Bonjour à tous! Lundi prochain, les cours commenceront dans le nouveau groupe du
cours Python Developer , ce qui signifie que nous avons le temps de publier un autre matériel intéressant, ce que nous allons faire maintenant. Bonne lecture.

En 2003, Intel a sorti le nouveau processeur Pentium 4 «HT». Ce processeur overclocké à 3GHz et pris en charge la technologie d'hyper-threading.

Au cours des années suivantes, Intel et AMD ont eu du mal à obtenir les meilleures performances de bureau en augmentant la vitesse du bus, la taille du cache L2 et en réduisant la taille de la matrice pour minimiser la latence. En 2004, le modèle HT avec une fréquence de 3 GHz a été remplacé par le modèle 580 Prescott avec overclocking à 4 GHz.
Il semblait que pour aller de l'avant, il était juste nécessaire d'augmenter la fréquence d'horloge, cependant, les nouveaux processeurs souffraient d'une forte consommation d'énergie et d'une dissipation thermique.
Votre processeur de bureau délivre-t-il 4 GHz aujourd'hui? Il est peu probable, car le chemin vers l'amélioration des performances passe finalement par l'augmentation des vitesses de bus et l'augmentation du nombre de cœurs. En 2006, Intel Core 2 a remplacé le Pentium 4 et avait une vitesse d'horloge beaucoup plus faible.
Outre la sortie de processeurs multicœurs pour un large public d'utilisateurs, quelque chose d'autre s'est produit en 2006. Python 2.5 a enfin vu le jour! Il était déjà accompagné d'une version bêta du mot clé with, que vous connaissez et aimez tous.
Python 2.5 avait une limitation majeure lorsqu'il s'agissait d'utiliser Intel Core 2 ou AMD Athlon X2.
C'était un GIL.
Qu'est-ce qu'un GIL?
GIL (Global Interpreter Lock) est une valeur booléenne dans l'interpréteur Python protégé par un mutex. Le verrou est utilisé dans la boucle de calcul de bytecode CPython principal pour déterminer le thread qui exécute actuellement les instructions.
CPython prend en charge l'utilisation de plusieurs threads dans un seul interpréteur, mais les threads doivent demander l'accès au GIL afin d'effectuer des opérations de bas niveau. En retour, cela signifie que les développeurs Python peuvent utiliser du code asynchrone, du multithreading et ne plus avoir à se soucier de bloquer des variables ou des plantages au niveau du processeur pendant les blocages.
GIL simplifie la programmation Python multithread.

GIL nous dit également que bien que CPython puisse être multi-thread, un seul thread à la fois peut être exécuté. Cela signifie que votre processeur quad-core fait quelque chose comme ça (à l'exception de l'écran bleu, espérons-le).
La version actuelle de GIL a
été écrite en 2009 pour prendre en charge les fonctions asynchrones et est restée intacte même après de nombreuses tentatives de suppression de principe ou de modification des exigences.
Toute suggestion de suppression du GIL était justifiée par le fait que le verrouillage global de l'interpréteur ne devrait pas dégrader les performances du code à thread unique. Quiconque a tenté d'activer l'hyperthreading en 2003 comprendra de quoi
je parle .
Abandon de Gil dans CPython
Si vous voulez vraiment paralléliser le code dans CPython, vous devrez utiliser plusieurs processus.
Dans CPython 2.6, le module de
multitraitement a été ajouté à la bibliothèque standard. Le multiprocessing a masqué la génération de processus en CPython (chaque processus ayant son propre GIL).
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Les processus sont créés, les commandes leur sont envoyées à l'aide de modules compilés et de fonctions Python, puis ils sont rejoints au processus principal.
Le multitraitement prend également en charge l'utilisation de variables via une file d'attente ou un canal. Elle a un objet de verrouillage, qui est utilisé pour verrouiller des objets dans le processus principal et écrire à partir d'autres processus.
Le multitraitement présente un inconvénient majeur. Il supporte une charge de calcul importante, qui affecte à la fois le temps de traitement et l'utilisation de la mémoire. Le temps de démarrage de CPython même sans aucun site est de 100 à 200 ms (consultez
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b pour en savoir plus).
Par conséquent, vous pouvez avoir du code parallèle dans CPython, mais vous devez toujours planifier soigneusement le travail des processus de longue durée qui partagent plusieurs objets.
Une autre alternative peut être d'utiliser un package tiers tel que Twisted.
PEP554 et la mort de GIL?
Donc, permettez-moi de vous rappeler que le multithreading en CPython est simple, mais en réalité ce n'est pas de la parallélisation, mais le multitraitement est parallèle, mais implique une surcharge importante.
Et s'il y avait une meilleure façon?La clé pour contourner le GIL réside dans le nom, le verrouillage global de l'interpréteur fait partie de l'état global de l'interpréteur. Les processus CPython peuvent avoir plusieurs interprètes et, par conséquent, plusieurs verrous, cependant, cette fonction est rarement utilisée, car l'accès à celui-ci se fait uniquement via la C-API.
