Chaque système de surveillance est confronté à trois types de problèmes de performances.
Premièrement, un bon système de surveillance devrait très rapidement recevoir, traiter et enregistrer des données provenant de l'extérieur. Le compte passe en microsecondes. À première vue, cela peut sembler peu évident, mais lorsque le système devient suffisamment grand, toutes ces fractions de secondes sont résumées, se transformant en retards clairement visibles.

La deuxième tâche consiste à fournir un accès pratique à de grands tableaux de mesures précédemment collectées (en d'autres termes, aux données historiques). Les données historiques sont utilisées dans une grande variété de contextes. Par exemple, des rapports et des graphiques sont générés à partir d'eux, des contrôles agrégés sont construits sur eux, les déclencheurs en dépendent. S'il y a des retards dans l'accès à l'historique, cela affecte immédiatement la vitesse de l'ensemble du système dans son ensemble.
Troisièmement, les données historiques prennent beaucoup de place. Même des configurations de surveillance relativement modestes acquièrent très rapidement une solide histoire. Mais presque personne ne veut garder à portée de main l'historique de charge du processeur de cinq ans, donc le système de surveillance devrait être capable non seulement d'enregistrer correctement, mais aussi de bien supprimer l'historique (dans Zabbix, ce processus est appelé «entretien ménager»). La suppression des anciennes données ne doit pas être aussi efficace que la collecte et l'analyse de nouvelles, mais les opérations de suppression lourdes utilisent des ressources de SGBD précieuses et peuvent ralentir les opérations plus critiques.
Les deux premiers problèmes sont résolus par la mise en cache. Zabbix prend en charge plusieurs caches spécialisés pour accélérer les opérations de lecture et d'écriture des données. Les mécanismes SGBD eux-mêmes ne conviennent pas ici, car même l'algorithme de mise en cache à usage général le plus avancé ne saura pas quelles structures de données nécessitent un accès instantané à un moment donné.
Surveillance et données de séries chronologiques
Tout va bien tant que les données sont dans la mémoire du serveur Zabbix. Mais la mémoire n'est pas infinie et à un moment donné, les données doivent être écrites (ou lues) dans la base de données. Et si les performances de la base de données sont sérieusement en retard sur la vitesse de collecte des métriques, même les algorithmes de mise en cache spéciaux les plus avancés ne seront pas utiles pendant longtemps.
Le troisième problème se résume également aux performances de la base de données. Pour le résoudre, vous devez choisir une stratégie de suppression fiable qui n'interfère pas avec d'autres opérations de base de données. Par défaut, Zabbix supprime les données historiques par lots de plusieurs milliers d'enregistrements par heure. Vous pouvez configurer des périodes de maintenance plus longues ou des tailles de paquets plus importantes si la vitesse de collecte des données et la place dans la base de données le permettent. Mais avec un très grand nombre de métriques et / ou une fréquence élevée de leur collecte, une bonne configuration de l'entretien peut être une tâche intimidante, car un calendrier de suppression des données peut ne pas suivre le rythme de l'enregistrement de nouvelles.
En résumé, le système de surveillance résout les problèmes de performances dans trois directions: la collecte de nouvelles données et leur écriture dans la base de données à l'aide de requêtes SQL INSERT, l'accès aux données à l'aide de requêtes SELECT et la suppression de données à l'aide de DELETE. Voyons comment une requête SQL typique est exécutée:
- Le SGBD analyse la requête et vérifie les erreurs de syntaxe. Si la demande est syntaxiquement correcte, le moteur crée une arborescence de syntaxe pour un traitement ultérieur.
- Le planificateur de requêtes analyse l'arbre de syntaxe et calcule les différentes manières (chemins) pour exécuter la demande.
- L'ordonnanceur calcule le moyen le moins cher. Dans le processus, il prend en compte beaucoup de choses - quelle est la taille des tables, est-il nécessaire de trier les résultats, existe-t-il des index applicables à la requête, etc.
