a cessé de circuler de service en service, les domaines sont vraiment devenus indépendants. Des contextes limités sont pris en charge plus clairement. Comment réutiliser les bibliothèques d'infrastructure? Nous les avons alloués à un référentiel séparé, puis les avons placés dans les packages Nuget que nous avons mis dans Artifactory. Avec toute modification, l'assemblage et la publication se produisent automatiquement.
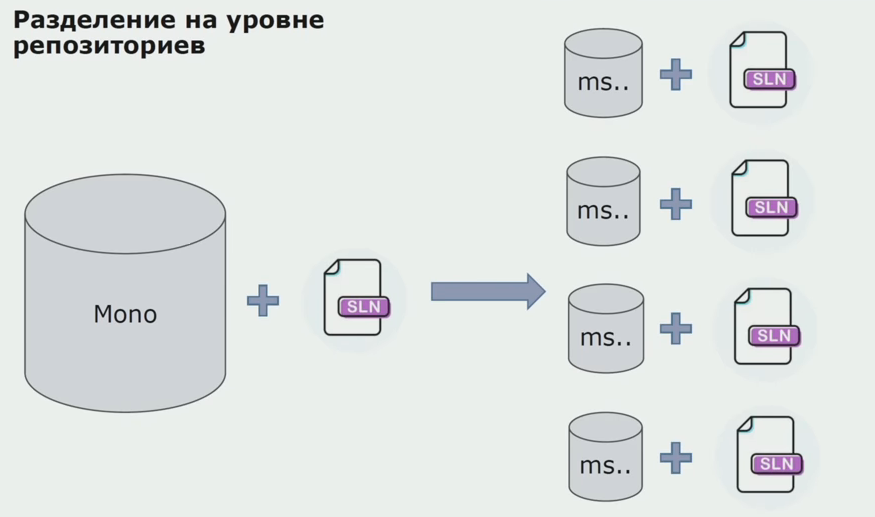
Nos services ont commencé à se référer aux packages d'infrastructure interne de la même manière qu'aux packages externes. Nous téléchargeons des bibliothèques externes de Nuget. Pour travailler avec Artifactory, où nous mettons ces packages, nous avons utilisé deux gestionnaires de packages. Dans les petits référentiels, nous avons également utilisé Nuget. Dans les référentiels avec plusieurs services, nous avons utilisé Paket, qui offre plus de cohérence de version entre les modules.
Ainsi, en travaillant sur le code source, en modifiant légèrement l'architecture et en partageant les référentiels, nous rendons nos services plus indépendants.
Problèmes d'infrastructure
La plupart des inconvénients du passage aux microservices sont liés à l'infrastructure. Vous aurez besoin d'un déploiement automatisé, vous aurez besoin de nouvelles bibliothèques pour l'infrastructure.
Installation manuelle dans les environnementsInitialement, nous avons installé la solution sur l'environnement manuellement. Pour automatiser ce processus, nous avons créé un pipeline CI / CD. Nous avons choisi le processus de livraison continue, car le déploiement continu pour nous n'est pas encore acceptable du point de vue des processus métier. Par conséquent, l'envoi à l'opération est effectué par le bouton, et pour le test - automatiquement.
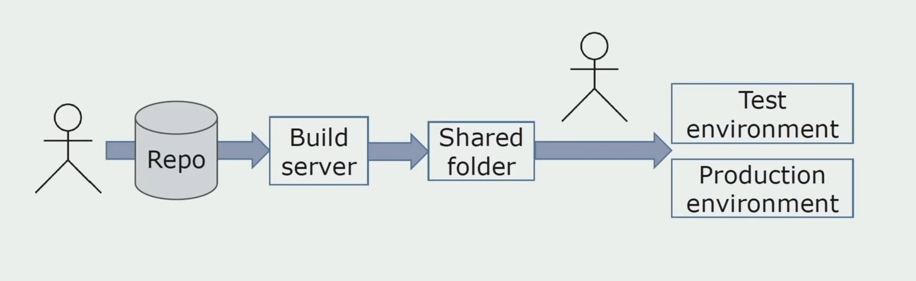
Nous utilisons Atlassian, Bitbucket pour stocker le code source et Bamboo pour l'assemblage. Nous aimons écrire des scripts d'assemblage dans Cake car c'est le même C #. Les packages prêts à l'emploi arrivent sur Artifactory et Ansible accède automatiquement aux serveurs de test, après quoi ils peuvent être testés immédiatement.
Journalisation séparée
À une époque, l'une des idées du monolithe était la mise en place d'un abattage conjoint. Nous devions également comprendre quoi faire avec les journaux individuels qui se trouvent sur les disques. Les journaux nous sont écrits dans des fichiers texte. Nous avons décidé d'utiliser la pile ELK standard. Nous n'avons pas écrit directement sur l'ELK via les fournisseurs, mais nous avons décidé de finaliser les journaux de texte et d'y inscrire l'ID de trace en tant qu'identifiant, en ajoutant le nom du service afin que ces journaux puissent ensuite être triés.

En utilisant Filebeat, nous avons la possibilité de collecter nos journaux à partir des serveurs, puis de les convertir, en utilisant Kibana pour créer des demandes dans l'interface utilisateur et regarder comment l'appel s'est passé entre les services. L'identifiant de trace aide beaucoup à cela.
Test et débogage des services associés
Au départ, nous ne comprenions pas entièrement comment déboguer les services développés. Tout était simple avec le monolithe, nous l'avons exécuté sur la machine locale. Au début, ils ont essayé de faire la même chose avec les microservices, mais parfois pour lancer complètement un microservice, vous devez en démarrer plusieurs autres, ce qui n'est pas pratique. , , , . , prod. , , . , , .
, production- . , .
Specflow. NUnit Ansible. , . - . , , Jira.
, . JMeter, — InfluxDB, — Grafana.
?
-, «». , production-, -. 1,5 , , .
. , , . .
. , .
, . , . Scrum-. , .
- . , , , . .
- . , , . , , , Scrum.
- — . . . legacy, , .
: . . , , , , , , , — , . . , , .
PS ( ) – .
.