Pendant la session de formation (mai-juin et décembre-janvier), les utilisateurs nous demandent de vérifier les emprunts de 500 documents par minute. Les documents sont présentés dans des fichiers de différents formats, la complexité de travailler avec chacun d'eux étant différente. Pour vérifier l'emprunt d'un document, nous devons d'abord extraire son texte du fichier, et en même temps gérer le formatage. La tâche consiste à mettre en œuvre une extraction de haute qualité d'un demi-millier de textes avec une mise en forme par minute, tout en tombant rarement (ou mieux ne tombant pas du tout), consommant peu de ressources et ne payant pas la moitié du budget galactique pour le développement et le fonctionnement de l'idée finale.
Oui, oui, bien sûr, nous savons que sur trois choses - rapidement, à moindre coût et efficacement - vous devez en choisir deux. Mais le plus méchant, c'est que dans notre cas, nous ne pouvons rien supprimer. La question est de savoir dans quelle mesure nous l'avons fait ...

Source de l'image: Wikipedia
On nous dit souvent que le sort des gens dépend de la qualité de notre travail. Par conséquent, vous devez éduquer en vous les perfectionnistes. Bien sûr, nous améliorons constamment la qualité du système (dans tous les aspects), car les auteurs sans scrupules trouvent de nouvelles façons de contourner le problème. Et j'espère que le jour est proche où la complexité de la tromperie, d'une part, et le sentiment de satisfaction d'un travail bien fait, d'autre part, inciteront la grande majorité des étudiants à abandonner leur désir bien-aimé de s'amuser. Dans le même temps, nous comprenons que le prix de l'erreur peut être la souffrance possible de personnes innocentes si nous la simulons soudainement.
Pourquoi suis-je? Si nous étions perfectionnistes, nous aborderions avec attention la rédaction d'une série d'articles sur le travail du système anti-plagiat . Nous élaborerions minutieusement un plan de publication pour énoncer tout de la manière la plus logique et attendue pour le lecteur:
- Tout d'abord, nous parlerions de la structure de notre système (la cinquième publication sur Habré) et décririons les trois étapes principales du traitement d'un document lorsqu'il est vérifié pour l'emprunt:
- Extraire le texte du document (vous êtes ici!);
- Recherche de prêts (des pièces sont déjà dans plusieurs de nos articles );
- Construire un rapport sur le document (en plans).
- En outre, nous commencerions à consacrer le lecteur au dispositif de mécanismes auxiliaires intéressants, tels que la recherche d'emprunts transférables ( premier article ), la définition de la paraphrase ( quatrième ) et la classification thématique ( deuxième ).
- Et enfin, nous sommes arrivés au moteur de recherche - l'indice des bardeaux ( septième article ).
Un lecteur attentif doit avoir remarqué que nous ne souffrons toujours pas d'un perfectionnisme excessif, il est donc temps de passer à la première étape - extraire du texte et formater des documents. C'est ce que nous ferons aujourd'hui, en réfléchissant à la mortalité de l'être et à la lumière au bout du tunnel, à la non-existence de quelque chose d'idéal et à la poursuite de l'excellence, à avoir un plan et à le suivre et aux compromis que la vie nous incline toujours.
