Fin juin, une équipe de l'Université Carnegie Mellon nous a montré XLNet, présentant immédiatement la
publication , le
code et le modèle fini (
XLNet-Large , Cased: 24 couches, 1024-caché, 16 têtes). Il s'agit d'un modèle pré-formé pour résoudre divers problèmes de traitement du langage naturel.
Dans la publication, ils ont immédiatement indiqué une comparaison de leur modèle avec le
BERT de Google. Ils écrivent que XLNet est supérieur à BERT dans un grand nombre de tâches. Et montre des résultats dans 18 tâches de pointe.
BERT, XLNet et Transformers
Le transfert d'apprentissage est l'une des tendances récentes de l'apprentissage en profondeur. Nous formons des modèles pour résoudre des problèmes simples sur une énorme quantité de données, puis nous utilisons ces modèles pré-formés, mais pour résoudre d'autres problèmes plus spécifiques. BERT et XLNet ne sont que de tels réseaux pré-formés qui peuvent être utilisés pour résoudre des problèmes de traitement du langage naturel.
Ces modèles développent l'idée de
transformateurs - l'approche actuellement dominante pour construire des modèles pour travailler avec des séquences. Très détaillé et avec des exemples de code sur les transformateurs et le mécanisme Attention est écrit dans
Le transformateur annoté .
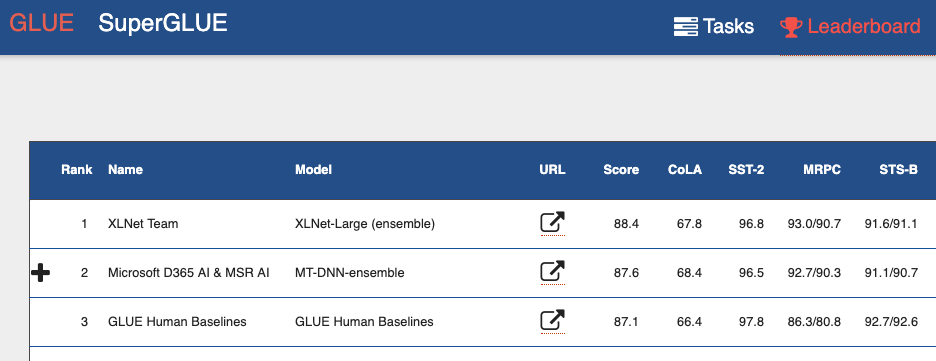
Si vous regardez le
classement du benchmark GLUE (General Language Understanding Evaluation) , vous pouvez voir de haut en bas de nombreux modèles basés sur des transformateurs. Y compris les deux modèles qui donnent de meilleurs résultats que les humains. Nous pouvons dire qu'avec les transformateurs, nous assistons à une mini-révolution dans le traitement du langage naturel.
Inconvénients du BERT
BERT est un auto-encodeur (autoencoder, AE). Il cache et gâche certains mots de la séquence et tente de restaurer la séquence de mots d'origine à partir du contexte.
Cela entraîne des inconvénients du modèle:
- Chaque mot caché est prédit individuellement. Nous perdons des informations sur les relations possibles entre les mots masqués. L'article fournit un exemple appelé «New York». Si nous essayons de prédire indépendamment ces mots dans leur contexte, nous ne prendrons pas en compte la relation entre eux.
- Incohérence entre les phases de formation du modèle BERT et l'utilisation du modèle BERT pré-formé. Lorsque nous formons le modèle - nous avons des mots cachés (jetons [MASQUE]), lorsque nous utilisons le modèle pré-formé, nous ne fournissons pas déjà de tels jetons à l'entrée.
Et pourtant, malgré ces problèmes, le BERT a montré des résultats de pointe sur de nombreuses tâches de traitement du langage naturel.
Caractéristiques XLNet
XLNet est une modélisation de langage autorégressive, AR LM. Elle essaie de prédire le prochain jeton à partir de la séquence des précédents. Dans les modèles autorégressifs classiques, cette séquence contextuelle est prise indépendamment des deux directions de la chaîne d'origine.
XLNet généralise cette méthode et forme le contexte à différents endroits de la séquence source. Comment le fait-il? Il prend toutes (en théorie) les permutations possibles de la séquence originale et prédit chaque jeton de la séquence des précédentes.
Voici un exemple de l'article comment le jeton x3 de diverses permutations de la séquence d'origine est prévu.
