Récemment, le langage Scala a été largement utilisé par Data Science. Il a gagné en popularité principalement en raison de l'avènement de Spark, écrit en scala. En pratique, souvent au stade de la recherche, l'analyse et la création du modèle est réalisée en Python puis implémentée en Scala, car ce langage est plus adapté à la production.
Nous avons préparé un aperçu détaillé des bibliothèques les plus intéressantes utilisées pour implémenter l'apprentissage automatique et les tâches de science des données dans Scala. Certains d'entre eux sont utilisés dans notre programme éducatif " Analyse de données sur Scala ".
Pour plus de commodité, toutes les bibliothèques présentées dans la note ont été divisées en 5 groupes: analyse des données et mathématiques, PNL, visualisation, apprentissage automatique, etc.
Analyse des données et mathématiques
N ° 1. Breeze (Commits: 3316, Contributeurs: 84)
La bibliothèque Breeze est connue comme la bibliothèque scientifique principale de Scala. Il a des choses similaires de MATLAB (en termes de structures de données) et de Python, classes NumPy. Breeze permet une manipulation rapide et efficace des tableaux de données et vous permet d'effectuer de nombreuses autres opérations, notamment les suivantes:
- Opérations matricielles et vectorielles pour la création, la transposition, l'exécution d'opérations élément par élément, l'inversion, le calcul des déterminants et bien d'autres choses.
- Fonctions probabilistes et statistiques: des distributions statistiques et du calcul des statistiques descriptives (telles que la moyenne, la variance et l'écart type) aux modèles de chaîne de Markov. Les principaux packages de statistiques sont breeze.stats et breeze.stats.distributions.
- L'optimisation, qui consiste à examiner une fonction pour un minimum local ou global. Les méthodes d'optimisation sont stockées dans le package breeze.optimize.
- Algèbre linéaire: Toutes les opérations de base sont basées sur la bibliothèque netlib-java, ce qui rend Breeze extrêmement rapide pour le calcul algébrique.
- Opérations de traitement du signal. Des exemples de telles opérations dans Breeze sont la convolution et la transformée de Fourier, qui divise cette fonction en la somme des composantes du sinus et du cosinus.
Il convient de noter que Breeze vous permet également de créer des graphiques, mais nous en parlerons plus tard.
N ° 2. Selle (Commits: 184, Contributeurs: 10)
Un autre outil de données pour Scala est Saddle. Il s'agit d'un analogue de Pandas en Python, mais uniquement pour Scala. Comme les trames de données dans Pandas ou R, Saddle est basé sur une structure de trame (matrice indexée bidimensionnelle).
Il existe cinq structures de données de base au total, à savoir:
Frame (matrice indexée 2D)
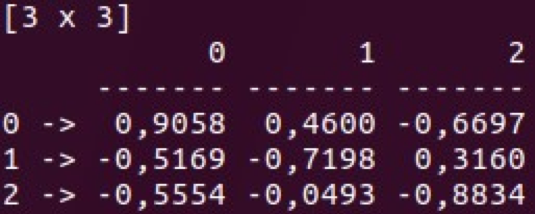
- Index (comme hashmap)
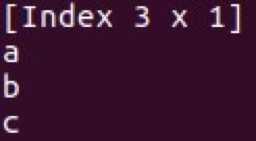
Les classes Vec et Mat sont situées dans Series et Frame. Vous pouvez effectuer diverses manipulations avec ces structures de données et les utiliser pour l'analyse de données de base. Une autre grande caractéristique de Saddle est sa résistance aux lacunes de données.
Numéro 3. ScalaLab (Commits: 23, Contributeurs: 1)
ScalaLab est une sorte de MATLAB à Scala. De plus, ScalaLab peut appeler directement et accéder aux résultats du script MATLAB.
La principale différence avec les bibliothèques informatiques précédentes est que ScalaLab utilise son propre langage spécifique au domaine appelé ScalaSci. Scalalab est pratique dans la mesure où il accède à de nombreuses bibliothèques scientifiques de Java et Scala, vous pouvez donc facilement importer vos données, puis utiliser diverses méthodes pour effectuer des manipulations et des calculs. La plupart des choses sont similaires à Breeze and Saddle. De plus, comme dans Breeze, il existe des graphiques qui vous permettent d'interpréter davantage les données.
Nlp
Numéro 4. Epic (commits: 1790, contributeurs: 15) et Puck (commits: 536, contributeurs: 1)
Scala possède de bonnes bibliothèques de traitement du langage naturel dans le cadre de ScalaNLP, notamment Epic et Puck. Ces bibliothèques sont principalement utilisées comme outils d'analyse de texte. Dans le même temps, Puck est plus pratique si vous devez analyser des milliers d'offres en raison de sa vitesse élevée et de l'utilisation d'un GPU. Epic est également connu comme un cadre de prévision qui utilise des prévisions structurées pour construire des systèmes complexes.
Visualisation
N ° 5. Breeze-viz (Commits: 29, Contributeurs: 3)
Comme son nom l'indique, Breeze-viz est une bibliothèque de visualisation développée par Breeze pour Scala. Il est basé sur la bibliothèque Java bien connue JFreeChart et la cartographie est quelque peu similaire à MATLAB. Bien que Breeze-viz ait beaucoup moins de fonctionnalités que MATLAB, matplotlib en Python ou R, il est néanmoins utile pour créer des modèles et analyser des données.