Au début était le mot
Dans un premier temps, nous n'avons extrait des documents que les éléments les plus nécessaires à leur vérification d'emprunt - le texte des documents eux-mêmes. Les principaux formats ont été pris en charge - docx, doc, txt, pdf, rtf, html. Ensuite, les ppt, pptx, odt, epub, fb2, djvu les moins courants ont été ajoutés, mais il était nécessaire de refuser de travailler avec la plupart d'entre eux à l'avenir . Chacun d'eux a été traité à sa manière - quelque part dans une bibliothèque séparée, quelque part dans son propre analyseur. En moyenne, l'extraction de texte a duré environ des centaines de millisecondes. Il semblerait que la principale et presque la seule difficulté à extraire du texte soit l '«analyse» du format lui-même, ce qui est particulièrement vrai pour les formats binaires pdf et doc (et la nature exclusive de ce dernier rend son utilisation encore plus problématique). Cependant, déjà à ce stade, lorsque nos désirs se limitaient à l'extraction du texte, il devenait clair que toute façon de lire les formats dont nous avions besoin comportait un certain nombre de caractéristiques désagréables. Les plus importants d'entre eux:
- Les exceptions sont même lors du traitement de certains documents valides, sans parler du traitement de documents «cassés» mal formés. Ce qui crée encore plus de problèmes, c'est que le code natif peut tomber et gérer de telles situations dans le code .net est difficile;
- Consommation de mémoire insuffisamment élevée, ce qui peut nuire à la fois aux processus voisins et à l'actuel traitant le document «problème» (mémoire insuffisante dans le code managé ou non managé);
- Traitement trop long du document, qui est exacerbé par le manque de mécanismes d'annulation pour la plupart des bibliothèques, et parfois par la complexité (lire: presque impossible) d'annuler un appel de code non géré à partir d'un appel géré;
- "Extraction de texte à partir de documents." Générer le texte d'un document pdf (et ce format est la clé pour nous), dont l'analyse a déjà été effectuée, contrairement aux attentes, est une tâche non triviale. Le fait est que le format pdf a été initialement développé principalement pour la présentation électronique des supports d'impression. Le texte dans les fichiers PDF est un ensemble de blocs de texte situés sur les pages d'un document. De plus, le bloc peut être un paragraphe de texte ou un seul caractère. La tâche de restaurer le texte dans sa forme originale à partir de cet ensemble de blocs incombe à la bibliothèque (code / programme) qui lit le document. Oui, le format, à partir d'une certaine version de celui-ci, permet de spécifier l'ordre des blocs, mais, malheureusement, les documents avec une séquence marquée de blocs de texte sont rares. Par conséquent, les bibliothèques de lecture de texte pdf contiennent un certain nombre d'heuristiques (enfin, c'est standard ici: apprentissage automatique,
bigdata, blockchain , ...) qui vous permettent de restaurer le texte sous la forme correcte avec un degré ou un autre, et, comme prévu, le résultat obtenu diffère d'une bibliothèque à l'autre. .

Source de l'image du bas: article
Source de l'image supérieure: Hmm ...
Besoin de plus de données!
Si, pour analyser un document à emprunter, l'arrière-plan textuel du document nous a suffi, la mise en œuvre d'un certain nombre de nouvelles fonctionnalités est impossible ou très difficile sans extraire des données supplémentaires du document. Aujourd'hui, en plus de l'arrière-plan du texte, nous extrayons également la mise en forme des documents et le rendu des images de page. Nous utilisons ce dernier pour la reconnaissance optique de texte ( OCR ), ainsi que pour identifier certains types de contournements.
Le formatage d'un document comprend la disposition géométrique de tous les mots et caractères des pages, ainsi que la taille de police de tous les caractères. Ces informations nous permettent de:
- Affichez magnifiquement le rapport de vérification du document, en dessinant les emprunts détectés directement sur le document d'origine;

- Déterminer avec plus de précision les blocs de documents (page de titre, bibliographie ) et récupérer ses métadonnées (auteurs, titre du poste, année et lieu de travail, etc.);
- Détectez les tentatives de contournement du système.
Pour unifier le traitement des documents et un ensemble de données extraites, nous convertissons les documents de tous les formats pris en charge par nous en pdf. Ainsi, la procédure d'extraction des données du document se déroule en deux étapes:
- Convertissez un document en pdf;
- Extraire les données du pdf.
Convertissez en pdf. Sélection de la bibliothèque
Puisqu'il n'est pas si facile de prendre et de convertir un document en pdf, nous avons décidé de ne pas réinventer la roue et d'explorer des solutions toutes faites, en choisissant la plus appropriée pour nous. C'était en 2017.
Critères de sélection des candidats:
- Bibliothèque sur .net, idéalement .net core et multiplateforme
Spoiler!En conséquence, à ce moment-là, l'idéal était inaccessible
- Prise en charge des formats requis - doc, docx, rtf, odf, ppt, pptx
- La stabilité
- Performances
- Qualité du support technique
- Prix d'émission
Nous avons analysé les solutions disponibles, en sélectionnant parmi elles les 6 plus adaptées à nos missions:
MS Word Interop, Neevia Document Converter Pro et DynamicPdf nécessitent l'installation de MS Office en production, ce qui pourrait enfin et irrévocablement nous lier à Windows. Par conséquent, nous n'avons plus envisagé ces options.
Ainsi, il nous reste trois candidats principaux, et un seul d'entre eux prend entièrement en charge tous les formats dont nous avons besoin. Eh bien, il est temps de voir de quoi ils sont capables.
Pour tester les bibliothèques, nous avons formé un échantillon de 120 000 documents utilisateurs réels, le ratio des formats dans lequel correspond approximativement ce que nous voyons chaque jour en production.
