Au cours des 3 dernières années, plus d'un millier d'incidents à des degrés divers d'épopée se sont produits à Contour. Les raisons sont différentes: par exemple, 36% sont causés par une libération de mauvaise qualité et 14% - en raison de la maintenance du fer dans le centre de données. D'où viennent les statistiques? Après chaque incident, un rapport est rédigé - post mortem. Ils sont rédigés par les ingénieurs de service qui ont répondu à la notification de l'accident et ont été les premiers à en comprendre les causes. Les autopsies sont analysées, identifiées et éliminées les causes des incidents, de sorte qu'à l'avenir de tels incidents ne se produisent pas. Mais cela n'a pas toujours été le cas.
Alexey Kirpichnikov (
BeeVee ) programme sur Yandex depuis 2008. Les embouteillages, travaillé sur des projets sportifs spéciaux, était un chef d'équipe du backend Yandex.Taxi. Depuis 2014, il est engagé dans le DevOps et l'infrastructure à
Kontur - il développe des outils qui facilitent la vie des développeurs des équipes produits. L'idée d'écrire et d'analyser des sujets post-mortem est apparue il y a cinq ans, et pendant ce temps, les sujets post-mortem ont été envahis par des modèles, un glossaire, des mémos, des captures d'écran et des analyses. Mais ce n'est pas le plus difficile -
il a été plus difficile de surmonter l'inertie, les craintes et l'incompréhension de la signification des rapports d'incident chez les ingénieurs . Ce qui est finalement arrivé et quel avantage irréparable les «analyses de canapé» peuvent faire, c'est de déchiffrer le rapport d'Alexey.
 Veuillez noter - sous les pieds de table de différentes longueurs, il y a des livres «Metrics», «Tests» et «Deploy».
Veuillez noter - sous les pieds de table de différentes longueurs, il y a des livres «Metrics», «Tests» et «Deploy».À Kontur, après l'embauche, ils donnent un ensemble de souvenirs: un stylo, une tasse, un cahier. Je suis arrivée chez SKB Kontur dans une nouvelle équipe d'infrastructure il y a 5 ans, lorsque l'entreprise a eu 25 ans.

Le contour de ces temps, et maintenant aussi, est une entreprise de produits dans laquelle plusieurs dizaines de produits ont développé le même nombre d'équipes, indépendantes les unes des autres en termes de choix de technologies et d'outils.
À cette époque, j'ai lu pour la première fois «Project '' Phoenix ''» et j'ai été inspiré par les idées nouvelles des pratiques DevOps. J'ai commencé à écrire mes idées d'améliorations dans un cahier, et maintenant c'est un artefact avec des taches de café et des documents historiques.
- « Surveillance! Mettons Grafana, collectons des métriques et construisons des graphiques. Nous comprendrons mieux ce qui se passe en production. " Pour 2014, il s'agit d'une nouvelle idée assez fraîche et d'une pratique DevOps solide. »
- " Crash automatique!" Combien de fichiers zip peuvent être téléchargés dans le dossier partagé, décompressez-les sur le serveur et exécutez exe dans le planificateur de tâches sous Windows? "Introduisons un système de déploiement industriel et publions des versions à travers lui, CI!"
- « Autopsie ! S'il y a une sorte d'accident dans la production, essayons tous de comprendre ce que c'était, de trouver la raison, d'écrire un rapport et de changer notre développement, nos tests, nos processus CI afin qu'il n'y ait plus de tels incidents à l'avenir »
Depuis 5 ans, nous progressons dans tous ces domaines. Nous avons notre propre système d'alerte
Moira , un système d'orchestration des applications et un tas d'outils. Mais de tout ce qui précède, la
rédaction de rapports d'incident s'est avérée être la pratique d'ingénierie la plus difficile à mettre en œuvre . Les ingénieurs adorent toutes sortes d'outils - attachez une sorte de système d'hébergement ou de CI, scriptez quelque chose, automatisez et ils n'aiment pas écrire de rapports, bien que cette pratique soit d'une grande utilité.
Je vais vous dire comment nous avons mis en œuvre des systèmes post-mortem et quels avantages nous en tirons. Peut-être que notre râteau aidera à aller plus vite et à remplir moins de cônes. Avant de commencer à parler d'autopsie, nous comprendrons la définition.
Qu'est-ce qu'un incident?
Lequel de ces incidents est l'incident?
- Exemple n ° 1. Sur une plateforme de blog avec un million d'utilisateurs, à la suite d'une sorte d'erreur, toutes les entrées d'un utilisateur sont perdues.
- Exemple n ° 2. Le service pour les employés de bureau fonctionne les jours de semaine de 9 à 6, et à d'autres moments, il n'y a pas d'utilisateurs. Le service n'était pas disponible dans la nuit du samedi au dimanche pendant deux heures consécutives, personne ne l'a remarqué.
- Exemple n ° 3. Grafana avec des mesures de production a chuté de 15 minutes. En production, rien ne s'est cassé, mais les graphismes n'étaient pas disponibles.
Pour comprendre ce qu'est cette fakapy, nous nous tournons vers l'expérience des gourous - Google, Atlassian, PagerDuty. Les gourous savent comment préparer les équipes, les ingénieurs de garde et comment rédiger des rapports pour les comprendre. Leurs guides en ligne ont des définitions d'incidents.
Définition de PagerDuty.
Un incident est toute interruption ou dégradation non planifiée d'un service qui affecte la disponibilité du service pour les utilisateurs. Un incident grave est un incident qui nécessite une réponse coordonnée de plusieurs équipes.
Cela semble logique, mais la définition est vague. En pratique, cela aide peu à comprendre ce qu'est un incident et ce qui ne l'est pas.
Le livre sur l'
ingénierie de la fiabilité des sites de Google a des critères clairs:
- Les utilisateurs ont remarqué la dégradation du service.
- Toutes les données ont été perdues.
