Dans la
version précédente, j'ai décrit le cadre d'automatisation du réseau. Selon les critiques de certaines personnes, même cette première approche du problème a déjà posé quelques questions sur les étagères. Et cela me fait très plaisir, car notre objectif dans le cycle n'est pas de couvrir l'ansible avec des scripts Python, mais de construire un système.
Le même cadre fixe l'ordre dans lequel nous traiterons la question.
Et la virtualisation du réseau, à laquelle ce numéro est dédié, ne rentre pas vraiment dans le thème ADSM, où nous analysons l'automatisation.
Mais regardons-le sous un angle différent.
Depuis longtemps déjà, de nombreux services utilisent un même réseau. Dans le cas d'un opérateur, ce sont par exemple 2G, 3G, LTE, large bande et B2B. Dans le cas de DC: connectivité pour différents clients, Internet, stockage en bloc, stockage d'objets.
Et tous les services doivent être isolés les uns des autres. Il est donc apparu des réseaux de superposition.
Et tous les services ne veulent pas attendre qu'une personne les configure manuellement. Il y a donc eu des orchestrateurs et SDN.
La première approche de l'automatisation systématique du réseau, ou plutôt de certaines parties de celui-ci, a longtemps été adoptée et a été mise en œuvre dans de nombreux endroits: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Ici, nous traitons avec lui aujourd'hui.

Table des matières
- Raisons
- Terminologie
- Sous-couche - Réseau physique
- Superposition - réseau virtuel
- Superposition avec ToR
- Superposition de l'hôte
- Étude de cas: tissu de tungstène
- Communication au sein d'une machine physique
- Communication entre machines virtuelles situées sur différentes machines physiques
- Sortie sur le monde extérieur
- FAQ
- Conclusion
- Liens utiles
Raisons
Et puisque nous en avons parlé, il convient de mentionner les conditions préalables à la virtualisation du réseau. En fait, ce processus n'a pas commencé hier.
Vous avez probablement entendu plus d'une fois que le réseau a toujours été la partie la plus inerte de tout système. Et cela est vrai dans tous les sens. Un réseau est la base sur laquelle tout est basé, et y apporter des modifications est assez difficile - les services ne tolèrent pas lorsque le réseau se trouve. Souvent, la mise hors service d'un seul nœud peut ajouter la plupart des applications et affecter de nombreux clients. C'est en partie pourquoi l'équipe du réseau peut résister à tout changement - parce que maintenant cela fonctionne (
nous ne savons même pas comment ), mais ici nous devons configurer quelque chose de nouveau, et on ne sait pas comment cela affectera le réseau.
Afin de ne pas attendre que les fournisseurs de réseau passent les VLAN et de ne pas enregistrer de services sur chaque nœud de réseau, les gens ont décidé d'utiliser des superpositions - réseaux superposés - dont il existe une grande variété: GRE, IPinIP, MPLS, MPLS L2 / L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE, etc.
Leur attrait réside dans deux choses simples:
- Seuls les nœuds d'extrémité sont configurés - vous n'avez pas besoin de toucher les nœuds de transit. Cela accélère considérablement le processus et vous permet même parfois d'exclure le service d'infrastructure réseau du processus d'introduction de nouveaux services.
- La charge est cachée profondément à l'intérieur des en-têtes - les nœuds de transit n'ont besoin de rien savoir à ce sujet, sur l'adressage sur les hôtes, les routes du réseau imposé. Et cela signifie que vous devez stocker moins d'informations dans les tableaux, alors prenez un appareil plus simple / moins cher.
Dans ce problème pas tout à fait à part entière, je ne prévois pas d'analyser toutes les technologies possibles, mais plutôt de décrire le cadre de fonctionnement des réseaux de superposition dans les DC.
La série entière décrira un centre de données, composé de rangées de racks similaires dans lesquels le même équipement serveur est installé.
Cet équipement exécute des machines virtuelles / conteneurs / sans serveur qui mettent en œuvre des services.

Terminologie
Dans la boucle, j'appellerai le
serveur un programme qui implémente le côté serveur de la communication client-serveur.
Les machines physiques dans les racks
ne seront
pas appelées serveurs.
La machine physique est un ordinateur monté en rack x86. Le plus souvent, nous utilisons le terme
hôte . Nous l'appellerons donc "
machine " ou
hôte .
Un hyperviseur est une application exécutée sur une machine physique qui émule les ressources physiques sur lesquelles les machines virtuelles s'exécutent. Parfois, dans la littérature et le réseau, le mot "hyperviseur" est utilisé comme synonyme de "hôte".
Une machine virtuelle est un système d'exploitation exécuté sur une machine physique au-dessus d'un hyperviseur. Pour nous, dans le cadre de ce cycle, peu importe qu'il s'agisse en fait d'une machine virtuelle ou simplement d'un conteneur. Nous l'appellerons "
VM "
Le locataire est un concept large que je définirai dans cet article comme un service distinct ou un client distinct.
Multi-tenancy ou multi-tenancy - l'utilisation de la même application par différents clients / services. Dans le même temps, l'isolation des clients les uns des autres est réalisée en raison de l'architecture de l'application et non des instances exécutées séparément.
ToR - Top of the Rack switch - un commutateur monté en rack auquel toutes les machines physiques sont connectées.
En plus de la topologie ToR, différents fournisseurs pratiquent End of Row (EoR) ou Middle of Row (bien que ce dernier soit une rareté dédaigneuse et que je n'ai pas vu les abréviations MoR).
Réseau sous-jacent ou
réseau sous-jacent ou sous-couche - infrastructure de réseau physique: commutateurs, routeurs, câbles.
Réseau de superposition ou
réseau de superposition ou superposition - un réseau virtuel de tunnels qui s'exécute au-dessus d'un réseau physique.
L3-factory ou IP-factory est une formidable invention de l'humanité, qui permet aux interviews de ne pas répéter STP et de ne pas apprendre TRILL. Un concept dans lequel l'intégralité du réseau jusqu'au niveau d'accès est exclusivement L3, sans VLAN et en conséquence de vastes domaines de diffusion étendus. D'où vient le mot «usine» dans la partie suivante.
SDN - Réseau défini par logiciel. A à peine besoin d'une introduction. Une approche de la gestion du réseau lorsque les modifications apportées au réseau ne sont pas effectuées par une personne, mais par un programme. Cela signifie généralement déplacer le plan de contrôle au-delà des périphériques réseau finaux vers le contrôleur.
NFV - Network Function Virtualization - virtualisation des périphériques réseau, qui suppose qu'une partie des fonctions réseau peut être lancée sous la forme de machines virtuelles ou de conteneurs pour accélérer la mise en œuvre de nouveaux services, organiser le chaînage des services et une évolutivité horizontale plus facile.
VNF - Fonction de réseau virtuel. Périphérique virtuel spécifique: routeur, commutateur, pare-feu, NAT, IPS / IDS, etc.