Donc, le premier tour. Voyons quelle proportion de documents peut être convertie avec succès en bibliothèques pdf à l'étude. Avec succès, dans notre cas, il ne s'agit pas de lever une exception, de respecter le délai d'expiration de 3 minutes et de renvoyer un texte non vide.
Syncfusion s'est immédiatement démarqué, qui a non seulement réussi à traiter le plus petit nombre de documents, mais a également vidé l'ensemble du processus sur certains documents (en générant des exceptions telles que OutOfMemoryException ou des exceptions du code natif qui n'ont pas été détectées sans danser avec un tambourin).
GroupDocs n'a pas réussi à traiter environ 5,5 fois plus de documents que DevExpress (tout peut être vu sur la plaque ci-dessus). Ceci malgré le fait qu'une licence de développeur unique de GroupDocs coûte environ 9 fois plus cher qu'une licence de développeur unique de DevExpress. Il en est ainsi d'ailleurs.
Le deuxième test sérieux est le temps de conversion, les mêmes 120 000 documents:
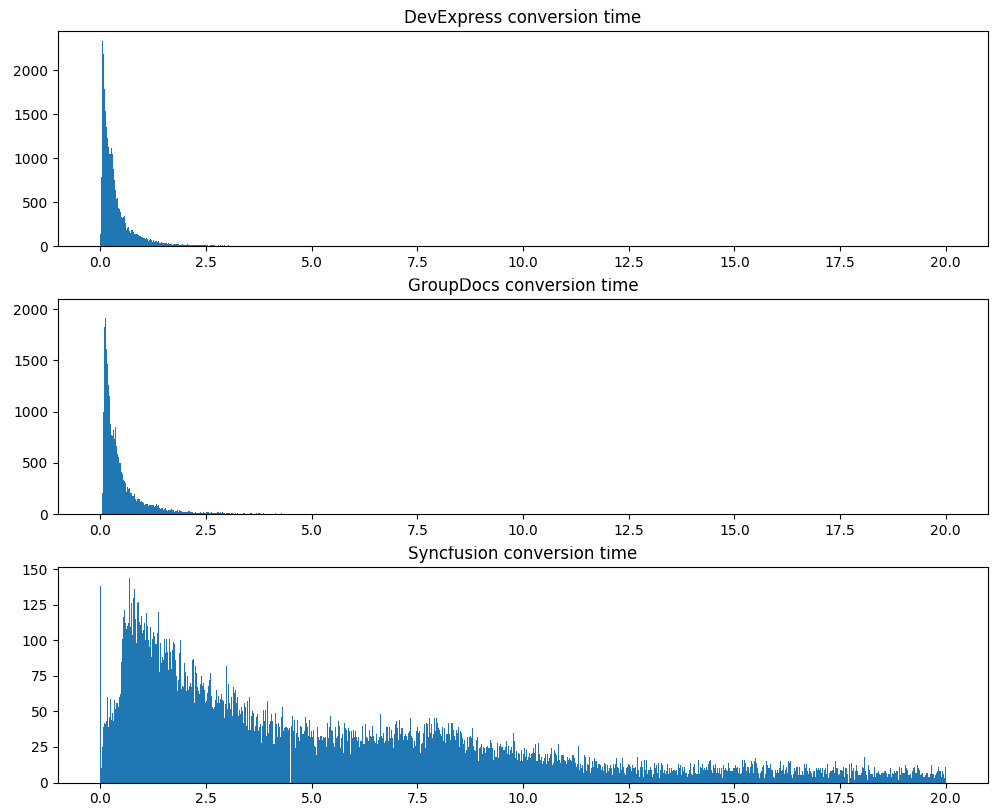
Notez que DevExpress non seulement traite les documents plus rapidement en moyenne, mais affiche également un temps de traitement beaucoup plus stable.
Mais la stabilité et la vitesse de traitement ne signifient rien si la sortie est mauvaise pdf. Peut-être que DevExpress saute la moitié du texte? Nous vérifions. Ainsi, les mêmes 120 000 documents, cette fois-ci, nous calculerons le volume total du texte extrait et la part moyenne des mots du dictionnaire (plus les mots extraits sont dictionnaire, moins les déchets / texte extrait incorrectement):
En partie, l'hypothèse était correcte. Il s'est avéré que GroupDocs, contrairement à DevExpress, peut fonctionner avec des notes de bas de page. DevExpress les ignore simplement lors de la conversion d'un document en pdf. Par ailleurs, oui, le texte du pdf'ok reçu est extrait dans tous les cas à l'aide de DevExpress'a.
