Mon nom est Stas Kirillov, je suis un développeur leader dans le groupe de plates-formes ML de Yandex. Nous développons des outils d'apprentissage automatique, soutenons et développons une infrastructure pour eux. Vous trouverez ci-dessous mon récent exposé sur le fonctionnement de la bibliothèque CatBoost. Dans le rapport, j'ai parlé des points d'entrée et des fonctionnalités du code pour ceux qui veulent le comprendre ou devenir notre contributeur.
- CatBoost vit sur GitHub sous la licence Apache 2.0, c'est-à-dire qu'il est ouvert et gratuit pour tout le monde. Le projet se développe activement, maintenant notre référentiel compte plus de quatre mille étoiles. CatBoost est écrit en C ++, c'est une bibliothèque de boost de gradient sur les arbres de décision. Il prend en charge plusieurs types d'arbres, y compris les arbres dits "symétriques", qui sont utilisés par défaut dans la bibliothèque.
Quel est le profit de nos arbres inconscients? Ils apprennent rapidement, appliquent rapidement et aident à apprendre à être plus résistants aux changements de paramètres en termes de changements dans la qualité finale du modèle, ce qui réduit considérablement le besoin de sélection des paramètres. Notre bibliothèque vise à faciliter son utilisation en production, à apprendre rapidement et à obtenir une bonne qualité immédiatement.

L'amplification du gradient est un algorithme dans lequel nous construisons des prédicteurs simples qui améliorent notre fonction objectif. Autrement dit, au lieu de construire immédiatement un modèle complexe, nous construisons tour à tour de nombreux petits modèles.

Comment se déroule le processus d'apprentissage dans CatBoost? Je vais vous expliquer comment cela fonctionne en termes de code. Tout d'abord, nous analysons les paramètres de formation que l'utilisateur transmet, les validons, puis voyons si nous devons charger les données. Parce que les données peuvent déjà être chargées - par exemple, en Python ou R. Ensuite, nous chargeons les données et construisons une grille à partir des bordures afin de quantifier les caractéristiques numériques. Cela est nécessaire pour accélérer l'apprentissage.
Les fonctionnalités catégorielles que nous traitons un peu différemment. Nous catégorisons les entités au tout début, puis renumérotons les hachages de zéro au nombre de valeurs uniques de l'entité catégorielle afin de lire rapidement les combinaisons d'entités catégorielles.
Ensuite, nous lançons directement la boucle de formation - le cycle principal de notre apprentissage automatique, où nous construisons de manière itérative des arbres. Après ce cycle, le modèle est exporté.
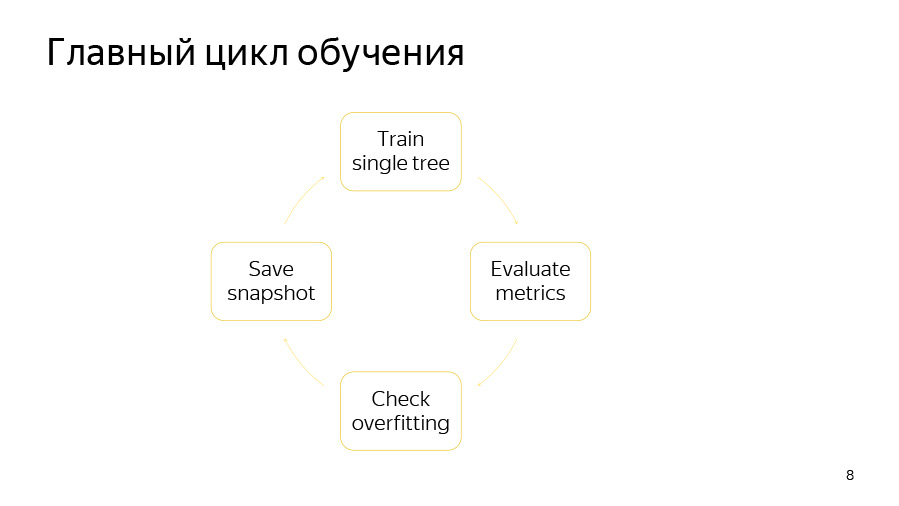
Le cycle de formation lui-même comprend quatre points. Premièrement, nous essayons de construire un arbre. Ensuite, nous examinons le type d'augmentation ou de diminution de la qualité qu'il donne. Ensuite, nous vérifions si notre détecteur de recyclage a fonctionné. Ensuite, nous, si le moment est venu, enregistrons l'instantané.