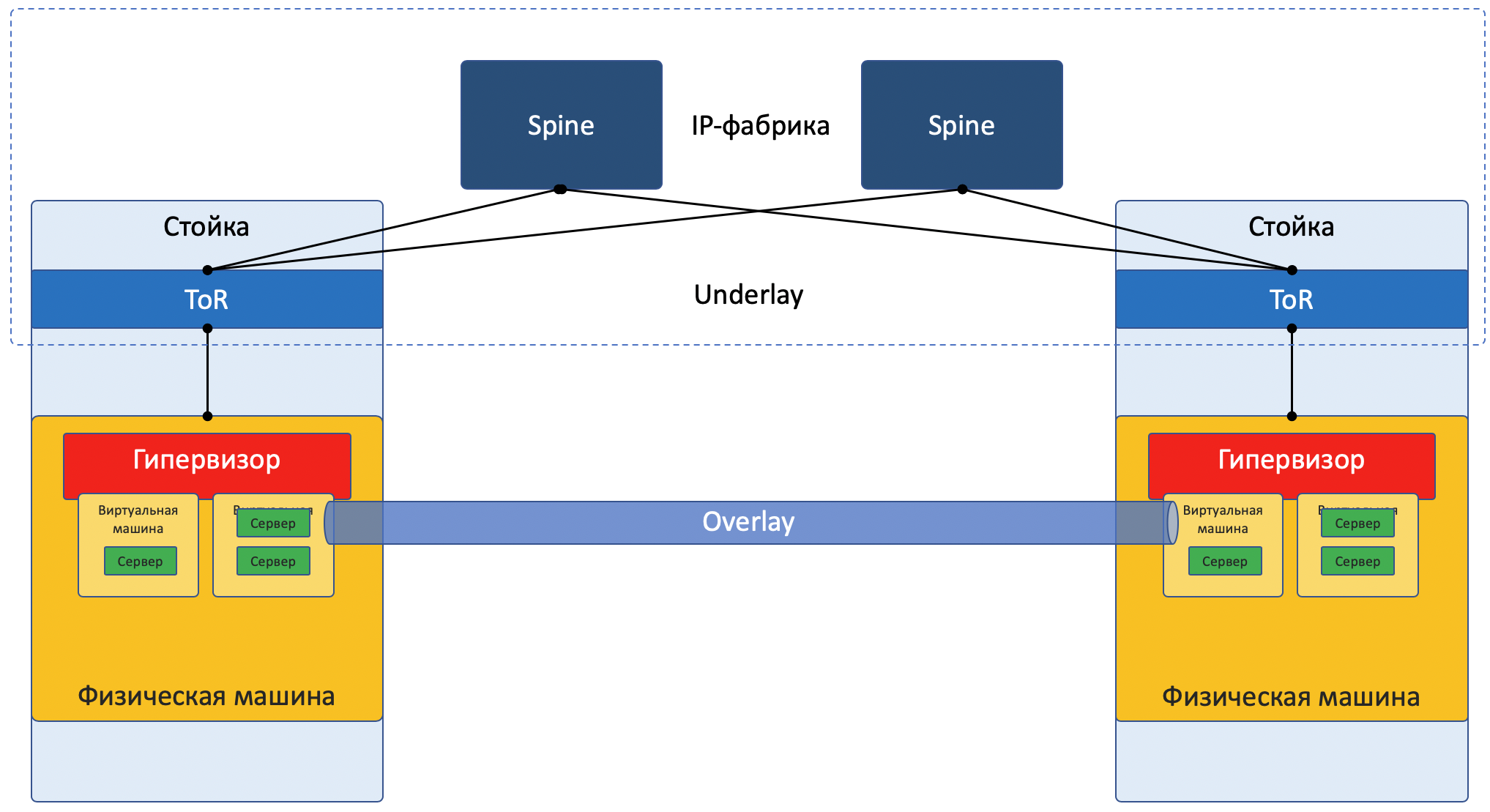
Je simplifie maintenant délibérément la description d'une implémentation spécifique afin de ne pas trop dérouter le lecteur. Pour une lecture plus réfléchie, envoyez-la à la section Liens . De plus, Roma Gorge, qui critique cet article pour des inexactitudes, promet d'écrire un numéro séparé sur les technologies de virtualisation des serveurs et des réseaux, plus approfondi et plus attentif aux détails.
Aujourd'hui, la plupart des réseaux peuvent être clairement divisés en deux parties:
Underlay - un réseau physique avec une configuration stable.
Overlay - Abstraction over Underlay pour isoler les locataires.
Cela est vrai à la fois pour le cas de DC (que nous analyserons dans cet article) et pour ISP (que nous n'analyserons pas, car il était déjà dans
SDSM ). Avec les réseaux d'entreprise, bien sûr, la situation est quelque peu différente.
Image de focus réseau:

Sous-couche
La sous-couche est un réseau physique: commutateurs et câbles matériels. Les appareils sous-jacents savent comment accéder aux machines physiques.
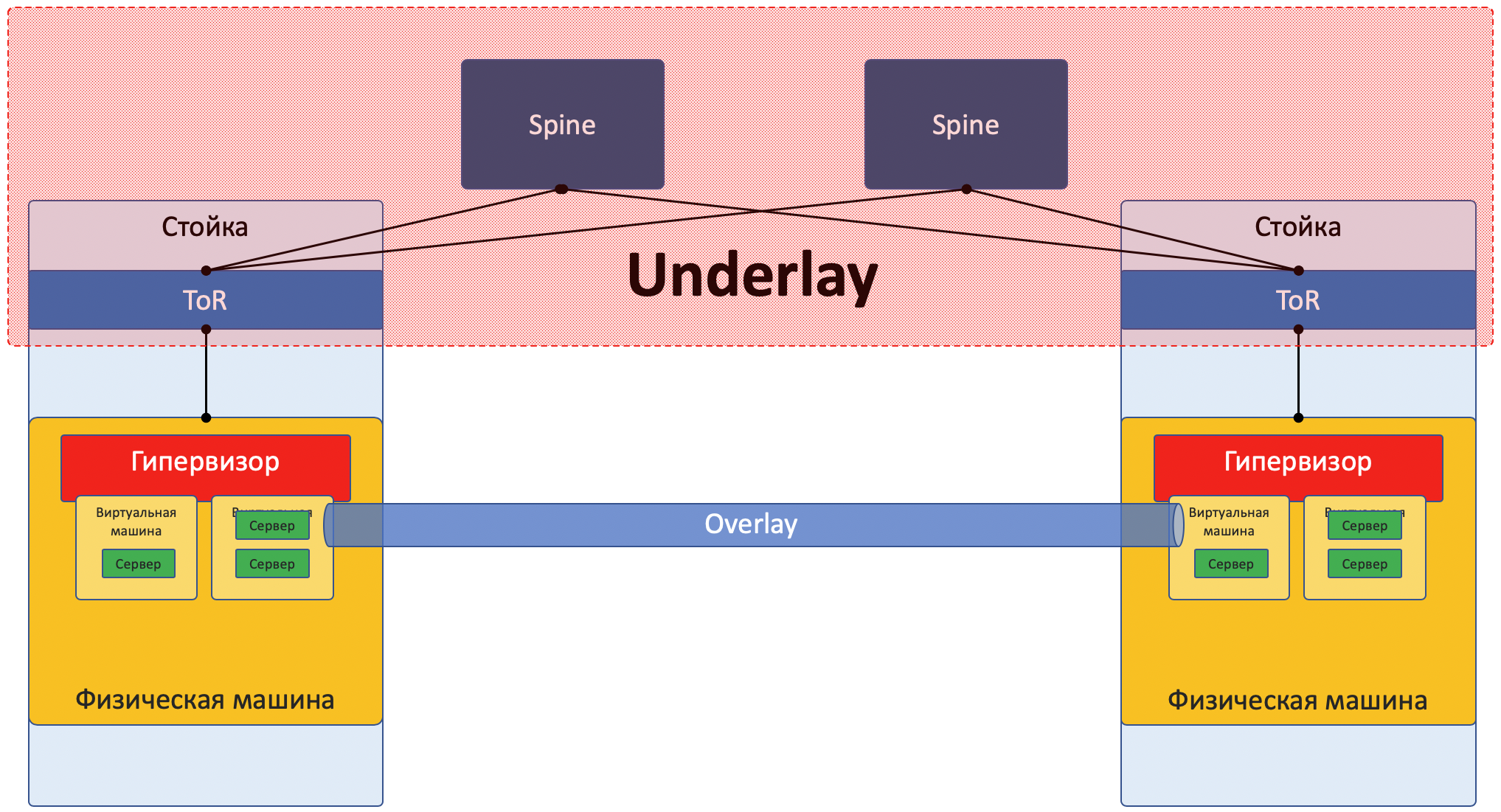
Il s'appuie sur des protocoles et des technologies standard. Notamment parce que les périphériques matériels fonctionnent toujours sur des logiciels propriétaires qui ne permettent ni la programmation des puces ni la mise en œuvre de leurs protocoles, respectivement, la compatibilité avec d'autres fournisseurs et la normalisation sont nécessaires.
Mais quelqu'un comme Google peut se permettre de développer ses propres commutateurs et d'abandonner les protocoles généralement acceptés. Mais LAN_DC n'est pas Google.
Le calque sous-jacent est relativement rarement modifié, car sa tâche est la connectivité IP de base entre les machines physiques. Underlay ne sait rien des services qui s'exécutent dessus, des clients, des locataires - il n'a besoin que de livrer un package d'une machine à une autre.
La sous-couche peut être comme ceci:
- IPv4 + OSPF
- IPv6 + ISIS + BGP + L3VPN
- L2 + TRILL
- L2 + STP
Le réseau Underlay est configuré de manière classique: CLI / GUI / NETCONF.
Manuellement, scripts, utilitaires propriétaires.
Plus en détail, le prochain article de la série sera consacré à la sous-couche.
Superposition
Overlay - un réseau de tunnels virtuels s'étendant sur Underlay, il permet aux machines virtuelles d'un client de communiquer entre elles, tout en assurant l'isolement des autres clients.
Les données client sont encapsulées dans tous les en-têtes de tunneling pour la transmission sur un réseau partagé.

Ainsi, les machines virtuelles d'un client (un service) peuvent communiquer entre elles via Overlay, sans même savoir ce que le paquet va réellement.
La superposition peut être par exemple la même que celle que j'ai mentionnée ci-dessus:
- Tunnel GRE
- VXLAN
- EVPN
- L3VPN
- GENEVE
Un réseau de superposition est généralement configuré et entretenu via un contrôleur central. À partir de là, la configuration, le plan de contrôle et le plan de données sont fournis aux périphériques qui acheminent et encapsulent le trafic client.
