Autrefois, nous n'avions que quelques services et la mise à jour de plusieurs d'entre eux en production en une journée a été un grand
succès . Puis le monde s'est accéléré, le système est devenu plus complexe et nous nous sommes transformés en une organisation avec une architecture de microservices. Nous avons maintenant une centaine de services, et avec l'augmentation de leur nombre, la fréquence des sorties augmente également - il y en a plus de 250 par semaine.
Et si de nouvelles fonctionnalités sont testées au sein des équipes produit, alors la tâche de l'équipe de test d'intégration est de vérifier que les modifications incluses dans la version ne cassent pas la fonctionnalité du composant, du système et d'autres fonctionnalités.

Je travaille en tant qu'ingénieur en automatisation des tests chez Yandex.Money.
Dans cet article, je parlerai de l'évolution des tests d'intégration des services Web, ainsi que de l'adaptation du processus pour augmenter le nombre de composants du système et augmenter la fréquence des versions.
À propos des changements dans le cycle de publication et le développement du mécanisme de calcul ont été décrits par ops et dev dans l'
un des articles précédents . Je vais vous parler de l'historique des changements dans les processus de test au cours de cette transformation.
Nous avons maintenant environ 30 équipes de développement. L'équipe comprend généralement le chef de produit, le chef de projet, les développeurs et testeurs frontaux et principaux. Ils sont unis par le travail sur des tâches pour un produit spécifique. En règle générale, une équipe est responsable du service, qui y apporte le plus souvent des modifications.
Test d'acceptation de bout en bout
Il n'y a pas si longtemps, avec la sortie de chaque composant, seuls des tests unitaires et des composants étaient exécutés, et après cela, seuls quelques-uns des scripts de bout en bout les plus importants étaient exécutés sur un environnement de test à part entière avant de mettre le service en production. Parallèlement à l'augmentation du nombre de composants, le nombre de connexions entre eux a commencé à croître de façon exponentielle. Souvent - des connexions complètement non triviales. Je me souviens comment l'indisponibilité du service pour l'émission de données marketing a complètement interrompu l'inscription des utilisateurs (bien sûr, pendant une courte période).
Cette approche de vérification des modifications a commencé à échouer de plus en plus souvent - elle nécessitait de couvrir tous les scénarios d'entreprise critiques avec des autotests et de les exécuter sur un environnement de test à part entière avec une version de composant prête à être publiée.
D'accord, des autotests pour des scénarios critiques sont apparus - mais comment les exécuter? Il y avait une tâche à intégrer dans le cycle de publication, affectant au minimum sa fiabilité avec de fausses baisses de test. En revanche, je souhaitais réaliser l'étape de test d'intégration le plus rapidement possible. Il y avait donc une infrastructure pour effectuer des tests d'acceptation.
Nous avons essayé d'utiliser au maximum les outils déjà utilisés pour exécuter le composant sur le cycle de publication et les tâches de lancement: Jira et Jenkins, respectivement.
Cycle de test d'acceptation
Pour effectuer les tests d'acceptation, nous avons déterminé le cycle suivant:
- suivi des tâches entrantes pour les tests d'acceptation d'une version,
- l'exécution du travail Jenkins pour installer la version de build sur un environnement de test,
- vérifier que le service a augmenté,
- lancer le job Jenkins avec des tests d'intégration,
- analyse des résultats de l'analyse,
- test répété (si nécessaire),
- mise à jour de l'état de la tâche - terminée ou interrompue, en indiquant la raison dans le commentaire.
Le cycle entier a été effectué manuellement à chaque fois. En conséquence, déjà à la dixième sortie par jour, je voulais jurer d'exécuter les mêmes tâches, au mieux, sous mon souffle, en me serrant la tête et en exigeant de la
bière de valériane.
Moniteur Bot
Nous avons réalisé que le suivi et la génération de rapports sur les nouvelles tâches dans Jira sont des processus importants qui sont rapides et faciles à automatiser. Il y avait donc un bot qui fait ça.
Les données pour générer des alertes se présentent sous la forme de notifications push de Jira. Après le lancement du bot, nous avons cessé de mettre à jour la page du tableau de bord avec les tâches d'acceptation, et la largeur du sourire de l'automate a légèrement augmenté.