L'apprentissage d'un seul arbre est un cycle à travers les niveaux des arbres. Au tout début, nous sélectionnons au hasard une permutation de données si nous utilisons le boosting ordonné ou si nous avons des fonctionnalités catégorielles. Ensuite, nous comptons les compteurs sur cette permutation. Ensuite, nous essayons de choisir goulûment de bonnes divisions dans cet arbre. Par scissions, nous entendons simplement certaines conditions binaires: telle ou telle caractéristique numérique est supérieure à telle ou telle valeur, ou telle ou telle contre par caractéristique catégorielle est supérieure à telle ou telle valeur.
Comment est organisé le cycle de niveau d'arbre gourmand? Au tout début, le bootstrap est fait - nous pesons à nouveau ou échantillonnons les objets, après quoi seuls les objets sélectionnés seront utilisés pour construire l'arborescence. Le bootstrap peut également être recompté avant de sélectionner chaque division si l'option d'échantillonnage à chaque niveau est activée.
Ensuite, nous agrégons les dérivées en histogrammes, comme nous le faisons pour chaque candidat divisé. À l'aide d'histogrammes, nous essayons d'évaluer le changement dans la fonction objectif qui se produira si nous sélectionnons ce candidat divisé.
Nous sélectionnons le candidat avec la meilleure vitesse et l'ajoutons à l'arbre. Ensuite, nous calculons des statistiques en utilisant cet arbre sélectionné sur les permutations restantes, mettons à jour la valeur dans les feuilles à ces permutations, calculons les valeurs dans les feuilles pour le modèle et procédons à l'itération suivante de la boucle.

Il est très difficile de distinguer un endroit où la formation a lieu, donc sur cette diapositive - vous pouvez l'utiliser comme point d'entrée - les principaux fichiers que nous utilisons pour la formation sont répertoriés. C'est greedy_tensor_search, dans lequel nous vivons la procédure même de sélection gourmande des splits. C'est train.cpp, où nous avons la principale usine de formation CPU. C'est aprox_calcer, où se trouvent les fonctions de mise à jour des valeurs dans les feuilles. Et aussi score_calcer - une fonction pour évaluer un candidat.
Les parties tout aussi importantes sont catboost.pyx et core.py. Ceci est le code de l'encapsuleur python, très probablement beaucoup d'entre vous incorporeront une sorte de substance dans l'encapsuleur python. Notre wrapper python est écrit en Cython, Cython est traduit en C ++, donc ce code devrait être rapide.
Notre R-wrapper se trouve dans le dossier R-package. Peut-être que quelqu'un devra ajouter ou corriger certaines options, pour les options, nous avons une bibliothèque distincte - catboost / libs / options.
Nous sommes venus d'Arcadia à GitHub, nous avons donc de nombreux artefacts intéressants que vous rencontrerez.


Commençons par la structure du référentiel. Nous avons un dossier util où les primitives de base sont: les vecteurs, les cartes, les systèmes de fichiers, le travail avec les chaînes, les flux.
Nous avons une bibliothèque où se trouvent les bibliothèques partagées utilisées par Yandex - beaucoup, pas seulement CatBoost.
Le dossier CatBoost et contrib est le code des bibliothèques tierces auxquelles nous lions.
Parlons maintenant des primitives C ++ que vous rencontrerez. Le premier est les pointeurs intelligents. Dans Yandex, nous utilisons THolder depuis std :: unique_ptr, et MakeHolder est utilisé à la place de std :: make_unique.

