Bonjour à tous. Dans cet article, je parlerai de notre expérience en participant au concours d'analyse de données
Data Mining Cup 2019 (DMC) et de la façon dont nous avons réussi à entrer dans le TOP 10 des équipes et à participer à la finale du championnat en personne à Berlin.

Je vais raconter au nom de notre équipe, que j'entre (Alexander Perevalov), ainsi que mon collègue Sergey Bobkov. Nous sommes des étudiants diplômés de l'
Université Polytechnique de Perm , dans notre temps libre du travail et des études, nous nous engageons à résoudre des concours de science des données.
Qu'est-ce que DMC et comment l'avons-nous découvert
La Data Mining Cup est un championnat mondial d'analyse des données des étudiants qui se tient une fois par an. Son histoire a commencé il y a 20 ans, bien avant
Kaggle , on peut dire que le
DMC a organisé des concours d'analyse de données avant de devenir courant .
DMC est
hébergé par la société allemande
PrudSys , une société de
renseignement de détail . Auparavant, seule la participation en solitaire était autorisée au championnat, puis les participants étaient autorisés à se regrouper en équipes de l'université, soit dit en passant, le nombre maximum d'équipes de l'université est seulement de 2. L'adhésion à l'université est également strictement contrôlée, pour la participation, il est nécessaire d'avoir un courrier avec le domaine de votre étudiant et envoyer une copie de votre carte d'étudiant.
Aujourd'hui, si nous comparons le niveau de participants à DMC et Kaggle, bien sûr, le niveau de Kaggle est beaucoup plus élevé. Cela est dû à la restriction des étudiants dans le DMC et à la popularité de Kaggle. Une caractéristique distinctive du DMC est l'
absence d'un classement , ce qui élimine les problèmes de montage.
J'ai découvert la Data Mining Cup au moment où nous partions avec un groupe de notre université pour un stage en Allemagne, à mon arrivée à la maison, mon ami et coéquipier m'invitait à participer, c'était mi-avril. Honnêtement, j'étais sceptique quant à cette idée, cependant, ayant appris que cette année les données et la tâche sont assez simples - nous avons encore commencé à la résoudre.
Comment nous avons résolu la tâche
En 2019, la tâche se situait dans le domaine de la détection de fraude en libre-service. Vous avez sûrement déjà rencontré des caisses en libre-service dans les supermarchés. Ces appareils fonctionnent à la fois sous la supervision d'un employé de magasin et de manière entièrement automatique. Les caisses enregistreuses libre-service vous permettent d'optimiser les frais de personnel et de minimiser les files d'attente dans les supermarchés. Cependant, il y a un problème, la nature humaine est telle que d'une manière ou d'une autre, il y a un désir de «ne pas percer» les marchandises que nous voulons voir dans notre réfrigérateur. Pour éviter cela, un contrôle est nécessaire, mais tel qu'il n'embarrasse ni n'embête les clients.
Ainsi, sur la base des données balisées sur les transactions d'auto-paiement, il est nécessaire de développer un modèle mathématique qui classerait automatiquement une transaction particulière comme frauduleuse ou non frauduleuse. Donc, nous résolvons le problème de classification binaire.
Les données étaient les suivantes:

La taille de l'échantillon de formation n'était que de ~ 1800 exemples, tandis que l'échantillon de test était de 499000 exemples. De plus, l'
échantillon de formation
n'était pas équilibré : seulement 4% des transactions étaient frauduleuses, il est évident que l'
exactitude (la part des bonnes réponses) est ici inutile. Étonnamment, il n'y avait aucune valeur manquante dans les données, et certains des attributs étaient également répartis. Sur cette base, nous pouvons conclure que les
données sont générées artificiellement.De plus, les organisateurs ont proposé leur métrique sous la forme d'une matrice de confusion, qui est mesurée en unités monétaires:
Après analyse, il est devenu clair pour nous que la précision est plus importante dans ce cas, car
nous supportons la perte maximale si nous qualifions par erreur un acheteur honnête de fraudeur.Le cours de notre solution a consisté en étapes classiques:
- Analyse de base des données
- Analyse des signes, de leurs statistiques descriptives et distributions
- Élimination des valeurs aberrantes
- Génération de personnages
- Création d'un modèle et définition des paramètres
- Validation et prévision finale
Les diapositives avec le contenu de notre solution sont disponibles sur:
www.docdroid.net/2XEDfYg/dmc-2019-1.pdfLe référentiel sur GitHub est ici:
github.com/Perevalov/dmc2019 (tout est dispersé sur différentes branches, jusqu'à ce qu'il soit temps de tout mettre en ordre)
Finales organisationnelles
Après avoir envoyé la décision finale début mai, nous avons commencé à attendre des résultats. Les conditions des organisateurs sont telles que les
équipes du
Top 10 sont invitées à une finale en personne à Berlin , qui se déroule dans le cadre de la conférence Retail Intelligence Summit 2019: Smart Decisions for Smart Retail.
