
Aujourd'hui, la plupart des systèmes d'information sont des solutions complexes avec une architecture assez complexe et un grand nombre de dépendances mutuelles. Pendant le fonctionnement de ces systèmes, au moment des pics de charge, certains modules peuvent tomber en panne ou ne pas fonctionner correctement. Dans ce cas, le système cesse d'être stable et peut cesser de traiter correctement toutes les demandes entrantes. Pour assurer un fonctionnement stable du système, différentes stratégies peuvent être mises en œuvre.
Dans certains cas (si cela est autorisé), la traduction du système dans le soi-disant. "Mode sans échec". Dans ce mode, le système peut traiter un plus grand nombre d'appels avec une légère diminution de la précision des résultats du traitement des requêtes. Dans d'autres cas, la mise à l'échelle des ressources informatiques et l'augmentation du nombre de modules système individuels chargés du traitement des demandes entrantes peuvent aider. Dans ce cas, la tâche la plus importante est de
déterminer l'état du système , en fonction de laquelle, l'une ou l'autre action doit déjà être entreprise pour stabiliser son fonctionnement.
Dans mes projets, j'ai résolu un problème similaire de diverses manières depuis un certain temps. Depuis que j'étais à l'université, j'avais un petit projet écrit en .NET 4.0, à partir duquel de temps en temps je prenais de petits morceaux de code pour de vrais projets. J'ai longtemps prévu de refactoriser ce projet, de le nettoyer et de l'organiser sous la forme d'un mini-framework séparé qui nous permet de résoudre magnifiquement et de manière minimaliste le problème de la surveillance de l'état du système. Après avoir passé plusieurs soirées et quelques jours de congé, j'ai mis ce code en ordre et l'ai publié sur
GitHub . De plus, je propose d'examiner plus en détail ce qui et comment est mis en œuvre dans ce projet.
Pour déterminer la nécessité de modifier le mode de fonctionnement du système, il est proposé d’utiliser une approche utilisant des «capteurs» et des «observateurs» virtuels.
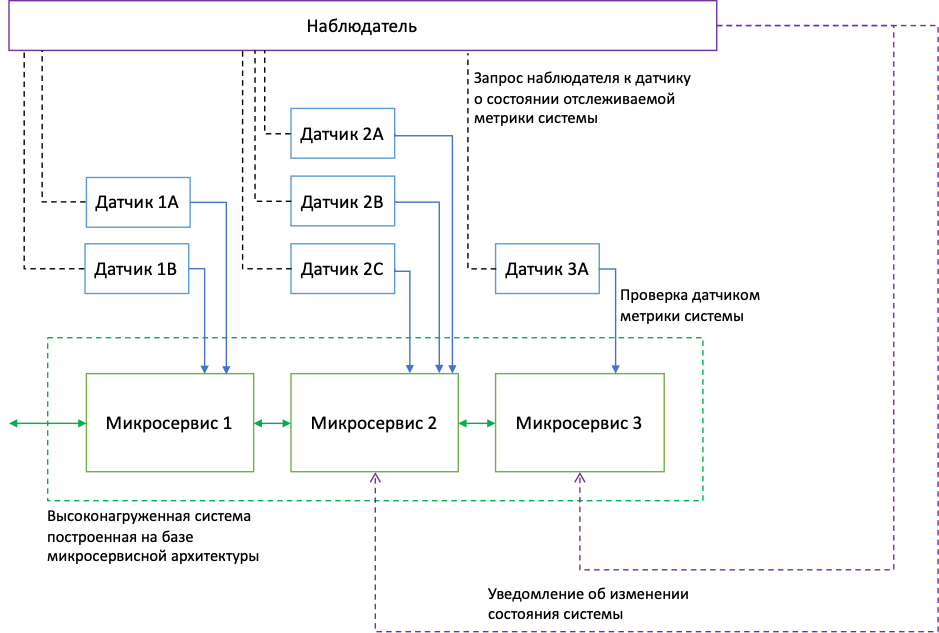
▌ Entités et définitions
Entités de base à utiliser:
- Capteur - est chargé de vérifier l'état de l'un des indicateurs du système;
- Observateur - interroge un ou plusieurs capteurs. Change son état en fonction des lectures actuelles des capteurs;
- Calculatrice d'état - calcule l'état actuel en fonction du journal des métriques.
