
Comment Dailymotion utilise Kubernetes: Déploiement d'applications
Chez Dailymotion, nous avons commencé à utiliser Kubernetes en production il y a 3 ans. Mais le déploiement d'applications sur plusieurs clusters est toujours un plaisir, donc au cours des dernières années, nous avons essayé d'améliorer nos outils et nos flux de travail.
Où ça a commencé
Ici, nous montrons comment nous déployons nos applications sur plusieurs clusters Kubernetes à travers le monde.
Pour déployer plusieurs objets Kubernetes à la fois, nous utilisons Helm et tous nos graphiques sont stockés dans un référentiel git. Pour déployer la pile d'applications complète à partir de plusieurs services, nous utilisons ce que l'on appelle le graphique généralisé. En substance, il s'agit d'un graphique qui déclare les dépendances et vous permet d'initialiser l'API et ses services avec une seule commande.
Nous avons également écrit un petit script Python sur Helm pour effectuer des vérifications, créer des graphiques, ajouter des secrets et déployer des applications. Toutes ces tâches sont effectuées sur la plate-forme CI centrale à l'aide de l'image Docker.
Venons-en au fait.
Remarque Lorsque vous lisez ceci, le premier candidat à la sortie de Helm 3 a déjà été annoncé. La version principale contient un ensemble d'améliorations conçues pour résoudre certains des problèmes que nous avons rencontrés dans le passé.
Flux de travail de développement de graphiques
Pour les applications, nous utilisons la ramification et nous avons décidé d'appliquer la même approche aux graphiques.
- La branche dev est utilisée pour créer des graphiques qui seront testés sur des clusters de développement.
- Lorsque la demande de pool est transférée au maître , elles sont archivées dans le transfert.
- Enfin, nous créons une demande de pool pour pousser les modifications dans la branche prod et les appliquer en production.
Chaque environnement possède son propre référentiel privé qui stocke nos graphiques, et nous utilisons Chartmuseum avec des API très utiles. Ainsi, nous garantissons une stricte isolation entre les environnements et vérifions les cartes en conditions réelles avant de les utiliser en production.
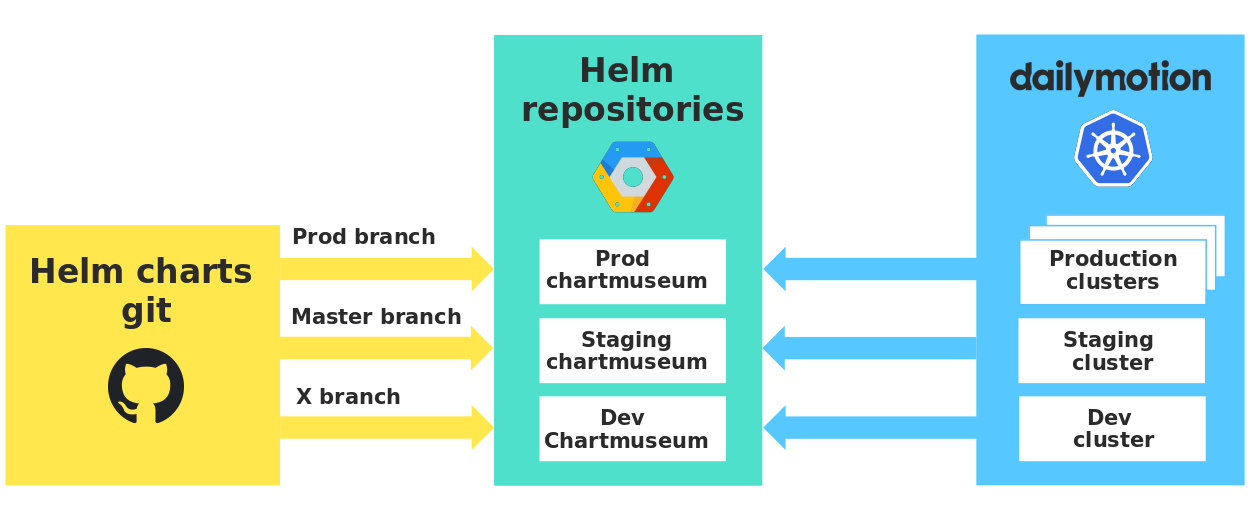
Référentiels de graphiques dans différents environnements
Il est à noter que lorsque les développeurs envoient la branche dev, une version de leur graphique est automatiquement envoyée au dev Chartmuseum. Ainsi, tous les développeurs utilisent le même référentiel de développement, et vous devez soigneusement indiquer votre version du graphique afin de ne pas utiliser accidentellement les modifications de quelqu'un d'autre.