Pinger
Nous avons décidé de simplifier la vérification que lors du déploiement dans l'environnement de test, aucune erreur d'assemblage ou d'installation ne s'est produite et que la version souhaitée du composant a été générée, et pas une autre. Le composant donne sa version et son statut via HTTP. Et vérifier que le service renvoie la version correcte serait simple et compréhensible si différents composants n'étaient pas écrits dans des langages différents - certains en Node.js, certains en C #. De plus, nos services les plus populaires en Java ont également fourni la version dans un format différent.
De plus, je voulais avoir des informations et des notifications en temps réel non seulement sur les changements de version, mais aussi sur les changements dans la disponibilité des composants dans le système. Pour résoudre ce problème, le service Pinger est apparu, qui collecte des informations sur l'état et la version des composants en les interrogeant de manière cyclique.
Nous utilisons un modèle push de remise des messages - un agent est déployé sur chaque instance de l'environnement de test, qui collecte des informations sur les composants de cet environnement et stocke les données sur un nœud central toutes les 10 secondes. Nous allons à ce nœud pour l'état actuel - cette approche nous permet de prendre en charge plus d'une centaine de bancs d'essai.
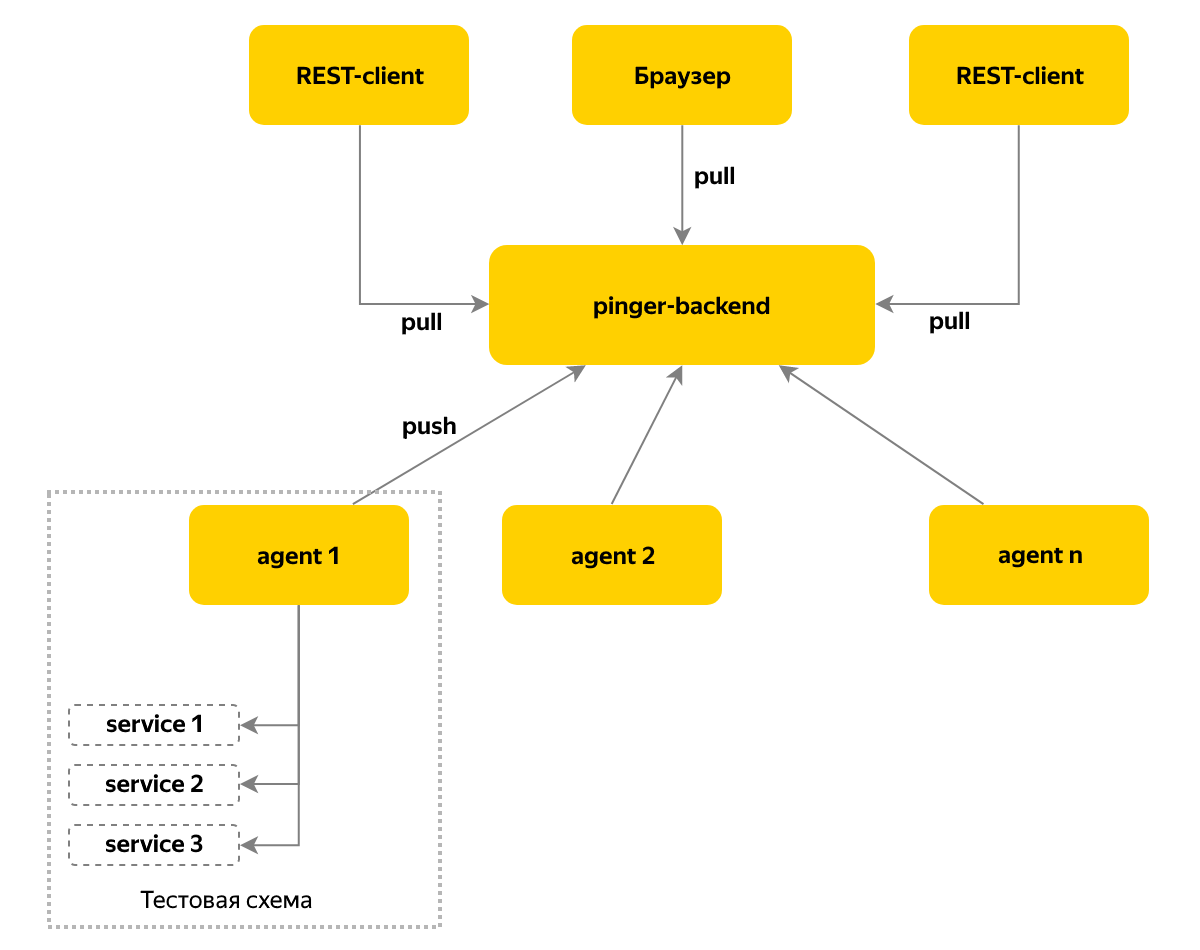
Casier
Le temps est venu pour des tâches plus complexes - mise à jour automatique des composants et exécution de tests. A cette époque, notre équipe disposait déjà de 3 bancs de test dans OpenStack pour les tests d'acceptation, et il fallait d'abord résoudre le problème de gestion des ressources des bancs de test: il serait désagréable que la mise à jour de la prochaine version «roule» lors de l'exécution des tests sur le système. Il arrive également que le banc de test soit débogué, et vous ne devez donc pas l'utiliser pour l'acceptation.
