Bonjour chers lecteurs! Dans cet article, je veux parler de l'architecture de mon projet, que j'ai refactorisé 4 fois lors de son lancement, car je n'étais pas satisfait du résultat. Je vais parler des inconvénients des approches populaires et montrer les miennes.
Je veux dire tout de suite que c'est mon premier article, je ne dis pas quoi faire comme moi - à droite. Je veux juste montrer ce que j'ai fait, dire comment j'en suis arrivé au résultat final et, surtout, obtenir les opinions des autres.
J'ai travaillé dans plusieurs campagnes et j'ai vu un tas de tout ce que j'aurais fait différemment.
Par exemple, je vois souvent une architecture N-Layer, il y a une couche pour travailler avec les données (DA), il y a une couche avec la logique métier (BL) qui fonctionne avec DA et éventuellement d'autres services, et il y a aussi une couche de vue \ API dans laquelle une demande est reçue, traitée en utilisant BL. Cela semble pratique, mais en regardant le code, je vois cette situation:
- [DA] extrait \ écrit \ modifie les données, même si une requête complexe - OK
- [BL] 80% appelle 1 méthode et obtient le résultat ci-dessus - Pourquoi ce calque vide?
- [Voir] 80% Appelle 1 méthode BL lance le résultat ci-dessus - Pourquoi cette couche vierge?
De plus, il est à la mode d'encapsuler des interfaces pour que plus tard vous puissiez verrouiller et tester - wow, wow!
- Pourquoi se mouiller?
- Eh bien, pour réduire les effets secondaires pendant la durée des tests.
- Autrement dit, nous allons protester sans effets secondaires, mais dans la prod avec eux?
...
C’est une chose fondamentale que je n’aimais pas dans cette architecture, car pour résoudre un problème comme: «Lister les goûts des utilisateurs» est un gros processus, mais en réalité il y a 1 requête dans la base de données et peut-être un mappage.
Exemple de solution1) [DA] Ajouter une demande à DA
2) [BL] Réponse DA directe
3) [Voir] Résultat BA en avant, peut promouvoir
N'oubliez pas que toutes ces méthodes doivent encore être ajoutées à l'interface, nous écrivons un projet afin de se mouiller, et non pour une solution.
Ailleurs, j'ai vu une implémentation d'API avec une approche CQRS.
La solution n'a pas l'air mal, 1 dossier - 1 fonctionnalité. Un développeur qui crée une fonctionnalité se trouve dans son dossier et peut presque toujours oublier l'influence de son code sur d'autres fonctionnalités, mais il y avait tellement de fichiers que ce n'était qu'un cauchemar. Modèles de demande / réponse, validateurs, assistants, logique elle-même. La recherche dans le studio a pratiquement refusé de fonctionner, des extensions ont été mises en place pour trouver les éléments nécessaires dans le code.
Il y a encore beaucoup à dire, mais j'ai souligné les principales raisons qui m'ont poussé à le refuser
Et enfin à mon projet
Comme je l'ai dit, j'ai refactorisé mon projet plusieurs fois, à ce moment-là j'ai eu une «dépression programmeur», je n'étais tout simplement pas satisfait de mon code, et je l'ai refactorisé, encore et encore, à la fin j'ai commencé à regarder une vidéo sur l'architecture de l'application pour voir comment d'autres le font. Je suis tombé sur les rapports d'Anton Moldovan sur le DDD et la programmation fonctionnelle, et j'ai pensé: «Voilà, j'ai besoin de F #!».
Après avoir passé quelques jours sur F #, j'ai réalisé qu'en principe, je ferais la même chose en C # et pas pire. La vidéo montre:
- Voici le code C #, c'est de la merde
- Voici F # cool, moins écrit - super.
Mais l'astuce est que la solution sur F # a été implémentée différemment, et contre cela, ils ont montré une mauvaise implémentation sur C #. Le principe principal était que BL n'est pas une chose qui appelle les services DA et fait tout le travail, mais c'est une fonction pure .
Bien sûr, F # est bon, j'ai aimé certaines fonctionnalités mais, comme C #, ce n'est qu'un outil qui peut être utilisé de différentes manières.
Et je suis retourné en C # et j'ai commencé à créer.