De plus, notre petit script Python vérifie les objets Kubernetes par rapport aux spécifications Kubernetes OpenAPI à l'aide de Kubeval avant de les publier sur Chartmusem.
Workflow de développement de graphique général
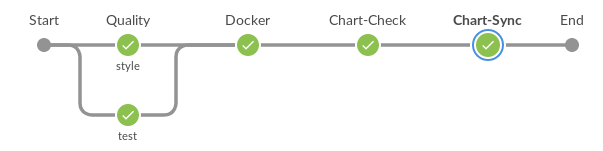
- Mise en place de la tâche pipeline selon la spécification gazr.io pour le contrôle qualité (peluche, test unitaire).
- Soumettre une image docker avec les outils Python qui déploient nos applications.
- Configuration de l'environnement par le nom de la succursale.
- Vérifiez les fichiers yaml Kubernetes avec Kubeval.
- Augmentez automatiquement la version du graphique et de ses graphiques parents (graphiques qui dépendent du graphique modifié).
- Soumettre au Chartmuseum un graphique correspondant à son environnement
Gestion des différences de cluster
Fédération des clusters
Il fut un temps où nous utilisions Kubernetes Cluster Federation , où vous pouviez déclarer des objets Kubernetes à partir d'un point de terminaison d'API. Mais il y avait des problèmes. Par exemple, certains objets Kubernetes n'ont pas pu être créés à l'extrémité de la fédération, il était donc difficile de gérer les objets combinés et d'autres objets pour des clusters individuels.
Pour résoudre le problème, nous avons commencé à gérer les clusters de manière indépendante, ce qui a grandement simplifié le processus (nous avons utilisé la première version de la fédération; dans la seconde, quelque chose pouvait changer).
Notre plateforme est désormais distribuée dans 6 régions - 3 localement et 3 dans le cloud.
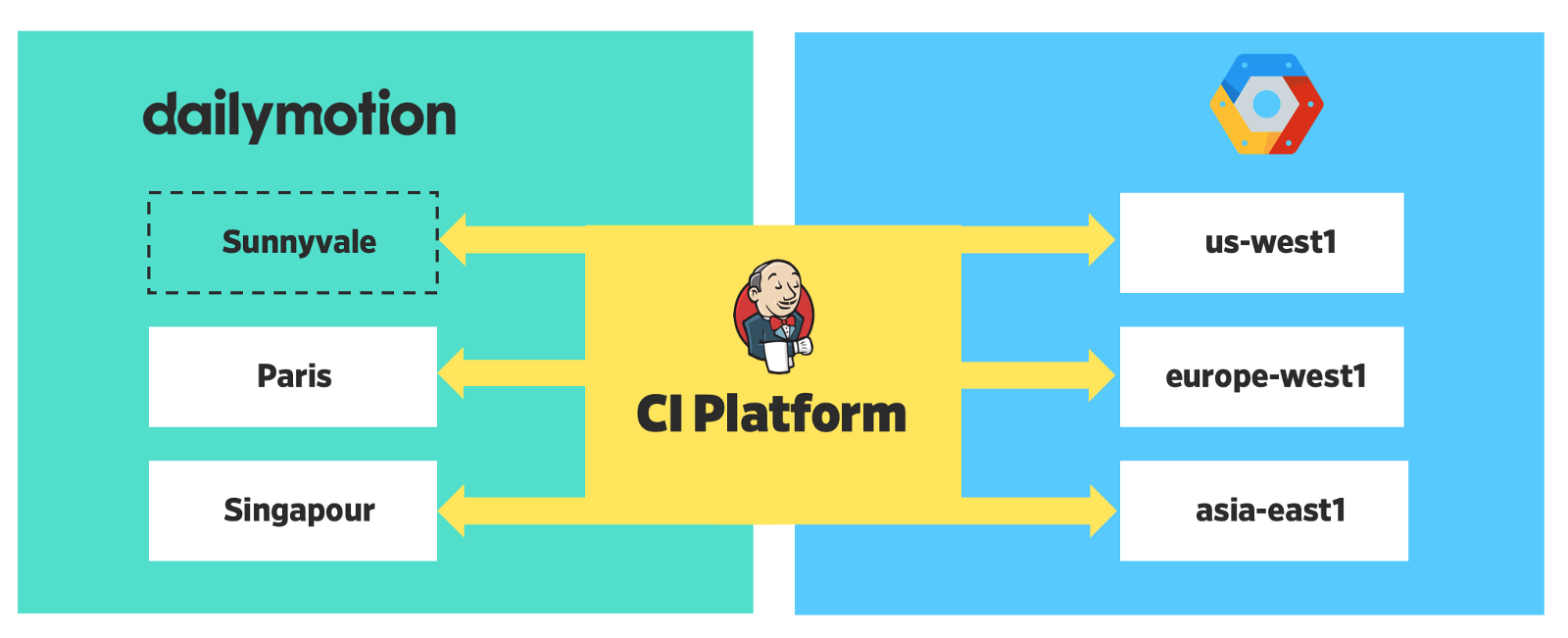
Déploiement distribué
Valeurs globales de barre
4 valeurs globales de Helm vous permettent de déterminer les différences entre les clusters. Pour tous nos graphiques, il existe des valeurs par défaut minimales.
global: cloud: True env: staging region: us-central1 clusterName: staging-us-central1
Valeurs globales
