L'article montre comment implémenter la gestion des erreurs et la journalisation sur la base du principe "Made and Forgot" dans Go. La méthode est conçue pour les microservices sur Go, fonctionnant dans un conteneur Docker et construite conformément aux principes de l'architecture propre.
Cet article est une version détaillée d'un rapport de la récente réunion de Go à Kazan . Si vous êtes intéressé par Go et que vous vivez à Kazan, Innopolis, la belle Yoshkar-Ola ou dans une autre ville à proximité, vous devriez visiter la page de la communauté: golangkazan.imtqy.com .
Lors de la réunion, notre équipe dans deux rapports a montré comment nous développons des microservices sur Go - quels principes nous suivons et comment nous simplifions nos vies. Cet article se concentre sur notre concept de gestion des erreurs, que nous étendons maintenant à tous nos nouveaux microservices.
Accords de structure de microservices
Avant d'aborder les règles de gestion des erreurs, il convient de décider quelles restrictions nous observons lors de la conception et du codage. Pour ce faire, il convient de dire à quoi ressemblent nos microservices.
Tout d'abord, nous respectons une architecture propre. Nous divisons le code en trois niveaux et observons la règle de dépendance: les packages à un niveau plus profond sont indépendants des packages externes et il n'y a pas de dépendances cycliques. Heureusement, les dépendances directes de tourniquet des packages sont interdites dans Go. Des dépendances indirectes via la terminologie d'emprunt, des hypothèses sur le comportement ou la conversion en un type peuvent toujours apparaître, elles doivent être évitées.
Voici à quoi ressemblent nos niveaux:
- Le niveau de domaine contient des règles de logique métier dictées par le domaine.
- parfois on se passe de domaine si la tâche est simple
- règle: le code au niveau du domaine dépend uniquement des capacités de Go, de la bibliothèque Go standard et des bibliothèques sélectionnées qui étendent la langue Go
- La couche d'application contient des règles de logique métier dictées par les tâches de l'application.
- règle: le code au niveau de l'application peut dépendre du domaine
- Le niveau d'infrastructure contient le code d'infrastructure qui connecte l'application à diverses technologies de stockage (MySQL, Redis), de transport (GRPC, HTTP), d'interaction avec l'environnement externe et avec d'autres services
- règle: le code au niveau de l'infrastructure peut dépendre du domaine et de l'application
- règle: une seule technologie par package Go
- Le paquet principal crée tous les objets - "singleton à vie", les connecte ensemble et lance des coroutines à longue durée de vie - par exemple, il commence à traiter les requêtes HTTP à partir du port 8081
Voici à quoi ressemble l'arborescence de répertoires du microservice (la partie où se trouve le code Go):

Pour chacun des contextes d'application (modules), la structure du package ressemble à ceci:
- le package d'application déclare une interface de service qui contient toutes les actions possibles à un niveau donné qui implémente l'interface de structure de service et la fonction
func NewService(...) Service - l'isolation du travail avec la base de données est obtenue du fait que le domaine ou le package d'application déclare l'interface Repository, qui est implémentée au niveau de l'infrastructure dans le package avec le nom visuel "mysql"
- le code de transport se trouve dans le paquet
infrastructure/transport
- nous utilisons GRPC, donc les talons de serveur sont générés à partir du fichier proto (c'est-à-dire l'interface du serveur, les structures de réponse / demande et tout le code d'interaction client)
Tout cela est illustré dans le diagramme:

Principes de gestion des erreurs
Ici, tout est simple:
- Nous pensons que des erreurs et des paniques se produisent lors du traitement des demandes à l'API - ce qui signifie qu'une erreur ou une panique ne devrait affecter qu'une seule demande
- Nous pensons que les journaux ne sont nécessaires que pour l'analyse des incidents (et il existe un débogueur pour le débogage), par conséquent, les informations sur les demandes sont reçues dans le journal et, tout d'abord, les erreurs inattendues lors du traitement des demandes
- Nous pensons qu'une infrastructure entière est construite pour le traitement des journaux (par exemple, basée sur ELK) - et le microservice y joue un rôle passif, écrivant des journaux sur stderr
Nous ne nous concentrerons pas sur les paniques: n'oubliez pas de gérer la panique dans chaque goroutine et lors du traitement de chaque requête, de chaque message, de chaque tâche asynchrone lancée par la requête. Presque toujours, la panique peut être transformée en une erreur pour empêcher l'application complète de se terminer.
