
Entrée
Au fil des années de développement de projets ML et DL, notre studio a accumulé une grande base de code, beaucoup d'expérience et des idées et conclusions intéressantes. Lorsque vous démarrez un nouveau projet, ces connaissances utiles vous aident à démarrer la recherche en toute confiance, à réutiliser des méthodes utiles et à obtenir les premiers résultats plus rapidement.
Il est très important que tous ces matériaux soient non seulement dans l'esprit des développeurs, mais également sous forme lisible sur disque. Cela permettra de former plus efficacement les nouveaux employés, de les mettre à jour et de les immerger dans le projet.
Bien sûr, cela n'a pas toujours été le cas. Nous avons rencontré beaucoup de problèmes au début
- Chaque projet était organisé différemment, surtout s'il était initié par des personnes différentes.
- Ils n'ont pas su ce que faisait le code, comment l'exécuter et qui était l'auteur.
- Ils n'ont pas utilisé la virtualisation au bon niveau, empêchant souvent leurs collègues d'installer des bibliothèques existantes d'une version différente.
- Les conclusions tirées des cartes qui se sont installées et sont mortes dans la montagne des cahiers de jupyter ont été oubliées.
- Rapports perdus sur les résultats et l'avancement du projet.
Afin de résoudre ces problèmes une fois pour toutes, nous avons décidé que nous devions travailler à la fois sur une organisation unifiée et appropriée du projet, et sur la virtualisation, l'abstraction des composants individuels et la réutilisation du code utile. Progressivement, tous nos progrès dans ce domaine sont devenus un cadre indépendant - Océan.
Cerise sur le gâteau - les journaux du projet, qui sont agrégés et transformés en un magnifique site, sont automatiquement collectés à l'aide d'une seule commande.
Dans l'article, nous vous expliquerons avec un petit exemple artificiel de quelles parties Ocean se compose et comment l'utiliser.
Pourquoi l'océan
Dans le monde du ML, nous avons envisagé d'autres options. Tout d'abord, nous devons mentionner le Cookiecutter-data-science (ci - après CDS) en tant qu'inspirateur idéologique. Commençons par le bon: CDS offre non seulement une structure de projet pratique, mais indique également comment gérer le projet pour que tout se passe bien - par conséquent, nous vous recommandons de faire une digression et de regarder les principales idées clés de cette approche dans l'article CDS original .
Armé de CDS dans le projet de travail, nous y avons immédiatement apporté plusieurs améliorations: nous avons ajouté un enregistreur de fichiers pratique, une classe de coordination responsable de la navigation dans le projet et un générateur automatique de documentation Sphinx. De plus, plusieurs commandes ont été soumises au Makefile, de sorte que même un non initié dans les détails du chef de projet était pratique pour les exécuter.
Cependant, dans le processus, les inconvénients de l'approche CDS ont commencé à apparaître:
- Le dossier de données peut s'agrandir, mais lequel des scripts ou des cahiers génère le fichier suivant n'est pas complètement clair. Dans un grand nombre de fichiers, il est facile de se confondre. Il n'est pas clair si, dans le cadre de la mise en œuvre de la nouvelle fonctionnalité, il est nécessaire d'utiliser certains des fichiers existants, car la description ou la documentation à leur fin n'est stockée nulle part.
- Dans les données, il n'y a pas assez de sous-dossier de fonctionnalités dans lequel vous pouvez stocker des signes: statistiques calculées, vecteurs et autres caractéristiques à partir desquelles différentes représentations finales des données seraient collectées. Cela a déjà été remarquablement écrit dans un article de blog.
- src est un autre dossier de problèmes. Il a des fonctions pertinentes pour l'ensemble du projet, par exemple, la préparation et le nettoyage des données du module src.data . Mais il y a aussi le module src.models , qui contient tous les modèles de toutes les expériences, et il peut y en avoir des dizaines. Par conséquent, src est mis à jour très souvent, se développant avec des changements très mineurs, et selon la philosophie CDS, après chaque mise à jour, vous devez reconstruire le projet, et c'est aussi le moment ..., - eh bien, vous comprenez.