Ces valeurs aident à déterminer le contexte de nos applications et sont utilisées pour différentes tâches: surveillance, traçage, journalisation, appels externes, mise à l'échelle, etc.
- «Cloud»: nous avons une plateforme hybride Kubernetes. Par exemple, notre API est déployée dans les zones GCP et dans nos centres de données.
- «Env»: certaines valeurs peuvent varier pour les environnements non fonctionnels. Par exemple, les définitions de ressources et les configurations de mise à l'échelle automatique.
- «Région»: ces informations aident à déterminer l'emplacement du cluster et peuvent être utilisées pour déterminer les points de terminaison les plus proches pour les services externes.
- «ClusterName»: si et quand nous voulons déterminer la valeur d'un cluster individuel.
Voici un exemple concret:
{{/* Returns Horizontal Pod Autoscaler replicas for GraphQL*/}} {{- define "graphql.hpaReplicas" -}} {{- if eq .Values.global.env "prod" }} {{- if eq .Values.global.region "europe-west1" }} minReplicas: 40 {{- else }} minReplicas: 150 {{- end }} maxReplicas: 1400 {{- else }} minReplicas: 4 maxReplicas: 20 {{- end }} {{- end -}}
Exemple de modèle de barre
Cette logique est définie dans le modèle d'assistance afin de ne pas obstruer Kubernetes YAML.
Annonce de candidature
Nos outils de déploiement sont basés sur plusieurs fichiers YAML. Voici un exemple de la façon dont nous déclarons un service et sa topologie de mise à l'échelle (nombre de répliques) dans un cluster.
releases: - foo.world foo.world: # Release name services: # List of dailymotion's apps/projects foobar: chart_name: foo-foobar repo: git@github.com:dailymotion/foobar contexts: prod-europe-west1: deployments: - name: foo-bar-baz replicas: 18 - name: another-deployment replicas: 3
Définition du service
Il s'agit d'un diagramme de toutes les étapes qui définissent notre flux de travail de déploiement. La dernière étape déploie l'application sur plusieurs clusters de travail simultanément.