Ci-dessous, nous analyserons cela avec des exemples.
Oui, c'est du pur SDN.Il existe deux approches fondamentalement différentes pour organiser un réseau Overlay:
- Superposition avec ToR
- Superposition de l'hôte
Superposition avec ToR
La superposition peut commencer sur un commutateur d'accès monté en rack (ToR), comme c'est le cas, par exemple, dans le cas d'une usine VXLAN.
Il s'agit d'un mécanisme éprouvé sur les réseaux ISP et tous les fournisseurs d'équipement réseau le prennent en charge.
Cependant, dans ce cas, le commutateur ToR doit être en mesure de partager différents services, respectivement, et l'administrateur réseau doit dans une certaine mesure coopérer avec les administrateurs des machines virtuelles et apporter des modifications (quoique automatiquement) à la configuration du périphérique.
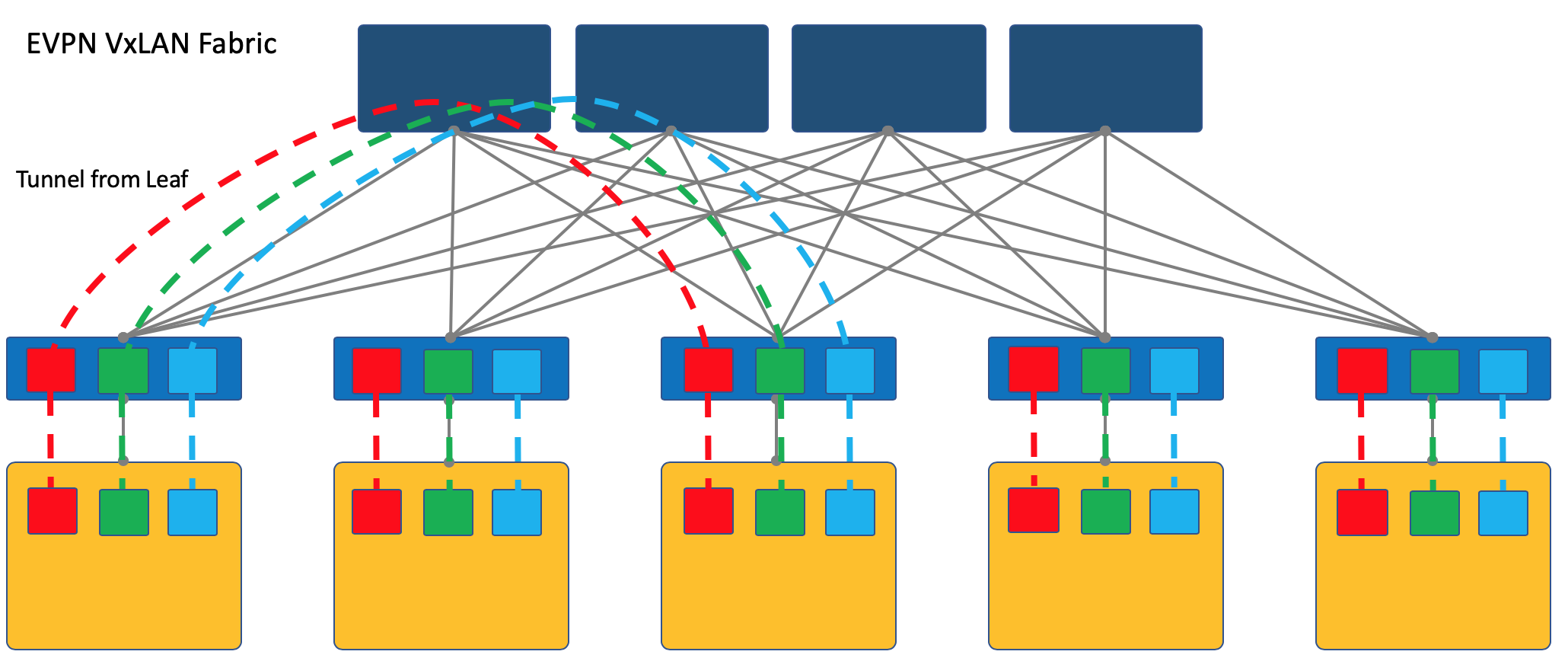
Ici, je vais renvoyer le lecteur à un article sur
VxLAN sur le hub de notre vieil ami
@bormoglotx .
Dans cette
présentation avec ENOG , les approches de la construction d'un réseau DC avec une usine EVPN VXLAN sont décrites en détail.
Et pour une immersion plus complète dans les réalités, vous pouvez lire le livre
Un tissu moderne, ouvert et évolutif: VXLAN EVPN .
Je note que VXLAN n'est qu'une méthode d'encapsulation et la terminaison de tunnel peut se produire non pas sur ToR, mais sur l'hôte, comme c'est le cas avec OpenStack, par exemple.
Cependant, l'usine VXLAN où la superposition commence sur ToR est l'une des conceptions de réseau de superposition bien établies.
Superposition de l'hôte
Une autre approche consiste à démarrer et à terminer les tunnels sur les hôtes finaux.
Dans ce cas, le réseau (Underlay) reste aussi simple et statique que possible.
Et l'hôte lui-même fait toute l'encapsulation nécessaire.
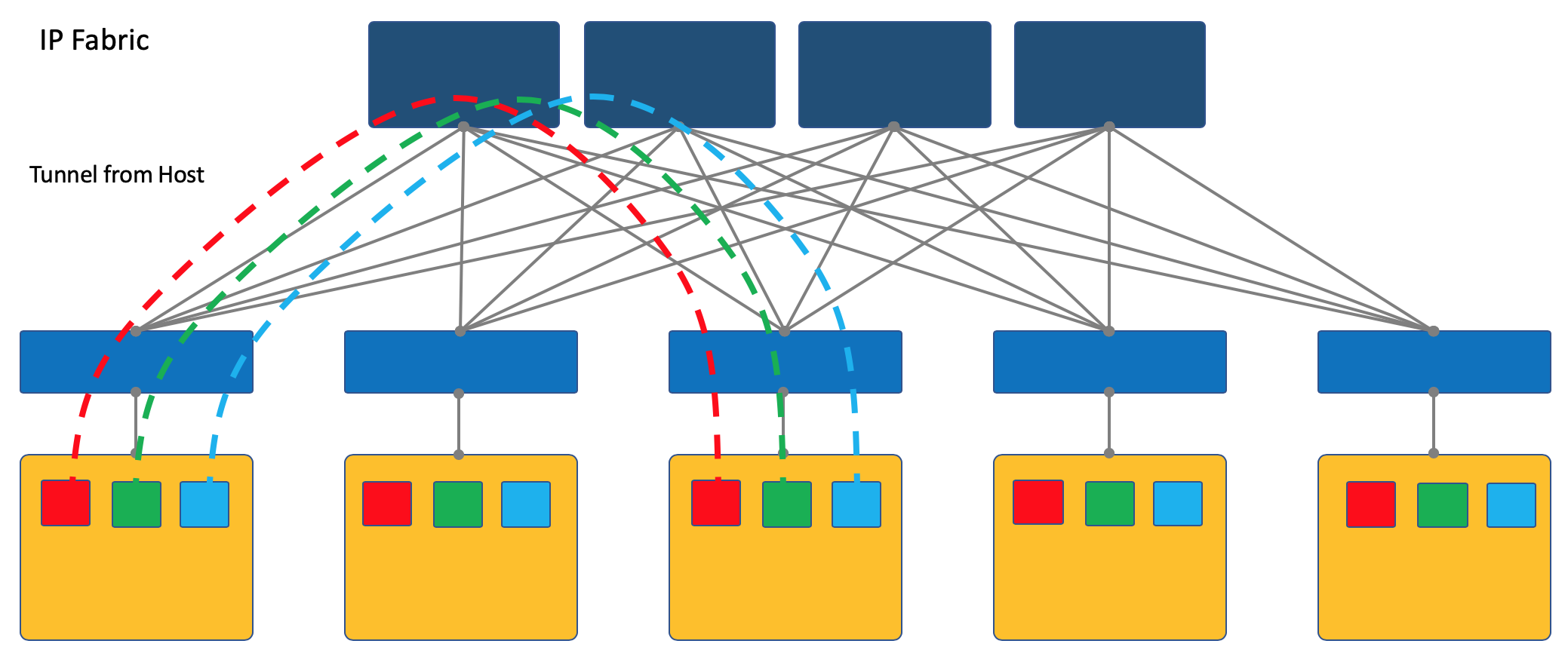
Pour ce faire, vous devrez certainement exécuter une application spéciale sur les hôtes, mais cela en vaut la peine.