- Il a fallu l'intervention de l'ingénieur de garde, par exemple, pour annuler manuellement la libération.
- La résolution du problème a pris trop de temps. Si un problème a été résolu en 2 heures, puis qu'une semaine a été consacrée à ce problème - il s'agit d'un incident qui nécessite une enquête.
- La surveillance n'a pas fonctionné. Par exemple, vous avez découvert un problème des utilisateurs.
Contour n'a pas de définition publiée d'un fakap, mais nous avons formulé nos critères pour déterminer ce qui est un incident.
Les utilisateurs externes ou internes ont constaté une dégradation du service . L'exemple n ° 3 avec Grafana, qui gisait, est un incident clair. La production n'a pas cassé et les utilisateurs externes ne l'ont pas remarqué, mais malgré cela, pour Contour c'est un fakap, car les outils internes ne fonctionnaient pas.
Chance . Dans l'exemple n ° 2, le service des employés de bureau a duré 2 heures la nuit - il a eu de la chance qu'il tombe la nuit. La prochaine fois, ce sera peut-être malchanceux, et donc l'incident de nuit doit également être jugé, comme s'il s'était produit pendant la journée.
L'incident concerne plusieurs équipes . Nous prenons cette définition de PagerDuty. L'analyse d'un incident est une bonne raison pour que plusieurs équipes travaillent ensemble. La culture «De notre côté, la balle a volé, mais quelque chose s'est cassé pour vous - c'est de votre faute» est éradiquée par une analyse conjointe.
Au moins un ingénieur considère cela comme un incident . La définition la plus vague, mais aussi la plus importante. Une règle simple: si l'ingénieur estime que le rapport vaut la peine, alors il vaut le rapport. Si cela vous fait peur que les ingénieurs commencent à rédiger des rapports pour n'importe qui et appellent toute petite chose un accident, ce n'est pas le cas.
Les ingénieurs sont des gens raisonnables, faites-leur confiance.Avec la définition et les différents types de dommages triés. Passons à la façon de bénéficier des incidents.
À quoi sert le fakap?
Les instructions simples que je donnerai plus loin, vous pouvez postuler vous-même, sans même parcourir l'article jusqu'au bout. Mais lisez toujours jusqu'à la fin.
Instruction classique
Trouvez d'abord les coupables. Faites ensuite le travail «pédagogique» avec les ingénieurs.
- Demandez à être plus prudent la prochaine fois.
- Si cela ne vous aide pas, envoyez-le à des cours de recyclage. Peut-être y apprendront-ils à être plus prudents.
- Si cela ne vous aide pas, supprimez les auteurs de travailler avec des parties critiques du système. Arrêtez de laisser les développeurs en production s'ils gâchent là-bas.
- Si rien n'y fait, licenciez les mauvais et engagez des compétents.
Si l'instruction vous agace, c'est une bonne nouvelle.
Cette approche est considérée comme traditionnelle pour les sociétés classiques à orientation verticale avec un patron qui gronde tout le monde et peut le licencier. L'un des fondements du mouvement DevOps et de l'idéologie DevOps est le départ d'organisations verticalement intégrées vers des organisations horizontales, avec une plus grande confiance dans les employés.
J'illustrerai ce changement de paradigme avec des
instructions de John Alspaw, l'un des leaders du mouvement DevOps, qui travaillait auparavant pour CTO à Etsy. L'instruction est tirée de son article canonique de 2013, Blameless Post Mortem and a Just Culture.
Demandez aux ingénieurs:
- quels événements ils ont observés;
- quand et quelles mesures ont été prises;
- quel résultat était attendu de ces actions;
- de quelles hypothèses provenaient;
- tel que compris par la séquence des événements qui se sont produits.
Les ingénieurs doivent être interrogés sans menace de punition.
C'est l'essentiel de la recommandation de John.
La menace de punition: recyclage, élimination de la production ou licenciement, motive les gens à mentir. Et la vérité est importante pour nous. Rapport d'incident - c'est le lien de rétroaction très manquant dans le processus de développement et de mise en production de fonctionnalités.
Dans l'ancien paradigme, les développeurs ont développé, jeté le vaisseau par-dessus la clôture aux ingénieurs d'exploitation et ils ont essayé de le faire fonctionner. Ils sont ennuyés par toute mise à jour, car elle peut tout casser, et les ingénieurs ont tout commencé avec tant de difficulté.