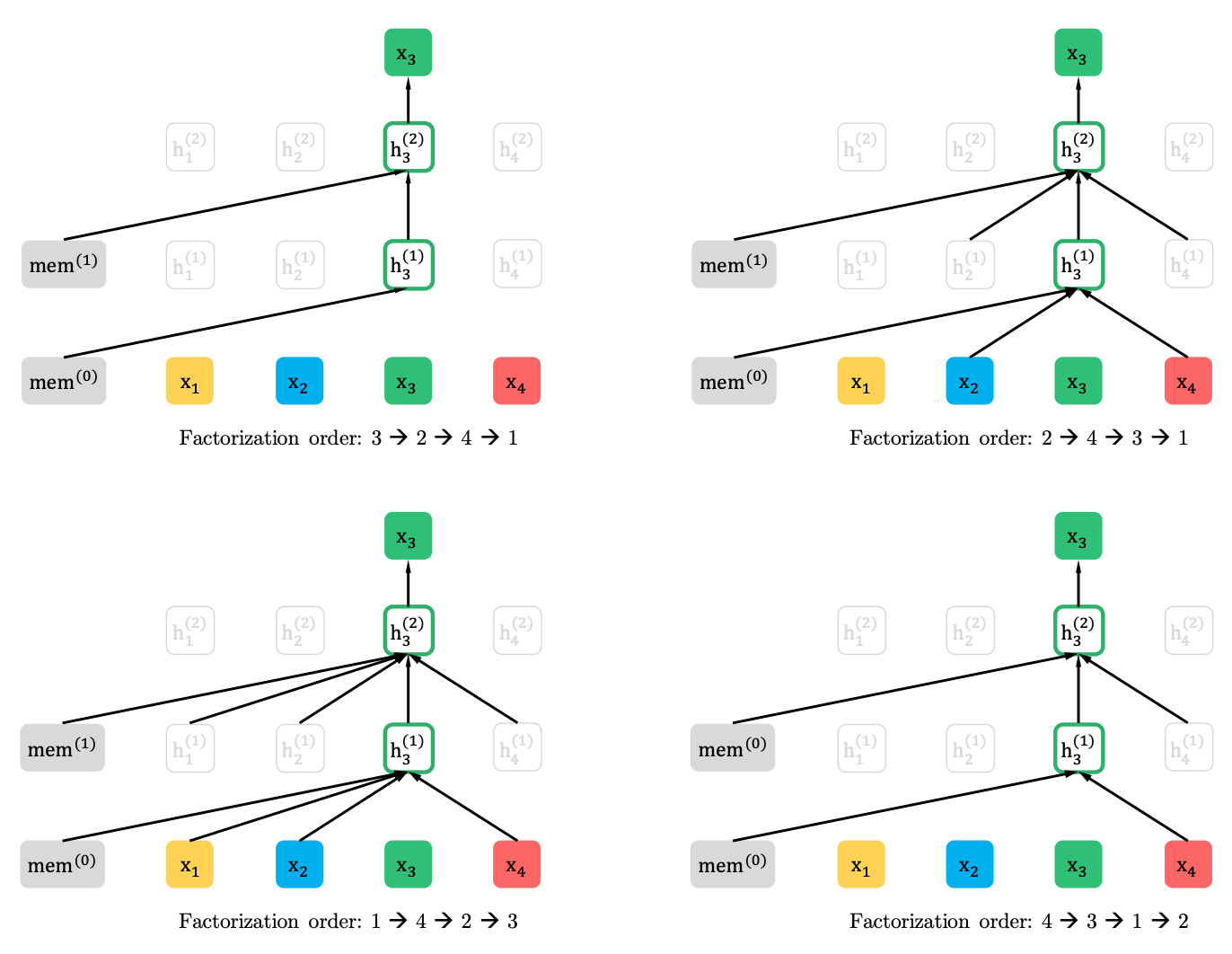
De plus, le contexte n'est pas un sac de mots. Des informations sur l'ordre initial des jetons sont également fournies au modèle.
