Il s'agit bien sûr de
DevOpsConf . Si vous ne rentrez pas dans les détails, alors le 30 septembre et le 1er octobre nous tiendrons une conférence sur l'unification des processus de développement, de test et d'exploitation, et si vous y allez, je demande cat.
Dans le cadre de l'approche DevOps, toutes les parties du développement technologique du projet sont entrelacées, se déroulent en parallèle et s'influencent mutuellement. La création de processus de développement automatisés pouvant être modifiés, simulés et testés en temps réel revêt une importance particulière. Cela aide à répondre instantanément aux changements du marché.
Lors de la conférence, nous voulons montrer comment cette approche affecte le développement de produits. Quelle est la fiabilité et l'adaptabilité du système pour le client. Comment DevOps modifie la structure et l'approche de l'entreprise pour l'organisation du workflow.

Dans les coulisses
Il est important pour nous de savoir non seulement ce que font les différentes entreprises dans le cadre de l'approche DevOps, mais aussi de comprendre pourquoi c'est tout. Par conséquent, nous avons invité non seulement des experts au Comité du programme, mais des experts qui voient le discours DevOps sous différents angles:
- ingénieurs seniors;
- les développeurs
- timlides;
- CTO.
D'une part, cela crée des difficultés et des conflits lors de l'examen des demandes de rapports. Si un ingénieur souhaite analyser un accident majeur, il est plus important pour le développeur de comprendre comment créer un logiciel qui fonctionne dans les nuages et les infrastructures. Mais en acceptant, nous créons un programme qui sera précieux et intéressant pour tout le monde: des ingénieurs au CTO.

La tâche de notre conférence n'est pas seulement de choisir des rapports plus high-tech, mais de présenter une vue d'ensemble: comment l'approche DevOps fonctionne dans la pratique, quel type de rake vous pouvez rencontrer lorsque vous passez à de nouveaux processus. Dans le même temps, nous construisons la partie contenu, en passant de la tâche métier à des technologies spécifiques.
Les sections de la conférence resteront les mêmes que la
dernière fois .
- Plateforme d'infrastructure.
- L'infrastructure comme code.
- Livraison continue.
- Rétroaction.
- Architecture chez DevOps, DevOps pour CTO.
- Pratiques SRE.
- Formation et gestion des connaissances.
- Sécurité, DevSecOps.
- Transformation DevOps.
Appel à communications: quels rapports recherchons-nous?
Nous avons divisé sous condition l'audience potentielle de la conférence en cinq groupes: ingénieurs, développeurs, spécialistes de la sécurité, chefs d'équipe et CTO. Chaque groupe a sa propre motivation pour venir à la conférence. Et, si vous regardez DevOps à partir de ces positions, vous pouvez comprendre comment concentrer votre sujet et où mettre l'accent.
Pour les ingénieurs qui créent une plate-forme d'infrastructure, il est important de comprendre les tendances existantes, de comprendre quelles technologies sont les plus avancées actuellement. Ils seront intéressés à se familiariser avec l'expérience réelle de l'utilisation de ces technologies et à échanger des vues. Un ingénieur écoutera avec plaisir un rapport avec une analyse d'un accident hardcore, nous essaierons à notre tour de prendre et de peaufiner un tel rapport.
Pour les développeurs, il est important de comprendre un concept comme
une application native dans le cloud . Autrement dit, comment développer un logiciel pour qu'il fonctionne dans les nuages et diverses infrastructures. Le développeur doit constamment recevoir des commentaires du logiciel. Ici, nous voulons entendre des cas sur la façon dont les entreprises construisent ce processus, comment surveiller les performances des logiciels et comment fonctionne l'ensemble du processus de livraison.
Il est important pour les
professionnels de la cybersécurité de comprendre comment configurer le processus de sécurité afin qu’il n’arrête pas les processus de développement et les changements au sein de l’entreprise. Les sujets sur les exigences que DevOps impose à ces spécialistes seront intéressants.
Les Timlids veulent savoir comment fonctionne le processus de livraison continue dans d'autres entreprises. De quelle manière la société a-t-elle procédé, comment les processus de développement et l'assurance qualité au sein de DevOps ont-ils été construits? Les coéquipiers natifs du cloud sont également intéressants. Et aussi - des questions sur l'interaction au sein de l'équipe et entre les équipes de développeurs et d'ingénieurs.
Pour
CTO, le plus important est de trouver comment combiner tous ces processus et les adapter aux besoins de l'entreprise. Il s'assure que l'application est fiable à la fois pour l'entreprise et le client. Et ici, vous devez comprendre quelles technologies fonctionneront sous quelles tâches commerciales, comment construire l'ensemble du processus, etc. Le CTO est également responsable de la budgétisation. Par exemple, il doit comprendre combien d'argent il doit dépenser pour recycler des spécialistes afin qu'ils puissent travailler dans DevOps.

Si vous avez quelque chose à dire à ces occasions, ne restez pas silencieux;
soumettez un rapport . La date limite de l'appel à communications est le 20 août. Plus tôt vous vous présenterez, plus vous aurez de temps pour finaliser le rapport et préparer la présentation. Alors, ne serrez pas.