Je voulais pouvoir voir le statut de l'emploi et, si nécessaire, verrouiller manuellement le stand pendant la durée de l'analyse des tests tombés ou jusqu'à la fin des autres travaux.
Pour tout cela, le service Locker est apparu. Il maintient le statut du banc de test pendant une longue période («occupé» / «gratuit»), vous permet de spécifier un commentaire sur «occupé», de sorte qu'il est clair que nous déboguons maintenant, recréons une copie de l'environnement de test ou exécutons des tests pour la prochaine version. Nous avons également commencé à bloquer les stands la nuit - sur eux les administrateurs effectuent des travaux selon un calendrier, tels que les sauvegardes et la synchronisation de la base de données.
Lors du blocage, l'heure est toujours définie après laquelle le verrou expire - maintenant, les gens n'ont plus besoin de participer au retour des stands dans le pool disponible, et la machine fait tout.
Devoir
Pour répartir uniformément la charge entre les membres de l'équipe pour analyser les résultats des tests, nous avons proposé des équipes quotidiennes. Le préposé travaille avec les tâches de test d'acceptation des versions, analyse les autotests tombés et signale les bogues. Si le préposé comprend qu'il ne gère pas le déroulement des tâches, il peut demander de l'aide à l'équipe. À l'heure actuelle, le reste de l'équipe est engagé dans des tâches qui ne sont pas liées aux versions.
Avec l'augmentation du nombre de versions, le rôle du deuxième opérateur est apparu, qui se connecte à la principale s'il y a des blocages ou s'il y a des versions critiques dans la file d'attente. Afin de fournir des informations sur l'avancement des tests des versions, nous avons créé une page avec le nombre de tâches dans les états «ouvert» / «en cours» / «en attente d'une réponse en service», l'état du blocage des bancs d'essai et les composants inaccessibles sur les stands:
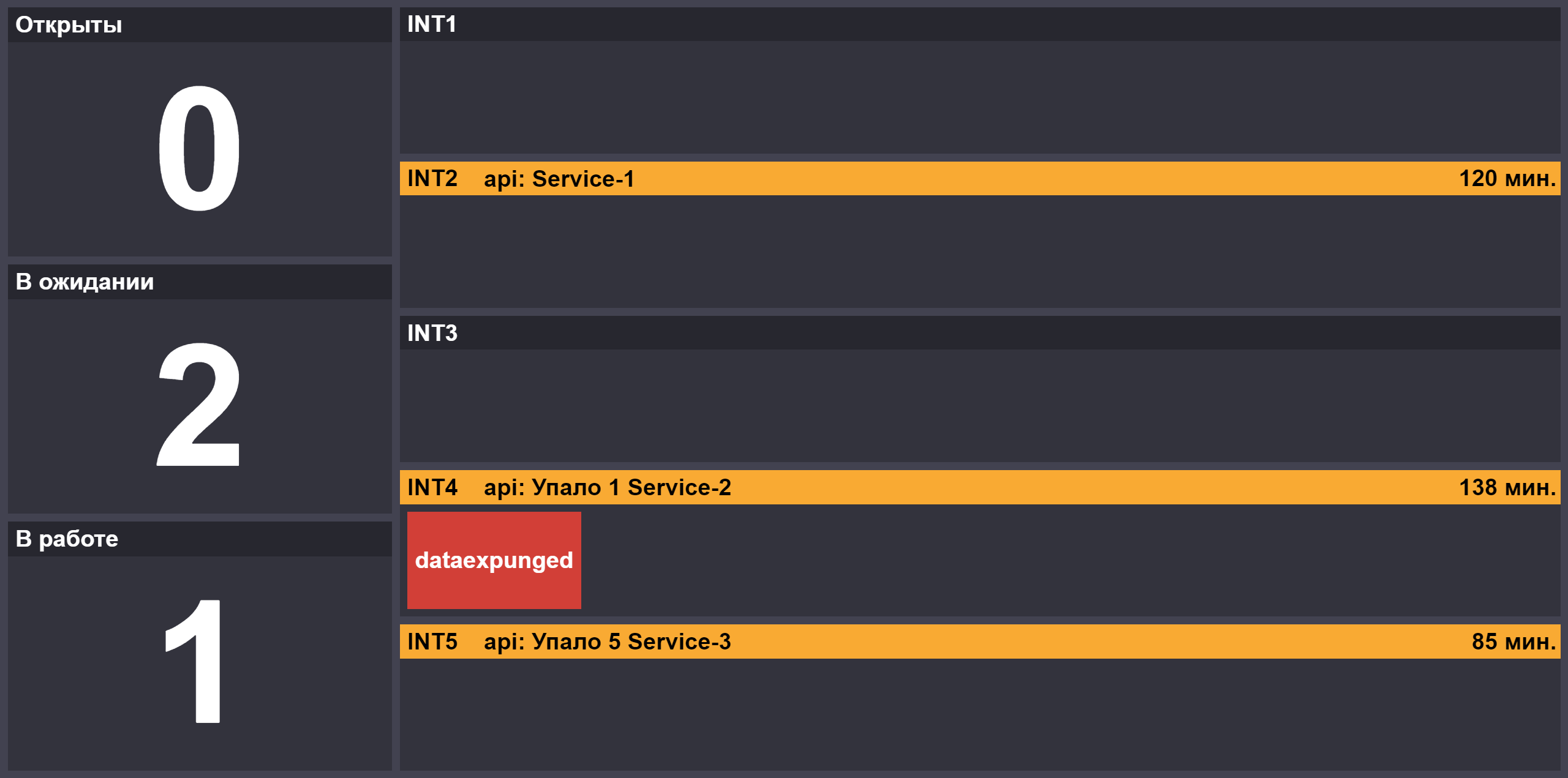
Le travail de l'officier de service nécessite de la concentration, il a donc un chignon - le jour de son devoir, il peut choisir un endroit pour déjeuner pour toute l'équipe près du bureau. Les pots-de-vin dans le style sont particulièrement amusants: "laissez-moi vous aider à trier les tâches, et aujourd'hui nous irons à
mon endroit préféré" =)
Journaliste