Erreurs Idiom Sentinel
Au niveau de la logique métier, seules les erreurs attendues définies par les règles métier sont traitées. Les erreurs sentinelles vous aideront à identifier de telles erreurs - nous utilisons cet idiome au lieu d'écrire nos propres types de données pour les erreurs. Un exemple:
package app import "errors" var ErrNoCake = errors.New("no cake found")
Une variable globale est déclarée ici, ce que, par notre accord de gentleman, nous ne devrions changer nulle part. Si vous n'aimez pas les variables globales et utilisez le linter pour les détecter, vous pouvez vous en tirer avec certaines constantes, comme le suggère Dave Cheney dans le message Erreurs constantes :
package app type Error string func (e Error) Error() string { return string(e) } const ErrNoCake = Error("no cake found")
Si vous aimez cette approche, vous souhaiterez peut-être ajouter le type ConstError à votre bibliothèque de langues Go d'entreprise.
Composition des erreurs
Le principal avantage des erreurs Sentinel est la possibilité de composer facilement des erreurs. En particulier, lors de la création d'une erreur ou de la réception d'une erreur de l'extérieur, il serait bon de lui ajouter stacktrace. À ces fins, il existe deux solutions populaires.
- Paquet xerrors, qui dans Go 1.13 sera inclus dans la bibliothèque standard comme expérience
- Package github.com/pkg/errors par Dave Cheney
- le paquet est gelé et ne se dilate pas, mais il est néanmoins bon
Notre équipe utilise toujours github.com/pkg/errors et les errors.WithStack fonctions avec errors.WithStack (quand nous n'avons rien à ajouter, sauf stacktrace) ou les errors.Wrap . errors.Wrap (quand nous avons quelque chose à dire sur cette erreur). Les deux fonctions acceptent une erreur à l'entrée et renvoient une nouvelle erreur, mais avec stacktrace. Exemple de la couche infrastructure:
package mysql import "github.com/pkg/errors" func (r *repository) FindOne(...) { row := r.client.QueryRow(sql, params...) switch err := row.Scan(...) { case sql.ErrNoRows:
Nous recommandons que chaque erreur soit enveloppée une seule fois. C'est facile à faire si vous suivez les règles:
- toutes les erreurs externes sont enveloppées une fois dans l'un des packages d'infrastructure
- toutes les erreurs générées par les règles de logique métier sont complétées par stacktrace au moment de la création
Cause racine de l'erreur
On s'attend à ce que toutes les erreurs soient divisées en prévu et inattendu. Pour gérer l'erreur attendue, vous devez vous débarrasser des effets de la composition. Les packages xerrors et github.com/pkg/errors ont tout ce dont vous avez besoin: en particulier, le package errors a la fonction errors.Cause , qui renvoie la cause première de l'erreur. Cette fonction dans une boucle, l'une après l'autre, récupère les erreurs antérieures tandis que l'erreur extraite suivante a la méthode d' Cause() error .
Un exemple auquel nous extrayons la cause racine et la comparons directement avec l'erreur sentinelle:
func (s *service) SaveCake(...) error { state, err := s.repo.FindOne(...) if errors.Cause(err) == ErrNoCake { err = nil
Gestion des erreurs en différé
Vous utilisez peut-être linter, ce qui vous permet de vérifier manuellement toutes les erreurs. Dans ce cas, vous êtes probablement furieux lorsque linter vous demande de vérifier les erreurs avec les méthodes .Close() et d'autres méthodes que vous defer uniquement defer . Avez-vous déjà essayé de gérer correctement l'erreur en différé, surtout s'il y avait une autre erreur avant cela? Et nous avons essayé et sommes pressés de partager la recette.
Imaginez que tout le travail avec la base de données se fasse uniquement par le biais de transactions. Selon la règle de dépendance, les niveaux d'application et de domaine ne doivent pas dépendre directement ou indirectement de l'infrastructure et de la technologie SQL. Cela signifie qu'au niveau de l'application et du domaine, il n'y a pas de mot "transaction" .