- Lorsque le chemin optimal est trouvé, le moteur exécute la requête en accédant aux blocs de données souhaités (à l'aide d'index ou de balayage séquentiel), applique les critères de tri et de filtrage, collecte le résultat et le renvoie au client.
- Pour insérer, modifier et supprimer des requêtes, le moteur doit également mettre à jour les index des tables correspondantes. Pour les grandes tables, cette opération peut prendre plus de temps que de travailler avec les données elles-mêmes.
- Très probablement, le SGBD mettra également à jour les statistiques internes d'utilisation des données pour les appels ultérieurs au planificateur de requêtes.
En général, il y a beaucoup de travail. La plupart des SGBD fournissent une tonne de paramètres pour l'optimisation des requêtes, mais ils se concentrent généralement sur certains workflows moyens dans lesquels l'insertion et la suppression d'enregistrements se produisent à peu près à la même fréquence que la modification.
Cependant, comme mentionné ci-dessus, pour les systèmes de surveillance, les opérations les plus courantes sont l'ajout et la suppression périodique en mode batch. La modification des données ajoutées précédemment ne se produit presque jamais, et l'accès aux données implique l'utilisation de fonctions agrégées. De plus, les valeurs des métriques ajoutées sont généralement classées par heure. Ces données sont communément appelées
séries chronologiques :
La série chronologique est une série de points de données indexés (ou répertoriés ou graffitis) dans un ordre temporaire.
Du point de vue de la base de données, les séries chronologiques ont les propriétés suivantes:
- Les séries temporelles peuvent être localisées sur un disque sous la forme d'une séquence de blocs ordonnés dans le temps.
- Les tables de séries chronologiques peuvent être indexées à l'aide d'une colonne de temps.
- La plupart des requêtes SQL SELECT utilisent des clauses WHERE, GROUP BY ou ORDER BY sur une colonne indiquant l'heure.
- En règle générale, les données de série chronologique ont une «date d'expiration» après laquelle elles peuvent être supprimées.
De toute évidence, les bases de données SQL traditionnelles ne conviennent pas pour stocker de telles données, car les optimisations générales ne prennent pas en compte ces qualités. Par conséquent, au cours des dernières années, un certain nombre de nouveaux SGBD orientés temps sont apparus, tels que, par exemple, InfluxDB. Mais tous les SGBD populaires pour les séries chronologiques ont un inconvénient important - le manque de prise en charge complète de SQL. De plus, la plupart d'entre eux ne sont même pas CRUD (Créer, Lire, Mettre à jour, Supprimer).
Zabbix peut-il utiliser ces SGBD de quelque manière que ce soit? L'une des approches possibles consiste à transférer les données historiques pour le stockage vers une base de données externe spécialisée dans la série chronologique. Étant donné que l'architecture Zabbix prend en charge des backends externes pour le stockage des données historiques (par exemple, la prise en charge Elasticsearch est implémentée dans Zabbix), à première vue, cette option semble très raisonnable. Mais si nous prenions en charge un ou plusieurs SGBD pour les séries chronologiques en tant que serveurs externes, les utilisateurs devraient alors prendre en compte les points suivants:
- Un autre système qui doit être exploré, configuré et entretenu. Un autre endroit pour garder une trace des paramètres, de l'espace disque, des politiques de stockage, des performances, etc.
- Réduire la tolérance aux pannes du système de surveillance, comme un nouveau lien apparaît dans la chaîne des composants associés.
Pour certains utilisateurs, les avantages d'un stockage dédié dédié aux données historiques peuvent l'emporter sur les inconvénients d'avoir à se soucier d'un autre système. Mais pour beaucoup, c'est une complication inutile. Il convient également de rappeler que puisque la plupart de ces solutions spécialisées ont leurs propres API, la complexité de la couche universelle pour travailler avec les bases de données Zabbix augmentera considérablement. Et nous, idéalement, préférons créer de nouvelles fonctions, plutôt que de lutter contre d'autres API.