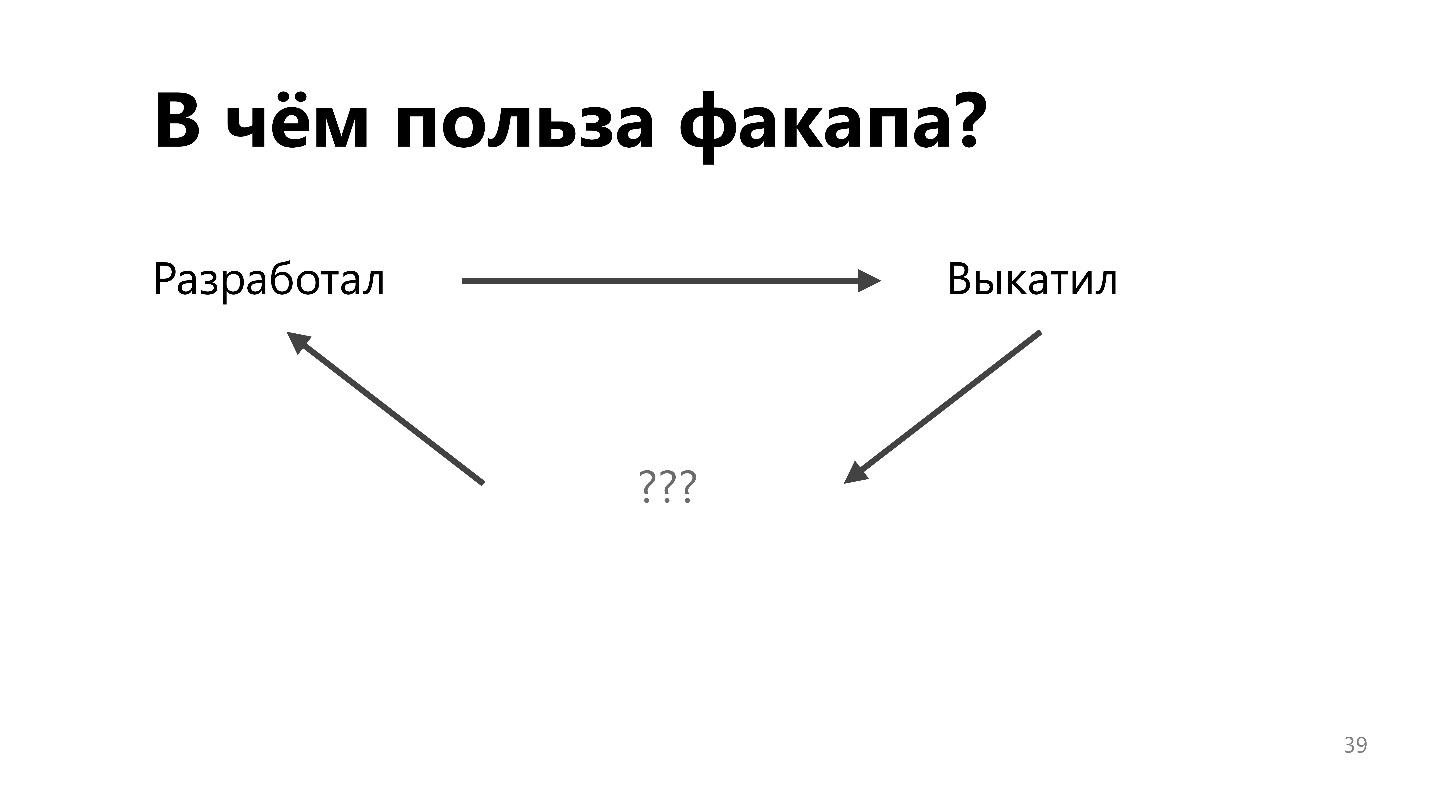
Le processus de rétroaction permet de changer le processus, l'infrastructure, les outils et l'approche de développement afin qu'il y ait moins de plantages en production.
Cela convaincra les chefs d'équipe et les responsables du développement de l'utilité de l'autopsie. Mais le problème est qu'il est difficile d'amener les ingénieurs à faire ce qu'ils pensent inutile et inutile. Nous avons une culture d'ingénierie dans notre entreprise, et je ne peux pas simplement venir, agiter le décret du PDG et exiger que tout le monde écrive post-mortem. Je dois en convaincre les ingénieurs.
Comment «vendre» l'idée d'ingénieurs post-mortem aux ingénieurs? Pour contourner les objections, pour montrer pourquoi l'autopsie est cool, pour démontrer l'avantage des rapports, que ce n'est pas seulement une désinscription, si seulement le patron est derrière.
Objection n ° 1: une fois
C'est le premier problème de l'ingénieur qui démonte le fakap - la guerre se terminera, alors nous parlerons! Lorsqu'un fakap se produit, je veux le réparer rapidement, mais je ne veux pas écrire des rapports incompréhensibles et longs.
Pour résoudre le problème, il y a un hack de vie, comment écrire quelque chose de bien lors d'un accident. Il a été popularisé par Artemy Lebedev:
«Il existe une manière simple d'organiser le temps - la méthode de la« jeepeg progressive ». À tout instant, tout projet est prêt à 100%, bien qu'il puisse être 4% plus développé. Selon le temps disponible, le projet peut être élaboré jusqu'à un pixel, ou il peut être laissé au stade de l'esquisse conceptuelle. »
Je vais illustrer la méthode progressive jeepeg en utilisant une image. Sur un Internet lent, une image n'est pas téléchargée immédiatement, mais par étapes.

Lors d'un incendie, vous n'avez pas besoin de rédiger un rapport cool et long. Cela vous suffit dans le coin supérieur gauche. Il suffit de marquer les choses qui seront difficiles à récupérer de la mémoire. N'essayez pas d'écrire un texte littéraire cohérent à un moment où tout est cassé en production.
Effectuez une action simple - notez la chronologie des événements.
Chronologie
La chronologie est alors très difficile à restaurer, si elle n'est pas enregistrée immédiatement. Un exemple d'enregistrement d'un vrai post-mortem dans le circuit.
15.01.18 17:25 YEKT PrefixSearch 50 . , .
Il s'agit d'une observation horodatée courte et simple. Selon cette chronologie, plus tard, il est facile de restaurer la séquence des événements et de trouver la cause de la panne. Mais si vous n'enregistrez rien directement pendant un incendie, il sera difficile, voire impossible, de restaurer les événements ultérieurement.
Captures d'écran
Une chose pratique, surtout lorsque vous travaillez avec un site Web ou une application de bureau. La situation est parfois difficile à décrire avec des mots, et une capture d'écran n'est qu'un clic d'une touche de raccourci.
La première objection a fonctionné. Enregistrement d'un minimum d'informations, un petit rapport lors de l'incident n'est pas difficile et ne prend pas un temps précieux. Lorsque tout est terminé, il doit être complété et exécuté dans un document compréhensible et cohérent.
Objection n ° 2: la paresse
Vous n'avez pas dormi pendant deux jours et avez corrigé un grave accident, en retard fatal dans toutes les tâches que vous alliez accomplir cette semaine. Mais il s'avère que quelque chose d'autre doit être fait, mais le feu a déjà été éteint! En ce moment, une paresse inimaginable se rattrape.
Pour vaincre complètement le problème ne fonctionnera pas. Mais vous pouvez faciliter votre travail à l'avance.