- Journal d'état - un ensemble d'indicateurs pour chacun des capteurs indiquant le temps d'interrogation.
Pour chaque abstraction, il existe une implémentation de base, ainsi que des mécanismes pour une expansion simple et pratique. Examinons-les plus en détail.
Capteur
Interface
IProbe de base. Les classes implémentant IProbe fournissent, sur demande, la valeur des paramètres système qu'ils observent, ou un module / service spécifique.
public interface IProbe { string Name { get; } Task<ProbeResult> Check(); }
À la suite de la méthode
Check , l'instance IProbe renvoie une structure ProbeResult
public struct ProbeResult { public string ProbeName { get; set; } public DateTime Time { get; set; } public bool Success { get; set; } public string Data { get; set; } public Exception Exception { get; set; } public override string ToString() => $"{Time}: {Success}"; }
où le champ Success détermine si le paramètre a été testé avec succès du point de vue du capteur, et les champs Data et Exception peuvent stocker des informations supplémentaires au cas où cela serait nécessaire pour le débogage ou la journalisation.
Observateur
L'interface de base d'
ISpectator . Il surveille le système, génère des événements au moment de changer l'état du système pour notifier tous les modules qui sont abonnés à ces événements. Il utilise une instance d'une classe qui implémente l'interface IStateEvaluator pour calculer l'état actuel.
public interface ISpectator<TState> where TState : struct, IConvertible { event EventHandler<StateEventArgs<TState>> StateChanged; event EventHandler<HealthCheckEventArgs> HealthChecked; TState State { get; } TimeSpan Uptime { get; } string Name { get; } void AddProbe(IProbe probe); void CheckHealth(); }
Lors de chaque interrogation de capteur, l'observateur déclenche l'événement StateChanged et un objet de type
StateEventArgs est transmis aux abonnés de cet événement, qui contient des informations sur l'état actuel du système.
Calculatrice d'état
L'interface
IEvaluator de base. Calcule l'état actuel du système en fonction du journal d'état du capteur.
public interface IStateEvaluator<TState> { TState Evaluate( TState currentState, DateTime stateChangedLastTime, IReadOnlyCollection<JournalRecord> journal); }
Journal d'état
Une collection d'instances de la structure JournalRecord. L'instance JournalRecord stocke des informations sur tous les capteurs interrogés au moment où le sondage a été lancé par l'observateur.
public struct JournalRecord { public JournalRecord(DateTime time, IEnumerable<ProbeResult> values) { Time = time; Values = values.ToImmutableList(); } public DateTime Time { get; set; } public IReadOnlyCollection<ProbeResult> Values { get; set; } public override string ToString() => $"{Time}: [{string.Join(",", Values)}]"; }
▌ Comment ça marche
Le processus de calcul de l'état du système peut être décrit comme suit: chacun des capteurs intégrés dans le système peut déterminer l'un des paramètres du système / module / service observé. Par exemple, il peut être en train de fixer le nombre de requêtes actives externes à l'API, la quantité de RAM utilisée, le nombre d'entrées dans le cache, etc.
Chaque capteur peut être affecté à un ou plusieurs observateurs. Chaque observateur peut travailler avec un ou plusieurs capteurs. L'observateur doit implémenter l'interface ISpectator et générer des événements en cas de changement d'état ou d'interrogation des capteurs.
Lors de la prochaine vérification de l'état du système, l'observateur interroge tous ses «capteurs», formant un réseau pour l'écriture dans le journal d'état. Si l'état du système a changé, l'observateur génère un événement approprié. Les abonnés aux événements qui reçoivent des informations sur la modification peuvent modifier les paramètres de fonctionnement du système. De plus, pour déterminer l'état du système, on peut utiliser des "calculateurs" de différents types.
Modes de fonctionnement synchrones et asynchrones
Considérons deux scénarios principaux dans lesquels l'observateur lance une étude des «capteurs».
Mode synchrone
Un relevé des capteurs suivi d'un recalcul de l'état du système est provoqué par l'appel direct d'un des modules du système à l'observateur.
Dans ce cas, l'observateur et les capteurs fonctionnent dans le même fil. L'erreur de calcul de l'état du système est effectuée dans le cadre d'une opération au sein du système.