La question se pose - existe-t-il un moyen de tirer parti du SGBD pour les séries chronologiques, mais sans perdre la flexibilité et les avantages de SQL? Naturellement, une réponse universelle n'existe pas, mais une solution spécifique s'est approchée de la réponse -
TimescaleDB .
Qu'est-ce que TimescaleDB?
TimescaleDB (TSDB) est une extension PostgreSQL qui optimise le travail avec les séries temporelles dans une base de données PostgreSQL (PG) régulière. Bien que, comme mentionné ci-dessus, les solutions de séries chronologiques bien évolutives ne manquent pas sur le marché, une caractéristique unique de TimescaleDB est sa capacité à bien fonctionner avec les séries chronologiques sans sacrifier la compatibilité et les avantages des bases de données relationnelles CRUD traditionnelles. En pratique, cela signifie que nous obtenons le meilleur des deux mondes. La base de données sait quelles tables doivent être considérées comme des séries temporelles (et applique toutes les optimisations nécessaires), mais vous pouvez travailler avec elles de la même manière qu'avec les tables normales. De plus, les applications ne sont pas tenues de savoir que les données sont contrôlées par TSDB!
Pour marquer une table comme une table de séries chronologiques (dans TSDB, cela s'appelle une hypertable), il suffit d'appeler la procédure TSDB create_ hypertable (). Sous le capot, TSDB divise ce tableau en soi-disant fragments (le terme anglais est un morceau) selon des conditions spécifiées. Les fragments peuvent être représentés comme des sections contrôlées automatiquement d'une table. Chaque fragment a une plage de temps correspondante. Pour chaque fragment, TSDB définit également des index spéciaux afin que l'utilisation d'une plage de données n'affecte pas l'accès aux autres.
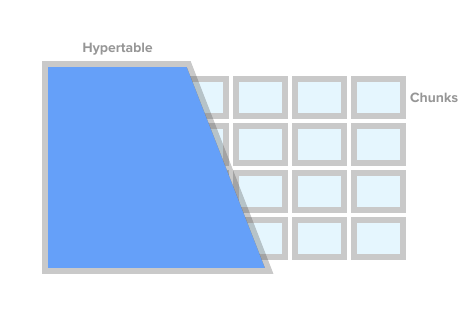 Image hypertable de timescaledb.com
Image hypertable de timescaledb.comLorsque l'application ajoute une nouvelle valeur pour la série chronologique, l'extension dirige cette valeur vers le fragment souhaité. Si la plage de temps de la nouvelle valeur n'est pas définie, TSDB créera un nouveau fragment, lui attribuera la plage souhaitée et y insérera la valeur. Si une application demande des données à une hypertable, puis avant d'exécuter la demande, l'extension vérifie quels fragments sont associés à cette demande.
Mais ce n'est pas tout. TSDB complète l'écosystème PostgreSQL robuste et éprouvé avec une multitude de changements de performances et d'évolutivité. Ceux-ci incluent l'ajout rapide de nouveaux enregistrements, des requêtes de temps rapides et des suppressions de lots pratiquement gratuites.
Comme indiqué précédemment, afin de contrôler la taille de la base de données et de respecter les politiques de rétention (c'est-à-dire de ne pas stocker les données plus longtemps que nécessaire), une bonne solution de surveillance doit supprimer efficacement une grande quantité de données historiques. Avec TSDB, nous pouvons supprimer l'histoire souhaitée simplement en supprimant certains fragments de l'hypertable. Dans ce cas, l'application n'a pas besoin de suivre les fragments par leur nom ou tout autre lien, TSDB supprimera tous les fragments nécessaires selon la condition de temps spécifiée.
