GitHub héberge plus de 300 langages de programmation - des langages couramment utilisés tels que Python, Java et Javascript aux langages ésotériques tels que
Befunge , connus uniquement des très petites communautés.
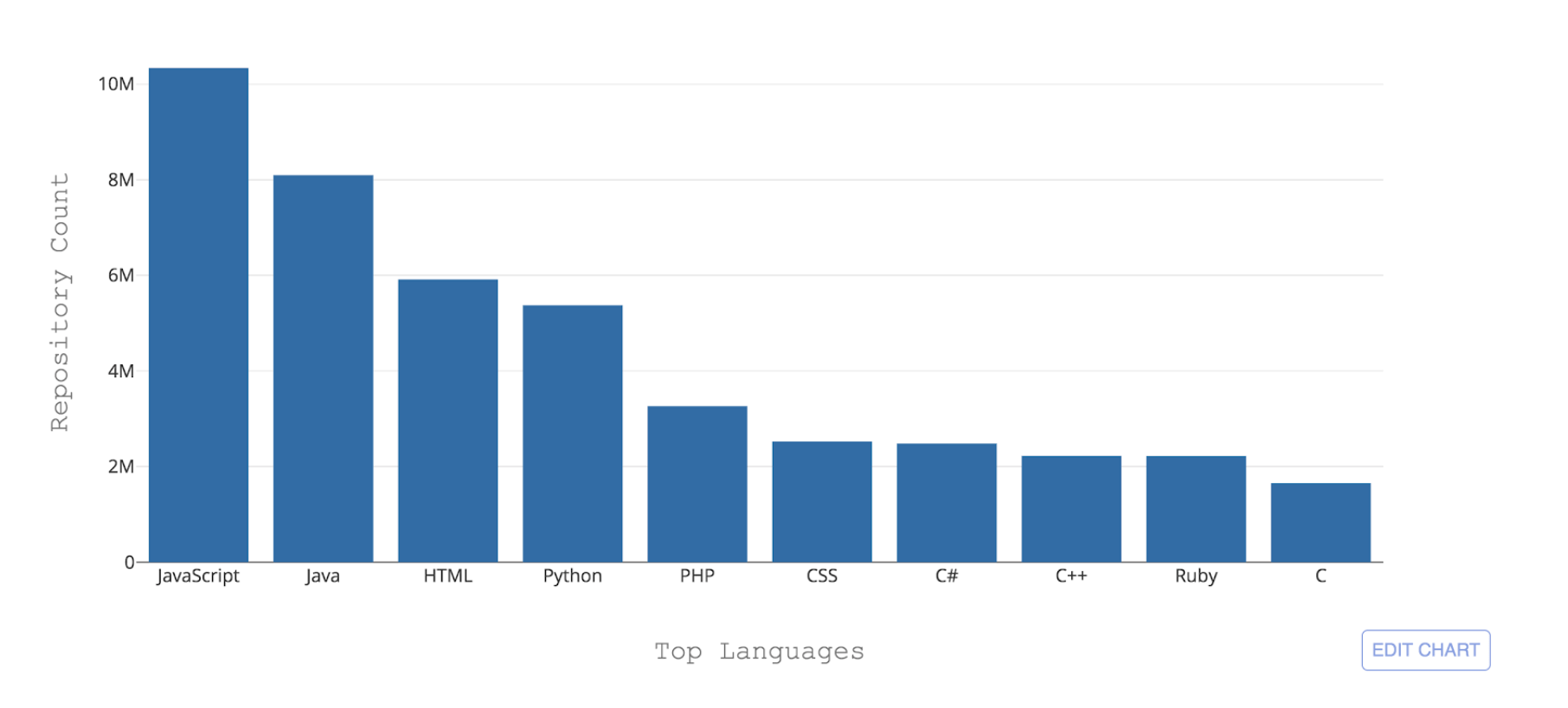 Figure 1: 10 principaux langages de programmation hébergés par GitHub par nombre de référentiels
Figure 1: 10 principaux langages de programmation hébergés par GitHub par nombre de référentielsL'un des défis nécessaires auxquels GitHub est confronté est de pouvoir reconnaître ces différents langages. Lorsqu'un code est envoyé à un référentiel, il est important de reconnaître le type de code qui a été ajouté à des fins de recherche, d'alerte de vulnérabilité de sécurité et de mise en évidence de la syntaxe - et d'afficher la distribution de contenu du référentiel aux utilisateurs.
Linguist est l'outil que nous utilisons actuellement pour détecter les langages de codage sur GitHub. Linguist une application basée sur Ruby qui utilise diverses stratégies pour la détection de la langue, en tirant parti des conventions de dénomination et des extensions de fichier et en prenant également en compte les modèles Vim ou Emacs, ainsi que le contenu en haut du fichier (shebang). Linguist gère la désambiguïsation du langage via des heuristiques et, à défaut, via un classifieur Naive Bayes formé sur un petit échantillon de données.