Nous avons notre propre SharedPtr. De plus, il existe sous deux formes, SimpleSharedPtr et AtomicSharedPtr, qui diffèrent par le type de compteur. Dans un cas, il est atomique, ce qui signifie que comme si plusieurs flux pouvaient posséder un objet. Il sera donc à l'abri du point de vue du transfert entre flux.
Une classe distincte, IntrusivePtr, vous permet de posséder des objets hérités de la classe TRefCounted, c'est-à-dire des classes qui ont un compteur de référence intégré. Il s'agit d'allouer de tels objets à la fois, sans allouer en plus un bloc de contrôle avec un compteur.
Nous avons également notre propre système d'entrée et de sortie. IInputStream et IOutputStream sont des interfaces d'entrée et de sortie. Ils ont des méthodes utiles, telles que ReadTo, ReadLine, ReadAll, en général, tout ce qui peut être attendu de InputStreams. Et nous avons des implémentations de ces flux pour travailler avec la console: Cin, Cout, Cerr et séparément Endl, qui est similaire à std :: endl, c'est-à-dire qu'il vide le flux.

Nous avons également nos propres implémentations d'interface pour les fichiers: TInputFile, TOutputFile. Il s'agit d'une lecture en mémoire tampon. Ils implémentent la lecture et l'écriture tamponnées dans un fichier, vous pouvez donc les utiliser.
Util / system / fs.h a des méthodes NFs :: Exists et NFs :: Copy, si vous devez soudainement copier quelque chose ou vérifier qu'un fichier existe vraiment.

Nous avons nos propres conteneurs. Ils sont passés à l'utilisation de std :: vector il y a longtemps, c'est-à-dire qu'ils héritent simplement de std :: vector, std :: set et std :: map, mais nous avons également nos propres THashMap et THashSet, qui ont en partie des interfaces compatibles avec unordered_map et unordered_set. Mais pour certaines tâches, ils se sont avérés plus rapides, nous les utilisons donc toujours.

Les références de tableau sont analogues à std :: span de C ++. Certes, il n'est pas apparu avec nous la vingtième année, mais bien plus tôt. Nous l'utilisons activement pour transférer des références à des tableaux, comme s'ils étaient alloués sur de grands tampons, afin de ne pas allouer de tampons temporaires à chaque fois. Supposons que, pour compter les dérivées ou certaines approximations, nous pouvons allouer de la mémoire sur un grand tampon pré-alloué et passer uniquement TArrayRef à la fonction de comptage. C'est très pratique et nous l'utilisons beaucoup.

Arcadia utilise son propre ensemble de classes pour travailler avec des chaînes. Il s'agit, tout d'abord, de TStingBuf - un analogue de str :: string_view de C ++ 17.
TString n'est pas du tout std :: sting, c'est une chaîne CopyOnWrite, vous devez donc travailler avec précaution. De plus, TUtf16String est le même TString, seul son type de base n'est pas char, mais wchar 16 bits.
Et nous avons des outils pour convertir de chaîne en chaîne. Il s'agit de ToString, qui est un analogue de std :: to_string et FromString associé à TryFromString, qui vous permet de transformer la chaîne en le type dont vous avez besoin.

Nous avons notre propre structure d'exception, l'exception de base dans les bibliothèques d'arcade est yexception, qui hérite de std :: exception. Nous avons une macro ythrow qui ajoute des informations sur l'endroit où l'exception a été levée à yexception, c'est juste un wrapper pratique.
Il existe un analogue de std :: current_exception - CurrentExceptionMessage, cette fonction lève l'exception actuelle sous forme de chaîne.
Il existe des macros pour les assertions et les vérifications - ce sont Y_ASSERT et Y_VERIFY.

Et nous avons notre propre sérialisation intégrée, elle est binaire et n'est pas destinée à transférer des données entre différentes révisions. Au contraire, cette sérialisation est nécessaire pour transférer des données entre deux binaires de la même révision, par exemple, dans l'apprentissage distribué.
Il se trouve que nous avons deux versions de sérialisation dans CatBoost. La première option fonctionne via les méthodes d'interface Enregistrer et Charger, qui sérialisent vers le flux. Une autre option est utilisée dans notre formation distribuée, elle utilise une bibliothèque BinSaver interne assez ancienne, pratique pour sérialiser des objets polymorphes qui doivent être enregistrés dans une usine spéciale. Cela est nécessaire pour la formation distribuée, dont nous n'aurons probablement pas le temps de parler ici.