Motif
C’est d’abord et avant tout. Il y a une grande crainte d'un document vide qui doit être rempli de texte significatif. C'est beaucoup plus facile si le modèle est préparé. Il se compose généralement de sections et de questions. Nous entrons les réponses aux questions dans chaque section, et le modèle est rempli.
Les modèles de rapport d'incident sont volumineux. Lisez-les en détail avec le gourou. Tous les documents et livres auxquels je fais référence contiennent des modèles d'incident utilisés par les entreprises. D'après notre expérience, je peux ajouter ce qui suit.
Créer un mémo avec des exemples
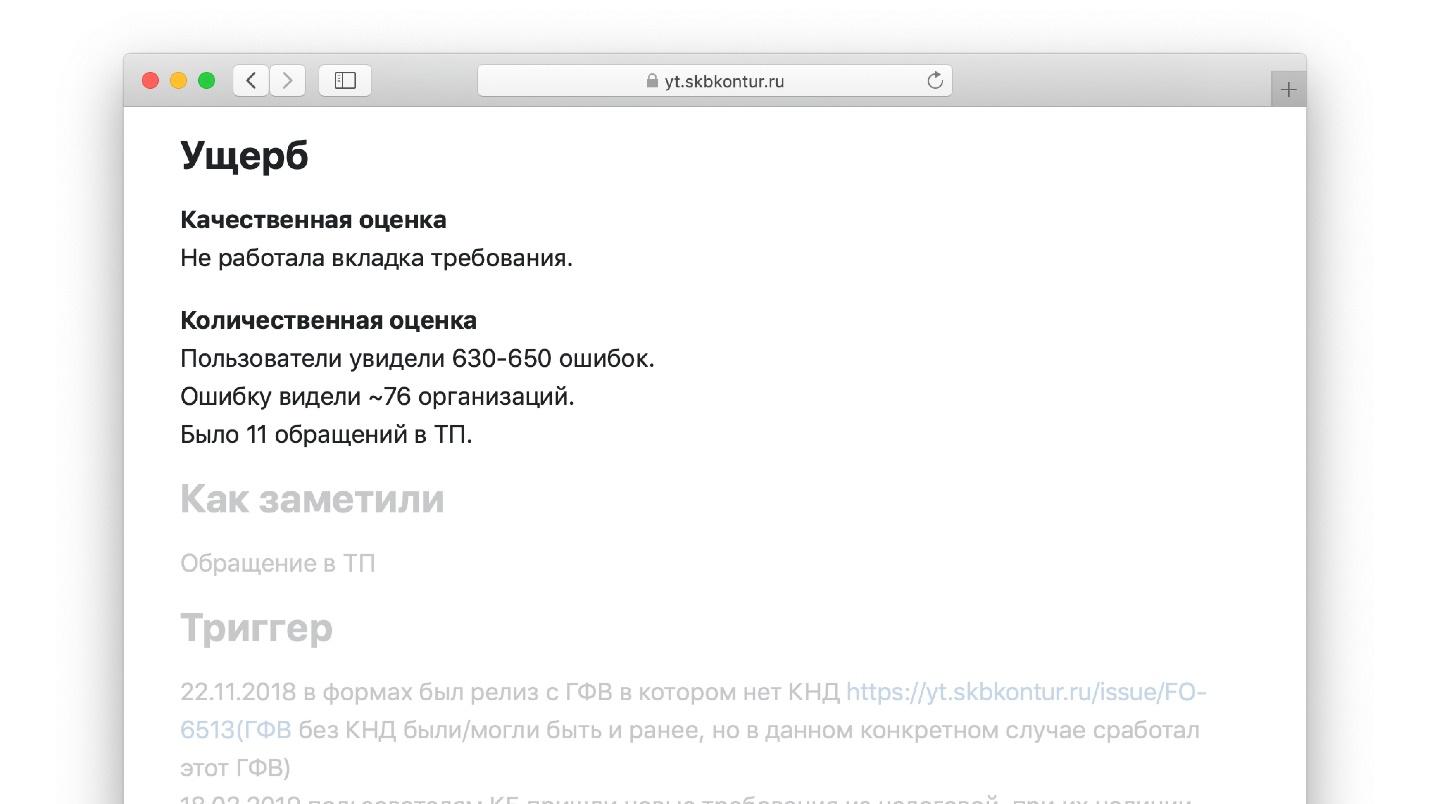
Notre modèle comporte une section «Dommages» avec des sous-sections.
Section "Évaluation qualitative". Il décrit ce que l'ingénieur voit devant lui lorsqu'il remplit cette partie du modèle:
- quelle fonctionnalité n'a pas fonctionné, combien de temps et pour qui;
- s'il y a eu perte ou corruption de données.
Ayant atteint cet endroit dans le modèle, l'ingénieur écrit: "Il y a un million d'utilisateurs sur notre plateforme de blog, nous avons perdu toutes les entrées de l'un d'eux." C'est beaucoup plus facile que d'écrire un essai à partir de zéro, comme dans une leçon de littérature.
Section "Quantification":- combien de demandes ont disparu;
- combien de latence a augmenté dans les métriques d'application et d'application client;
- combien d'appels sont perdus;
- Taille de la file d'attente du support technique utilisateur pour le problème.
Un ensemble de ces questions est le modèle.
Un exemple de l'un des modèles complétés.
Ajouter un glossaire
Un autre hack de vie pour les rapports d'accident, que je n'ai pas vu dans le livre avec le gourou. Lors de la rédaction d'un rapport, il est pratique d'utiliser des termes que vous connaissez bien. Par exemple, si je travaille avec Graphite, dans lequel les métriques sont stockées, je sais bien ce qu'est un «relais». Mais l'ingénieur qui lira le rapport dans un an peut ne pas être familier avec le terme. Il est peu probable qu'il soit en mesure de lire le rapport, qui se compose de mots inconnus. D'un autre côté, si chaque terme et définition est constamment mâché dans le rapport, la paresse ne fera que l'effrayer et le rapport ne sera pas terminé.