Ainsi, nous avons étudié la vitesse et la stabilité des bibliothèques en question, maintenant nous évaluons soigneusement la qualité de la conversion des documents pdf. Pour ce faire, nous analyserons non seulement le volume du texte à extraire et la proportion de mots du dictionnaire, mais nous comparerons les textes extraits des pdfs reçus avec les textes pdf obtenus à l'aide de MS Word. Nous acceptons le résultat de la conversion d'un document en utilisant MS Word comme pdf de référence . Environ 4 500 paires de « document, référence pdf'ka » ont été préparées pour ce test.
Pour chaque paire « pdf de référence, résultat de conversion », nous avons calculé la similitude dans la longueur du texte extrait et dans les fréquences des mots extraits. Naturellement, ces mesures n'ont été obtenues que dans les cas où la conversion a réussi. Par conséquent, nous ne considérons pas les résultats de Syncfusion ici. DevExpress et GroupDocs ont montré à peu près les mêmes performances. Du côté DevExpress, il y a un pourcentage significativement plus élevé de conversions réussies, du côté GD, un travail correct avec les notes de bas de page.
Compte tenu des résultats, le choix était évident. À ce jour, nous utilisons la solution de DevExpress et nous prévoyons bientôt de passer à sa 19e version.
Il y a un pdf, extraire le texte avec mise en forme
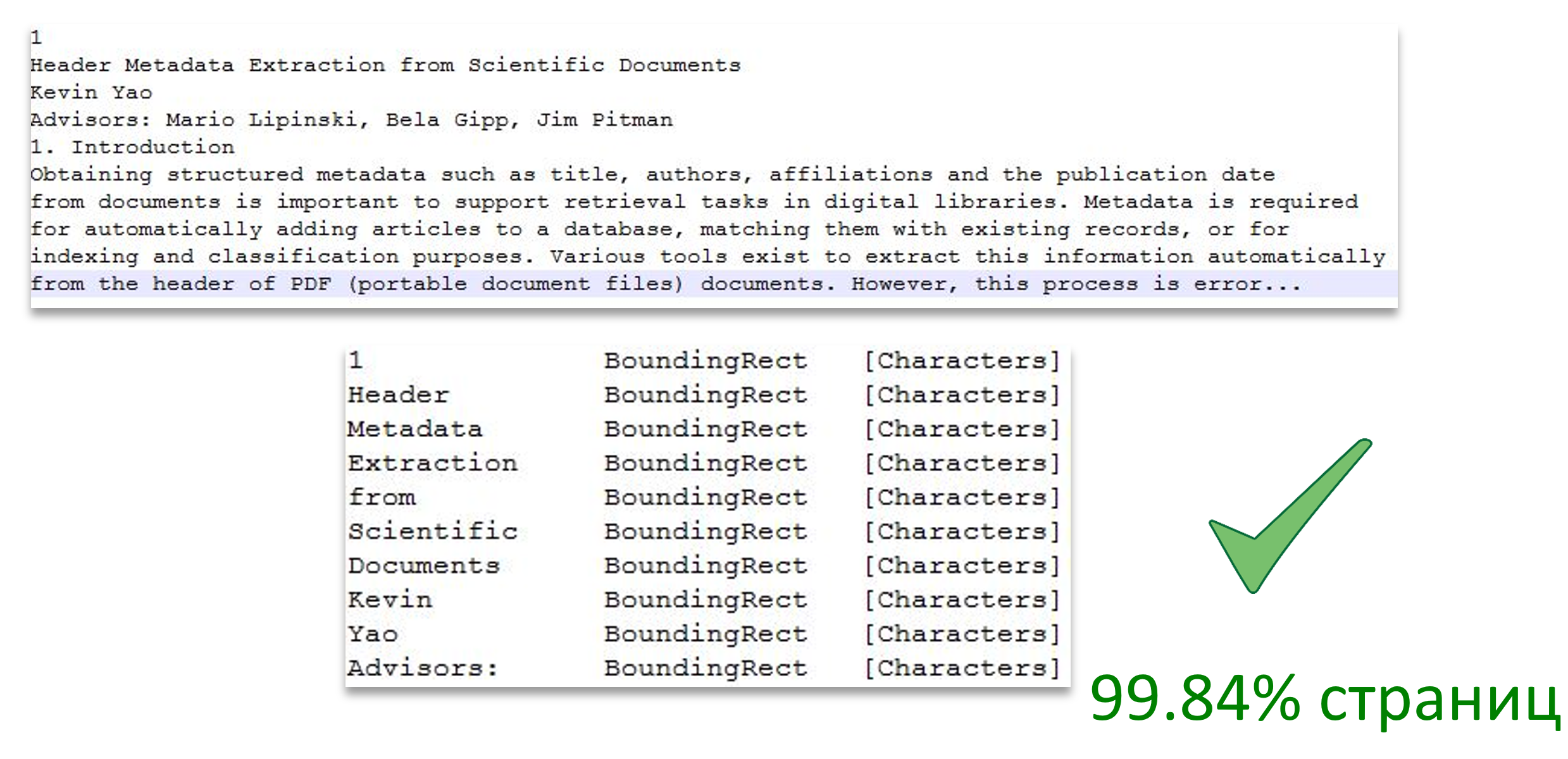
Ainsi, nous pouvons convertir des documents en pdf. Nous avons maintenant une autre tâche: utiliser DevExpress pour extraire le texte, connaître à chaque mot toutes les informations dont nous avons besoin. À savoir:
- Sur quelle page se trouve le mot;
- L'emplacement du mot sur la page (encadrement d'un rectangle);
- La taille de police du mot (caractères du mot).