Nous avons également notre propre boost_optional analogique ou std :: optional - TMaybe. Analogue de std :: variant - TVariant. Vous devez les utiliser.

Il existe une certaine convention selon laquelle, dans le code CatBoost, nous lançons une TCatBoostException au lieu d'une yexception. Il s'agit de la même exception, seule la trace de pile est toujours ajoutée lorsqu'elle est levée.
Et nous utilisons également la macro CB_ENSURE pour vérifier facilement certaines choses et lever des exceptions si elles ne sont pas exécutées. Par exemple, nous l'utilisons souvent pour analyser les options ou analyser les paramètres transmis par l'utilisateur.

Liens depuis la diapositive: premier , deuxième
Assurez-vous de vérifier le style de code avant de commencer le travail, il se compose de deux parties. Le premier est un style de code général, qui se trouve directement à la racine du référentiel dans le fichier CPP_STYLE_GUIDE.md. À la racine du référentiel se trouve également un guide séparé pour notre équipe: catboost_command_style_guide_extension.md.
Nous essayons de formater le code Python en utilisant PEP8. Cela ne fonctionne pas toujours, car pour le code Cython, le linter ne fonctionne pas pour nous, et parfois quelque chose se passe avec PEP8.

Quelles sont les caractéristiques de notre montage? L'assemblage Arcadia visait à l'origine à collecter les applications les plus étanches, c'est-à-dire qu'il y aurait un minimum de dépendances externes en raison de la liaison statique. Cela vous permet d'utiliser le même binaire sur différentes versions de Linux sans recompiler, ce qui est assez pratique. Les objectifs de l'assemblage sont décrits dans les fichiers ya.make. Un exemple de ya.make peut être vu sur la diapositive suivante.

Si vous souhaitez soudainement ajouter une sorte de bibliothèque, un programme ou autre chose, vous pouvez, premièrement, simplement regarder dans les fichiers ya.make voisins, et deuxièmement, utiliser cet exemple. Ici, nous avons répertorié les éléments les plus importants de ya.make. Au tout début du fichier, nous disons que nous voulons déclarer une bibliothèque, puis nous listons les unités de compilation que nous voulons mettre dans cette bibliothèque. Il peut s'agir à la fois de fichiers cpp et, par exemple, de fichiers pyx pour lesquels Cython démarre automatiquement, puis du compilateur. Les dépendances de bibliothèque sont répertoriées via la macro PEERDIR. Il écrit simplement les chemins d'accès au dossier avec la bibliothèque ou avec un autre artefact à l'intérieur, par rapport à la racine du référentiel.
Il y a une chose utile, GENERATE_ENUM_SERIALIZATION, nécessaire pour générer des méthodes ToString, FromString pour les classes d'énumération et les énumérations décrites dans un fichier d'en-tête que vous transmettez à cette macro.

Maintenant sur la chose la plus importante - comment compiler et exécuter une sorte de test. À la racine du référentiel se trouve le script ya, qui télécharge les kits et outils nécessaires, et il a la commande ya make - la sous-commande make - qui vous permet de créer une version -r avec le commutateur -r et une version de débogage avec la clé -d. Les artefacts qui s'y trouvent sont transmis et séparés par un espace.
Pour construire Python, j'ai immédiatement signalé ici des drapeaux qui pourraient être utiles. Nous parlons de construire avec le système Python, dans ce cas avec Python 3. Si vous avez soudainement un CUDA Toolkit installé sur votre ordinateur portable ou votre machine de développement, alors pour un assemblage plus rapide, nous vous recommandons de spécifier –d have_cuda no flag. CUDA s'appuie depuis un certain temps, en particulier sur les systèmes à 4 cœurs.