J'ai créé de tels projets dans la solution:
- API
- Noyau
- Les services
- Les tests
J'ai également utilisé des fonctionnalités C # 8, en particulier le type de référence nullable, je vais montrer son application.
Brièvement sur les tâches des couches que je leur ai données.
API
1) Réception des demandes, modèles de demande + validation, restrictions
2) Fonctions d'appel du noyau et des services
Plus de détails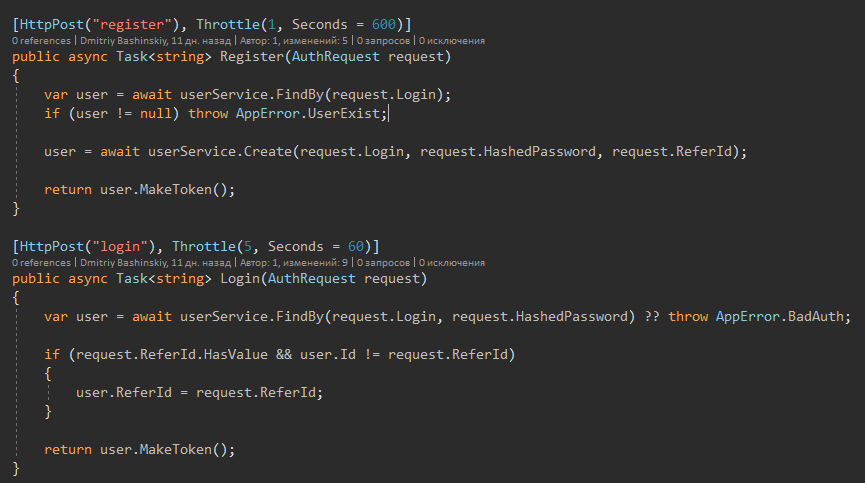
Ici, nous voyons un code simple et lisible, je pense que tout le monde comprendra ce qui est écrit ici.
Schéma clair observé
1) Obtenez des données
2) Traiter, modifier, etc. - Cette partie doit être testée.
3) Enregistrez.
3) Cartographie, si nécessaire
4) Gestion des erreurs (journalisation + réponse humaine)