- des références sont présentées, mais il reste une question ouverte: qui, quand et sous quelle forme devrait y apporter le matériel. Et vous pouvez en dire beaucoup au cours du projet: quel travail a été fait, quel est leur résultat, quels sont les plans futurs.
Pour résoudre les problèmes ci-dessus, l'essence suivante est présentée dans Ocean: experiment . Une expérience est un référentiel de toutes les données impliquées dans le test d'une hypothèse. Cela peut inclure: quelles données ont été utilisées, quelles données (artefacts) ont résulté, la version du code, l'heure de début et de fin de l'expérience, le fichier exécutable, les paramètres, les mesures et les journaux. Certaines de ces informations peuvent être suivies à l'aide d'utilitaires spéciaux, par exemple, MLFlow. Cependant, la structure des expériences présentées dans Ocean est plus riche et plus flexible.
Le module d'une expérience est le suivant:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
Nous partageons la base de code: un bon code réutilisable qui est pertinent tout au long du projet reste dans le module src du niveau projet. Il est rarement mis à jour, vous devez donc moins souvent créer un projet. Et le module de scripts d'une expérience doit contenir du code qui n'est pertinent que pour l'expérience en cours. Ainsi, il peut être changé fréquemment: il n'affecte pas le travail des collègues dans d'autres expériences.
Examinons les possibilités de notre framework en utilisant l'exemple d'un projet abstrait ML / DL.
Flux de travail du projet
Initialisation
Ainsi, le client - la police de Chicago - nous a transmis les données et la tâche: analyser les crimes commis dans la ville au cours de la période 2011-2017 et tirer des conclusions.
Commençons! Nous allons au terminal et exécutons la commande:
ocean project new -n Crimes
Le cadre a créé le dossier du projet sur les délits correspondant. Nous regardons sa structure:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
Le coordinateur du module du même nom, déjà écrit et prêt, permet de naviguer dans tous ces dossiers. Pour l'utiliser, le projet doit être assemblé:
make package
Il s'agit d'un bug : si les commandes make ne veulent pas être exécutées, ajoutez-y le drapeau -B, par exemple, "make -B package". Cela s'applique à tous les autres exemples.
Journaux et expériences
Nous commençons par le fait que les données client, dans notre cas le fichier crimes.csv , sont placées dans le dossier data / raw .
Sur le site Web de Chicago, il y a des cartes avec les divisions de la ville en postes («temps» - l'emplacement le plus petit pour lequel une voiture de patrouille est affectée), les secteurs («secteurs», composés de 3 à 5 postes), les sections («districts», comprenant: 3 secteurs), les districts administratifs («quartiers») et, enfin, les espaces publics («zone communautaire»). Ces données peuvent être utilisées pour la visualisation. Dans le même temps, les fichiers json avec les coordonnées des sections de polygones de chaque type ne sont pas des données envoyées par le client, nous les mettons donc en données / externes .
Ensuite, vous devez introduire le concept d'expérience. Tout est simple: nous considérons une tâche distincte comme une expérience distincte. Besoin d'analyser / pomper les données et de les préparer pour une utilisation future? Cela vaut la peine de faire une expérience. Préparez-vous beaucoup de visualisation et de rapports? Expérience séparée. Tester l'hypothèse en préparant un modèle? Eh bien, vous obtenez le point.
Pour créer notre première expérience à partir du dossier du projet, nous effectuons:
ocean exp new -n Parsing -a ivanov
Maintenant un nouveau dossier avec le nom exp-001-Parsing est apparu dans le dossier crimes / experiences , sa structure est donnée ci-dessus.
Après cela, vous devez regarder les données. Pour ce faire, créez un ordinateur portable dans le dossier des carnets correspondant. Dans Surf, nous suivons le nom «numéro d'ordinateur portable - nom», et l'ordinateur portable créé s'appellera 001-Parse-data.ipynb . À l'intérieur, nous préparerons des données pour de futurs travaux.