Ya ide devrait déjà fonctionner. Il s'agit d'un outil qui va générer une solution clion ou qt pour vous. Et pour ceux qui sont venus avec Windows, nous avons une solution Microsoft Visual Studio, qui se trouve dans le dossier msvs.
Auditeur:
- Avez-vous tous les tests via le wrapper Python?
Stas:
- Non, nous avons séparément des tests qui se trouvent dans le dossier pytest. Ce sont des tests de notre interface CLI, c'est-à-dire de notre application. Certes, ils fonctionnent via pytest, c'est-à-dire que ce sont des fonctions Python dans lesquelles nous faisons un appel de vérification de sous-processus et vérifions que le programme ne plante pas et fonctionne correctement avec certains paramètres.
Auditeur:
- Et les tests unitaires en C ++?
Stas:
- Nous avons également des tests unitaires en C ++. Ils se trouvent généralement dans le dossier lib des sous-dossiers ut. Et ils sont écrits comme ça - test unitaire ou test unitaire pour. Il y a des exemples. Il existe des macros spéciales pour déclarer une classe de test unitaire et des registres séparés pour la fonction de test unitaire.
Auditeur:
- Pour vérifier que rien ne s'est cassé, vaut-il mieux lancer ceux-ci et ceux-là?
Stas:
- Oui. La seule chose est que nos tests open source ne sont verts que sous Linux. Par conséquent, si vous compilez, par exemple, sous Mac, si cinq tests échouent, il n'y a rien à craindre. En raison de l'implémentation différente de l'exposant sur différentes plateformes ou de quelques autres différences mineures, les résultats peuvent être très différents.

Pour un exemple, nous prendrons une tâche. Je voudrais montrer un exemple. Nous avons un fichier avec des tâches - open_problems.md. Résolvons le problème №4 de open_problems.md. Il est formulé comme suit: si l'utilisateur définit le taux d'apprentissage à zéro, alors nous devons tomber de TCatBoostException. Vous devez ajouter la validation des options.
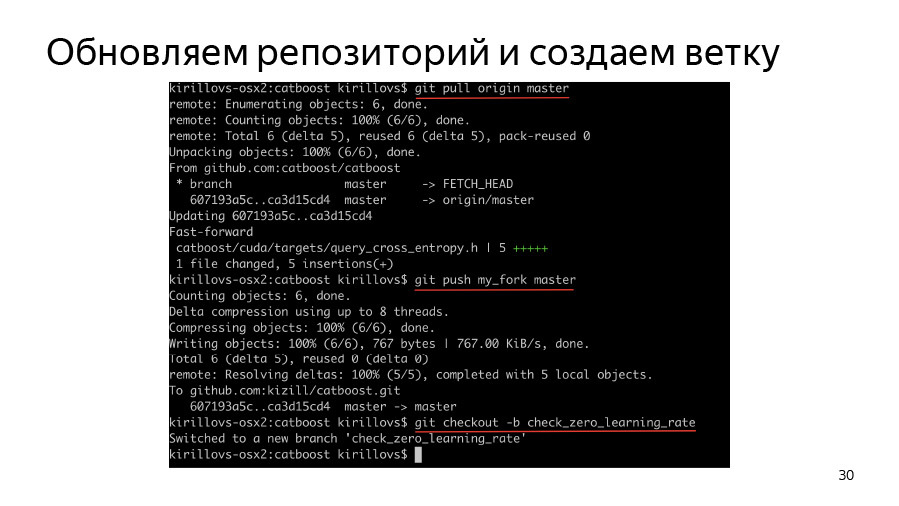
Tout d'abord, nous devons créer une branche, cloner notre fork, cloner l'origine, l'origine pop, exécuter l'origine dans notre fork, puis créer une branche et commencer à y travailler.
Comment fonctionne l'analyse des options? Comme je l'ai dit, nous avons un important dossier catboost / libs / options où l'analyse de toutes les options est stockée.

Nous avons toutes les options stockées dans le wrapper TOption, ce qui nous permet de comprendre si l'option a été remplacée par l'utilisateur. Si ce n'est pas le cas, il conserve une valeur par défaut en soi. En général, CatBoost analyse toutes les options sous la forme d'un grand dictionnaire JSON, qui pendant l'analyse se transforme en dictionnaires et structures imbriqués.