Partitionnement TimescaleDB et PostgreSQL
À première vue, il peut sembler que TSDB est un bel emballage autour du partitionnement de table PG standard (
partitionnement déclaratif , comme il est officiellement appelé dans PG10). En effet, pour stocker des données historiques, vous pouvez utiliser le partitionnement standard PG10. Mais si on y regarde de près, les fragments du TSDB et de la section PG10 sont loin d'être des concepts identiques.
Pour commencer, la configuration du partitionnement dans PG nécessite une compréhension plus approfondie des détails, ce que l'application elle-même ou le SGBD devrait faire dans le bon sens. Tout d'abord, vous devez planifier votre hiérarchie de sections et décider d'utiliser ou non des partitions imbriquées. Deuxièmement, vous devez trouver un schéma de dénomination de section et le transférer d'une manière ou d'une autre dans les scripts pour créer le schéma. Très probablement, le schéma de dénomination comprendra la date et / ou l'heure, et ces noms devront être automatisés d'une manière ou d'une autre.
Ensuite, vous devez réfléchir à la façon de supprimer les données expirées. Dans TSDB, vous pouvez simplement appeler la commande drop_chunks (), qui détermine les fragments à supprimer pendant une période de temps donnée. Dans PG10, si vous devez supprimer une certaine plage de valeurs des sections PG standard, vous devrez calculer vous-même la liste des noms de section pour cette plage. Si le schéma de partitionnement sélectionné implique des sections imbriquées, cela complique davantage la suppression.
Un autre problème qui doit être résolu est de savoir quoi faire avec les données qui vont au-delà des plages de temps actuelles. Par exemple, les données peuvent provenir d'un futur pour lequel des sections n'ont pas encore été créées. Ou du passé pour les sections déjà supprimées. Par défaut dans PG10, l'ajout d'un tel enregistrement ne fonctionnera pas et nous perdrons simplement les données. Dans PG11, vous pouvez définir une section par défaut pour ces données, mais cela ne masque que temporairement le problème et ne le résout pas.
Bien sûr, tous les problèmes ci-dessus peuvent être résolus d'une manière ou d'une autre. Vous pouvez accrocher la base avec des déclencheurs, des cron-jabs et saupoudrer généreusement de scripts. Ce sera moche, mais fonctionnel. Il ne fait aucun doute que les sections PG sont meilleures que les tables monolithiques géantes, mais ce qui n'est certainement pas résolu par les scripts et les déclencheurs, ce sont les améliorations des séries chronologiques que PG n'a pas.
C'est-à-dire Par rapport aux sections PG, les hypertables TSDB se distinguent favorablement non seulement en sauvant les nerfs des administrateurs de base de données, mais aussi en optimisant à la fois l'accès aux données et en ajoutant de nouveaux. Par exemple, les fragments dans TSDB sont toujours un tableau unidimensionnel. Cela simplifie la gestion des fragments et accélère les insertions et les sélections. Pour ajouter de nouvelles données, TSDB utilise son propre algorithme de routage dans le fragment souhaité qui, contrairement au PG standard, n'ouvre pas immédiatement toutes les sections. Avec un grand nombre de sections, la différence de performances peut varier considérablement. Des détails techniques sur la différence entre le partitionnement standard dans PG et TSDB peuvent être trouvés dans
cet article .
Zabbix et TimescaleDB
De toutes les options, TimescaleDB semble être le choix le plus sûr pour Zabbix et ses utilisateurs:
- TSDB est conçu comme une extension PostgreSQL, et non comme un système autonome. Par conséquent, il ne nécessite pas de matériel supplémentaire, de machines virtuelles ou d'autres modifications de l'infrastructure. Les utilisateurs peuvent continuer à utiliser leurs outils choisis pour PostgreSQL.
- TSDB vous permet de sauvegarder presque tout le code pour travailler avec la base de données dans Zabbix inchangé.
- TSDB améliore considérablement les performances du synchroniseur d'historique et de la femme de ménage.
- Seuil d'entrée bas - Les concepts de base du TSDB sont simples et directs.