N ° 6. Vegas (Commits: 210, Contributeurs: 14)
Vegas est une autre bibliothèque de visualisation de données Scala. Il est beaucoup plus fonctionnel que Breeze-viz et vous permet de faire des transformations utiles pour les graphiques: filtrage, transformations et agrégations. En général, la bibliothèque est similaire à Bokeh et Plotly en Python.
Vegas vous permet d'écrire du code dans un style déclaratif, ce qui permet de se concentrer principalement sur la détermination de ce qui doit être fait avec les données et de mener une analyse approfondie des visualisations sans se soucier de la mise en œuvre du code.

Apprentissage automatique
Numéro 7. Smile (Commits: 1019, Contributeurs: 21)
Le Statistical Machine Intelligence and Learning Engine, ou tout simplement Smile, est une bibliothèque d'apprentissage machine moderne prometteuse, quelque peu similaire à scikit-learn en Python. Il est développé en Java, mais il dispose également d'une API pour Scala. La bibliothèque est assez rapide et productive: utilisation efficace de la mémoire, un grand nombre d'algorithmes d'apprentissage automatique pour la classification, la régression, NNS, la sélection de fonctions, etc.

Numéro 8. Spark ML
Une bibliothèque d'apprentissage automatique qui fonctionne dès le départ dans Apache Spark. Spark lui-même est écrit en Scala et dispose d'une API appropriée pour toutes ses bibliothèques.
Spark ML - contrairement à Spark MLlib (une ancienne bibliothèque), il fonctionne avec des trames de données. Il permet également de construire des pipelines de différentes transformations sur vos données. Cela peut être considéré comme une séquence d'étapes, où chaque étape est soit un transformateur qui convertit une trame de données en une autre, soit un estimateur, par exemple, un algorithme d'apprentissage automatique qui est formé sur une trame de données.
N ° 9. DeepLearning.scala (Commits: 1647, Contributeurs: 14)
DeepLearning.scala est un outil alternatif d'apprentissage automatique qui vous permet de créer des modèles d'apprentissage profond. La bibliothèque utilise des formules mathématiques pour créer des réseaux de neurones dynamiques complexes grâce à une combinaison de programmation orientée objet et fonctionnelle. Il utilise un large éventail de types, ainsi que des classes de types applicatifs. Ce dernier vous permet de démarrer plusieurs calculs en même temps, ce qui améliore la productivité.
N ° 10. Summing Bird (Commits: 1772, Contributeurs: 31)
Summingbird est un cadre de traitement de données qui permet l'utilisation de calculs MapReduce par lots et en temps réel. Le principal catalyseur du développement du langage a été les développeurs de Twitter, qui écrivaient souvent deux fois le même code: d'abord pour le traitement par lots, puis pour le streaming.
Summingbird utilise et génère deux types de données: les flux (séquences infinies de tuples) et les instantanés, qui à un certain moment sont considérés comme l'état complet de l'ensemble de données. Enfin, Summingbird fournit une plate-forme pour Storm, Scalding et un moteur de mémoire à des fins de test.
N ° 11. PredictionIO (Commits: 4343, Contributeurs: 125)
Il convient également de mentionner le service d'apprentissage automatique pour la création et le déploiement de mécanismes prédictifs appelés PredictionIO. Il est construit sur Apache Spark MLlib et HBase et a même été classé sur Github comme le produit d'apprentissage automatique le plus populaire basé sur Apache Spark. Il vous permet de créer, d'évaluer et de déployer facilement et efficacement des services, de mettre en œuvre vos propres modèles d'apprentissage automatique et de les intégrer à votre service.
Autre
N ° 12. Akka (Commits: 21430, Contributeurs: 467)
Développé par Scala, Akka est un environnement parallèle pour la création d'applications JVM distribuées. Il utilise un modèle basé sur un acteur, dans lequel un acteur est un objet qui reçoit des messages et effectue les actions appropriées.
La principale différence est la couche supplémentaire entre les acteurs et le cadre, qui ne nécessite que les acteurs pour traiter les messages, tandis que le cadre s'occupe de tout le reste. Tous les acteurs sont organisés hiérarchiquement, ce qui aide les acteurs à interagir plus efficacement entre eux et à résoudre des problèmes complexes, en les divisant en tâches plus petites.
N ° 13. Slick (Commits: 1940, Contributeurs: 92)
La dernière bibliothèque est Slick, ce qui signifie le kit de connexion intégré au langage Scala. Il s'agit d'une bibliothèque pour créer et exécuter des requêtes de base de données: H2, MySQL, PostgreSQL, etc. Certaines bases de données sont disponibles via des extensions slick.
Pour créer des requêtes, Slick fournit un DSL puissant qui rend le code comme si vous utilisiez des collections Scala. Slick prend en charge à la fois les requêtes SQL simples et les jointures fortement typées de plusieurs tables. De plus, des sous-requêtes simples peuvent être utilisées pour créer des sous-requêtes plus complexes.
Conclusion
Dans cet article, nous avons identifié et décrit brièvement certaines bibliothèques Scala qui peuvent être très utiles pour effectuer des tâches de traitement de données de base.
Si vous avez de l'expérience avec d'autres bibliothèques ou plates-formes Scala utiles qui méritent d'être ajoutées à cette liste, n'hésitez pas à les partager dans les commentaires.