Code de préparation des données import numpy as np import pandas as pd pd.options.display.max_columns = 100
Pour que vos collègues sachent ce que vous avez fait et si vos résultats peuvent être utilisés par eux, vous devez commenter cela dans le journal: le fichier log.md. La structure du journal (qui est essentiellement un fichier de démarque familier) est la suivante:

Les pièces remplies à la main sont surlignées en couleur. La méta principale de l'expérience (couleur prune claire) est l'auteur et l'explication de sa tâche, le résultat auquel l'expérience va. Les liens vers les données, prises et générées au cours du processus (couleur verte), aident à surveiller les fichiers de données et à comprendre qui, dans quoi et pourquoi les utilise. Le journal lui-même (couleur jaune) indique le résultat du travail, les conclusions et le raisonnement. Toutes ces données deviendront plus tard le contenu du site du journal du projet.
Vient ensuite l'étape EDA ( Exploratory Data Analysis - «intelligence data analysis» ). Peut-être qu'elle sera menée par différentes personnes, et, bien sûr, nous aurons besoin de résultats sous forme de rapports et de graphiques plus tard. Ces arguments sont l'occasion de créer une nouvelle expérience. Nous réalisons:
ocean exp new -n Eda -a ivanov
Dans le dossier des cahiers de l'expérience, créez le cahier 001-EDA.ipynb . Le code complet n'a pas de sens, mais il n'est pas nécessaire, par exemple, pour vos collègues. Mais vous avez besoin de graphiques et de conclusions. Beaucoup de code sort dans le cahier, et ce n'est pas en soi ce que l'on veut montrer au client. Par conséquent, nous enregistrerons nos découvertes et nos informations dans le fichier log.md et enregistrerons les images des graphiques dans des références .
Voici, par exemple, une carte des zones sûres de Chicago, si le destin vous y amène:
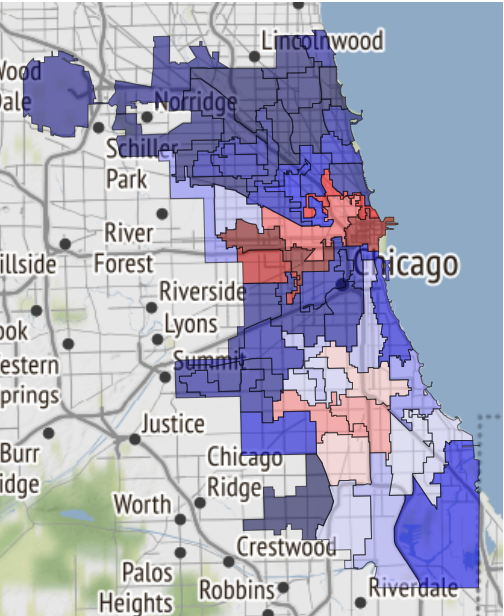
Il vient d'être reçu dans un cahier et transféré aux références .
L'entrée suivante a été ajoutée au journal:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
Remarque: le graphique est conçu comme l'insertion d'une image dans un fichier md. Et si vous laissez un lien vers le bloc-notes, il sera converti au format html et enregistré en tant que page distincte sur le site.
Pour le collecter à partir des journaux d'expériences, nous exécutons la commande suivante au niveau du projet:
ocean log new
Après cela, le dossier crime / project_log est créé et index.html est le journal du projet.
Il s'agit d'un bug : lorsqu'il est affiché dans Jupyter, le site est implémenté comme un iframe pour plus de sécurité, et donc les polices ne s'affichent pas correctement. Par conséquent, en utilisant Ocean, vous pouvez immédiatement créer une archive avec une copie du site afin qu'il soit pratique de le télécharger et de l'ouvrir sur un ordinateur local ou de l'envoyer par courrier. Comme ça:
ocean log archive [-n NAME] [-p PASSWORD]
La documentation
Jetons un coup d'œil à la documentation de construction à l'aide de Sphinx. Créez une fonction dans le fichier crimes / my_cool_module.py et documentez-la. Notez que Sphinx utilise le format de texte restructuré (RST):
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
Et puis tout est très simple: au niveau du projet, nous exécutons l'équipe de génération de documentation, et vous êtes prêt:
ocean docs new
Question du public : Pourquoi, si nous avons collecté le projet via make , devez-vous collecter de la documentation à travers l' ocean ?