Rédigez un petit glossaire décrivant tous les termes utilisés dans le rapport.
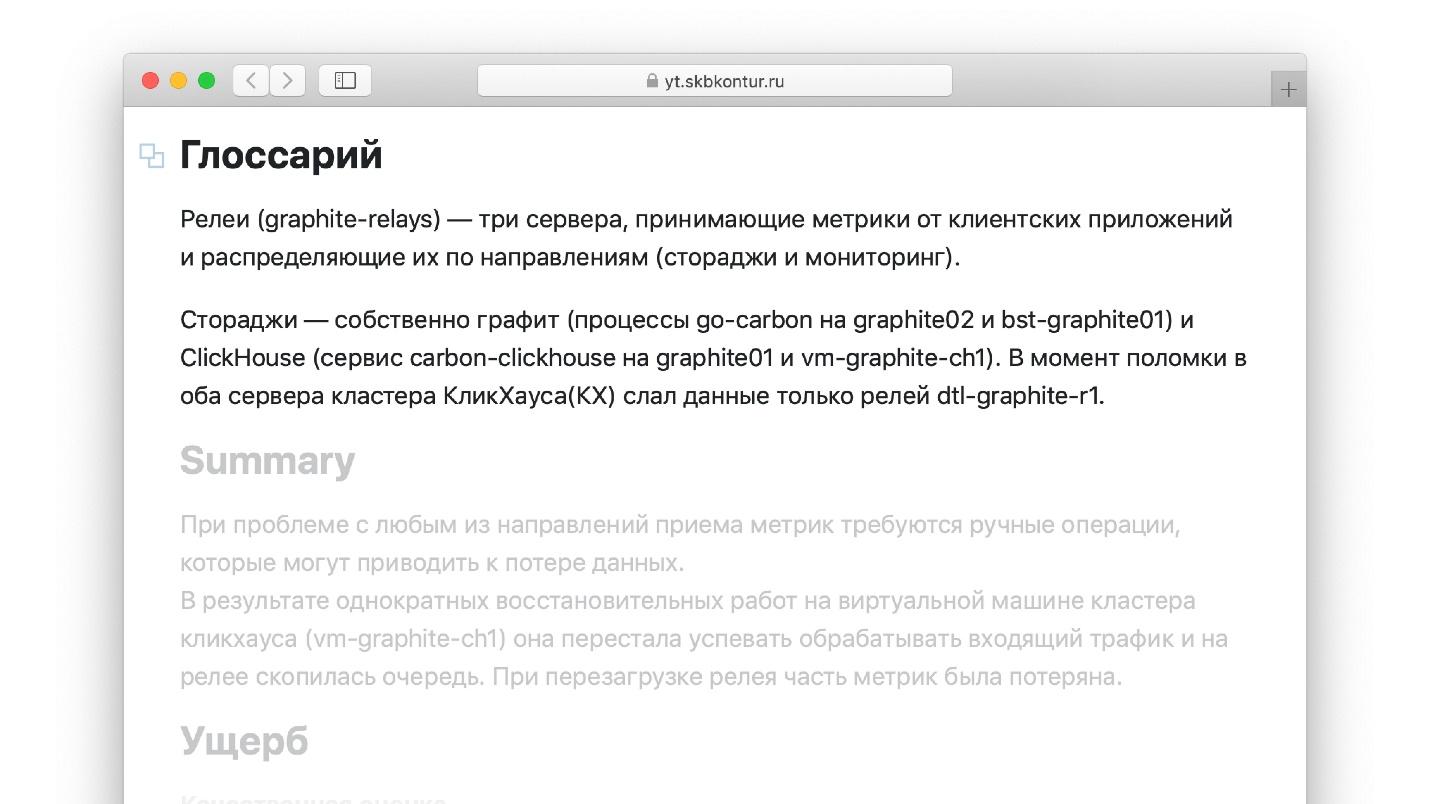
Copiez tous les artefacts
Si vous attachez des artefacts au rapport: des instantanés dans Grafana, l'historique des messages dans le chat, dans lequel l'incident a été analysé avec d'autres ingénieurs, faites des copies. Les métriques ont la possibilité de «pourrir» et les chats changent. Il y a un an, vous étiez à Slack, maintenant dans Telegram - le lien de discussion est obsolète et ne fonctionne pas, et les mesures de rétention vont tomber - elles sont stockées pendant un an.
Copiez les artefacts - ce hack de vie facilite la rédaction de rapports.
Objection n ° 3: personne ne lira
La plus grande et incompréhensible question posée par les ingénieurs est: "Qui lira ces rapports?" Supposons que j'ai surmonté la paresse et écrit une chronologie des événements pendant l'accident. Il a ensuite rassemblé ses forces et a ajouté un rapport de plusieurs pages sur ce qui s'est passé et les causes de l'accident. Mais s'il n'y a aucune compréhension de qui lira tout cela et qui en bénéficiera, il n'y a pas de désir de remplir des rapports.
L'autopsie est une rétroaction dans le processus d'amélioration continue des processus de développement.
