Présentation
Il y a quelque temps, j'avais besoin de résoudre le problème de la segmentation des points dans un nuage de points (les nuages de points sont des données obtenues à partir de lidars).
Exemples de données et tâche à résoudre:
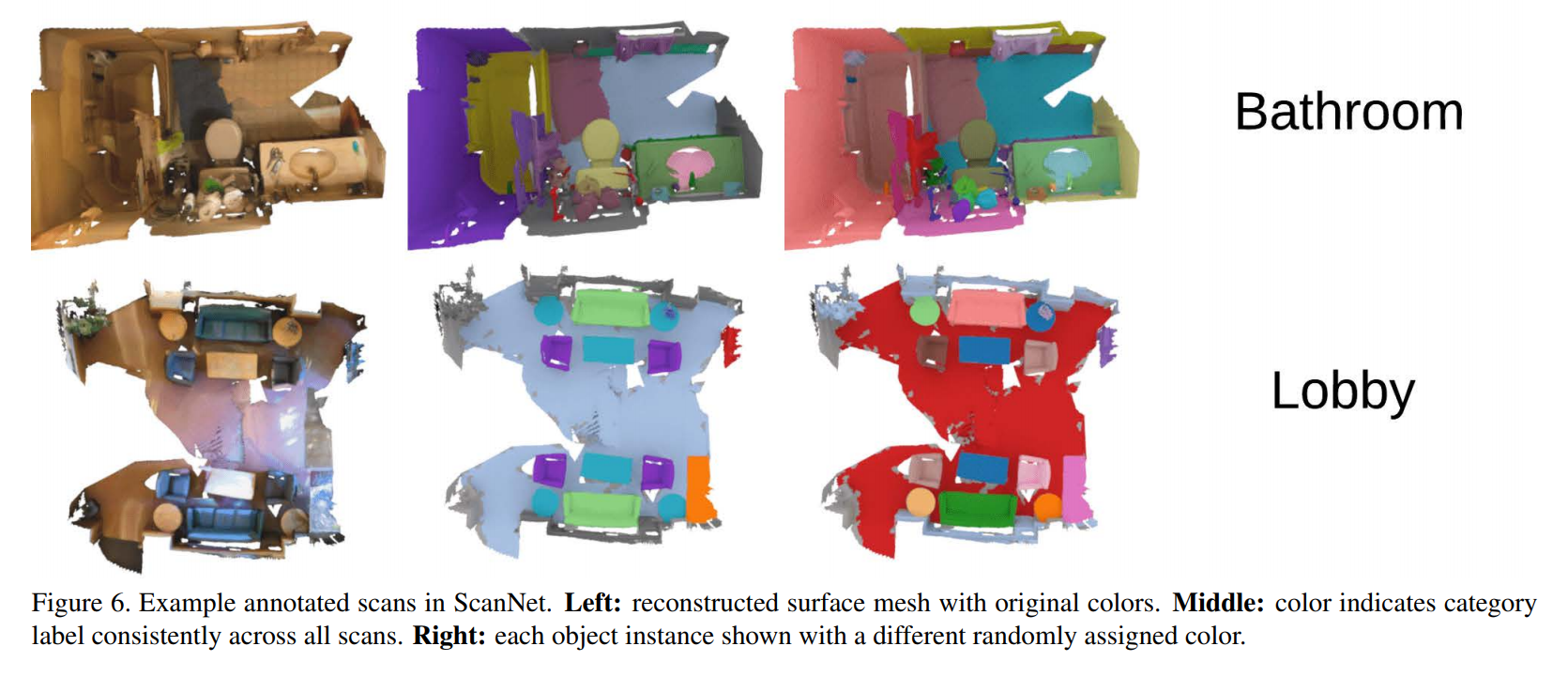
La recherche d'un aperçu général des méthodes existantes n'a pas réussi, j'ai donc dû collecter moi-même des informations. Vous pouvez voir le résultat: voici les articles les plus importants et les plus intéressants (à mon avis) des dernières années. Tous les modèles considérés résolvent le problème de la segmentation d'un nuage de points (à quelle classe appartient chaque point).
Cet article sera utile à ceux qui connaissent les réseaux de neurones et qui souhaitent comprendre comment les appliquer à des données non structurées (par exemple, des graphiques).
Ensembles de données existants
Maintenant, dans le domaine public, il existe les ensembles de données suivants sur ce sujet:
Fonctionnalités de travail avec les nuages de points
Les réseaux de neurones sont arrivés dans ce domaine tout récemment. Et les architectures standard comme les réseaux entièrement connectés et convolutionnels ne sont pas applicables pour résoudre ce problème. Pourquoi?
Parce que l'ordre des points n'est pas important ici. Un objet est un ensemble de points et peu importe l'ordre dans lequel ils sont affichés. Si chaque pixel a sa place dans l'image, alors nous pouvons mélanger les points en toute sécurité et l'objet ne change pas. Le résultat des réseaux de neurones standard, au contraire, dépend de l'emplacement des données. Si vous mélangez des pixels sur l'image, vous obtenez un nouvel objet.