Nous avons en quelque sorte découvert - par exemple, en recherchant avec un grep ou en lisant le code - que nous avons le taux d'apprentissage dans TBoostingOptions. Essayons d'écrire du code qui ajoute simplement CB_ENSURE, que notre taux d'apprentissage est supérieur à std :: numeric_limits :: epsilon, que l'utilisateur a entré quelque chose de plus ou moins raisonnable.

Ici, nous venons d'utiliser la macro CB_ENSURE, écrit du code et maintenant nous voulons ajouter des tests.

Dans ce cas, nous ajoutons un test sur l'interface de ligne de commande. Dans le dossier pytest, nous avons le script test.py, où il y a déjà pas mal d'exemples de tests et vous pouvez simplement en choisir un qui ressemble à votre tâche, le copier et changer les paramètres pour qu'il commence à tomber ou à ne pas tomber, selon les paramètres que vous avez passés. Dans ce cas, nous prenons et créons simplement un pool simple de deux lignes. (Nous appelons les pools d'ensembles de données dans Yandex. C'est notre particularité.) Et puis nous vérifions que notre binaire chute vraiment si nous passons le taux d'apprentissage 0.0.

Nous ajoutons également un test à python-package, qui se trouve dans atBoost / python-package / ut / medium. Nous avons également de très gros tests qui sont liés aux tests de construction de packages de roues python.

De plus, nous avons des clés pour vous faire - -t et -A. -t exécute les tests, -A force tous les tests à s'exécuter, qu'ils aient des balises grandes ou moyennes.
Ici, pour la beauté, j'ai également utilisé un filtre nommé test. Il est défini à l'aide de l'option -F et du nom de test spécifié plus tard, qui peuvent être des étoiles de caractère sauvage. Dans ce cas, j'ai utilisé test.py::test_zero_learning_rate*, car, en regardant nos tests de paquetages python, vous verrez: presque toutes les fonctions prennent en charge un type de tâche. C'est ainsi que, selon le code, nos tests de package python sont identiques pour l'apprentissage du CPU et du GPU et peuvent être utilisés pour les tests de formateur de GPU et de CPU.

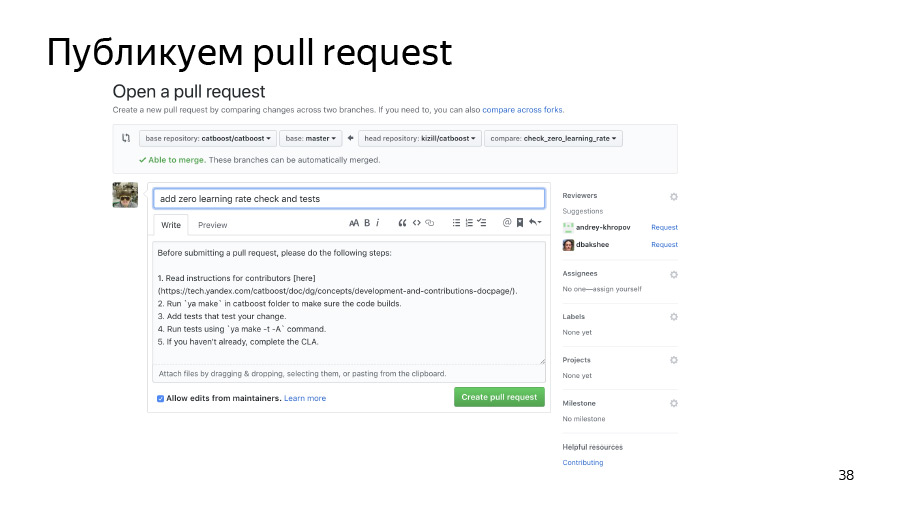
Validez ensuite nos modifications et transférez-les dans notre référentiel forké. Nous publions la demande de pool. Il a déjà rejoint, tout va bien.