Bien que Linguist fasse un bon travail pour faire des prédictions linguistiques au niveau des fichiers (84% de précision), ses performances diminuent considérablement lorsque les fichiers utilisent des conventions de dénomination inattendues et, surtout, lorsqu'une extension de fichier n'est pas fournie. Cela rend Linguist impropre à un contenu tel que GitHub Gists ou des extraits de code dans README, des problèmes et des demandes d'extraction.
Afin de rendre la détection du langage plus robuste et maintenable à long terme, nous avons développé un classificateur d'apprentissage automatique nommé Octo Lingua basé sur une architecture de réseau de neurones artificiels (ANN) qui peut gérer les prédictions de langage dans des scénarios délicats. La version actuelle du modèle est capable de faire des prédictions pour les 50 principales langues hébergées par GitHub et surpasse Linguist en termes de précision et de performances.
Les écrous et boulons derrière OctoLingua
OctoLingua a été construit à partir de zéro en utilisant Python, Keras avec le backend TensorFlow - et est conçu pour être précis, robuste et facile à entretenir. Dans cette section, nous décrivons nos sources de données, notre architecture de modèle et notre référence de performances pour OctoLingua. Nous décrivons également ce qu'il faut pour ajouter la prise en charge d'une nouvelle langue.
Sources de données
La version actuelle d'OctoLingua a été formée sur les fichiers récupérés de
Rosetta Code et d'un ensemble de référentiels de qualité externalisés en interne. Nous avons limité notre ensemble de langues aux 50 principales langues hébergées sur GitHub.
Rosetta Code était un excellent ensemble de données de démarrage car il contenait du code source pour la même tâche exprimé dans différents langages de programmation. Par exemple, la tâche de génération d'une
séquence de Fibonacci est exprimée en C, C ++, CoffeeScript, D, Java, Julia, etc. Cependant, la couverture entre les langues n'était pas uniforme, car certaines langues n'ont qu'une poignée de fichiers et certains fichiers étaient trop peu peuplés. Il était donc nécessaire d'augmenter notre ensemble de formation avec quelques sources supplémentaires et d'améliorer considérablement la couverture et les performances linguistiques.
Notre processus d'ajout d'une nouvelle langue est désormais entièrement automatisé. Nous collectons par programme le code source des référentiels publics sur GitHub. Nous choisissons des référentiels qui répondent à des critères de qualification minimum tels que le fait d'avoir un nombre minimum de fourches, couvrant la langue cible et couvrant des extensions de fichier spécifiques. Pour cette étape de la collecte de données, nous déterminons la langue principale d'un référentiel en utilisant la classification de Linguist.
Caractéristiques: tirer parti des connaissances antérieures
Traditionnellement, pour les problèmes de classification de texte avec les réseaux de neurones, des architectures basées sur la mémoire telles que les réseaux de neurones récurrents (RNN) et les réseaux de mémoire à court terme (LSTM) sont souvent utilisées. Cependant, étant donné que les langages de programmation ont des différences de vocabulaire, de style de commentaire, d'extensions de fichiers, de structure, de style d'importation de bibliothèques et d'autres différences mineures, nous avons opté pour une approche plus simple qui exploite toutes ces informations en extrayant certaines fonctionnalités pertinentes sous forme de tableau à alimenter. notre classificateur. Les fonctionnalités actuellement extraites sont les suivantes:
- Cinq premiers caractères spéciaux par fichier
- 20 principaux jetons par fichier
- Extension de fichier
- Présence de certains caractères spéciaux couramment utilisés dans les fichiers de code source tels que les deux-points, les accolades et les points-virgules
Le modèle de réseau de neurones artificiels (ANN)
Nous utilisons les fonctionnalités ci-dessus comme entrée dans un réseau de neurones artificiels à deux couches construit à l'aide de Keras avec backend Tensorflow.
Le diagramme ci-dessous montre que l'étape d'extraction d'entités produit une entrée tabulaire à n dimensions pour notre classificateur. Au fur et à mesure que les informations se déplacent le long des couches de notre réseau, elles sont régularisées par abandon et produisent en fin de compte une sortie en 51 dimensions qui représente la probabilité prédite que le code donné soit écrit dans chacun des 50 premiers langages GitHub plus la probabilité qu'il ne le soit pas. écrit dans l'un de ceux-ci.
Figure 2: La structure ANN de notre modèle initial (50 langues + 1 pour "autre")Nous avons utilisé 90% de notre ensemble de données pour la formation sur environ huit époques. De plus, nous avons supprimé un pourcentage d'extensions de fichier de nos données de formation à l'étape de la formation, afin d'encourager le modèle à apprendre du vocabulaire des fichiers, et à ne pas surcharger la fonctionnalité d'extension de fichier, qui est hautement prédictive.
Référence de performance
OctoLingua vs. LinguisteDans la figure 3, nous montrons le
score F1 (moyenne harmonique entre la précision et le rappel) d'OctoLingua et Linguist calculé sur le même ensemble de tests (10% de notre source de données initiale).