Eh bien, si vous n'avez pas besoin de parler en public,
achetez simplement
un billet et venez les 30 septembre et 1er octobre pour discuter avec des collègues. Nous promettons que ce sera intéressant et inspirant.
Comme nous le voyons DevOps
Pour comprendre exactement ce que nous entendons par DevOps, je recommande de lire (ou relire) mon exposé «
Qu'est-ce que DevOps ». En marchant le long des vagues du marché, j'ai vu comment l'idée de DevOps se transforme dans des entreprises de différentes tailles: d'une petite startup à une multinationale. Le rapport est construit sur une série de questions, en y répondant, vous pouvez comprendre si votre entreprise passe à DevOps ou s'il y a des problèmes quelque part.
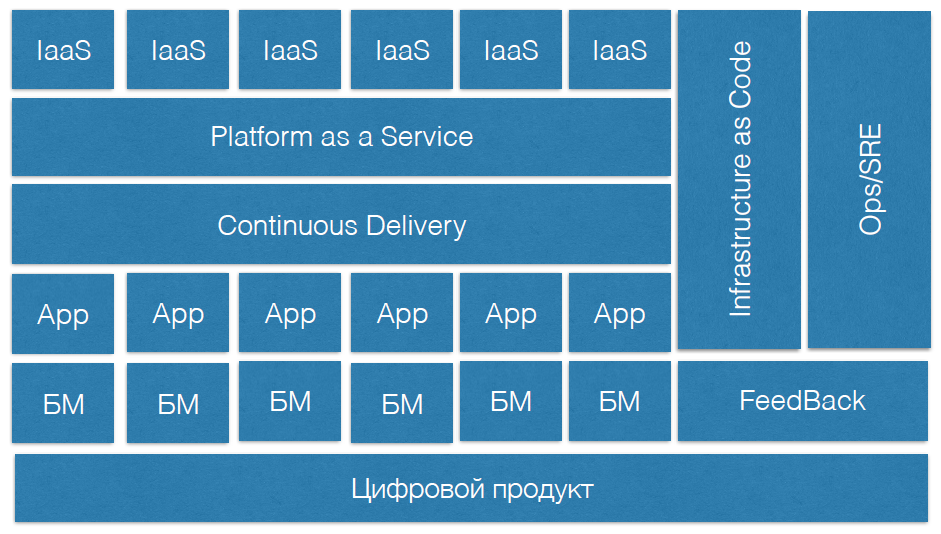
DevOps est un système complexe, il devrait avoir:
- Produit numérique.
- Les modules métiers que ce produit numérique développe.
- Équipes de produits qui écrivent du code.
- Pratiques de livraison continue.
- Plateformes en tant que service.
- L'infrastructure en tant que service.
- L'infrastructure comme code.
- Des pratiques de fiabilité distinctes câblées à l'intérieur de DevOps.
- Une pratique de rétroaction qui décrit tout cela.
À la fin du rapport, il y a un schéma qui donne une idée du système DevOps dans l'entreprise. Il vous permettra de voir quels processus de votre entreprise sont déjà débogués et lesquels n'ont qu'à être construits.
Vous pouvez regarder le reportage vidéo
ici .
Et maintenant, il y aura un bonus: plusieurs vidéos de RIT ++ 2019 qui se rapportent aux problèmes les plus courants de la transformation DevOps.
L'infrastructure de l'entreprise en tant que produit
Artyom Naumenko dirige l'équipe DevOps de Skyeng et s'occupe du développement de l'infrastructure de son entreprise. Il a expliqué comment l'infrastructure affecte les processus métier dans SkyEng: comment calculer le retour sur investissement pour celle-ci, quelles mesures devraient être choisies pour le calcul et comment travailler pour les améliorer.
En route vers les microservices
Nixys s'engage à prendre en charge des projets Web et des systèmes distribués très chargés. Son directeur technique Boris Ershov a expliqué comment transférer des produits logiciels, dont le développement a commencé il y a environ 5 ans (voire plus), sur des rails modernes.

En règle générale, ces projets sont un monde spécial où il y a des coins sombres et anciens de l'infrastructure que les ingénieurs actuels ne connaissent pas à leur sujet. Et les approches une fois sélectionnées de l'architecture et du développement sont dépassées et ne peuvent pas fournir aux entreprises le même rythme de développement et de sortie de nouvelles versions. En conséquence, chaque version du produit se transforme en une aventure incroyable où quelque chose tombe constamment et à l'endroit le plus inattendu.
Les gestionnaires de tels projets sont inévitablement confrontés à la nécessité de transformer tous les processus technologiques. Dans son rapport, Boris a déclaré:
- Comment choisir l'architecture adaptée au projet et ranger l'infrastructure;
- quels outils utiliser et quels pièges se trouvent sur le chemin de la transformation;
- que faire ensuite.