Réponse : le processus de génération de documentation n'est pas seulement l'exécution de la commande Sphinx, qui peut être placée dans make . Ocean prend en charge la numérisation du catalogue de vos codes sources, construit un index pour Sphinx à partir de ceux-ci, et seulement alors Sphinx lui-même se met au travail.
Une documentation html prête à l'emploi vous attend le long du chemin crimes / docs / _build / html / index.html . Et notre module avec commentaires y est déjà apparu:

Les modèles
L'étape suivante consiste à créer le modèle. Nous réalisons:
ocean exp new -n Model -a ivanov
Et cette fois, jetez un œil à ce qui se trouve dans le dossier des scripts à l'intérieur de l'expérience. Le fichier train.py est vierge pour le futur processus de formation. Le fichier contient déjà le code passe-partout qui fait plusieurs choses à la fois.
- La fonction d'apprentissage prend plusieurs chemins de fichiers:
- Dans le fichier de configuration, dans lequel il est raisonnable de transférer les paramètres du modèle, les paramètres de formation et d'autres options pratiques à contrôler de l'extérieur, sans plonger dans le code.
- Vers le fichier de données.
- Chemin d'accès au répertoire dans lequel vous souhaitez enregistrer le vidage de modèle final.
- Suit les métriques obtenues dans le processus d'apprentissage dans mlflow . Tout ce qui a été demandé peut être visualisé via le mlflow de l'interface utilisateur en exécutant la commande
make dashboard dans le dossier d'expérience. - Envoie une alerte à votre télégramme indiquant que le processus d'apprentissage est terminé. Pour implémenter ce mécanisme, le bot Alarmerbot a été utilisé . Pour que cela fonctionne, vous devez faire un peu: envoyer la commande / start au bot, puis transférer le jeton émis par le bot dans le fichier crimes / config / alarm_config.yml . La chaîne peut ressembler à ceci:
ivanov: a5081d-1b6de6-5f2762 - Il est contrôlé depuis la console.
Pourquoi gérer notre script depuis la console? Tout est organisé pour que le processus d'apprentissage ou d'obtention des prédictions de n'importe quel modèle soit facilement organisé par un développeur tiers qui ne connaît pas les détails de la mise en œuvre de votre expérience. Pour que toutes les pièces du puzzle s'emboîtent , après la conception de train.py, vous devez organiser le Makefile . Il contient la commande train vierge, et il vous suffit de définir correctement les chemins d'accès aux fichiers de configuration requis répertoriés ci-dessus, et de répertorier toutes les personnes qui souhaitent recevoir des notifications de télégramme dans la valeur du paramètre de nom d'utilisateur. En particulier, l'alias fonctionne, ce qui enverra une alerte à tous les membres de l'équipe.
Une fois que tout est prêt, notre expérience commence par la make train , simplement et avec élégance.
Si vous souhaitez utiliser les réseaux de neurones d'autres personnes, les environnements virtuels ( venv ) vous aideront. Les créer et les supprimer dans le cadre d'une expérience est très simple:
ocean env new créera un nouvel environnement. Il est non seulement actif par défaut, mais crée également un noyau supplémentaire (noyau) pour les blocs-notes et pour des recherches ultérieures. Il sera appelé de la même manière que le nom de l'expérience.ocean env list affiche une liste de noyaux.ocean env delete environnement créé dans l'expérience.
Qu'est-ce qui manque?
- Ocean n'est pas ami avec conda (
parce que nous ne l'utilisons pas ) - Modèle de projet en anglais uniquement.
- Le problème de localisation s'applique toujours au site: la construction du journal du projet suppose que tous les journaux sont en anglais.
Conclusion
Le code source du projet se trouve ici .
Si vous êtes intéressé - super! Vous pouvez trouver plus d'informations dans le fichier README dans le référentiel Ocean .
Et comme ils le disent généralement dans de tels cas, les contributions sont les bienvenues, nous ne serons heureux que si vous participez à l'amélioration du projet.