Ici, nous montrons trois tests. Le premier test est avec l'ensemble de test intact d'aucune façon. Le deuxième test utilise le même ensemble de fichiers de test avec les informations d'extension de fichier supprimées et le troisième test utilise également le même ensemble de fichiers, mais cette fois avec des extensions de fichier brouillées afin de confondre les classificateurs (par exemple, un fichier Java peut avoir un ". txt "et un fichier Python peuvent avoir une extension" .java ").
L'intuition derrière le brouillage ou la suppression des extensions de fichier dans notre ensemble de tests est d'évaluer la robustesse d'OctoLingua dans la classification des fichiers lorsqu'une fonctionnalité clé est supprimée ou trompeuse. Un classificateur qui ne dépend pas fortement de l'extension serait extrêmement utile pour classer les extraits et les extraits, car dans ces cas, il est courant que les gens ne fournissent pas d'informations d'extension précises (par exemple, de nombreux extraits liés au code ont une extension .txt).
Le tableau ci-dessous montre comment OctoLingua maintient une bonne performance dans diverses conditions, suggérant que le modèle apprend principalement du vocabulaire du code, plutôt que des méta-informations (c'est-à-dire l'extension de fichier), tandis que Linguist échoue dès que les informations sur les extensions de fichier sont modifié.
Figure 3: performances d'OctoLingua par rapport à Linguiste sur le même ensemble de testsEffet de la suppression de l'extension de fichier pendant le temps de formationComme mentionné précédemment, pendant le temps de formation, nous avons supprimé un pourcentage d'extensions de fichier de nos données de formation pour encourager le modèle à apprendre du vocabulaire des fichiers. Le tableau ci-dessous montre les performances de notre modèle avec différentes fractions d'extensions de fichiers supprimées pendant la formation.
 Figure 4: Performances d'OctoLingua avec différents pourcentages d'extensions de fichiers supprimés sur nos trois variantes de test
Figure 4: Performances d'OctoLingua avec différents pourcentages d'extensions de fichiers supprimés sur nos trois variantes de testNotez que sans extension de fichier supprimée pendant le temps de formation, les performances d'OctoLingua sur les fichiers de test sans extensions et extensions aléatoires diminuent considérablement par rapport à celles des données de test régulières. D'un autre côté, lorsque le modèle est formé sur un ensemble de données où certaines extensions de fichier sont supprimées, les performances du modèle ne diminuent pas beaucoup sur l'ensemble de test modifié. Cela confirme que la suppression de l'extension de fichier d'une fraction de fichiers au moment de la formation incite notre classificateur à en apprendre davantage sur le vocabulaire. Il montre également que la fonction d'extension de fichier, bien que hautement prédictive, avait tendance à dominer et à empêcher l'attribution de plus de poids aux fonctionnalités de contenu.
Prise en charge d'une nouvelle langue
L'ajout d'une nouvelle langue dans OctoLingua est assez simple. Cela commence par l'obtention d'une masse de fichiers dans la nouvelle langue (nous pouvons le faire par programme comme décrit dans les sources de données). Ces fichiers sont divisés en une formation et un ensemble de tests, puis exécutés via notre préprocesseur et notre extracteur de fonctionnalités. Ce nouveau train et ensemble de tests est ajouté à notre pool existant de données de formation et de test. Le nouvel ensemble de tests nous permet de vérifier que la précision de notre modèle reste acceptable.
Figure 5: Ajout d'une nouvelle langue avec OctoLinguaNos plans
Actuellement, OctoLingua est au "stade avancé du prototypage". Notre moteur de classification des langues est déjà robuste et fiable, mais ne prend pas encore en charge toutes les langues de codage sur notre plate-forme. Outre l'élargissement de la prise en charge de la langue - qui serait plutôt simple - nous visons à permettre la détection de la langue à différents niveaux de granularité. Notre implémentation actuelle nous permet déjà, avec une petite modification de notre moteur d'apprentissage automatique, de classer les extraits de code. Il ne serait pas trop exagéré d'amener le modèle au stade où il peut détecter et classer de manière fiable les langages intégrés.
Nous envisageons également la possibilité de recourir à l'open source pour notre modèle et nous aimerions entendre la communauté si vous êtes intéressé.
Résumé
Avec OctoLingua, notre objectif est de fournir un service qui permet une détection de langage de code source robuste et fiable à plusieurs niveaux de granularité, du niveau de fichier ou de l'extrait de code à la détection et la classification de langage potentiellement au niveau ligne. Finalement, ce service peut prendre en charge, entre autres, la recherche de code, le partage de code, la mise en surbrillance du langage et le rendu diff - tout cela visant à soutenir les développeurs dans leur travail de développement quotidien en plus de les aider à écrire du code de qualité. Si vous souhaitez tirer parti de notre travail ou y contribuer, n'hésitez pas à nous contacter sur Twitter
@github !