- L'installation et la configuration faciles de l'extension elle-même et de Zabbix aideront grandement les utilisateurs de systèmes de petite et moyenne taille.
Voyons ce qui doit être fait pour démarrer TSDB avec un Zabbix fraîchement installé. Après avoir installé Zabbix et exécuté les scripts de création de base de données PostgreSQL, vous devez télécharger et installer TSDB sur la plate-forme souhaitée. Voir les instructions d'installation
ici . Après avoir installé l'extension, vous devez l'activer pour la base Zabbix, puis exécuter le script timecaledb.sql fourni avec Zabbix. Il se trouve soit dans la base de données / postgresql / timecaledb.sql si l'installation provient de la source, soit dans /usr/share/zabbix/database/timecaledb.sql.gz si l'installation provient de packages. C’est tout! Vous pouvez maintenant démarrer le serveur Zabbix et cela fonctionnera avec TSDB.
Le script timescaledb.sql est trivial. Tout ce qu'il fait est de convertir les tableaux historiques Zabbix habituels en hypertables TSDB et de modifier les paramètres par défaut - définit les paramètres Remplacer la période de l'historique des éléments et Remplacer la période de tendance des éléments. Désormais (version 4.2), les tableaux Zabbix suivants fonctionnent sous le contrôle TSDB - history, history_uint, history_str, history_log, history_text, trends et trends_uint. Le même script peut être utilisé pour migrer ces tables (notez que le paramètre migrate_data est défini sur true). Il ne faut pas oublier que la migration des données est un processus très long et peut prendre plusieurs heures.
Le paramètre chunk_time_interval => 86400 peut également nécessiter des modifications avant d'exécuter timecaledb.sql. Chunk_time_interval est l'intervalle qui limite le temps des valeurs tombant dans ce fragment. Par exemple, si vous définissez l'intervalle chunk_time_interval sur 3 heures, les données pour la journée entière seront réparties sur 8 fragments, le premier fragment n ° 1 couvrant les 3 premières heures (0: 00-2: 59), le deuxième fragment n ° 2 - les 2 dernières heures ( 3: 00-5: 59), etc. Le dernier fragment n ° 8 contiendra des valeurs avec un temps de 21: 00-23: 59. 86 400 secondes (1 jour) est la valeur par défaut moyenne, mais les utilisateurs des systèmes chargés peuvent vouloir la réduire.
Afin d'estimer approximativement les besoins en mémoire, il est important de comprendre combien d'espace une pièce peut occuper en moyenne. Le principe général est que le système doit avoir suffisamment de mémoire pour organiser au moins un fragment de chaque hypertable. Dans ce cas, bien sûr, la somme des tailles de fragments doit non seulement tenir dans la mémoire avec une marge, mais également être inférieure à la valeur du paramètre shared_buffers de postgresql.conf. De plus amples informations sur ce sujet peuvent être trouvées dans la documentation TimescaleDB.
Par exemple, si vous avez un système qui collecte principalement des mesures entières et que vous décidez de diviser la table history_uint en fragments de 2 heures et de diviser le reste des tables en fragments d'une journée, vous devez modifier cette ligne dans timecaledb.sql:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
Après qu'une certaine quantité de données historiques s'est accumulée, vous pouvez vérifier la taille des fragments pour la table history_uint en appelant chunk_relation_size ():
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint'); chunk_table | total_bytes -----------------------------------------+------------- _timescaledb_internal._hyper_2_6_chunk | 13287424 _timescaledb_internal._hyper_2_7_chunk | 13172736 _timescaledb_internal._hyper_2_8_chunk | 13344768 _timescaledb_internal._hyper_2_9_chunk | 13434880 _timescaledb_internal._hyper_2_10_chunk | 13230080 _timescaledb_internal._hyper_2_11_chunk | 13189120
Cet appel peut être répété pour trouver les tailles de fragments pour toutes les hypertables. Si, par exemple, il a été constaté que la taille du fragment de history_uint est de 13 Mo, les fragments pour d'autres tables d'historique, disons 20 Mo et pour les tables de tendance 10 Mo, alors la mémoire totale requise est de 13 + 4 x 20 + 2 x 10 = 113 Mo. Nous devons également laisser de l'espace aux shared_buffers pour stocker d'autres données, disons 20%. Ensuite, la valeur de shared_buffers doit être définie sur 113 Mo / 0,8 = ~ 140 Mo.