L'une des tâches que nous avons rencontrées lors de l'introduction de la montre était la nécessité de transférer les connaissances d'un officier à un autre, par exemple, sur les tests tombant sur une nouvelle version ou les spécificités de la mise à jour d'un composant.
De plus, nous avons de nouvelles fonctionnalités de travail.
- Il y avait une catégorie de tests qui tombaient avec une fréquence plus ou moins grande en raison de problèmes avec les bancs de test. Des chutes peuvent survenir en raison de l'augmentation du temps de réponse de l'un des services ou du long chargement des ressources dans le navigateur. Je ne veux pas désactiver les tests, les moyens raisonnables pour augmenter leur fiabilité ont été épuisés.
- Nous avons eu un deuxième projet expérimental avec autotests, et le besoin s'est fait sentir d'analyser les cycles de deux projets à la fois, en examinant les rapports Allure.
- Un test peut prendre jusqu'à 20 minutes et vous souhaitez commencer à analyser les résultats immédiatement après le début des premières gouttes. Surtout si la tâche est critique et que les membres de l'équipe responsable de la libération se tiennent derrière vous
, tenant le couteau à la gorge avec des yeux pitoyables.
C'est ainsi qu'est né le service Reporter. Nous y repoussons les résultats du test en temps réel pendant le processus de test. Le service dispose d'une base de données de problèmes ou bogues connus liés à un test spécifique. En outre, une publication a été publiée sur le portail wiki de la société d'un rapport de synthèse sur les résultats de la course du journaliste. Ceci est pratique pour les gestionnaires qui ne veulent pas plonger dans les détails techniques avec lesquels l'interface Reporter ou Allure regorge.
Si le test se bloque, vous pouvez rechercher dans le Reporter une liste de bogues associés ou corriger des tâches. Ces informations raccourcissent le temps d'analyse et facilitent l'échange de connaissances sur les problèmes entre les membres de notre équipe. Les enregistrements des tâches terminées sont archivés, mais si nécessaire, vous pouvez les «extraire» dans une liste distincte. Afin de ne pas charger les services internes pendant les heures ouvrables, nous interviewons Jira la nuit et archivons les entrées pour les problèmes avec le statut final.