Automatisation des versions ou comment livrer rapidement et sans douleur
Alexander Korotkov est l'un des principaux développeurs du système CI / CD au CIAN. Il a parlé des outils d'automatisation qui ont amélioré la qualité et réduit le délai de livraison du code en production de 5 fois. Mais de tels résultats n'auraient pas pu être obtenus avec une seule automatisation, donc Alexander a attiré l'attention sur les changements dans les processus de développement.
Comment les accidents vous aident-ils à apprendre?
Alexey Kirpichnikov met en œuvre DevOps et l'infrastructure dans SKB Kontur depuis 5 ans. Pendant trois ans, environ 1 000 fakaps de divers degrés d'épopée se sont produits dans son entreprise. Parmi eux, par exemple, 36% ont été causés par le déploiement d'une version de mauvaise qualité en production, et 14% par des travaux de maintenance du fer dans le centre de données.
L'obtention d'informations aussi précises sur les accidents permet l'archivage des rapports (post-mortem), que les ingénieurs de l'entreprise mènent depuis plusieurs années de suite. Postmortem écrit l'ingénieur de service, qui a été le premier à répondre au signal de l'accident et a commencé à tout réparer. Pourquoi torturer les ingénieurs qui combattent les fakaps la nuit, en écrivant des rapports? Ces données vous permettent de voir la situation dans son ensemble et de faire évoluer le développement des infrastructures dans la bonne direction.
Dans son discours, Alexey a expliqué comment rédiger un post-mortem vraiment utile et comment mettre en œuvre la pratique de tels rapports dans une grande entreprise. Si vous aimez les histoires sur la façon dont quelqu'un a foiré, regardez une vidéo de la performance.
Nous comprenons que votre vision de DevOps peut ne pas coïncider avec nos opinions. Il sera intéressant de savoir comment vous voyez la transformation DevOps. Partagez vos expériences et visions sur ce sujet dans les commentaires.Quels rapports avons-nous déjà acceptés dans le programme?
Cette semaine, le Comité du programme a adopté 4 rapports: sur la sécurité, les infrastructures et les pratiques SRE.
Peut-être le sujet le plus douloureux de la transformation DevOps: comment s'assurer que les gars du département de la sécurité de l'information ne ruinent pas les liens déjà établis entre le développement, l'exploitation et l'administration.
Certaines entreprises se passent d'un service de sécurité de l'information . Comment alors assurer la sécurité de l'information? Cela
dira à Mona Arkhipova de sudo.su. De son rapport, nous apprenons:
- quoi et contre qui il faut protéger;
- quels sont les processus de sécurité courants;
- Comment les processus informatiques et informatiques se croisent
- qu'est-ce que CIS CSC et comment le mettre en œuvre;
- comment et par quels indicateurs effectuer des contrôles SI réguliers.
Le prochain rapport traite du développement de l'infrastructure sous forme de code. Réduire la quantité de routine manuelle et ne pas transformer tout le projet en chaos, est-ce possible?
Maxim Kostrikin d'Ixtens répondra à cette question. Ses entreprises utilisent
Terraform pour travailler avec l'infrastructure AWS. L'outil est pratique, mais la question est de savoir comment l'utiliser pour éviter l'apparition d'un énorme bloc de code. L'entretien d'un tel patrimoine coûtera de plus en plus chaque année.
Maxim montrera comment les modèles de placement de code visent à simplifier le travail d'automatisation et de développement.
Nous entendrons un autre
rapport sur l'infrastructure de
Vladimir Ryabov de Playkey . Ici, nous parlerons de la plate-forme d'infrastructure et nous apprendrons:
- comment comprendre si la capacité de stockage est utilisée efficacement;
- comment plusieurs centaines d'utilisateurs peuvent recevoir 10 To de contenu si seulement 20 To de stockage sont utilisés;
- comment compresser les données 5 fois et les fournir aux utilisateurs en temps réel;
- comment synchroniser à la volée des données entre plusieurs centres de données;
- comment exclure toute influence des utilisateurs les uns sur les autres dans l'utilisation séquentielle d'une machine virtuelle.
Le secret de cette magie réside dans la technologie
ZFS pour FreeBSD et son dernier fork de
ZFS sur Linux . Vladimir partagera les cas de Playkey.
Matvey Kukuy d'Amixr.IO est prêt à
dire par des exemples tirés de la vie ce qu'est le
SRE et comment il aide à construire des systèmes fiables. Amixr.IO transmet les incidents clients via son backend, des dizaines d'équipes de service à travers le monde ont déjà trié 150 000 cas. Lors de la conférence, Matvey partagera les statistiques et les idées que son entreprise a accumulées, résolvant les problèmes des clients et analysant la fakapy.
Encore une fois, je vous exhorte à ne pas être gourmand et à partager votre expérience avec DevOps-samurai. Postulez pour le rapport, et nous aurons 2,5 mois pour préparer une excellente présentation. Si vous voulez être un auditeur, abonnez - vous à la newsletter avec les mises à jour du programme et pensez sérieusement à réserver tôt les billets, car ils augmenteront de prix plus près des dates de la conférence.