Pour un réglage plus fin de TSDB, l'utilitaire timecaledb-tune est récemment apparu. Il analyse postgresql.conf, le corrèle avec la configuration du système (mémoire et processeur), puis donne des recommandations sur la définition des paramètres de mémoire, des paramètres de traitement parallèle, WAL. L'utilitaire modifie le fichier postgresql.conf, mais vous pouvez l'exécuter avec le paramètre -dry-run et vérifier les modifications proposées.
Nous allons nous attarder sur les paramètres Zabbix Remplacer la période de l'historique des éléments et Remplacer la période de tendance des éléments (disponibles dans Administration -> Général -> Entretien ménager). Ils sont nécessaires pour supprimer les données historiques sous forme de fragments entiers d'hypertables TSDB, pas d'enregistrements.
Le fait est que Zabbix vous permet de définir la période de maintenance pour chaque élément de données (métrique) individuellement. Cependant, cette flexibilité est obtenue en parcourant la liste des éléments et en calculant les périodes individuelles à chaque itération de l'entretien ménager. Si le système a des périodes de maintenance individuelles pour des éléments individuels, alors le système ne peut évidemment pas avoir un seul point de coupure pour toutes les métriques ensemble et Zabbix ne sera pas en mesure de donner la commande correcte pour supprimer les fragments nécessaires. Ainsi, en désactivant l'option Remplacer l'historique pour les métriques, Zabbix perdra la possibilité de supprimer rapidement l'historique en appelant la procédure drop_chunks () pour les tables history_ * et, en conséquence, la désactivation des tendances Override perdra la même fonction pour les tables trends_ *.
En d'autres termes, pour profiter pleinement du nouveau système d'entretien ménager, vous devez globaliser les deux options. Dans ce cas, le processus de gestion interne ne lira pas du tout les paramètres des éléments de données.
Performance avec TimescaleDB
Il est temps de vérifier si tout ce qui précède fonctionne vraiment dans la pratique. Notre banc de test est Zabbix 4.2rc1 avec PostgreSQL 10.7 et TimescaleDB 1.2.1 pour Debian 9. La machine de test est un Intel Xeon à 10 cœurs avec 16 Go de RAM et 60 Go d'espace de stockage sur le SSD. Selon les normes actuelles, il s'agit d'une configuration très modeste, mais notre objectif est de découvrir l'efficacité du TSDB dans la vie réelle. Dans les configurations avec un budget illimité, vous pouvez simplement insérer 128-256 Go de RAM et mettre la plupart (sinon la totalité) de la base de données en mémoire.
Notre configuration de test se compose de 32 agents Zabbix actifs qui transfèrent les données directement vers le serveur Zabbix. Chaque agent sert 10 000 articles. Le cache historique Zabbix est défini sur 256 Mo et la PG shared_buffers est définie sur 2 Go. Cette configuration fournit une charge suffisante sur la base de données, mais en même temps ne crée pas une charge importante sur les processus du serveur Zabbix. Pour réduire le nombre de pièces mobiles entre les sources de données et la base de données, nous n'avons pas utilisé le proxy Zabbix.
