En utilisant nginx pour équilibrer le trafic HTTP au niveau L7, il est possible d'envoyer une demande client au serveur d'applications suivant si la cible ne renvoie pas de réponse positive. Un test du mécanisme de vérification passive de l'état de santé du serveur d'application a montré l'ambiguïté de la documentation et la spécificité des algorithmes d'exclusion du serveur du pool de serveurs de production.
Résumé de l'équilibrage du trafic HTTP
Il existe différentes manières d'équilibrer le trafic HTTP. Aux niveaux du modèle OSI,
il existe des technologies d'équilibrage au niveau du réseau, du transport et des applications.
Des combinaisons peuvent être utilisées en fonction de la taille de l'application.
La technologie d'équilibrage du trafic donne des effets positifs dans l'application et sa maintenance. En voici quelques uns. Mise à l'échelle horizontale de l'application, dans laquelle la
charge est répartie sur plusieurs nœuds . Planification de la mise hors service du serveur d'applications en supprimant le flux des demandes des clients. Mise en œuvre de la stratégie de test A / B pour la fonctionnalité modifiée de l'application. Amélioration de la tolérance aux pannes des applications en
envoyant des demandes à des serveurs d'applications qui fonctionnent bien .
La dernière fonction est implémentée en deux modes. En mode passif, l'équilibreur du trafic client évalue les réponses du serveur d'applications cible et l'exclut du pool de serveurs de production sous certaines conditions. En mode actif, l'équilibreur envoie périodiquement de manière indépendante des requêtes au serveur d'applications à un URI donné et, pour certains signes de réponse, décide de l'exclure du pool de serveurs de production. Par la suite, l'équilibreur, sous certaines conditions, renvoie le serveur d'applications au pool de serveurs de production.
Vérification passive du serveur d'applications et son exclusion du pool de serveurs de production
Examinons de plus près la vérification passive du serveur d'applications dans l'édition freeware de nginx / 1.17.0. Les serveurs d'applications sont sélectionnés tour à tour par l'algorithme Round Robin, leurs poids sont les mêmes.
Le diagramme en trois étapes montre une section de temps commençant par l'envoi d'une demande client au serveur d'applications n ° 2. Un indicateur lumineux caractérise les demandes / réponses entre le client et l'équilibreur. Indicateur sombre - demandes / réponses entre nginx et les serveurs d'applications.
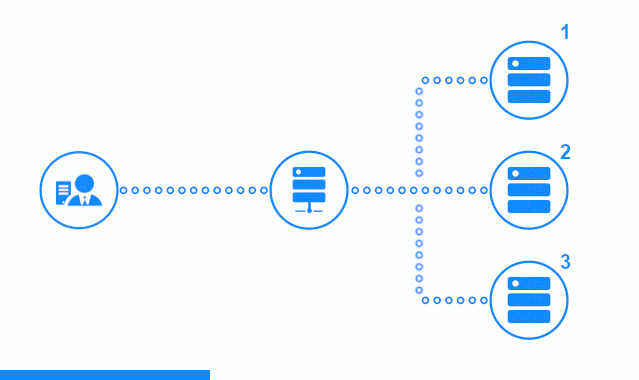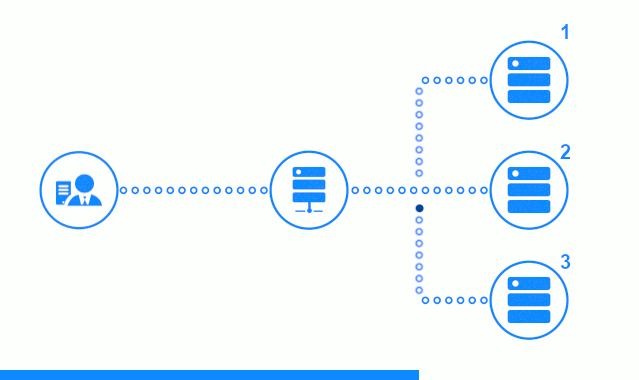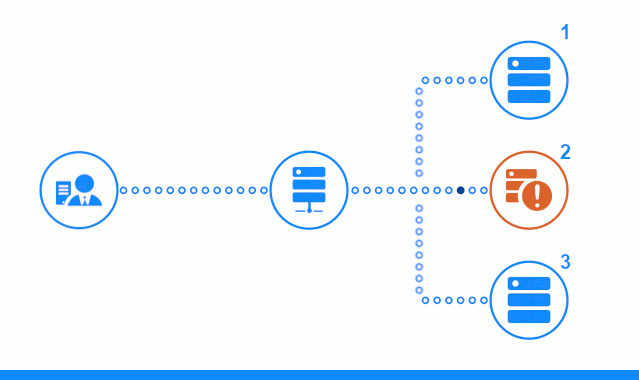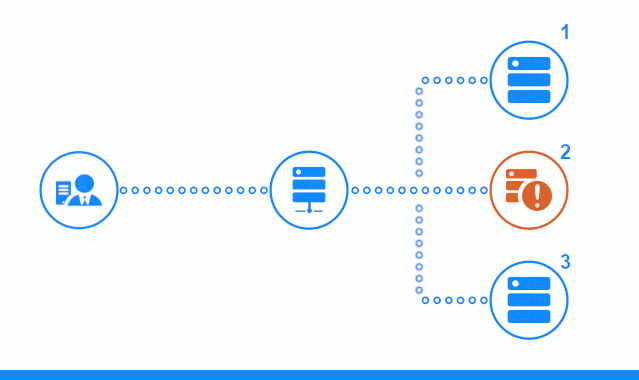
La troisième étape du diagramme montre comment l’équilibreur redirige la demande du client vers le serveur d’applications suivant, au cas où le serveur cible aurait donné une réponse d’erreur ou n’aurait pas répondu du tout.