Un avantage de l'introduction de Reporter était l'émergence d'une base de données d'exécution, sur la base de laquelle vous pouvez analyser la fréquence des chutes, classer les tests selon leur niveau de stabilité ou leur «utilité» en termes de nombre de bogues trouvés.
Autorun
Ensuite, nous sommes passés à l'automatisation du lancement des tests lorsque le problème des tests d'acceptation de la version arrive au traqueur de problèmes. À cet effet, le service Autorun a été écrit, qui vérifie s'il existe de nouvelles tâches d'acceptation dans Jira et, dans l'affirmative, il détermine le nom du composant et sa version en fonction du contenu de la tâche.
Pour la tâche, plusieurs étapes sont effectuées:
- prendre la serrure de l'un des bancs d'essai gratuits du service Locker,
- démarrer l'installation du composant nécessaire dans Jenkins, attendre que le composant soit monté avec la version requise,
- exécuter des tests
- attendre la fin du test, au cours de leur exécution, tous les résultats sont envoyés à Reporter,
- nous demandons à Reporter le nombre de tests qui ont échoué, à l'exclusion de ceux qui sont tombés en raison de problèmes connus,
- si 0 est tombé - nous transférons la tâche de test d'acceptation à «Terminer» et finissons de travailler avec. Tout est prêt =)
- s'il y a des tests "rouges" - nous traduisons la tâche en "En attente" et allons à Reporter pour les analyser.
La commutation entre les étapes est organisée par le principe d'une machine à états finis. Chaque étape elle-même connaît les conditions du passage à la suivante. Les résultats de l'étape sont stockés dans le contexte de la tâche, ce qui est courant pour les étapes d'une tâche.
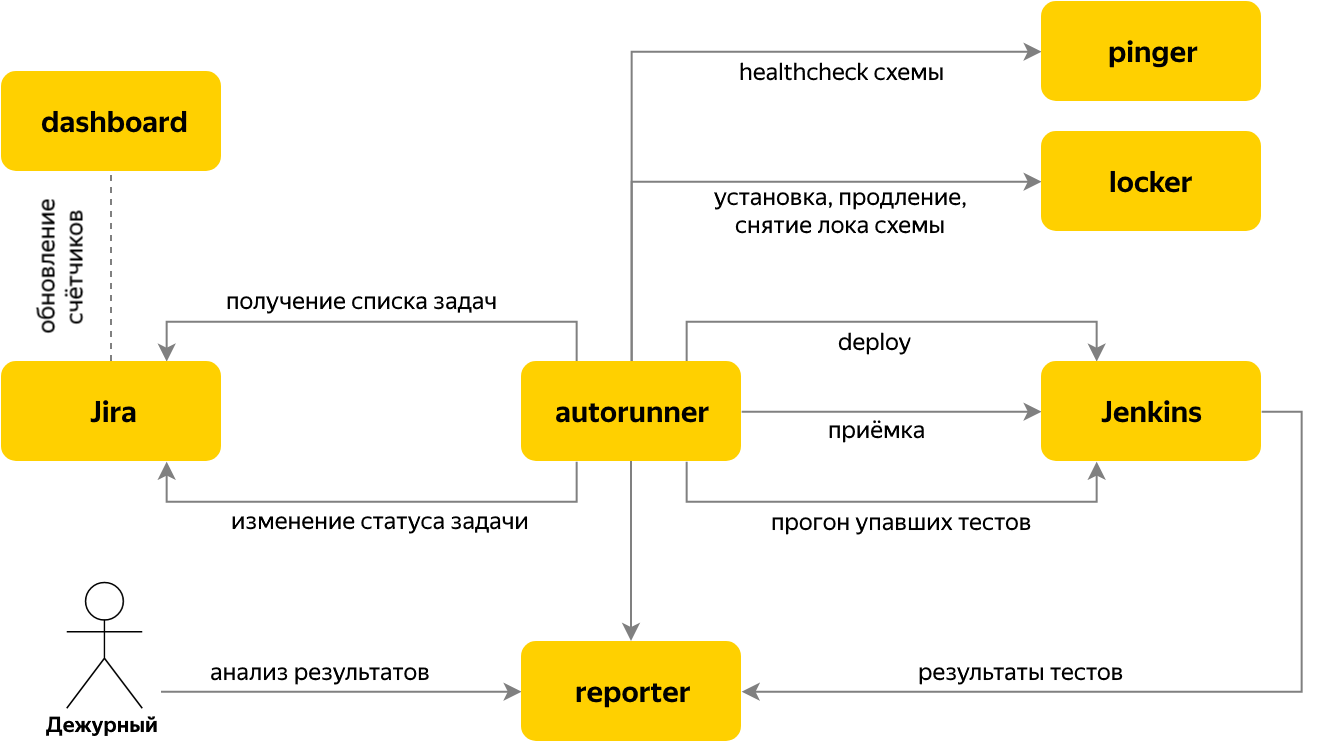
Tout cela vous permet de transférer automatiquement les versions le long du pipeline de déploiement, selon lesquelles 100% des tests sont verts. Mais qu'en est-il de l'instabilité causée non pas par des problèmes dans le composant, mais par les caractéristiques "naturelles" des tests d'interface utilisateur ou par l'augmentation des retards du réseau dans le banc de test?