Tout d'abord, exécuter un client sur une machine Linux est plus simple, ou, disons, généralement possible, tandis que sur le commutateur, vous devrez probablement vous tourner vers des solutions SDN propriétaires pour le moment, ce qui tue l'idée de multi-fournisseurs.
Deuxièmement, le commutateur ToR dans ce cas peut être laissé aussi simple que possible, à la fois du point de vue du plan de contrôle et du plan de données. En effet - alors il n'a pas besoin de communiquer avec le contrôleur SDN, et de stocker les réseaux / ARP de tous les clients connectés - aussi - il suffit de connaître l'adresse IP de la machine physique, ce qui simplifie grandement les tables de commutation / routage.
Dans la série ADSM, je choisis l'approche de superposition de l'hôte - alors nous n'en parlons que et nous ne reviendrons pas à l'usine VXLAN.
La façon la plus simple de considérer les exemples. Et comme sujet de test, nous prendrons la plate-forme OpenSource SDN OpenContrail, maintenant connue sous le nom de
Tungsten Fabric .
À la fin de l'article, je donnerai quelques réflexions sur l'analogie avec OpenFlow et OpenvSwitch.
Étude de cas: tissu de tungstène
Chaque machine physique a un
vRouter - un routeur virtuel qui connaît les réseaux qui lui sont connectés et à quels clients ils appartiennent - en fait - un routeur PE. Pour chaque client, il maintient une table de routage isolée (lire VRF). Et en fait, vRouter fait du tunnelage par superposition.
Un peu plus sur vRouter se trouve à la fin de l'article.
Chaque machine virtuelle située sur l'hyperviseur est connectée au vRouter de cette machine via l'
interface TAP .
TAP - Terminal Access Point - une interface virtuelle dans le noyau linux qui permet la mise en réseau.

S'il y a plusieurs réseaux derrière le vRouter, une interface virtuelle est créée pour chacun d'eux, à laquelle une adresse IP est affectée - ce sera l'adresse de passerelle par défaut.
Tous les réseaux d'un client sont placés dans un
VRF (une table), différent - dans différent.
Je ferai ici une réserve que ce n'est pas si simple, et enverrai le lecteur curieux à la fin de l'article .
Pour que vRouter'y communique entre eux et, par conséquent, les machines virtuelles situées derrière eux, ils échangent des informations de routage via un
contrôleur SDN .
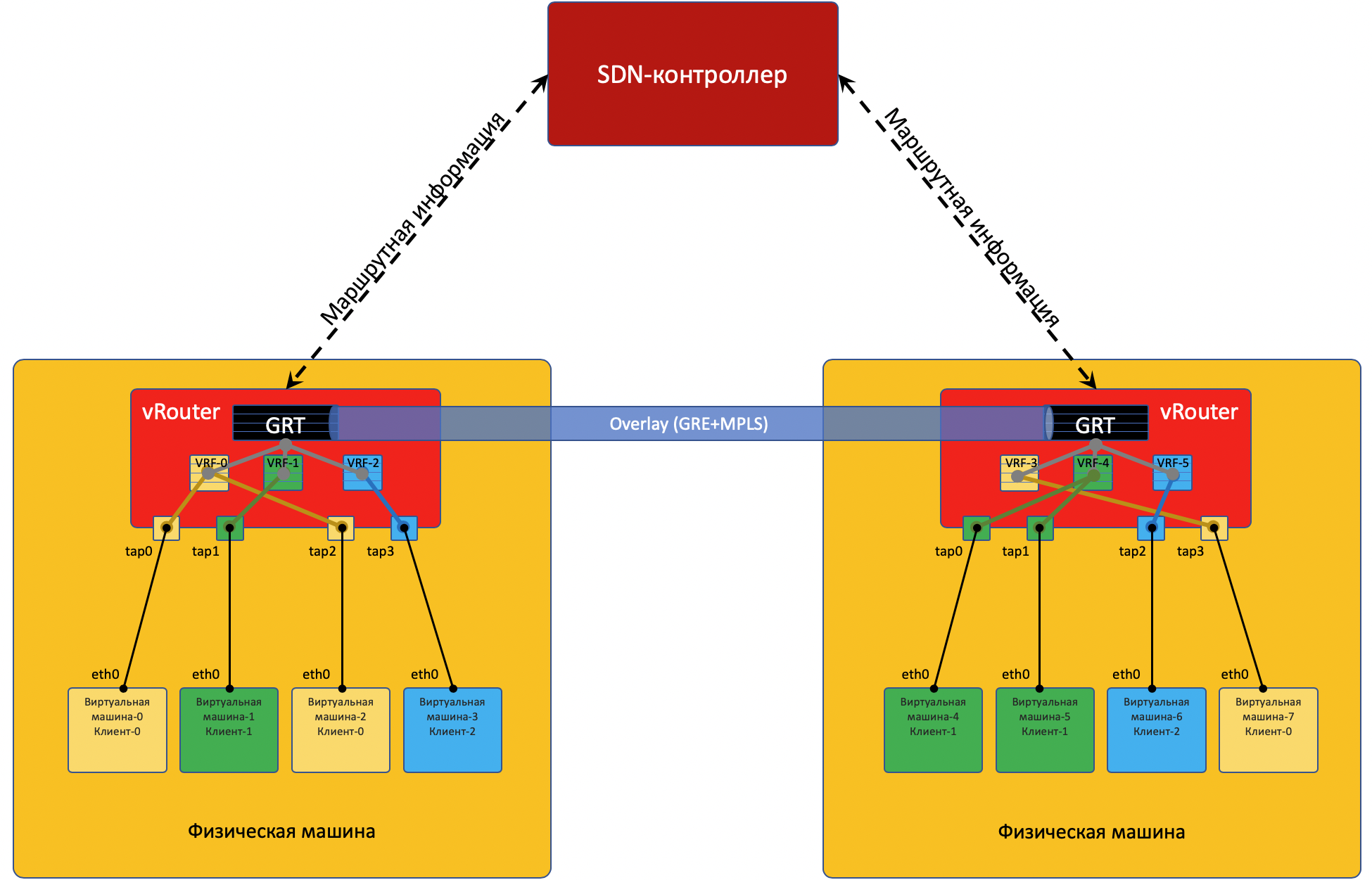
Pour entrer dans le monde extérieur, il y a un point de sortie de la matrice - la passerelle de réseau virtuel
VNGW - Virtual Network GateWay (
mon terme ).
Examinons maintenant les exemples de communications - et il y aura de la clarté.
Communication au sein d'une machine physique
VM0 veut envoyer un paquet à VM2. Supposons pour l'instant qu'il s'agit d'une machine virtuelle cliente unique.
Plan de données
- VM-0 a une route par défaut dans son interface eth0. Le paquet y est envoyé.
Cette interface eth0 est en fait virtuellement connectée au routeur virtuel vRouter via l'interface tap0 TAP. - vRouter analyse à quelle interface le paquet est arrivé, c'est-à-dire à quel client (VRF) il appartient, vérifie l'adresse du destinataire avec la table de routage de ce client.
- Après avoir découvert que le récepteur sur la même machine se trouve derrière un port différent, vRouter lui envoie simplement le paquet sans en-têtes supplémentaires - dans ce cas, le vRouter a déjà un enregistrement ARP.