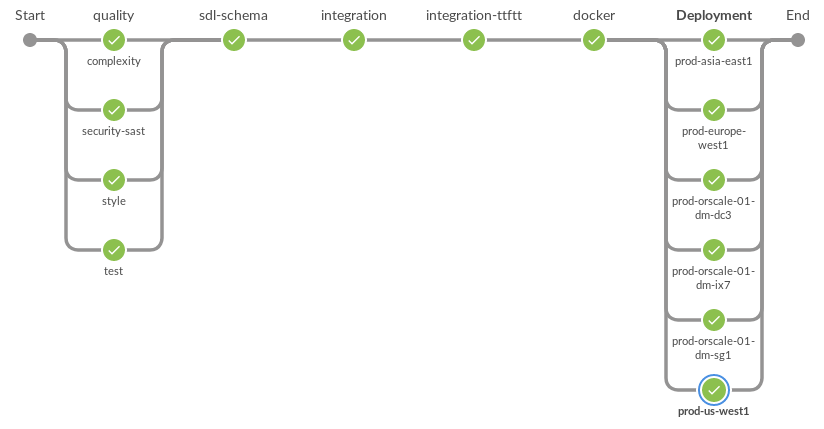
Étapes de déploiement de Jenkins
Et les secrets?
En termes de sécurité, nous gardons une trace de tous les secrets de divers endroits et les stockons dans le référentiel unique de Vault à Paris.
Nos outils de déploiement extraient les valeurs des secrets de Vault et, le moment venu, les insèrent dans Helm.
Pour ce faire, nous avons déterminé la correspondance entre les secrets de Vault et les secrets dont nos applications ont besoin:
secrets: - secret_id: "stack1-app1-password" contexts: - name: "default" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password" - name: "cluster1" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password"
- Nous avons identifié les règles générales que vous devez suivre lors de l'écriture de secrets dans Vault.
- Si le secret fait référence à un contexte ou à un cluster spécifique , vous devez ajouter une entrée spécifique. (Ici, le contexte de cluster1 a sa propre valeur pour le mot de passe secret stack-app1).
- Sinon, la valeur par défaut est utilisée.
- Pour chaque élément de cette liste, une paire clé-valeur est insérée dans le secret Kubernetes . Par conséquent, le schéma secret de nos graphiques est très simple.
apiVersion: v1 data: {{- range $key,$value := .Values.secrets }} {{ $key }}: {{ $value | b64enc | quote }} {{ end }} kind: Secret metadata: name: "{{ .Chart.Name }}" labels: chartVersion: "{{ .Chart.Version }}" tillerVersion: "{{ .Capabilities.TillerVersion.SemVer }}" type: Opaque
Problèmes et limitations
Travailler avec plusieurs référentiels
Maintenant, nous partageons le développement de graphiques et d'applications. Cela signifie que les développeurs doivent travailler dans deux référentiels git: l'un pour l'application et le second pour déterminer son déploiement dans Kubernetes. 2 référentiels git sont 2 flux de travail et il est facile pour un débutant de se perdre.
La gestion des graphiques résumés est gênante
Comme nous l'avons déjà dit, les graphiques génériques sont très pratiques pour définir des dépendances et déployer rapidement plusieurs applications. Mais nous utilisons --reuse-values pour éviter de transmettre toutes les valeurs à chaque fois que nous déployons l'application incluse dans ce graphique généralisé.
Dans le flux de travail de livraison continue, nous n'avons que deux valeurs qui changent régulièrement: le nombre de répliques et la balise d'image (version). D'autres valeurs plus stables sont modifiées manuellement, ce qui est plutôt compliqué. De plus, une erreur dans le déploiement d'un graphique généralisé peut entraîner de graves échecs, comme nous l'avons vu de notre propre expérience.