Voyons maintenant comment les réseaux de neurones se sont adaptés pour résoudre ce problème.
Articles les plus importants
Il n'y a pas beaucoup d'architectures de base dans ce domaine. Si vous avez l'intention de travailler avec des graphiques ou des données non structurées, vous devez avoir une idée des modèles suivants:
Examinons-les plus en détail.
- PointNet: Deep Learning sur les ensembles de points pour la classification et la segmentation 3D
Pionniers dans l'utilisation de données non structurées.
- comment ils décident: L'article décrit deux modèles: pour la segmentation des points et la classification d'un objet. La partie générale se compose des blocs suivants:
- un réseau de détermination de la transformation (translation du repère), qui s'applique alors à tous les points
- transformation appliquée à chaque point individuellement (percepteur régulier)
- maxpool, qui combine des informations de différents points et crée un vecteur d'entité global pour l'objet entier.
- alors les différences entre les modèles commencent:
- modèle de classification: un vecteur d'entité global va à l'entrée d'une couche entièrement connectée pour déterminer la classe de l'ensemble du nuage de points
- modèle de segmentation: le vecteur d'entité global et les entités calculées pour chaque point vont à l'entrée de la couche entièrement connectée qui définit la classe pour chaque point.
- code



Articles basés sur PointNet et PointNet ++:
La plupart des articles diffèrent en termes de nombre d'erreurs ou de profondeur et de complexité des blocs complexes.
PointWise: un réseau d'apprentissage des fonctionnalités point par point non supervisé
Caractéristique du travail - formation sans professeur
- comment ils décident: pour chaque point, le vecteur des plongements est formé, par lequel ils sont ensuite segmentés.
Le postulat principal de l'article est que les objets similaires devraient avoir des encastrements similaires (par exemple, deux pieds de chaise différents), malgré leur éloignement. PointNet est utilisé comme modèle de base. La principale innovation est la fonction d'erreur. Il se compose de deux parties: les erreurs de reconstruction et les erreurs de lissage.
L'erreur de reconstruction utilise des informations de contexte de point. Sa tâche est de rendre similaires les plongements de points avec le même contexte géométrique. Pour le calculer, en fonction du vecteur d'intégration du point sélectionné, de nouveaux points proches sont générés. En d'autres termes, la description de la fonction du point doit contenir des informations sur la forme de l'objet autour du point. Ensuite, considérez combien les points générés tombent de la forme réelle de l'objet.
L'erreur de lissage est nécessaire pour que les incrustations soient similaires aux points adjacents et différentes aux points distants. La plus belle chose ici est la mesure de la proximité, non seulement comme la norme entre deux points dans l'espace euclidien, mais en comptant la distance à travers les points de l'objet. Pour chaque point, un point est sélectionné à partir de k le plus proche et de k plus loin.
L'incorporation actuelle devrait être plus proche du minimum le plus proche d'une certaine marge qu'auparavant.
SGPN: Réseau de proposition de groupe de similarité pour la segmentation d'instance de nuage de points 3D
- comment ils décident: comme dans PointWise, la chose la plus intéressante dans le calcul de l'erreur est ici. PointNet ++ est la base, nous considérons d'abord le vecteur de caractéristique et l'objet appartiennent à chaque point individuellement, par analogie avec PointNet ++.
Ensuite, en fonction des caractéristiques, nous considérons 3 matrices (similitude, confiance et segmentation).
L'erreur d'apprentissage sera la somme de trois erreurs calculées par les matrices correspondantes: L = L1 + L2 + L3
Soit N le nombre de points
Matrice de similarité - carré, taille N * N. L'élément à l'intersection de la i-ème ligne et de la j-ème colonne indique si ces points appartiennent ou non au même objet. Les points appartenant au même objet doivent avoir des vecteurs de caractéristiques similaires. Les éléments de la matrice peuvent prendre l'une des trois valeurs suivantes: les points i et j appartiennent à un objet, les points appartiennent à une classe d'objets, mais à des objets différents (à la fois telle et telle chaise, mais les chaises sont différentes), ou ce sont généralement des points provenant d'objets de classes différentes. Cette matrice est calculée selon les vraies valeurs.

La matrice de confiance est un vecteur de longueur N.Pour chaque point, on considère l'intersection sur l'union (IoU) entre l'ensemble des points qui appartiennent à l'objet selon le travail de notre algorithme et l'ensemble des points qui appartiennent réellement à l'objet avec le point courant. L'erreur est simplement la norme L2 entre la vérité et la matrice calculée. Autrement dit, le réseau tente de prédire dans quelle mesure il est sûr de la prédiction de classe pour les points sur un objet.
La matrice de segmentation a une taille - N * le nombre de classes. L'erreur ici est considérée comme une entropie croisée dans le problème de classification multiclasse. - code

- Sachez ce que font vos voisins: segmentation sémantique 3D des nuages de points
- comment ils décident: Au début, ils considèrent les signes depuis longtemps, plus compliqués que dans PointNet, avec un tas de connexions résiduelles et de montants, mais en général - la même chose. Une légère différence - ils comptent les signes pour chaque point en coordonnées globales et locales.