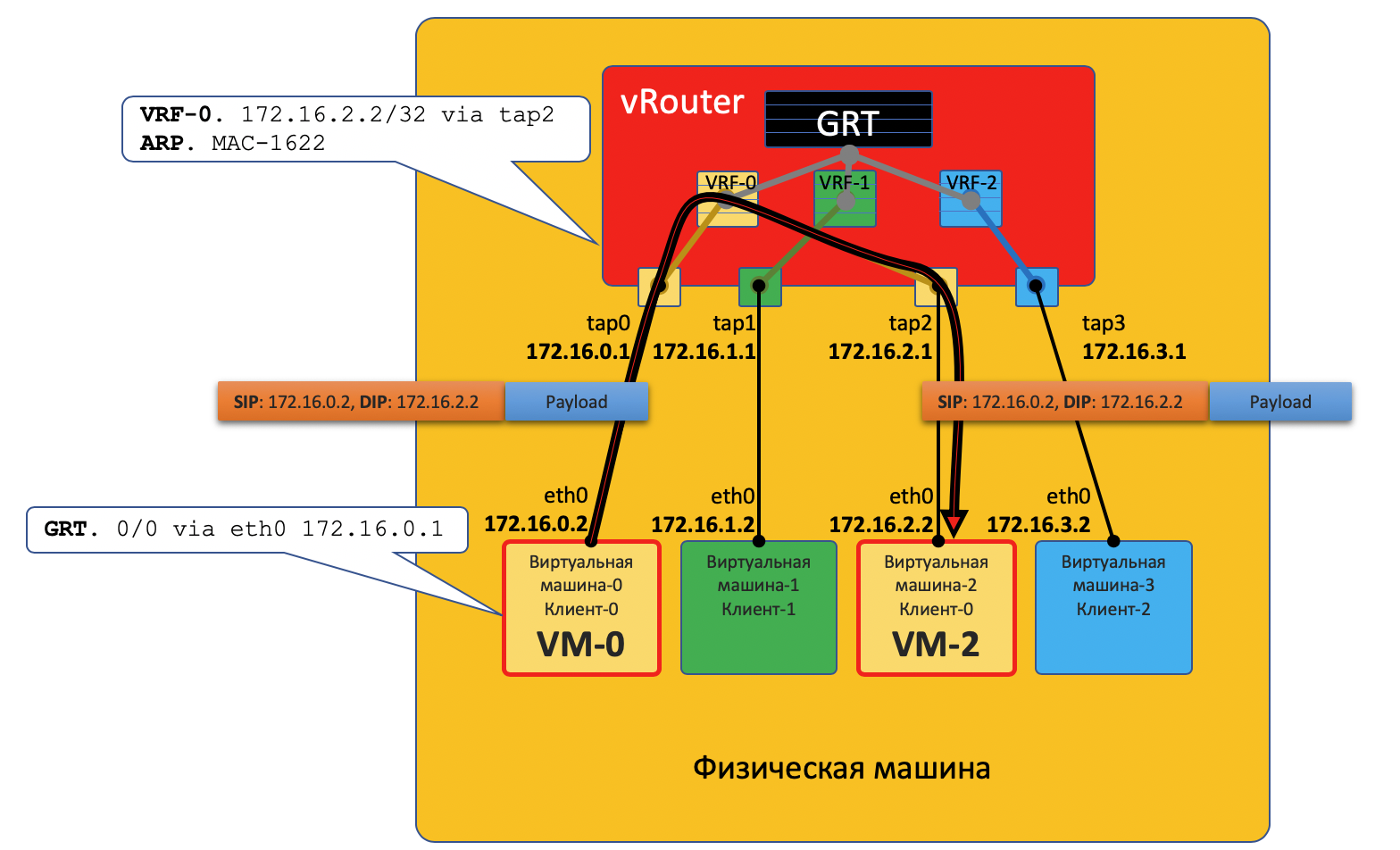
Dans ce cas, le paquet n'entre pas dans le réseau physique - il est routé à l'intérieur de vRouter.
Avion de contrôle
Lorsque la machine virtuelle démarre, l'hyperviseur lui dit:
- Sa propre adresse IP.
- La route par défaut passe par l'adresse IP du vRouter sur ce réseau.
Grâce à une API spéciale, l'hyperviseur rend compte à vRouter:
- Ce dont vous avez besoin pour créer une interface virtuelle.
- Laquelle (VM) doit créer un réseau virtuel.
- À quel VRF le lier (VN).
- L'enregistrement ARP statique pour cette machine virtuelle est quelle interface a son adresse IP et à quelle adresse MAC elle est attachée.
Et encore une fois, la véritable procédure d'interaction est simplifiée afin de comprendre le concept.

Ainsi, toutes les machines virtuelles d'un client sur une machine donnée, vRouter considère comme des réseaux directement connectés et peut router entre eux lui-même.
Mais VM0 et VM1 appartiennent à des clients différents, respectivement, sont dans des tables différentes vRouter'a.
Leur capacité à communiquer directement entre eux dépend des paramètres du vRouter et de la conception du réseau.
Par exemple, si les machines virtuelles des deux clients utilisent des adresses publiques ou si NAT se produit sur le vRouter lui-même, le routage direct vers vRouter peut également être effectué.
Dans le cas contraire, il est possible de traverser des espaces d'adressage - vous devez passer par un serveur NAT pour obtenir une adresse publique - cela est similaire à l'accès à des réseaux externes, qui sont décrits ci-dessous.
Communication entre machines virtuelles situées sur différentes machines physiques
Plan de données
- Le début est exactement le même: VM-0 envoie un paquet avec la destination VM-7 (172.17.3.2) par défaut.
- vRouter le reçoit et cette fois voit que la destination est sur une autre machine et est accessible via le tunnel Tunnel0.
- Tout d'abord, il raccroche l'étiquette MPLS identifiant l'interface distante, de sorte qu'à l'arrière de vRouter, il puisse déterminer où placer ce paquet sans crochets supplémentaires.

- Tunnel0 a une source de 10.0.0.2, le récepteur: 10.0.1.2.
vRouter ajoute des en-têtes GRE (ou UDP) et une nouvelle adresse IP au paquet d'origine. - La table de routage vRouter a une route par défaut via l'adresse ToR1 10.0.0.1. Là et envoie.
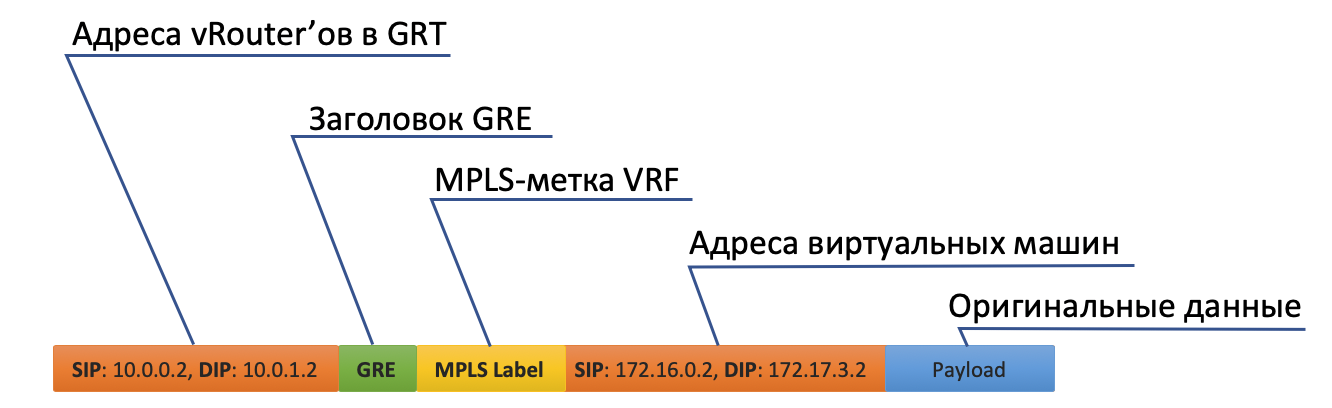
- ToR1 en tant que membre du réseau Underlay sait (par exemple, via OSPF) comment accéder à 10.0.1.2 et envoie un paquet le long de l'itinéraire. Veuillez noter que l'ECMP est inclus ici. Dans l'illustration, il y a deux nexsthops, et différents flux y seront disposés par hachage. Dans le cas d'une véritable usine, il y aura vraisemblablement 4 prochaines opérations.
En même temps, il n'a pas besoin de savoir ce qui se trouve sous l'en-tête IP externe. En fait, sous IP, il peut y avoir un sandwich entre IPv6 sur MPLS sur Ethernet sur MPLS sur GRE sur sur grec. - En conséquence, côté réception, vRouter supprime GRE et, à l'aide de l'étiquette MPLS, comprend à quelle interface ce paquet doit être transmis, le supprime et l'envoie au destinataire dans sa forme d'origine.
Avion de contrôle
Lorsque vous démarrez la machine, tout ce qui se passe est décrit ci-dessus.
Et en plus de ce qui suit:
- Pour chaque client, vRouter alloue une balise MPLS. Il s'agit de l'étiquette de service L3VPN où les clients seront répartis sur la même machine physique.
En fait, la balise MPLS est toujours allouée par le vRouter'om toujours - car on ne sait pas à l'avance que la machine n'interagira qu'avec d'autres machines derrière le même vRouter'om et ce n'est probablement même pas le cas.
- vRouter établit une connexion avec le contrôleur SDN via BGP (ou similaire - dans le cas de TF, il s'agit de XMPP 0_o).
- À travers cette session, vRouter indique au contrôleur SDN les routes vers les réseaux connectés:
- Adresse réseau
- Méthode d'encapsulation (MPLSoGRE, MPLSoUDP, VXLAN)
- Étiquette MPLS client
- Votre adresse IP comme nexthop
- Le contrôleur SDN reçoit ces routes de tous les vRouter'ov connectés et les renvoie aux autres. Autrement dit, il agit comme un réflecteur de route.
La même chose se produit dans la direction opposée.

La superposition peut changer au moins toutes les minutes. Quelque chose comme cela se produit dans les clouds publics, lorsque les clients démarrent et éteignent régulièrement leurs machines virtuelles.
Le contrôleur central assume toutes les difficultés de maintenance de la configuration et de contrôle des tables de commutation / routage sur vRouter.