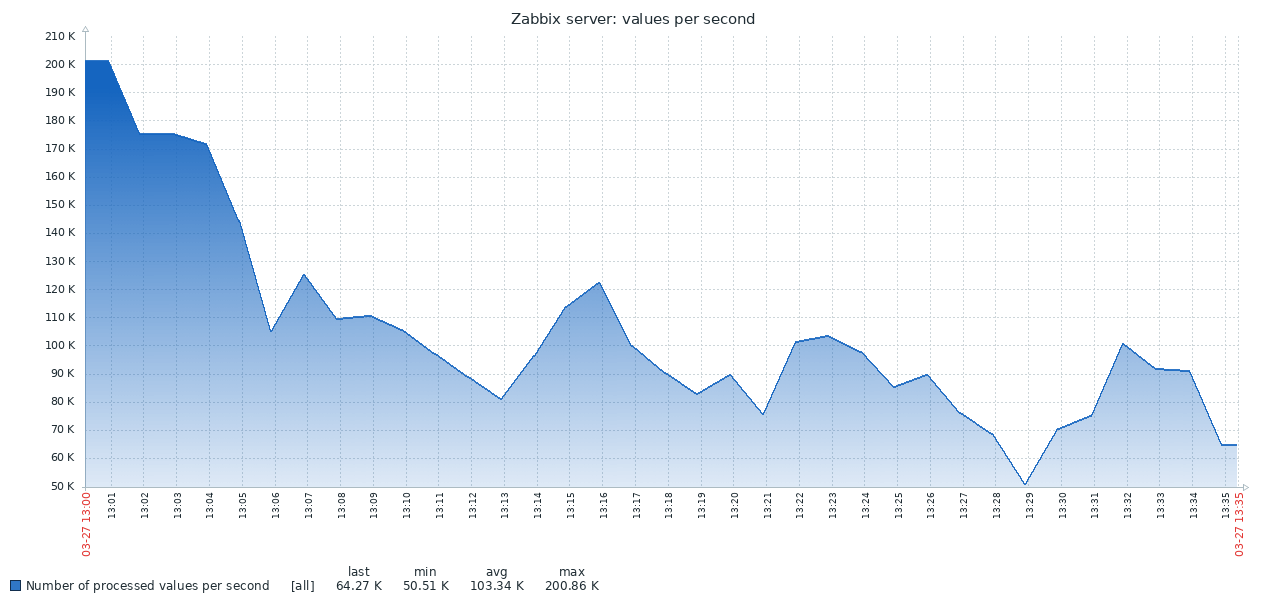
Voici le premier résultat obtenu à partir du système PG standard:
Le résultat de TSDB est complètement différent:

Le graphique ci-dessous combine les deux résultats. Le travail commence avec des valeurs NVPS assez élevées en 170-200K, car Il faut un certain temps pour remplir le cache d'historique avant que la synchronisation avec la base de données ne commence.
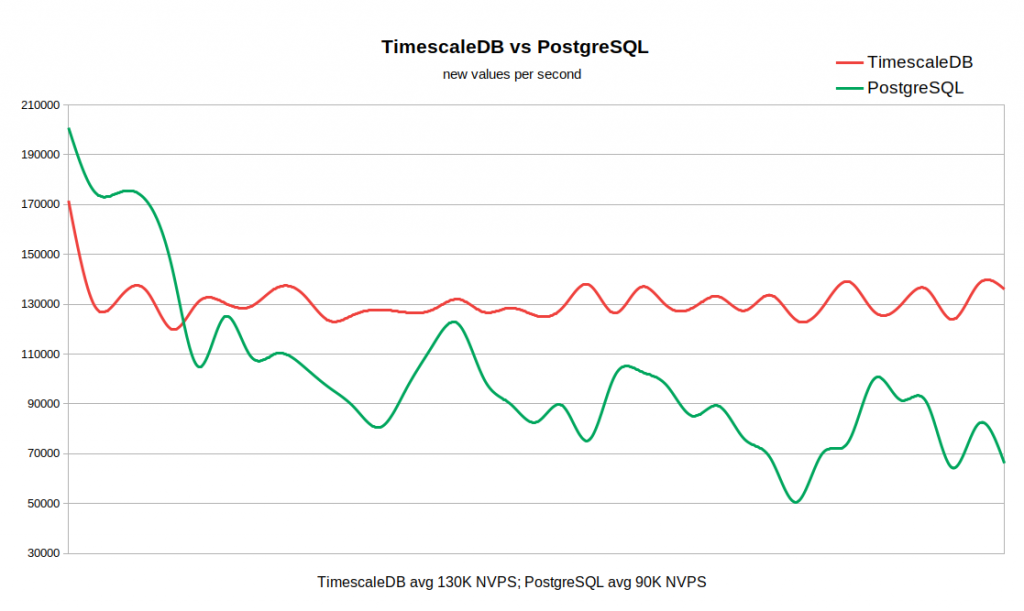
Lorsque la table d'historique est vide, la vitesse d'écriture dans TSDB est comparable à la vitesse d'écriture dans PG, et même avec une petite marge de ce dernier. Dès que le nombre d'enregistrements dans l'histoire atteint 50-60 millions, le débit de PG tombe à 110K NVPS, mais, ce qui est plus désagréable, il continue de changer inversement avec le nombre d'enregistrements accumulés dans le tableau historique. Dans le même temps, TSDB maintient une vitesse stable de 130K NVPS tout au long du test de 0 à 300 millions d'enregistrements.
Au total, dans notre exemple, la différence de performance moyenne est assez importante (130K contre 90K sans tenir compte du pic initial). On voit également que le taux d'insertion dans la PG standard varie sur une large plage. Ainsi, si un flux de travail nécessite de stocker des dizaines ou des centaines de millions d'enregistrements dans l'historique, mais qu'il n'y a pas de ressources pour des stratégies de mise en cache très agressives, alors TSDB est un candidat solide pour remplacer le PG standard.
L'avantage du TSDB est déjà évident pour ce système relativement modeste, mais la différence deviendra probablement encore plus perceptible sur de grands tableaux de données historiques. D'un autre côté, ce test n'est en aucun cas une généralisation de tous les scénarios possibles de travail avec Zabbix. Naturellement, de