La principale différence ici est à nouveau le nombre d'erreurs. Ce n'est pas une entropie croisée standard, mais la somme de deux erreurs:
- perte de distance par paire - les points d'un objet doivent être plus proches que τ_near et les points d'objets différents doivent être plus longs que τ_far .
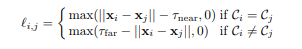
- perte de centroïde - les points d'un objet doivent être proches les uns des autres
Articles basés sur DGCNN:
DGCNN a été publié récemment (2018), il y a donc peu d'articles basés sur cette architecture. Je veux attirer votre attention sur une chose:
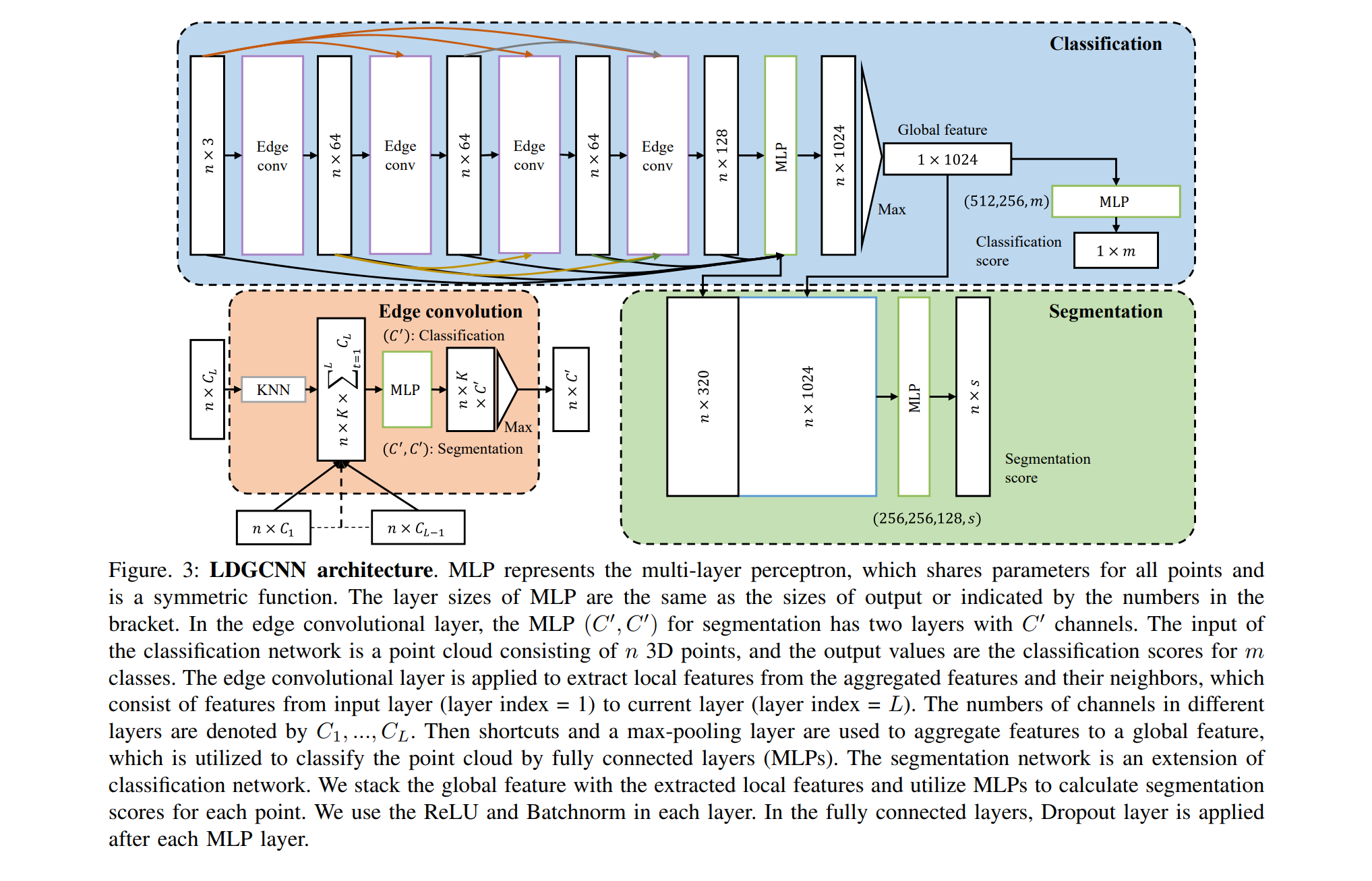
Conclusion
Vous trouverez ici de brèves informations sur les méthodes modernes de résolution des problèmes de classification et de segmentation dans les nuages de points. Il existe deux modèles principaux (PointNet ++, DGCNN), dont les modifications sont maintenant utilisées pour résoudre ces problèmes. Le plus souvent, pour la modification, la fonction d'erreur est modifiée et ces architectures sont compliquées par l'ajout de couches et de liens.