Plus de détailsCette classe contient toutes les erreurs d'application possibles auxquelles le gestionnaire d'exceptions répond.
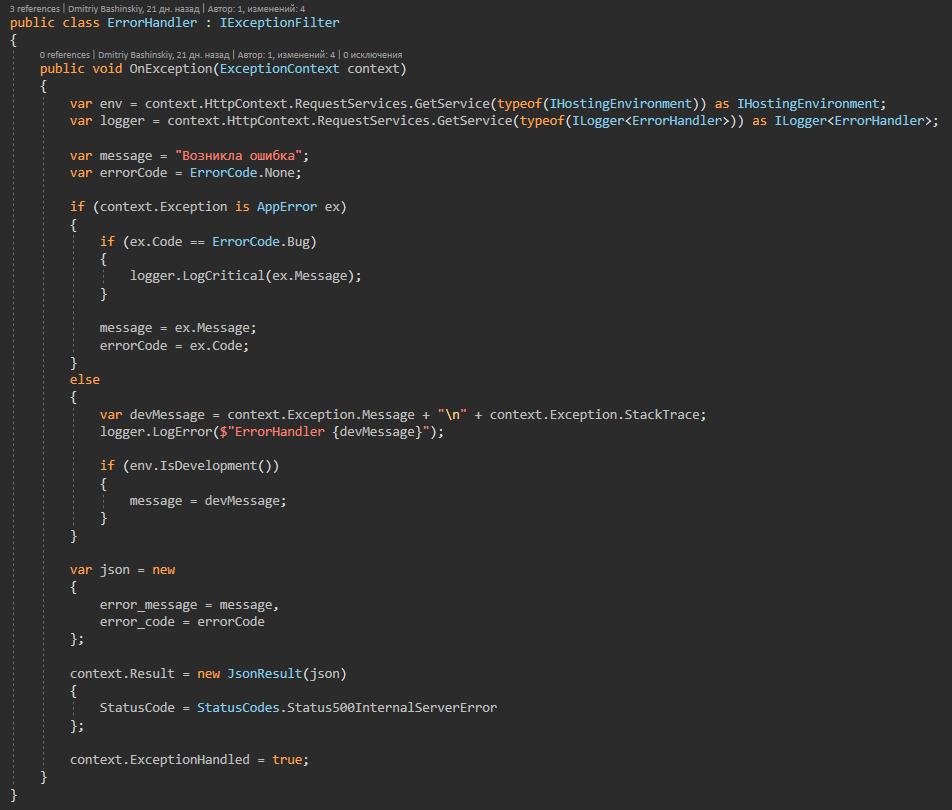
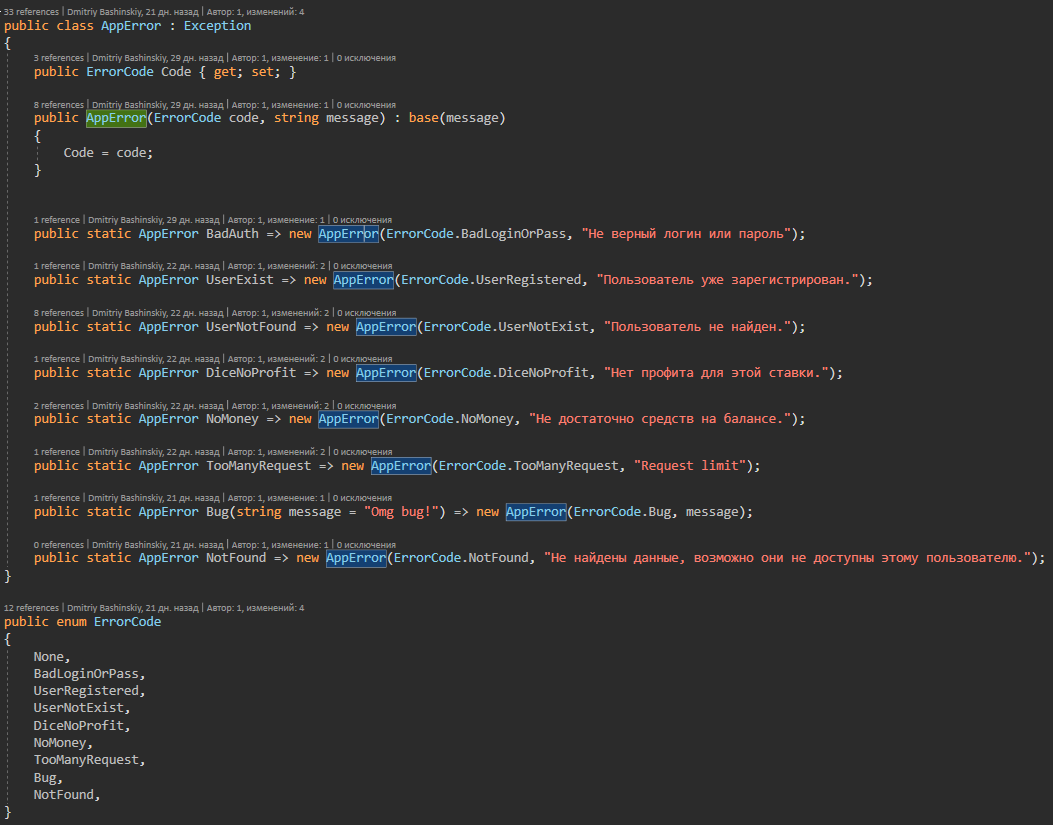
Il s'avère que l'application fonctionne, ou donne une erreur spécifique, et que les erreurs traitées ne sont ni un effet secondaire ni un bug, le journal de ces erreurs me vole tout de suite par télégramme dans un chat avec le bot.
J'ai AppError.Bug cette erreur pour un cas peu clair.
J'ai un rappel d'un autre service, il aura un ID utilisateur dans mon système, et si je ne trouve pas un utilisateur avec cet ID, soit quelque chose est arrivé à l'utilisateur ou ce n'est pas clair du tout, une telle erreur me vient comme CRITICAL, en théorie, elle ne devrait pas se poser, mais si cela se produit, cela nécessite mon intervention.