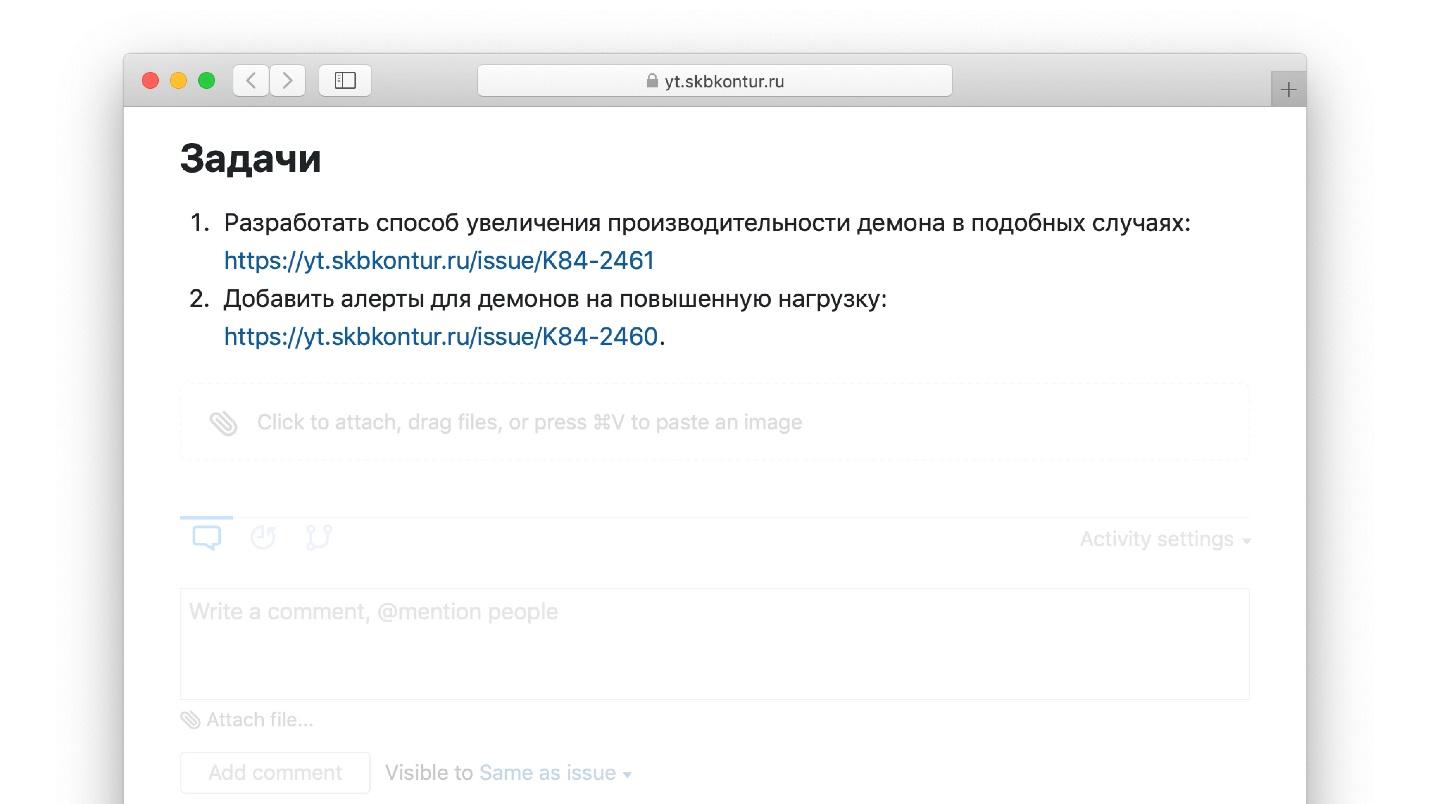
Dans tout livre de gourou, par exemple, dans le
manuel sur les incidents d'Atlassian , il est écrit qu'en fonction des résultats de chaque autopsie, il est nécessaire:
- formuler des tâches en développement;
- créer des tâches dans le bugtracker à partir desquelles vos développeurs les prendront;
- mettre des liens de l'autopsie à ces tâches.
Le feedback est clos : voici un post-mortem, ici des
actions : des tâches qui doivent être accomplies pour que l'accident ne se reproduise plus. Les tâches tombent dans l'arriéré de l'équipe, l'équipe les développe, déploie - encore une fois le fakap et l'autopsie. La roue du samsara s'est fermée.
C'est sur quoi tous les gourous convergent. Il n'y a rien à contester - les avantages sont évidents.
Un exemple de tâches d'éléments d'action d'un post-mortem réel.
Mais chez Kontur, nous avons ajouté un analyste à cela.
Analyse de canapé
Nous avions l'habitude d'analyser l'incident isolément. L'échec s'est produit de lui-même dans une équipe, dans un système d'hébergement - quelque chose s'est cassé, nous l'avons corrigé.
Mais il y a de nombreux incidents. Au cours des trois dernières années, plus de 1 000 rapports d'incidents se sont accumulés dans le circuit. Je voudrais savoir s'il est possible de bénéficier de toute la masse des rapports accumulés, et pas seulement de chacun individuellement. Est-il possible sur leur base de calculer les statistiques du système et de voir ce qu'il faut améliorer dans le système dans son ensemble.
Une équipe d'infrastructure spéciale travaille à Kontur, qui est engagée dans l'analyse de l'autopsie et publie les résultats et les conclusions sur la base de la masse entière des rapports accumulés. Nous appelons cela «l'analyse de canapé». Je vais vous donner des fragments d'un des articles de l'équipe, qui est publié sur notre réseau interne pour les employés.
Qu'analysons-nous dans l'analyse de canapé?