Pour référence,
en 2019, 149 équipes de 114 universités situées dans 28 pays ont participé au DMC.Pour être honnête, nous n'espérions même pas atteindre la finale , mais maintenant, fin mai, cette chère lettre d'invitation arrive. De plus, tous les finalistes ont été invités à payer des dépenses pouvant aller jusqu'à 500 euros, et ils ont également proposé un hébergement dans un hôtel pour une nuit, où l'événement a eu lieu.
Sans hésitation, nous avons acheté des billets pour Berlin et sommes allés chercher des visas. Étant des étudiants pauvres, le montant des dépenses pour un voyage de 2 jours s'est avéré assez important pour nous. Le coût des billets Perm-Berlin-Perm et du traitement des visas s'élevait à environ 40 000 roubles. par personne, c'est un peu plus de 500 euros.
Puisque nous représentons notre université à l'événement, nous avons décidé d'en obtenir un soutien matériel. De plus, l'Université Polytechnique de Perm met en œuvre un programme de développement des relations russo-allemandes et soutient fortement les étudiants d'initiative (il nous a semblé que oui). Avec l'approbation et la signature du chef du département dans lequel nous étudions, nous sommes allés au département des sciences et de l'innovation. Il a commencé une épopée bureaucratique d'un mois, qui s'est terminée par ce qui suit:
"Il n'y a pas d'argent, mais vous tenez bon .
" Bien sûr, nous étions un peu contrariés, mais nous n'avons pas perdu courage. Maintenant, il est ridicule de lire diverses déclarations de la direction de notre université sur la «nécessité de soutenir les jeunes scientifiques» et autres bêtises. Eh bien, c'est une digression.
Nous avons obtenu des visas en seulement 2 semaines. Dans le même temps, nous avons préparé un rapport pour le discours et le 2 juillet au soir nous sommes allés à l'aéroport.
Performance à la finale de la Data Mining Cup et remise des prix
En arrivant à Berlin le 3 juillet au matin, nous sommes allés à l'hôtel nHow, où la conférence a eu lieu. Le niveau d'organisation, bien sûr, est élevé. En effet, le coût de participation était de 1000 euros par personne (pour nous c'est gratuit). Et voici à quoi ressemble l'hôtel:

Notre représentation était prévue à 16h30. Elle s'est déroulée dans la salle de conférence principale, naturellement en anglais. Soit dit en passant, la performance elle-même n'a pas été prise en compte dans la note finale, elle a été calculée uniquement sur la base du taux final, sur lequel seuls les organisateurs disposaient de données.