La solution la plus simple consiste à remplacer le mot «transaction» par quelque chose d'abstrait; ainsi le modèle d'unité de travail est né. Dans notre implémentation, le service dans le package d'application reçoit la fabrique via l'interface UnitOfWorkFactory, et pendant chaque opération crée un objet UnitOfWork qui masque la transaction. L'objet UnitOfWork vous permet d'obtenir un référentiel.
Plus sur UnitOfWorkPour mieux comprendre l'utilisation de l'unité de travail, jetez un œil au schéma:
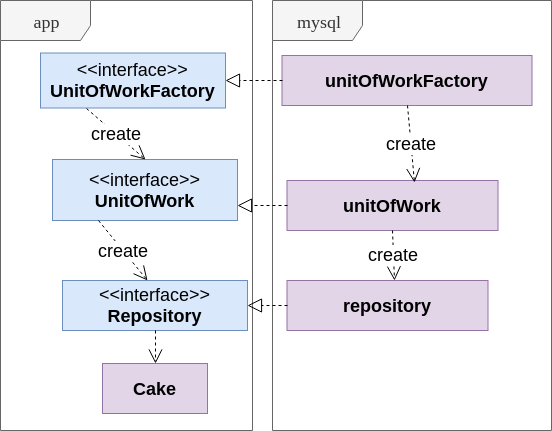
- Le référentiel représente une collection abstraite persistante d'objets (par exemple, des agrégats au niveau du domaine) d'un type défini
- UnitOfWork masque la transaction et crée des objets de référentiel
- UnitOfWorkFactory permet simplement au service de créer de nouvelles transactions sans rien savoir des transactions.
N'est-il pas excessif de créer une transaction pour chaque opération, même initialement atomique? Cela dépend de vous; Nous pensons qu'il est plus important de maintenir l'indépendance de la logique métier que d'économiser sur la création d'une transaction.
Est-il possible de combiner UnitOfWork et Repository? C'est possible, mais nous pensons que cela viole le principe de la responsabilité unique.
Voici à quoi ressemble l'interface:
type UnitOfWork interface { Repository() Repository Complete(err *error) }
L'interface UnitOfWork fournit la méthode Complete, qui prend un paramètre d'entrée-sortie: un pointeur vers l'interface d'erreur. Oui, c'est le pointeur et c'est le paramètre in-out - dans tous les autres cas, le code du côté appelant sera beaucoup plus compliqué.
Exemple d'opération avec unitOfWork:
Attention: l'erreur doit être déclarée comme valeur de retour nommée. Si au lieu de la valeur de retour nommée err vous utilisez la variable locale err, vous ne pouvez pas l'utiliser en différé! Et pas un seul linter ne le détectera encore - voir go-critique # 801
func (s *service) CookCake() (err error) { unitOfWork, err := s.unitOfWorkFactory.New() if err != nil { return err } defer unitOfWork.Complete(&err) repo := unitOfWork.Repository() }
Donc l'achèvement est réalisé transactions UnitOfWork:
func (u *unitOfWork) Complete(err *error) { if *err == nil {
La fonction mergeErrors fusionne deux erreurs, mais elle traite nil sans problème au lieu d'une ou des deux erreurs. Dans le même temps, nous pensons que les deux erreurs se sont produites lors de l'exécution d'une opération à différentes étapes, et la première erreur est plus importante - par conséquent, lorsque les deux erreurs ne sont pas nulles, nous enregistrons la première, et seul le message est enregistré à partir de la deuxième erreur:
package errors func mergeErrors(err error, nextErr error) error { if err == nil { err = nextErr } else if nextErr != nil { err = errors.Wrap(err, nextErr.Error()) } return err }
Vous devriez peut-être ajouter la fonction mergeErrors à votre bibliothèque d'entreprise pour Go.
Sous-système de journalisation
Liste de contrôle des articles : ce que vous aviez à faire avant de démarrer les microservices dans prod conseille:
- les journaux sont écrits dans stderr
- les journaux doivent être en JSON, un objet JSON compact par ligne
- Il devrait y avoir un ensemble standard de champs:
- horodatage - heure de l'événement en millisecondes , de préférence au format RFC 3339 (exemple: "1985-04-12T23: 20: 50.52Z")
- niveau - niveau d'importance, par exemple, "info" ou "erreur"
- app_name - nom de l'application
- et d'autres domaines
Nous préférons ajouter deux champs supplémentaires aux messages d'erreur: "error" et "stacktrace" .