Durée du Fakap
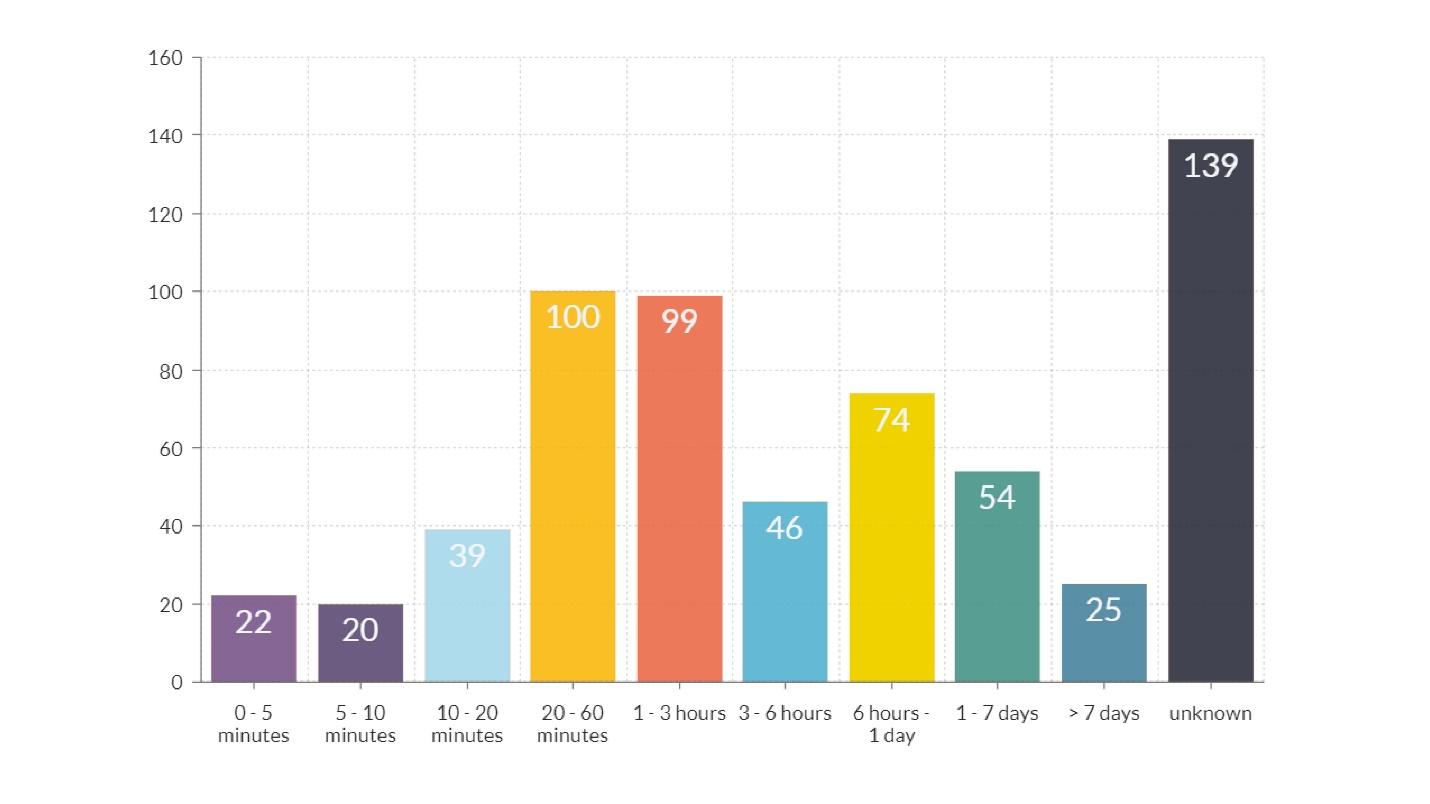 Dans le diagramme, en plus de la dernière colonne, où l'heure est inconnue, il y a deux pics plus évidents.Durée de l'ordre d'une heure
Dans le diagramme, en plus de la dernière colonne, où l'heure est inconnue, il y a deux pics plus évidents.Durée de l'ordre d'une heure - barres orange et rouges. La plupart de ce temps a été consacré à transmettre des informations sur ce qui s'est passé, de l'ingénieur qui a remarqué l'accident à l'ingénieur qui sait comment le réparer.
Le problème est la communication .
Si nous réparons nos outils afin que l'ingénieur qui résout le problème reçoive plus rapidement les informations, la durée des fakaps et les dégâts qui en découlent seront considérablement réduits. C'est quelque chose que nous ne reconnaîtrions pas en examinant un fakap individuellement.
Durée environ 12 heures - une colonne jaune. L'explication du fait qu'il existe de nombreux fakaps qui durent plus de 12 heures est simple: ils ont lancé la sortie le soir, et le matin, les utilisateurs sont venus et tout s'est cassé. La conclusion de ce qu'il faut faire pour réduire le nombre de ces fakaps est évidente.
Dommages de qualité

Les dommages qualitatifs sont divisés en plusieurs catégories. Le top 3 comprend:
- inaccessibilité, erreurs;
- freins, latence accrue;
- comportement incorrect visible.
Selon l'analyse, la grande majorité de ces erreurs. D'une part, c'est une bonne nouvelle. Trois types d'erreurs les plus courantes sont faciles à détecter - nous ajustons les mesures à la latence et au nombre d'erreurs, et remarquons rapidement de telles choses.
La mauvaise nouvelle, c'est qu'il y a la plupart de ces erreurs. Ce sont de simples erreurs techniques, ce qui signifie que nous pourrions améliorer quelque chose dans les tests de pipeline, effectuer plus de tests de résistance et améliorer le système de surveillance.
Déclencheurs
C'est ce qui a directement conduit à la panne, c'est-à-dire non pas la cause première de l'accident, mais la «dernière goutte»: les bûches ont rempli le disque et à cause de cela, tout s'est cassé, mis en liberté - tout a explosé.

En premier lieu, la «mise à jour de l'installation». Cette raison nous permet de comprendre où nous, en tant qu'équipe d'infrastructure, devons investir. Par exemple, pour améliorer le système de déploiement et introduire un déploiement canari. C'est le point d'effort qui aura le plus d'impact sur la qualité de nos systèmes.
C'est le point de toutes les analyses - pour comprendre où une petite équipe d'infrastructure devrait investir dès maintenant dans des conditions de ressources limitées.
Quoi améliorer - alerte ou déploiement? Que faire - l'hébergement ou la beauté des graphiques?
Voici un autre bon aperçu. En deuxième position, «la cause est inconnue». Il s'agit d'un indicateur de mauvaise communication des rapports d'incident.