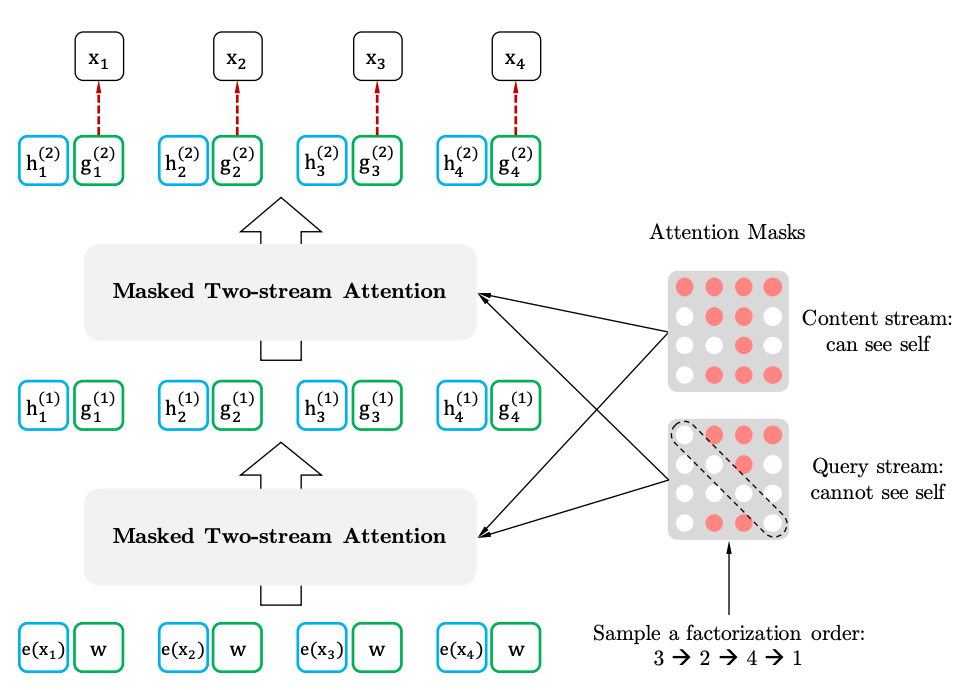
Si nous établissons des analogies avec le BERT, il s'avère que nous ne masquons pas les jetons à l'avance, mais utilisons plutôt différents ensembles de jetons cachés pour différentes permutations. Dans le même temps, le deuxième problème de BERT disparaît - le manque de jetons cachés lors de l'utilisation du modèle pré-formé. Dans le cas de XLNet, la séquence entière, sans masques, est déjà entrée.
Où est le XL dans le nom XL - parce que XLNet utilise le mécanisme Attention et les idées du modèle Transformer-XL. Bien que les langues perverses prétendent que XL fait allusion à la quantité de ressources nécessaires pour former le réseau.
Et sur les ressources. Sur Twitter, ils ont publié le
calcul de ce qu'il en coûterait pour former le réseau avec les paramètres de l'article. Cela a rapporté 245 000 dollars. Certes, un ingénieur de Google est venu et a
corrigé que l'article mentionne 512 puces TPU, dont quatre sur l'appareil. Autrement dit, le coût est déjà de 62 440 dollars, voire 32 720 dollars, compte tenu des 512 cœurs, qui sont également mentionnés dans l'article.
XLNet vs BERT
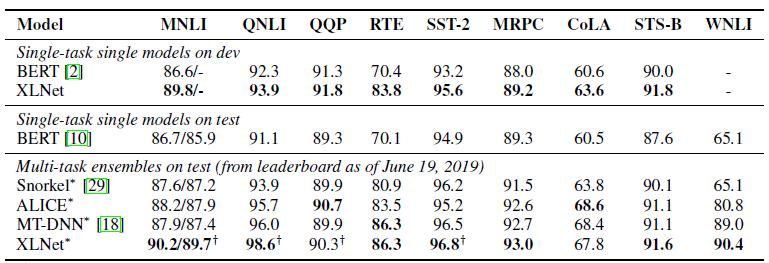
Jusqu'à présent, un seul modèle pré-formé pour l'anglais a été présenté pour l'article (XLNet-Large, Cased). Mais l'article mentionne également des expériences avec des modèles plus petits. Et dans de nombreuses tâches, les modèles XLNet affichent de meilleurs résultats par rapport aux modèles BERT similaires.
L'avènement du BERT et en particulier des modèles pré-formés a attiré beaucoup d'attention des chercheurs et a conduit à un grand nombre de travaux connexes. Voici maintenant XLNet. Il est intéressant de voir si, pendant un certain temps, il deviendra la norme de facto en PNL, ou vice versa, incitera les chercheurs à rechercher de nouvelles architectures et approches pour le traitement du langage naturel.