Il existe de nombreuses bibliothèques de journalisation de qualité pour le langage Golang, par exemple, sirupsen / logrus , que nous utilisons. Mais nous n'utilisons pas directement la bibliothèque. Tout d'abord, dans notre package de log , nous réduisons l'interface de bibliothèque trop étendue à une seule interface Logger:
package log type Logger interface { WithField(string, interface{}) Logger WithFields(Fields) Logger Debug(...interface{}) Info(...interface{}) Error(error, ...interface{}) }
Si le programmeur veut écrire des journaux, il doit obtenir l'interface de l'enregistreur de l'extérieur, et cela doit être fait au niveau de l'infrastructure, pas de l'application ou du domaine. L'interface de l'enregistreur est concise:
- il réduit le nombre de niveaux de gravité pour le débogage, les informations et les erreurs, comme le conseille l'article. Parlons de la journalisation.
- il introduit des règles spéciales pour la méthode Error: la méthode accepte toujours un objet error
Une telle rigueur permet d'orienter les programmeurs dans la bonne direction: si quelqu'un veut améliorer le système de journalisation lui-même, il doit le faire en tenant compte de l'ensemble de l'infrastructure de leur collecte et de leur traitement, qui ne commence que dans le microservice (et se termine généralement quelque part à Kibana et Zabbix).
Cependant, dans le package de journaux, il existe une autre interface qui vous permet d'interrompre le programme lorsqu'une erreur fatale se produit et ne peut donc être utilisée que dans le package principal:
package log type MainLogger interface { Logger FatalError(error, ...interface{}) }
Paquet Jsonlog
Implémente l'interface Logger notre package jsonlog , qui configure la bibliothèque logrus et résume le travail avec. Ressemble schématiquement à ceci:

Un package propriétaire vous permet de connecter les besoins d'un microservice (exprimés par l'interface log.Logger ), les capacités de la bibliothèque logrus et les fonctionnalités de votre infrastructure, la journalisation.
Par exemple, nous utilisons ELK (Elastic Search, Logstash, Kibana), et donc dans le package jsonlog nous:
- définir le format
logrus.JSONFormatter pour logrus.JSONFormatter
- en même temps, nous définissons l'option FieldMap, avec laquelle nous transformons le champ
"time" en "@timestamp" , et le champ "msg" en "message"
- sélectionner le niveau de journal
- ajouter un hook qui extrait stacktrace de l'objet
Error(error, ...interface{}) passé à la méthode Error(error, ...interface{})
Le microservice initialise l'enregistreur dans la fonction principale:
func initLogger(config Config) (log.MainLogger, error) { logLevel, err := jsonlog.ParseLevel(config.LogLevel) if err != nil { return nil, errors.Wrap(err, "failed to parse log level") } return jsonlog.NewLogger(&jsonlog.Config{ Level: logLevel, AppName: "cookingservice" }), nil }
Gestion des erreurs et journalisation avec le middleware
Nous passons à GRPC dans nos microservices sur Go. Mais même si vous utilisez l'API HTTP, les principes généraux sont pour vous.
Tout d'abord, la gestion des erreurs et la journalisation doivent se produire au niveau de l' infrastructure dans le package responsable du transport, car c'est lui qui combine la connaissance des règles du protocole de transport et la connaissance des app.Service interface app.Service . Rappelez-vous à quoi ressemble la relation de package:

Il est pratique de traiter les erreurs et de maintenir les journaux en utilisant le modèle Middleware (Middleware est le nom du modèle Decorator dans le monde de Golang et Node.js):
Où ajouter un middleware? Combien devrait-il y en avoir?