nombreux facteurs influencent les résultats, tels que les configurations matérielles, les paramètres du système d'exploitation, les paramètres du serveur Zabbix et la charge supplémentaire provenant d'autres services exécutés en arrière-plan. Autrement dit, votre kilométrage peut varier.
Conclusion
TimescaleDB est une technologie très prometteuse. Il a déjà été exploité avec succès dans des environnements de production graves. TSDB fonctionne bien avec Zabbix et offre des avantages significatifs par rapport à la base de données PostgreSQL standard.
Le TSDB a-t-il des défauts ou des raisons de reporter son utilisation? D'un point de vue technique, nous ne voyons aucun argument contre. Mais il faut garder à l'esprit que la technologie est encore nouvelle, avec un cycle de sortie instable et une stratégie peu claire pour le développement des fonctionnalités. En particulier, de nouvelles versions avec des changements importants sont publiées tous les mois ou deux. Certaines fonctions peuvent être supprimées, comme c'est le cas, par exemple, avec la segmentation adaptative. Par ailleurs, comme autre facteur d'incertitude, il convient de mentionner la politique d'octroi de licences. C'est très déroutant car il existe trois niveaux de licence. Le noyau TSDB est fabriqué sous la licence Apache, certaines fonctions sont publiées sous leur propre licence Timescale, mais il existe également une version fermée d'Enterprise.
Si vous utilisez Zabbix avec PostgreSQL, alors il n'y a aucune raison au moins de ne pas essayer TimescaleDB. Peut-être que cette chose vous surprendra agréablement :) Gardez à l'esprit que la prise en charge de TimescaleDB dans Zabbix est encore expérimentale - pendant un certain temps, pendant que nous recueillons des avis d'utilisateurs et acquérons de l'expérience.