"Pilules" possibles
Cela permet une solution technique simple pour réduire le nombre d'accidents d'un certain type. Par exemple, nous savons que les choses les plus importantes qui réduisent le nombre de fakaps sont les notifications du système de surveillance. S'il y avait plus d'alertes dans la surveillance de ces événements, combien d'incidents pourrions-nous éviter? Le pourcentage indique combien:
- sur le nombre d'erreurs HTTP du client - 10%;
- sur l'apparition de nouveaux types d'erreurs dans les journaux: installation, paramètres de notification - 8%;
- sur les ressources système: CPU, mémoire, disque, threads, GC - 6%.
Si l'alerte était correctement configurée et que l'ingénieur souhaité recevait une notification à temps, 24% des incidents ne se produiraient pas ou auraient une durée beaucoup plus courte. Cette conclusion peut être tirée sur la base de l'analyse de l'ensemble des incidents.
Ici, je vais de nouveau annoncer notre système d'alerte
Moira , qui est situé en Open Source.
Si vous disposez de Graphite, vous pouvez le télécharger et l'utiliser. J'espère qu'il y aura moins d'incidents.
Recommandations
Recommandations organisationnelles que l'équipe peut suivre, et aussi réduire le nombre d'accidents. Notre top 3.
- La similitude des sites de test et de combat . 5% des incidents sont survenus du fait que le site d'essai n'était pas assez similaire au site de combat.
- Compatibilité descendante dans les versions . La version a été dégonflée, n'était pas rétrocompatible avec la précédente, des migrations de données sont survenues - 4% des erreurs.
- Refus des libérations nocturnes . Si vous cessez de diffuser des rejets qui cassent, le soir, 4% des incidents disparaîtront.
Je souligne qu'il ne s'agit pas d'une instruction, mais d'une histoire sur la façon dont nous avons collecté des analyses. Vos analyses peuvent être différentes.
Comment écrire
Si vous réalisez que l'analyse des incidents est une bonne chose et que vous devez rédiger des rapports, je vais vous dire comment procéder.
Post-mortem et tâches dans un outil de suivi des bogues
Dans le bugtracker, contrairement à Google Docs ou Wiki, il existe des champs fixes pour lesquels vous pouvez définir un ensemble de valeurs. Cela facilite l'analyse des statistiques graphiques ultérieurement.
Dans le livre SRE, Google fournit un modèle dans Google Docs dans lequel ils écrivent des rapports dans leur document interne. Je ne peux pas imaginer comment nous pouvons collecter les analyses que nous collectons à partir de documents Google non structurés.
Nous écrivons des rapports dans le même traqueur de bogues que les tâches principales, car nous pouvons connecter la tâche avec l'autopsie. Examinons l'autopsie et voyons immédiatement quelles tâches sont fermées, lesquelles ne le sont pas et lesquelles restent à faire.
Créer des champs spéciaux
J'ai déjà parlé de domaines spéciaux. Nous avons ce qui suit.
- Le début et la fin du fakap peuvent être analysés automatiquement. Si vous mettez des horodatages lisibles par machine, vous pouvez tracer la durée du fakap.
- Le début et la fin de l'enquête.
- Déclencheur Configurez une liste déroulante de déclencheurs, c'est plus pratique.
- Comme indiqué.
- Dommages quantitatifs et qualitatifs.
- Équipes et services concernés.
Toutes les données de champs spéciaux vous permettent de comprendre le fonctionnement de votre infrastructure.
Un exemple de notre rapport d'incident terminé.

Les champs de la colonne de droite sont simplement remplis grâce à la sélection dans les listes déroulantes.
Rassemblez une équipe d'ingénieurs soucieux de la qualité
Pour obtenir des rapports qui vous aideront à comprendre comment développer votre infrastructure, vous aurez besoin de personnes soucieuses de la qualité de vos services. Ce ne seront pas nécessairement des ingénieurs qui se consacreront uniquement à l'analyse à temps plein à l'autopsie. Il est important que ces personnes soient très préoccupées par ce qui se passe. De temps en temps, ils se rassemblent, analysent toute la masse des incidents, écrivent de gros articles et apportent des avantages - fermez le cercle de rétroaction.
Notre équipe s'appelle Q-team - du mot "Qualité". Il compte 3 personnes - l'un des ingénieurs les plus talentueux de l'entreprise qui travaillent dans les infrastructures.
Total
Lisez le gourou - les articles de John Allspaw et les livres sur la gestion des incidents:
Site Reliability Engineering ,
PagerDuty Post-Mortem Process ,
Atlassian Incident Handbook .
Et quand vous venez travailler demain, faites
les premiers pas :
- démarrer un projet de fakaps dans le bugtracker dans lequel vous effectuez des tâches;
- prenez n'importe quel modèle - n'essayez pas d'écrire le vôtre, de prendre le nôtre ou de Google dans SRE;
- quand quelque chose explose, écrivez.
Au moment où vous rédigez les premier, deuxième et troisième rapports, vous n'aurez pas de belles analyses avec des colonnes multicolores. Mais après un an ou deux, lorsque les données se sont accumulées, vous regardez en arrière et vous remerciez pour la première étape.
Nous espérons que vous vous souviendrez et remercierez Alexei pour l'histoire d'une telle expérience. Et nous, à notre tour, essaierons de collecter de nouveaux rapports utiles dans le programme DevOpsConf , des recommandations à partir desquelles vous pourrez vous adresser et postuler. La conférence se tiendra du 30 au 1 septembre 2019 , jusqu'au 20 août, nous attendons toujours les candidatures des supporters de DevOps, mais 12 ont déjà été approuvées, c'est-à-dire que la concurrence sera plus élevée plus près de la date limite.
Si vous souhaitez partager votre expérience, décidez-vous et envoyez vos résumés . Si vous souhaitez recevoir les actualités du programme - abonnez-vous à notre newsletter et à notre chaîne de télégrammes .