En gros, le contrôleur s'arrête avec tous les vRouter via BGP (ou un protocole similaire) et transmet simplement les informations de routage. BGP, par exemple, possède déjà une famille d'adresses pour transmettre la méthode d'encapsulation
MPLS-in-GRE ou
MPLS-in-UDP .
Dans le même temps, la configuration du réseau Underlay ne change en rien, ce qui, incidemment, est beaucoup plus difficile à automatiser, et il est plus facile de rompre avec un mouvement maladroit.
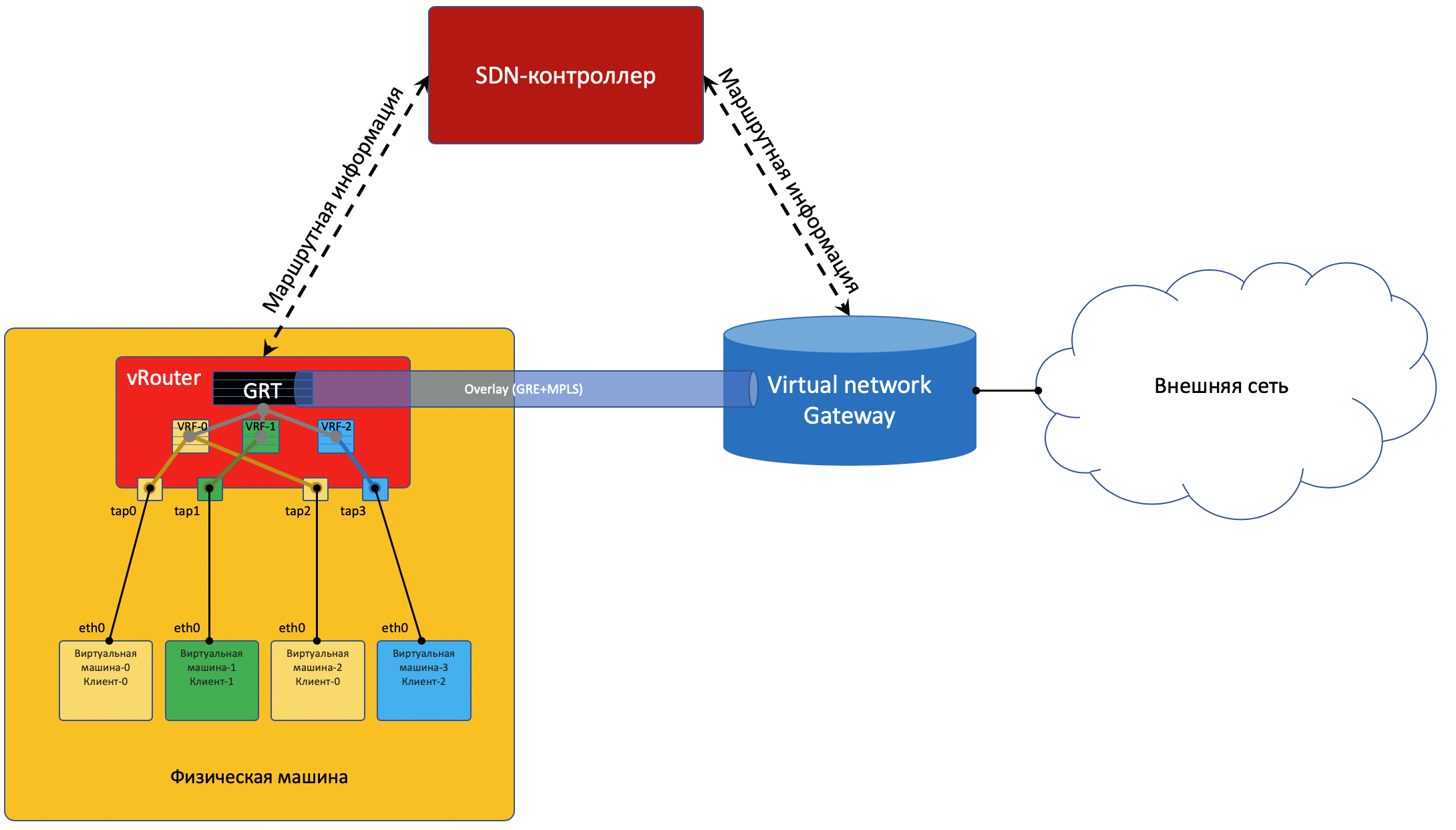
Sortie sur le monde extérieur
Quelque part, la simulation devrait se terminer, et à partir du monde virtuel, vous devez entrer dans le vrai. Et vous avez besoin d'une passerelle de
téléphones payants .
Deux approches sont pratiquées:
- Un routeur matériel est installé.
- Une appliance est lancée qui implémente les fonctions d'un routeur (oui, nous avons fait face à VNF après SDN). Appelons cela une passerelle virtuelle.
— — . , , , , , , , , , .
, , , , ( ). , - , , — .
Avec un pied, la passerelle regarde le réseau virtuel Overlay, comme une machine virtuelle normale, et peut interagir avec toutes les autres machines virtuelles. En même temps, il peut terminer sur lui-même les réseaux de tous les clients et, en conséquence, effectuer le routage entre eux.Avec l'autre pied, la passerelle regarde déjà le réseau fédérateur et sait comment accéder à Internet.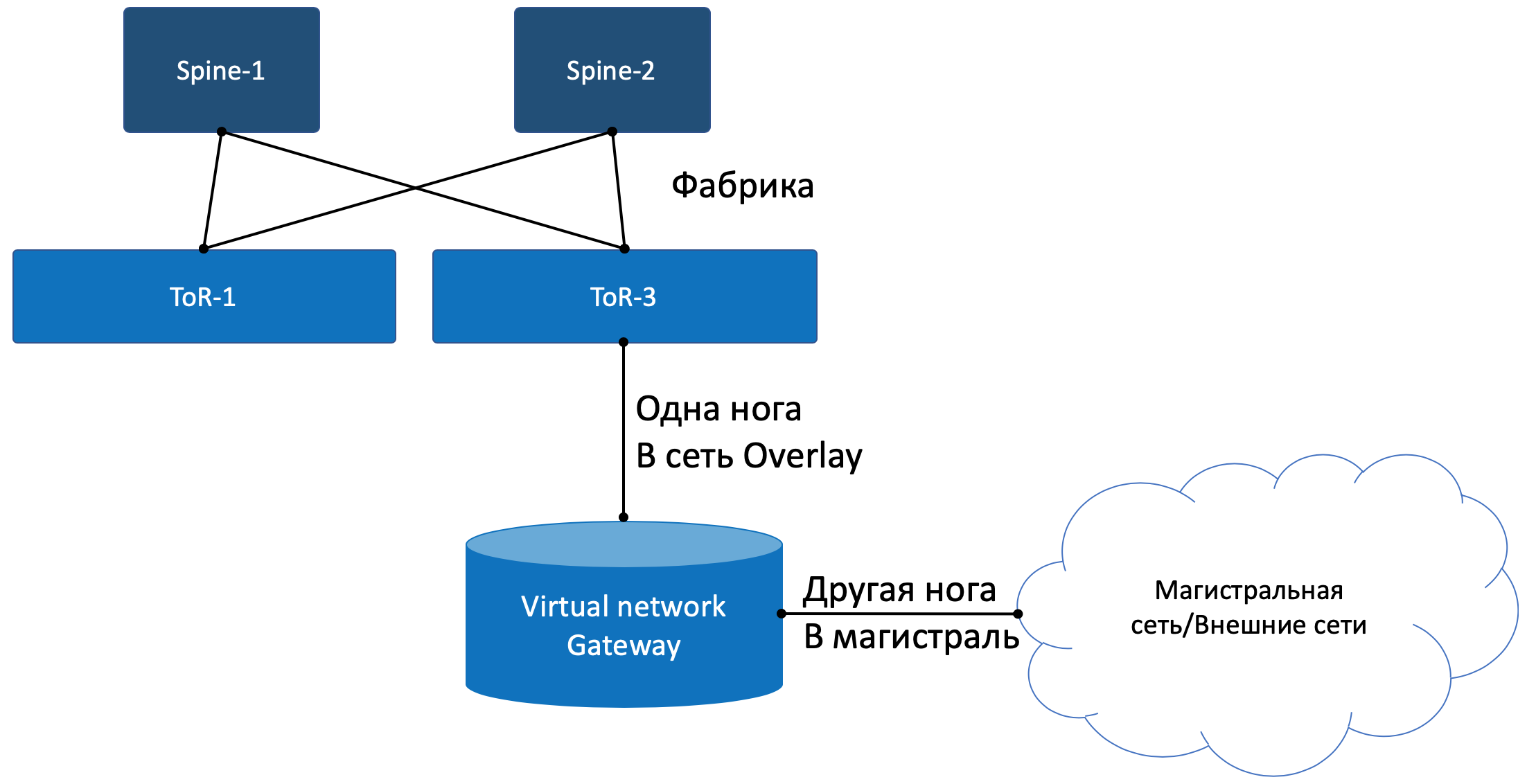
Plan de données
Autrement dit, le processus ressemble à ceci:- VM-0, ayant par défaut tous dans le même vRouter, envoie un paquet avec une destination dans le monde extérieur (185.147.83.177) à l'interface eth0.