Une des fonctionnalités de CPython 3.8 est PEP554, une implémentation de sous-interprètes et d'API avec un nouveau module d'
interpreters dans la bibliothèque standard.
Cela vous permet de créer plusieurs interprètes à partir de Python en un seul processus. Une autre innovation de Python 3.8 est que tous les interprètes auront leur propre GIL.
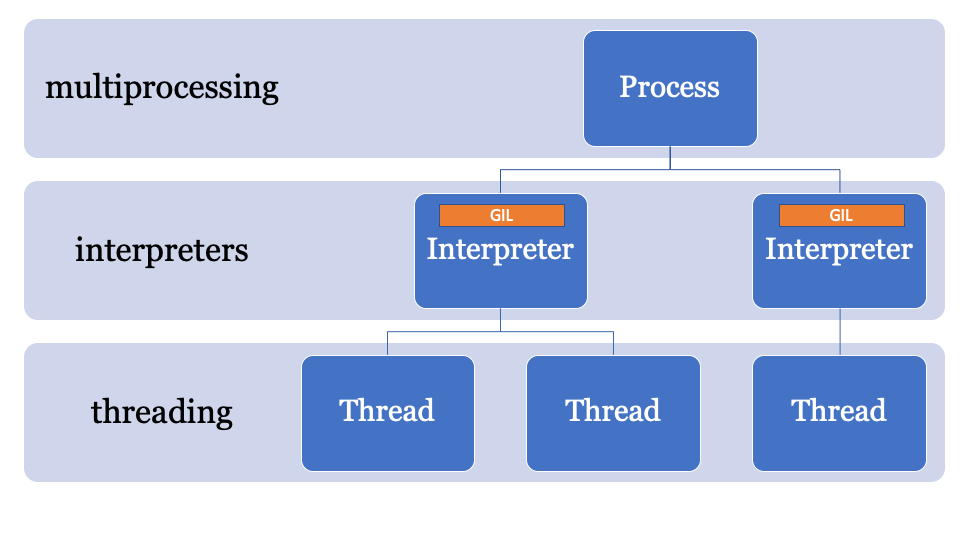
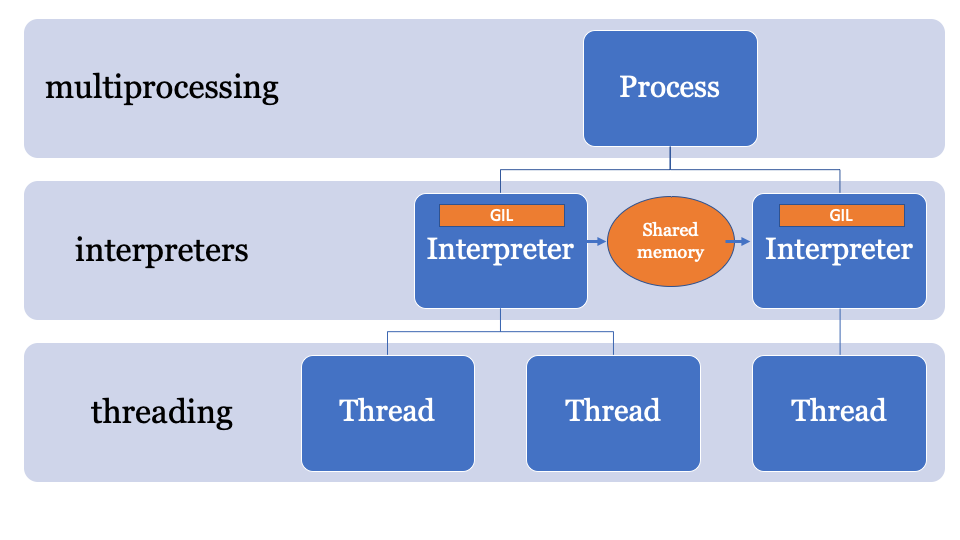
Étant donné que l'état de l'interpréteur contient une région allouée en mémoire, une collection de tous les pointeurs vers les objets Python (locaux et globaux), les sous-interprètes de PEP554 ne peuvent pas accéder aux variables globales des autres interprètes.
Comme le multiprocessing, les interprètes partageant des objets consistent à les sérialiser et à utiliser le formulaire IPC (réseau, disque ou mémoire partagée). Il existe de nombreuses façons de sérialiser des objets en Python, par exemple le module
marshal , le module
pickle ou des méthodes plus standardisées comme
json ou
simplexml . Chacun d'eux a ses avantages et ses inconvénients, et tous donnent une charge de calcul.
Il serait préférable d'avoir un espace mémoire commun qui peut être modifié et contrôlé par un processus spécifique. Ainsi, les objets peuvent être envoyés par l'interprète principal et reçus par un autre interprète. Ce sera l'espace mémoire géré pour la recherche de pointeurs PyObject, auquel chaque interprète peut accéder, tandis que le processus principal gère les verrous.