Le projet a déjà une implémentation de base d'un tel observateur -
SpectatorBase .
Afficher le code public class SpectatorBase<TState> : ISpectator<TState> where TState : struct, IConvertible { private TState _state; private readonly IList<IProbe> _probes; private readonly IStateEvaluator<TState> _stateEvaluator; private readonly List<JournalRecord> _journal; private readonly ReaderWriterLockSlim _journalLock; private readonly ReaderWriterLockSlim _stateLock; private readonly Stopwatch _stopwatch; public event EventHandler<StateEventArgs<TState>> StateChanged; public event EventHandler<HealthCheckEventArgs> HealthChecked; public virtual TState State { get { _stateLock.EnterReadLock(); try { return _state; } finally { _stateLock.ExitReadLock(); } } } public TimeSpan Uptime => _stopwatch.Elapsed; public string Name { get; set; } public IReadOnlyCollection<JournalRecord> Journal { get { _journalLock.EnterReadLock(); try { return _journal; } finally { _journalLock.ExitReadLock(); } } } public DateTime StateChangedDate { get; private set; } public TimeSpan RetentionPeriod { get; private set; } public SpectatorBase(IStateEvaluator<TState> stateEvaluator, TimeSpan retentionPeriod, TState initialState) { RetentionPeriod = retentionPeriod; _state = initialState; StateChangedDate = DateTime.UtcNow; _stateEvaluator = stateEvaluator; _stopwatch = Stopwatch.StartNew(); _probes = new List<IProbe>(); _journal = new List<JournalRecord>(); _journalLock = new ReaderWriterLockSlim(); _stateLock = new ReaderWriterLockSlim(); } public void AddProbe(IProbe probe) => _probes.Add(probe); protected virtual void ChangeState(TState state, IEnumerable<string> failedProbes) { _stateLock.EnterWriteLock(); try { _state = state; } finally { _stateLock.ExitWriteLock(); } StateChangedDate = DateTime.UtcNow; StateChanged?.Invoke(this, new StateEventArgs<TState>(state, StateChangedDate, failedProbes)); } public virtual void CheckHealth() { var results = new Stack<ProbeResult>(); var tasks = _probes .Select(async o => { results.Push(await o.Check().ConfigureAwait(false)); }) .ToArray(); Task.WaitAll(tasks); var now = DateTime.UtcNow; _journalLock.EnterWriteLock(); try {
Mode asynchrone
Dans ce cas, l'interrogation des capteurs se produit de manière asynchrone à partir des processus du système et peut être effectuée dans un thread séparé. La mise en œuvre de base d'un tel observateur est également déjà un projet -
AutomatedSpectator .
Afficher le code public class AutomatedSpectator<TState> : SpectatorBase<TState>, IAutomatedSpectator<TState> where TState : struct, IConvertible { public TimeSpan CheckHealthPeriod { get; } private readonly System.Timers.Timer _timer; public AutomatedSpectator( TimeSpan checkHealthPeriod, TimeSpan retentionPeriod, IStateEvaluator<TState> stateEvaluator, TState initialState) : base(stateEvaluator, retentionPeriod, initialState) { CheckHealthPeriod = checkHealthPeriod; _timer = new System.Timers.Timer(CheckHealthPeriod.TotalMilliseconds); _timer.Elapsed += (sender, args) => CheckHealth(); _timer.AutoReset = true; } public void Start() => _timer.Start(); }
▌ Conclusion
L'utilisation de X.Spectator m'a aidé personnellement dans plusieurs projets très chargés pour augmenter considérablement la stabilité d'un certain nombre de services. Le meilleur cadre proposé a fait ses preuves lorsqu'il est mis en œuvre dans des systèmes distribués construits sur la base d'une architecture de microservices. L'option d'intégration la plus optimale consiste à utiliser le principe d'inversion de contrôle, à savoir l'implémentation de dépendances, lorsque le processus d'implémentation de capteurs est implémenté à l'aide d'un conteneur IoC, et les observateurs sont présentés sous la forme de singletones, où une seule instance de chacun des observateurs est accessible par différentes classes de modules et de services.
▌ Liens et informations utiles
→
Dépôt de projets→
Exemples→
Package NuGet