L'image montre la répartition du texte en pages et montre également la correspondance d'un mot de texte avec la zone de page.

Source de l'image: Extraction des métadonnées d'en-tête à partir de documents scientifiques
Il semblerait que tout devrait être simple. Nous regardons ce que l'API DevExpress nous fournit:
- Nous avons une méthode qui retourne le texte de tout le document. Chaîne simple;
- Nous avons la possibilité d'itérer selon le document. Pour chaque mot, nous pouvons obtenir:
- Texte du mot;
- La page sur laquelle se trouve le mot;
- Le rectangle de cadrage du mot;
- Informations sur les caractères individuels du mot (signification du caractère encadrant le rectangle, taille de police, ...).
D'accord, tout semble être là. Voici seulement comment obtenir les données nécessaires pour chaque mot dans le texte du document renvoyé par DevExpress? Nous ne voulons pas vraiment collecter le texte du document à partir des mots nous-mêmes, car, par exemple, nous n'avons pas d'informations là où il y a juste un espace entre les mots et où se trouve le saut de ligne. Nous devrons trouver une heuristique basée sur l'emplacement des mots ... Le texte est - le voici, devant nous, déjà assemblé.

Source de l'image: Eureka!
La solution évidente consiste à faire correspondre les mots avec le texte du document. Nous regardons - en effet, dans le texte du document les mots sont disposés dans le même ordre dans lequel ils sont renvoyés par l'itérateur selon les mots du document.
Nous implémentons rapidement un algorithme simple pour faire correspondre les mots avec le texte du document, ajoutons des vérifications que tout est correctement mis en correspondance, commençons ...
En effet, tout fonctionne correctement sur la grande majorité des pages, mais malheureusement pas sur toutes les pages.

Source de l'image supérieure: Êtes-vous sûr?
De la part des documents, nous voyons que les mots dans le texte ne sont pas dans l'ordre dans lequel ils vont lors de l'itération sur les mots du document. De plus, on peut voir que la parenthèse ouvrante dans le texte de la liste de mots est représentée comme la parenthèse fermante et se trouve dans un autre «mot». Un affichage correct de ce fragment de texte peut être vu en ouvrant le document dans MS Word. Plus intéressant, si vous ne convertissez pas le document en pdf, mais que vous extrayez directement le texte du document, nous obtenons alors la troisième version du fragment de texte qui ne correspond ni à l'ordre correct ni aux deux autres commandes reçues de la bibliothèque. Dans ce fragment, comme dans la plupart des autres, sur lesquels un problème similaire se pose, le point est en caractères «RTL» invisibles, qui changent l'ordre des caractères / mots adjacents.
Ici, il convient de rappeler que nous avons appelé la qualité du support technique importante lors du choix d'une bibliothèque. Comme la pratique l'a montré, dans cet aspect, l'interaction avec DevExpress est assez efficace. Le problème avec le document soumis a été rapidement résolu après la création du ticket correspondant. Un certain nombre d'autres problèmes liés aux exceptions / consommation élevée de mémoire / traitement de documents longs ont également été corrigés.
Cependant, bien que DevExpress ne fournisse pas un moyen direct d'obtenir le texte avec les informations nécessaires pour chaque mot, nous continuons à comparer parfois incomparables. Si nous ne pouvons pas établir une correspondance exacte entre les mots et le texte, nous utilisons un certain nombre d'heuristiques qui permettent de petites permutations de mots. Si rien n'y fait, le document reste sans mise en forme. Rarement, mais cela arrive.
Au revoir :)