Une API pour cela est toujours en cours de développement, mais elle ressemblera probablement à ceci:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal
Cet exemple utilise NumPy. Le tableau numpy est envoyé sur le canal, il est sérialisé à l'aide du module
marshal , puis le sous-interprète traite les données (sur un GIL séparé), il peut donc y avoir un problème de parallélisation associé au CPU, ce qui est idéal pour les sous-interprètes.
Ça a l'air inefficace
Le module
marshal fonctionne très rapidement, mais pas aussi rapidement que le partage d'objets directement depuis la mémoire.
PEP574 introduit un nouveau protocole de
pickle (v5) qui prend en charge la possibilité de traiter les tampons de mémoire séparément du reste du flux de pickle. Pour les objets de données volumineux, la sérialisation de tous en une seule fois et la désérialisation à partir d'un sous-interpréteur ajoutera beaucoup de surcharge.
La nouvelle API peut être implémentée (purement hypothétiquement) comme suit -
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle
Il semble à motifs
Essentiellement, cet exemple est construit sur l'utilisation de l'API de sous-interprètes de bas niveau. Si vous n'avez pas utilisé la bibliothèque
multiprocessing , certains problèmes vous sembleront familiers. Ce n'est pas aussi simple que le traitement de flux, vous ne pouvez pas simplement, par exemple, exécuter cette fonction avec une telle liste de données d'entrée dans des interprètes séparés (pour l'instant).
Dès que ce PEP fusionnera avec d'autres, je pense que nous verrons plusieurs nouvelles API dans PyPi.
Combien de frais généraux le sous-interprète a-t-il?
Réponse courte: plus qu'un flux, moins qu'un processus.
Réponse longue: L' interpréteur a son propre état, il devra donc cloner et initialiser ce qui suit, malgré le fait que PEP554 simplifie la création de sous-interprètes:
- Modules dans l'
importlib __main__ et importlib ; - Le contenu du dictionnaire
sys ; - Fonctions intégrées (
print() , assert , etc.); - Streams;
- Configuration du noyau.
La configuration du noyau peut être facilement clonée depuis la mémoire, mais l'importation de modules n'est pas si simple. L'importation de modules en Python est lente, donc si la création d'un sous-interpréteur signifie l'importation de modules dans un espace de noms différent à chaque fois, les avantages sont réduits.
Et asyncio?
L'implémentation existante de la
asyncio événements
asyncio dans la bibliothèque standard crée des cadres de pile pour l'évaluation, et
asyncio également l'état dans l'interpréteur principal (et partage donc le GIL).
Après avoir combiné PEP554, probablement déjà en Python 3.9, une implémentation alternative de la boucle d'événements peut être utilisée (bien que personne ne l'ait encore fait), qui exécute des méthodes asynchrones dans des sous-interprètes en parallèle.
Ça a l'air cool, enveloppez-moi aussi!
Enfin, pas vraiment.
Étant donné que CPython fonctionne sur le même interpréteur depuis si longtemps, de nombreuses parties de la base de code utilisent «Runtime State» au lieu de «Interpreter State», donc si PEP554 était introduit maintenant, il y aurait encore beaucoup de problèmes.
Par exemple, l'état du garbage collector (dans les versions 3.7 <) appartient au runtime.
Lors des changements pendant les sprints PyCon, l'état du garbage collector a
commencé à se déplacer vers l'interpréteur, de sorte que chaque sous-interprète aurait son propre garbage collector (comme il se doit).
Un autre problème est qu'il y a des variables «globales» qui sont restées dans la base de code CPython avec de nombreuses extensions en C. Par conséquent, lorsque les gens ont soudainement commencé à paralléliser correctement leur code, nous avons vu des problèmes.
Un autre problème est que les descripteurs de fichiers appartiennent au processus, donc si vous avez un fichier ouvert pour l'écriture dans un interpréteur, le sous-interprète ne pourra pas accéder à ce fichier (sans autres modifications de CPython).
Bref, de nombreux problèmes doivent encore être résolus.
Conclusion: GIL est-il encore vrai?
GIL continuera d'être utilisé pour les applications monothread. Par conséquent, même lorsque vous suivez PEP554, votre code à thread unique ne deviendra soudainement pas parallèle.
Si vous voulez écrire du code parallèle en Python 3.8, vous aurez des problèmes de parallélisation associés au processeur, mais c'est aussi un billet pour le futur!
Quand?
Pickle v5 et le partage de mémoire pour le multitraitement seront très probablement en Python 3.8 (octobre 2019), et des sous-interprètes apparaîtront entre les versions 3.8 et 3.9.
Si vous souhaitez jouer avec les exemples présentés, j'ai créé une branche distincte avec tout le code nécessaire:
https://github.com/tonybaloney/cpython/tree/subinterpreters.Qu'en pensez-vous? Écrivez vos commentaires et rendez-vous sur le parcours.