La liste des erreurs HTTP et TCP dans lesquelles le serveur utilise le serveur suivant est spécifiée dans la directive
proxy_next_upstream .
Par défaut, nginx redirige uniquement les
demandes avec des méthodes HTTP idempotentes vers le serveur d'applications suivant.
Qu'obtient le client? D'une part, la possibilité de rediriger une demande vers le serveur d'applications suivant augmente les chances de fournir une réponse satisfaisante au client lorsque le serveur cible tombe en panne. D'un autre côté, il est évident qu'un appel séquentiel d'abord vers le serveur cible, puis vers le suivant augmente le temps de réponse total au client.
Au final,
la réponse du serveur d'applications est renvoyée au client
, où se termine le compteur de tentatives autorisées proxy_next_upstream_tries .
Lorsque vous utilisez la fonction de redirection vers le serveur de travail suivant, vous devez en outre harmoniser les délais d'expiration sur les serveurs d'équilibrage et d'application. La limite supérieure du temps pour une demande de «déplacement» entre les serveurs d'applications et l'équilibreur est le délai d'expiration du client ou le temps d'attente spécifié par l'entreprise. Lors du calcul des délais d'attente, il est également nécessaire de prendre en compte la marge pour les événements du réseau (retards / pertes lors de la livraison des paquets). Si le client termine à chaque fois la session par timeout pendant que l'équilibreur obtient une réponse garantie, la bonne intention de fiabiliser l'application sera vaine.

Le contrôle d'intégrité passif des serveurs d'applications est contrôlé par des directives, par exemple, avec les options suivantes pour leurs valeurs:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
À compter du 2 juillet
2019 , la documentation a
établi que le paramètre
max_fails définit le nombre de tentatives infructueuses de travail avec le serveur qui devraient se produire dans le délai spécifié par le paramètre
fail_timeout .
Le paramètre
fail_timeout définit la durée pendant laquelle le nombre spécifié de tentatives infructueuses de travailler avec le serveur doit se produire pour que le serveur soit considéré comme indisponible; et le temps pendant lequel le serveur sera considéré comme indisponible.
Dans l'exemple donné, faisant partie du fichier de configuration, l'équilibreur est configuré pour intercepter 5 appels ayant échoué en 100 secondes.
Retour du serveur d'applications au pool de serveurs de production
Comme indiqué dans la documentation, l'équilibreur après
fail_timeout ne peut pas considérer le serveur comme étant inopérant. Mais, malheureusement, la documentation n'établit pas explicitement comment les performances du serveur sont évaluées.
Sans expérience, on ne peut que supposer que le mécanisme de vérification de l'état est similaire à celui décrit précédemment.
Attentes et réalité
Dans la configuration présentée, le comportement suivant est attendu de l'équilibreur:
- Jusqu'à ce que l'équilibreur exclue le serveur d'applications n ° 2 du pool de serveurs de production, les demandes des clients lui seront envoyées.
- Les demandes renvoyées avec une erreur 500 du serveur d'applications n ° 2 seront transmises au serveur d'applications suivant et le client recevra des réponses positives.
- Dès que l'équilibreur reçoit 5 réponses avec le code 500 dans les 100 secondes, il exclut le serveur d'applications n ° 2 du pool de serveurs de production. Toutes les demandes suivant une fenêtre de 100 secondes seront immédiatement envoyées aux serveurs d'applications restants sans délai supplémentaire.
- Après 100 secondes, l'équilibreur doit en quelque sorte évaluer les performances du serveur d'applications et le renvoyer au pool de serveurs de production.
Après avoir effectué des tests en nature, selon les magazines de l'équilibreur, il a été établi que la déclaration n ° 3 ne fonctionne pas. L'équilibreur exclut un serveur inactif dès que la condition du paramètre
max_fails est
remplie . Ainsi, un serveur défaillant est exclu du service sans attendre le délai de 100 secondes. Le paramètre
fail_timeout joue uniquement le rôle de la limite supérieure du temps d'accumulation d'erreur.
Dans le cadre de l'assertion n ° 4, il s'avère que nginx vérifie la fonctionnalité d'une application qui était auparavant exclue de la maintenance du serveur avec une seule demande. Et si le serveur répond toujours avec une erreur, la vérification suivante
échouera après
fail_timeout .
Qu'est-ce qui manque?
- L'algorithme implémenté dans nginx / 1.17.0 n'est peut-être pas le moyen le plus juste de vérifier les performances du serveur avant de le retourner dans le pool de serveurs de travail. Au moins, selon la documentation actuelle, pas 1 demande n'est attendue, mais le montant spécifié dans max_fails .
- L'algorithme de vérification d'état ne prend pas en compte la vitesse des requêtes. Plus il est grand, plus le spectre est fort avec des tentatives infructueuses se déplaçant vers la gauche, et le serveur d'applications abandonne trop rapidement le pool de serveurs de travail. Je suppose que cela peut nuire aux applications qui se permettent de produire des erreurs «de caillots courts». Par exemple, lors de la collecte des ordures.

Je voulais vous demander s'il y avait un avantage pratique à l'algorithme de vérification de l'intégrité du serveur, qui mesure la vitesse des tentatives infructueuses?