- vRouter reçoit ce paquet et effectue une recherche d'adresse de destination dans la table de routage - il trouve la route par défaut via la passerelle VNGW1 via le tunnel 1.
Il voit également qu'il s'agit d'un tunnel GRE avec SIP 10.0.0.2 et DIP 10.0.255.2, et raccroche d'abord MPLS- L'étiquette de ce client que VNGW1 attend.
- vRouter emballe le paquet d'origine dans le MPLS, GRE et les nouveaux en-têtes IP et l'envoie à ToR1 10.0.0.1 par défaut.
- Un réseau sous-jacent livre le paquet à la passerelle VNGW1.
- La passerelle VNGW1 supprime les en-têtes de tunnel GRE et MPLS, voit l'adresse de destination, consulte sa table de routage et comprend qu'elle est dirigée vers Internet - cela signifie par le biais de la vue complète ou par défaut. Si nécessaire, effectue la traduction NAT.
- De VNGW à la frontière, il peut y avoir un réseau IP régulier, ce qui est peu probable.
Il peut s'agir d'un réseau MPLS classique (IGP + LDP / RSVP TE), il peut s'agir d'un retour d'usine avec un BGP LU, ou d'un tunnel GRE de VNGW à la frontière via le réseau IP.
Quoi qu'il en soit, VNGW1 effectue les encapsulations nécessaires et envoie le paquet d'origine vers la frontière.
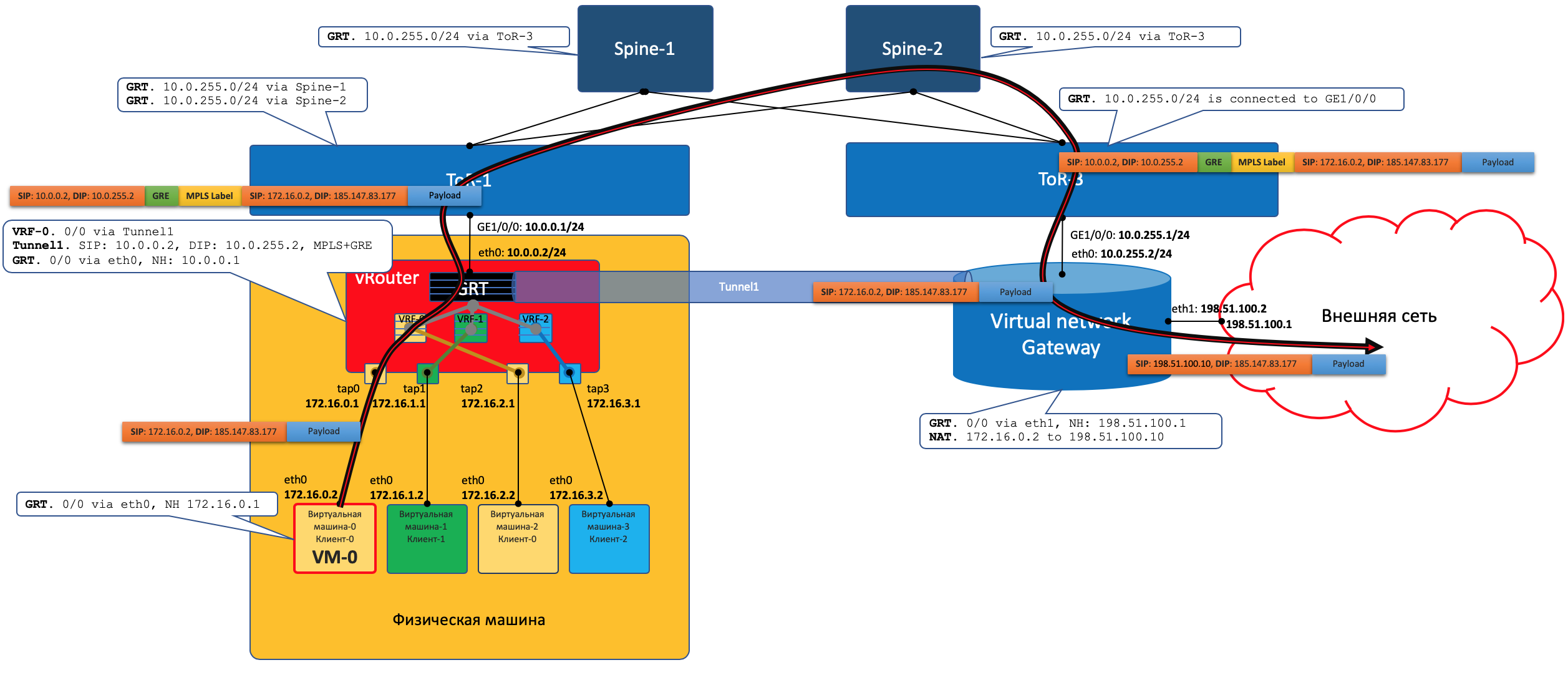 Le trafic en sens inverse passe par les mêmes étapes dans l'ordre inverse.
Le trafic en sens inverse passe par les mêmes étapes dans l'ordre inverse.- VNGW1
- , , Tunnel1 (MPLSoGRE MPLSoUDP).
- , MPLS, GRE/UDP IP ToR3 10.0.255.1.
— IP- vRouter', — 10.0.0.2. - vRouter'.
- vRouter GRE/UDP, MPLS- IP- TAP-, eth0 .

Control Plane
VNGW1 établit un voisinage BGP avec le contrôleur SDN, à partir duquel il reçoit toutes les informations de routage sur les clients: quelle adresse IP (vRouter'om) est quel client et avec quelle étiquette MPLS il s'identifie.De même, il indique lui-même au contrôleur SDN l'itinéraire par défaut avec l'étiquette de ce client, en se désignant comme nexthop. Et puis ce défaut vient à vRouter'y.Les VNGW acheminent généralement l'agrégation ou la traduction NAT.Et dans la direction opposée, il donne exactement cette route agrégée à une session avec des pensionnaires ou des réflecteurs de route. Et d'eux reçoit un itinéraire par défaut ou Full-View, ou autre chose.En termes d'encapsulation et d'échange de trafic, VNGW n'est pas différent de vRouter.Si vous étendez un peu la zone, vous pouvez ajouter d'autres périphériques réseau à VNGW et vRouter, tels que des pare-feu, des batteries de purification ou d'enrichissement du trafic, IPS, etc.Et avec l'aide de la création successive de VRF et de l'annonce correcte des itinéraires, vous pouvez faire une boucle de trafic comme vous le souhaitez, ce qui est appelé Service Chaining.Autrement dit, ici, le contrôleur SDN agit comme un réflecteur de route entre VNGW, vRouter'ami et d'autres périphériques réseau.Mais en fait, le contrôleur publie également des informations sur les ACL et les PBR (Policy Based Routing), forçant les flux de trafic individuels à aller différemment que l'itinéraire leur indique.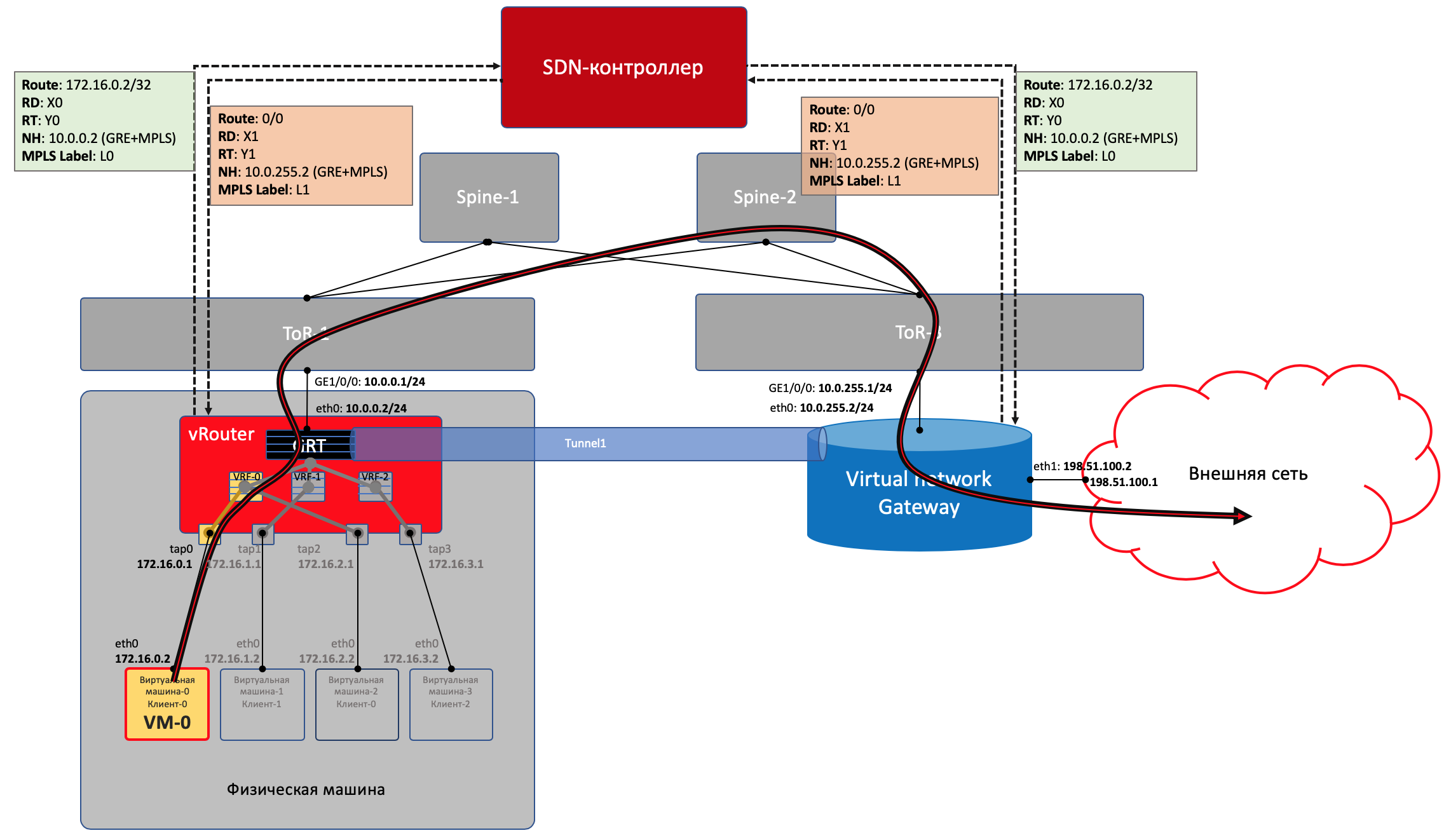
FAQ
Pourquoi faites-vous toujours une remarque GRE / UDP?Eh bien, en général, on peut dire qu'il est spécifique au tissu de tungstène - vous pouvez l'ignorer complètement.Mais si vous le prenez, TF lui-même, tout en étant un OpenContrail, supportait les deux encapsulations: MPLS en GRE et MPLS en UDP.UDP est bon car dans le port source dans son en-tête, il est très facile de coder une fonction de hachage à partir du port IP + Proto + d'origine, ce qui permettra l'équilibrage.Dans le cas de GRE, hélas, il n'y a que des en-têtes IP et GRE externes qui sont les mêmes pour tout le trafic encapsulé et il n'est pas question d'équilibrer - peu de personnes peuvent regarder si profondément à l'intérieur du paquet.Jusqu'à un certain temps, les routeurs, s'ils savaient utiliser des tunnels dynamiques, uniquement dans MPLSoGRE, et très récemment, ont appris dans MPLSoUDP. Par conséquent, vous devez toujours faire une remarque sur la possibilité de deux encapsulations différentes.En toute honnêteté, il convient de noter que TF prend entièrement en charge la connectivité L2 à l'aide de VXLAN.Vous avez promis d'établir des parallèles avec OpenFlow.Ils mendient vraiment. vSwitch dans le même OpenStack fait des choses très similaires en utilisant VXLAN, qui, incidemment, a également un en-tête UDP.Dans le plan de données, ils fonctionnent approximativement de la même manière, le plan de contrôle diffère considérablement. Tungsten Fabric utilise XMPP pour fournir des informations de route à vRouter, tandis que Openflow fonctionne dans OpenStack.Puis-je en savoir un peu plus sur vRouter?Il est divisé en deux parties: vRouter Agent et vRouter