Mise à jour de plusieurs fichiers de configuration
Lorsqu'un développeur ajoute une nouvelle application, il doit modifier plusieurs fichiers: l'annonce de l'application, la liste des secrets, l'ajout de l'application selon qu'elle est incluse dans le tableau généralisé.
Autorisations Jenkins trop étendues dans Vault
Nous avons maintenant un AppRole qui lit tous les secrets de Vault.
Le processus de restauration n'est pas automatisé
Pour revenir en arrière, vous devez exécuter la commande sur plusieurs clusters, ce qui est lourd d'erreurs. Nous effectuons cette opération manuellement pour nous assurer que l'identifiant de version correct est spécifié.
Nous évoluons vers GitOps
Notre objectif
Nous voulons retourner le graphique au référentiel de l'application qu'il déploie.
Le workflow sera le même que pour le développement. Par exemple, lorsqu'une branche est envoyée à l'assistant, le déploiement démarre automatiquement. La principale différence entre cette approche et le workflow actuel sera que tout sera géré dans git (l'application elle-même et comment la déployer dans Kubernetes).
Il y a plusieurs avantages:
- Beaucoup plus clair pour le développeur. Il est plus facile d'apprendre à appliquer des modifications au graphique local.
- Une définition de déploiement de service peut être spécifiée à l' emplacement du code de service.
- Gestion de la suppression des graphiques généralisés . Le service aura sa propre version de Helm. Cela vous permettra de gérer le cycle de vie de l'application (rollback, mise à niveau) au plus petit niveau, afin de ne pas affecter les autres services.
- Les avantages de git pour la gestion des graphiques sont les suivants: annulation des modifications, piste d'audit, etc. Si vous devez annuler une modification d'un graphique, vous pouvez le faire avec git. Le déploiement démarre automatiquement.
- Vous pourriez envisager d'améliorer votre flux de travail de développement avec des outils comme Skaffold , avec lesquels les développeurs peuvent tester les modifications dans un contexte de production.
Migration en deux étapes
Nos développeurs utilisent ce flux de travail depuis 2 ans maintenant, nous avons donc besoin de la migration la plus indolore. Par conséquent, nous avons décidé d'ajouter une étape intermédiaire sur le chemin de l'objectif.
La première étape est simple:
- Nous conservons une structure similaire pour configurer le déploiement d'applications, mais dans le même objet nommé DailymotionRelease.
apiVersion: "v1" kind: "DailymotionRelease" metadata: name: "app1.ns1" environment: "dev" branch: "mybranch" spec: slack_channel: "#admin" chart_name: "app1" scaling: - context: "dev-us-central1-0" replicas: - name: "hermes" count: 2 - context: "dev-europe-west1-0" replicas: - name: "app1-deploy" count: 2 secrets: - secret_id: "app1" contexts: - name: "default" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password" - name: "dev-europe-west1-0" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password"
- 1 version par application (sans graphiques généralisés).
- Graphiques dans le référentiel d'applications git.
Nous avons parlé avec tous les développeurs, donc le processus de migration a déjà commencé. La première phase est toujours contrôlée à l'aide de la plateforme CI. Bientôt, j'écrirai un autre article sur la deuxième étape: comment nous sommes passés au flux de travail GitOps avec Flux . Je vais vous dire comment nous nous sommes tous installés et quelles difficultés nous avons rencontrées (plusieurs référentiels, secrets, etc.). Suivez l'actualité.
Ici, nous avons essayé de décrire nos progrès dans le flux de travail de déploiement d'applications au cours des dernières années, ce qui a conduit à des réflexions sur l'approche GitOps. Nous n'avons pas atteint l'objectif et rendrons compte des résultats, mais maintenant nous sommes convaincus que nous l'avons fait correctement lorsque nous avons décidé de tout simplifier et de le rapprocher des habitudes des développeurs.