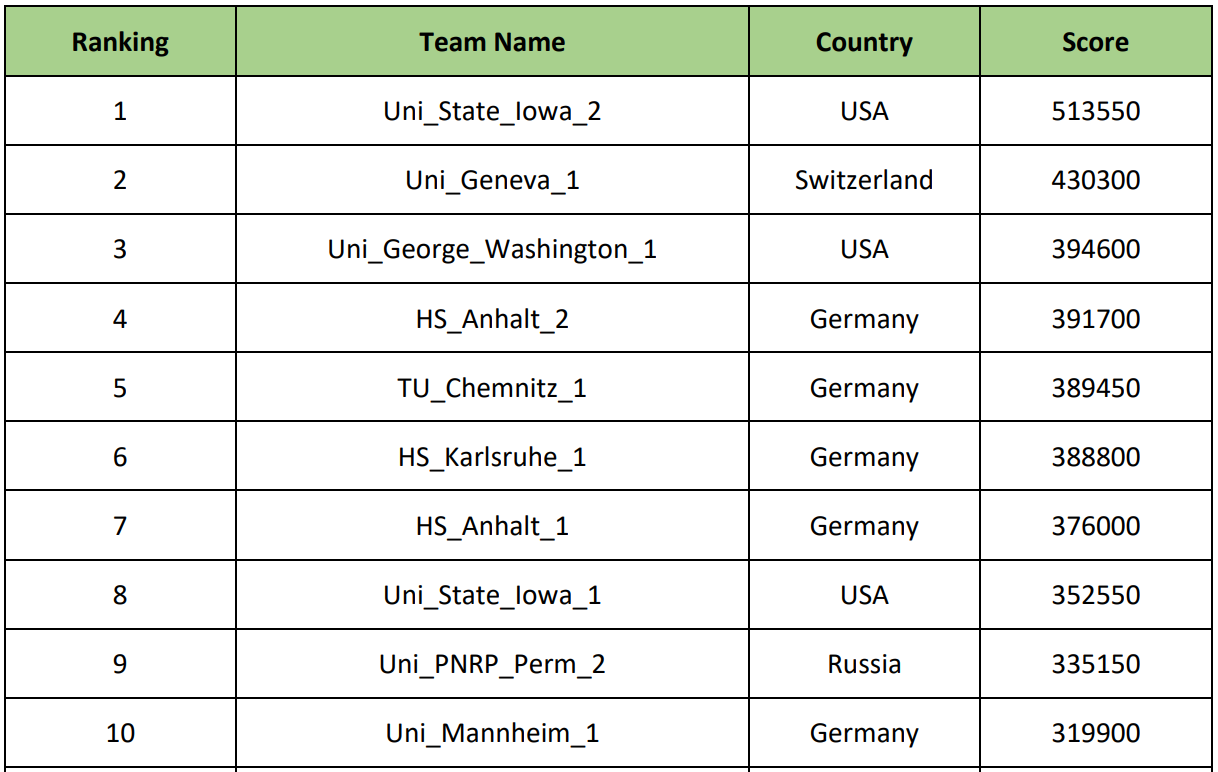
Parmi les 10 premières équipes se trouvaient des universités telles que l'Université George Washington (États-Unis), l'Université de Genève (Suisse), l'Université technologique de Chemnitz (Allemagne), l'Université de l'Iowa (États-Unis), etc. Et bien sûr, notre Perm National Research Polytechnic University.
Voici à quoi ressemblait la salle de conférence:

Un petit embarras était le fait que je devais parler non pas avec des diapositives, mais avec une affiche affichée à l'écran. Par conséquent, les performances des participants n'étaient pas suffisamment informatives. Cependant, il a été possible d'approcher et de voir l'affiche en papier de chacun des participants dans la salle de conférence. Fondamentalement, la plupart des gens ont utilisé l'
empilement, le mélange et l'assemblage (nous en sommes), certains participants ont également utilisé un
seuil augmenté pour les modèles de classification, quelques équipes ont réussi à ne pas générer du tout de fonctionnalités et ont construit le modèle sur la source.
Au fait, nous étions la plus petite équipe - seulement 2 personnes.
Après les représentations, un dîner de gala et une récompense ont commencé. Nous espérions des prix, mais nous nous sommes rendu compte que c'était improbable, alors notre désir banal était "au moins de ne pas avoir 10 ans". Il s'est avéré exactement ce que nous voulions - nous avons pris la 9ème place honorable. Naturellement, c'était un peu ennuyeux, mais le fait que nous soyons en finale parmi des universités aussi sérieuses en dit déjà long. Les gagnants étaient des participants de l'Université de l'Iowa (USA), bien que vous ne puissiez pas dire qu'ils venaient des États (voir photo):
 Les prix pour les 1ère, 2e et 3e places étaient respectivement de 2000, 1000 et 500 euros.
Les prix pour les 1ère, 2e et 3e places étaient respectivement de 2000, 1000 et 500 euros. La note finale est la suivante:
Conclusions
Nous n'avons pas regretté combien nous avons participé à ce concours. Au minimum, c'est une réalisation +1 dans le portefeuille, aux contacts les plus utiles avec les gens et l'occasion de représenter notre ville et notre pays lors d'un événement international.
Je conseille à tous les scientifiques de participer à de tels événements, c'est cool!