Forwarder.Le premier est lancé dans l'espace utilisateur du système d'exploitation hôte et communique avec le contrôleur SDN, échangeant des informations sur les routes, VRF et ACL.Le second implémente Data Plane - généralement dans Kernel Space, mais peut également être lancé sur SmartNIC - des cartes réseau avec un processeur et une puce de commutation programmable séparée, ce qui vous permet de supprimer la charge du processeur de la machine hôte et de rendre le réseau plus rapide et plus prévisible.Un autre scénario est possible lorsque vRouter est une application DPDK dans l'espace utilisateur.vRouter Agent supprime les paramètres de vRouter Forwarder.Qu'est-ce que le réseau virtuel?J'ai mentionné au début de l'article sur VRF que chaque locataire est attaché à son VRF. Et si cela suffisait pour une compréhension superficielle du travail du réseau de superposition, alors déjà à la prochaine itération, il est nécessaire de clarifier.Habituellement, dans les mécanismes de virtualisation, l'entité Virtual Network (vous pouvez la prendre comme un nom propre) est introduite séparément des clients / locataires / machines virtuelles - c'est une chose assez indépendante. Et ce réseau virtuel à travers les interfaces peut déjà être connecté dans un locataire, dans l'autre, dans deux, mais au moins où. Ainsi, par exemple, le chaînage de services est implémenté, lorsque le trafic doit être passé par certains nœuds dans la séquence souhaitée, créant et appelant simplement des réseaux virtuels dans la séquence correcte.Par conséquent, en tant que tel, il n'y a pas de correspondance directe entre le réseau virtuel et le locataire.
Conclusion
Il s'agit d'une description très superficielle du fonctionnement d'un réseau virtuel avec une superposition de l'hôte et du contrôleur SDN. Mais quelle que soit la plateforme de virtualisation que vous utilisez aujourd'hui, elle fonctionnera de la même manière, que ce soit VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric ou Juniper Contrail. Ils diffèrent par les types d'encapsulation et les en-têtes, les protocoles pour fournir des informations aux périphériques réseau finaux, mais le principe d'un réseau de superposition réglé par logiciel fonctionnant au-dessus d'un réseau de sous-couche relativement simple et statique restera le même.On peut dire que dans les domaines de la création d'un cloud privé à ce jour, le SDN basé sur le réseau de superposition a gagné. Cependant, cela ne signifie pas qu'Openflow n'a pas sa place dans le monde moderne - il est utilisé dans OpenStacke et dans le même VMWare NSX, à ma connaissance, Google l'utilise pour configurer le réseau de sous-couches.Ci-dessous, j'ai donné des liens vers des documents plus détaillés, si vous souhaitez étudier la question plus en profondeur.Et quelle est notre sous-couche?Mais en général, rien. Il n'a pas complètement changé. Tout ce qu'il doit faire en cas de superposition de l'hôte est de mettre à jour les routes et les ARP lorsque vRouter / VNGW apparaît et disparaît et de faire glisser les paquets entre eux.Formulons une liste d'exigences pour un réseau Underlay.- Pour pouvoir un certain protocole de routage, dans notre situation - BGP.
- , , - .
- ECMP — .
- QoS, , ECN.
- NETCONF — .
J'ai consacré très peu de temps ici au travail du réseau Underlay lui-même. En effet, plus tard dans la série, je me concentrerai dessus et nous ne toucherons à Overlay qu'en passant.Évidemment, je nous limite sévèrement tous, en utilisant comme exemple le réseau DC construit à l'usine Klose avec un routage IP pur et une superposition de l'hôte.Cependant, je suis sûr que tout réseau qui a une conception peut être décrit en termes formels et automatisé. C'est juste que je poursuis l'objectif de comprendre les approches de l'automatisation, et de ne pas confondre tout le monde, de résoudre le problème d'une manière générale.Dans le cadre de l'ADSM, Roman Gorge et moi prévoyons de publier un numéro distinct sur la virtualisation de la puissance de calcul et son interaction avec la virtualisation de réseau. Restez en contact.Liens utiles
Merci
- Roman Gorge , ancien hébergeur principal du podcast linkmeup, et maintenant expert dans le domaine des plateformes cloud. Pour commentaires et modifications. Eh bien, nous attendons avec impatience un article plus approfondi sur la virtualisation dans un proche avenir.
- Alexander Shalimov , mon collègue et expert dans le développement de réseaux virtuels. Pour commentaires et modifications.
- Valentina Sinitsyna , ma collègue et experte en tissu de tungstène. Pour commentaires et modifications.
- Artyom Chernobay - maillage illustrateur. Pour KDPV.
- Alexander Limonov. Pour le mème "automate".