Il existe différentes options pour ajouter un middleware, vous choisissez:
- Vous pouvez décorer l'interface
app.Service , mais nous vous déconseillons de le faire car cette interface ne reçoit pas d'informations sur la couche de transport, telles que l'adresse IP du client - Avec GRPC, vous pouvez accrocher un gestionnaire à toutes les demandes (plus précisément, deux - unaire et steam), mais toutes les méthodes API seront enregistrées dans le même style avec le même ensemble de champs
- Avec GRPC, le générateur de code crée pour nous une interface serveur dans laquelle nous appelons la méthode
app.Service - nous décorons cette interface car elle contient des informations au niveau du transport et la possibilité de consigner différentes méthodes API de différentes manières
Ressemble schématiquement à ceci:

Vous pouvez créer différents middlewares pour la gestion des erreurs (et la panique) et pour la journalisation. Vous pouvez tout croiser en un seul. Nous allons considérer un exemple dans lequel tout est croisé en un middleware, qui est créé comme ceci:
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService { server := &errorHandlingMiddleware{ next: next, logger: logger, } return server }
Nous obtenons l'interface api.BackendService en api.BackendService et la décorons, renvoyant notre implémentation de l'interface api.BackendService en api.BackendService .
Une méthode API arbitraire dans Middleware est implémentée comme suit:
func (m *errorHandlingMiddleware) ListCakes( ctx context.Context, req *api.ListCakesRequest) (*api.ListCakesResponse, error) { start := time.Now() res, err := m.next.ListCakes(ctx, req) m.logCall(start, err, "ListCakes", log.Fields{ "cookIDs": req.CookIDs, }) return res, translateError(err) }
Ici, nous effectuons trois tâches:
- Appelez la méthode ListCakes de l'objet décoré
- Nous
logCall méthode logCall , en lui transmettant toutes les informations importantes, y compris un ensemble de champs sélectionnés individuellement qui tombent dans le journal - À la fin, nous remplaçons l'erreur en appelant translateError.
La traduction des erreurs sera discutée plus tard. Et la logCall est effectuée par la méthode logCall , qui appelle simplement la bonne méthode d'interface Logger:
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) { fields["duration"] = fmt.Sprintf("%v", time.Since(start)) fields["method"] = method logger := m.logger.WithFields(fields) if err != nil { logger.Error(err, "call failed") } else { logger.Info("call finished") } }
Traduction d'erreur
Nous devons obtenir la cause première de l'erreur et la transformer en une erreur compréhensible au niveau du transport et documentée dans l'API de votre service.
Dans GRPC, c'est simple - utilisez la fonction status.Errorf pour créer une erreur avec un code d'état. Si vous disposez d'une API HTTP (API REST), vous pouvez créer votre propre type d'erreur que les niveaux d'application et de domaine ne devraient pas connaître.
Dans une première approximation, la traduction d'erreur ressemble à ceci:
Lors de la validation des arguments d'entrée, l'interface décorée peut renvoyer une erreur du type status.Status avec un code d'état, et la première version de translateError perdra ce code d'état.
Faisons une version améliorée en lançant un type d'interface (longue vie de frappe de canard!):
type statusError interface { GRPCStatus() *status.Status } func isGrpcStatusError(er error) bool { _, ok := err.(statusError) return ok } func translateError(err error) error { if isGrpcStatusError(err) { return err } switch errors.Cause(err) { case app.ErrNoCake: err = status.Errorf(codes.NotFound, err.Error()) default: err = status.Errorf(codes.Internal, err.Error()) } return err }
La fonction translateError est créée individuellement pour chaque contexte (module indépendant) dans votre microservice et traduit les erreurs de logique métier en erreurs au niveau du transport.
Pour résumer
Nous vous proposons plusieurs règles pour gérer les erreurs et travailler avec les journaux. À vous de décider de les suivre ou non.
- Suivez les principes de l'architecture propre, ne violez pas directement ou indirectement la règle des dépendances. La logique métier ne devrait dépendre que d'un langage de programmation et non de technologies externes.
- Utilisez un package qui propose la composition des erreurs et la création de traces de pile. Par exemple, "github.com/pkg/errors" ou le package xerrors, qui fera bientôt partie de la bibliothèque standard Go.
- N'utilisez pas de bibliothèques de journalisation tierces dans le microservice - créez votre propre bibliothèque avec les packages log et jsonlog, qui masqueront les détails de l'implémentation de la journalisation
- Utilisez le modèle Middleware pour gérer les erreurs et écrire des journaux sur la direction de transport du niveau d'infrastructure du programme
Ici, nous n'avons rien dit sur les technologies de suivi des requêtes (par exemple, OpenTracing), la surveillance des métriques (par exemple, les performances des requêtes de base de données) et d'autres choses comme la journalisation. Vous allez vous en occuper, nous croyons en vous.