Pour ce faire, nous avons mis en place un mécanisme de nouvelle tentative, que de nombreuses personnes utilisent, mais peu le reconnaissent. Les retrays sont organisés comme une série séquentielle de tests dans le pipeline Jenkins.
Après l'exécution, nous demandons une liste des tests ayant échoué à Reporter de Jenkins - et redémarrons uniquement ceux qui ont échoué. De plus, nous réduisons le nombre de threads au démarrage. Si le nombre de tests abandonnés n'a pas diminué par rapport à l'exécution précédente, nous mettons immédiatement fin à Job. Dans notre cas, cette approche de redémarrage nous permet d'augmenter le succès des tests d'acceptation d'environ 2 fois.
Blocage rapide
Le système de test d'acceptation qui en résulte nous a permis de réaliser plus de 60% des rejets sans intervention humaine. Mais que faire du reste? Si nécessaire, l'opératrice crée un rapport de bogue sur le composant sous test ou la tâche de fixer les tests à l'équipe de développement. Parfois - établit un bug de la configuration du banc de test pour le service d'exploitation.
Les tâches de correction des tests bloquent souvent le bon passage des tests automatiques, car les tests non pertinents seront toujours «rouges». Les testeurs des équipes de développement sont responsables de la rédaction de nouveaux tests et de la mise à jour des tests existants - en apportant des modifications par le biais de requêtes d'extraction au projet avec des tests automatiques. Ces modifications sont soumises à une révision obligatoire, ce qui nécessite un certain temps de la part du réviseur et de l'auteur, et je souhaite bloquer temporairement les tests non pertinents jusqu'à ce que la tâche soit traduite dans son état final.
Tout d'abord, nous avons implémenté un mécanisme d'arrêt basé sur les annotations des méthodes de test. Par la suite, il s'est avéré qu'en raison de la présence d'une révision obligatoire du code, le blocage du code n'est pas toujours pratique et peut prendre plus de temps que nous le souhaiterions.
Par conséquent, nous avons déplacé la liste des tâches bloquant les tests vers un nouveau service avec une page Web - Quick-block. Ainsi, les membres de l'équipe responsable du composant peuvent rapidement bloquer le test. Avant l'exécution, nous allons à ce service et obtenons une liste de tests en quarantaine, que nous traduisons en statut ignoré.
Résumé
Nous sommes passés de l'acceptation des versions en mode manuel à un processus presque entièrement automatique, capable de mener à bien des tests d'acceptation de plus de 50 versions par jour. Cela permet à l'entreprise de réduire le temps nécessaire pour publier des modifications, et notre équipe peut trouver des ressources pour expérimenter et développer des outils de test.
À l'avenir, nous prévoyons d'augmenter la fiabilité du processus, par exemple, en répartissant les demandes entre une paire d'instances de chaque service de la liste ci-dessus. Cela vous permettra de mettre à jour les outils sans temps d'arrêt et d'inclure de nouvelles fonctionnalités uniquement pour une partie des tests d'acceptation. De plus, nous veillons à stabiliser les tests eux-mêmes. En développement, un générateur de tickets pour refactoriser les tests avec le plus faible taux de réussite.
L'amélioration de la fiabilité des tests augmentera non seulement leur confiance, mais accélérera également les tests des versions en raison du manque de redémarrage des scripts tombés.