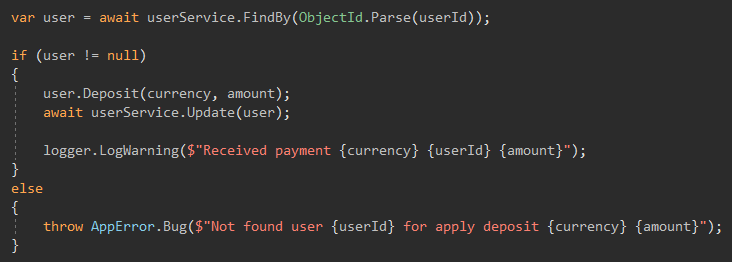
Core, le plus intéressant
J'ai toujours pensé que les BL ne sont que des fonctions qui donnent le même résultat avec la même entrée. La complexité du code dans cette couche était au niveau du travail en laboratoire, pas de grandes fonctions qui, clairement et sans erreurs, font leur travail. Et il était important qu'il n'y ait pas d'effets secondaires à l'intérieur des fonctions, tout ce dont la fonction avait besoin était son paramètre.
Si la fonction a besoin d'un solde utilisateur, nous obtenons le solde et le transférons à la fonction, et NE PAS pousser le service utilisateur dans BL.
1) Actions de base des entités
Plus de détails
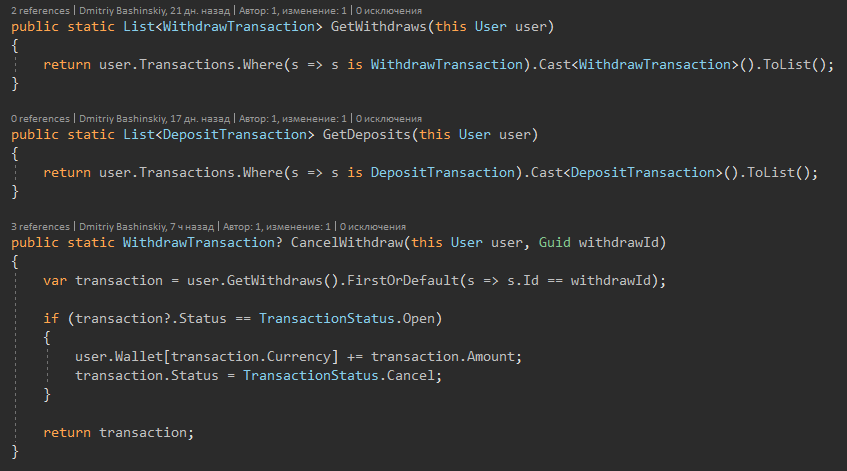
J'ai proposé des méthodes comme méthodes d'extension afin que la classe ne gonfle pas et que les fonctionnalités puissent être regroupées par fonctionnalités.
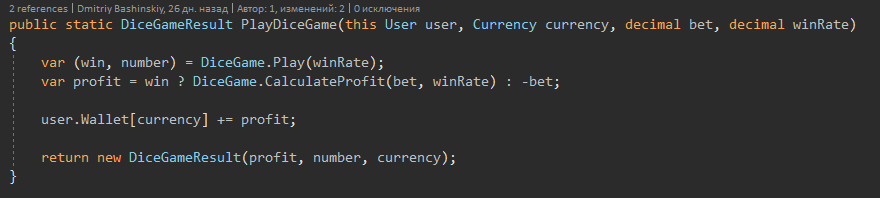
Je considère qu'une bonne construction de modèles d'entité est un sujet tout aussi important.
Par exemple, j'ai un utilisateur, l'utilisateur a des soldes dans plusieurs devises. L'une des décisions typiques que j'ai prises sans hésitation est l'essence de "Balance" et vient de mettre un tableau d'équilibres dans l'utilisateur. Mais quel genre de commodité a amené une telle décision?
1) Ajout / suppression de devises. Cette tâche signifie immédiatement pour nous non seulement l'écriture de nouveau code, mais aussi la migration, en remplissant / supprimant tous les utilisateurs existants, et c'est l'option la plus simple. À Dieu ne plaise, pour ajouter une nouvelle devise, vous devez créer un bouton pour l'utilisateur, sur lequel il clique et lance la création d'un nouveau portefeuille pour une sorte de processus métier. En conséquence, il était seulement nécessaire d'étendre l'énumération pour la nouvelle monnaie, et ils ont écrit une autre fonctionnalité pour créer des portefeuilles par un bouton, ils ont lancé une autre tâche vers l'avant.
2) Dans le code, constantes FirstOrDefault (s => s.Currency == currency) et vérification de null
Ma décision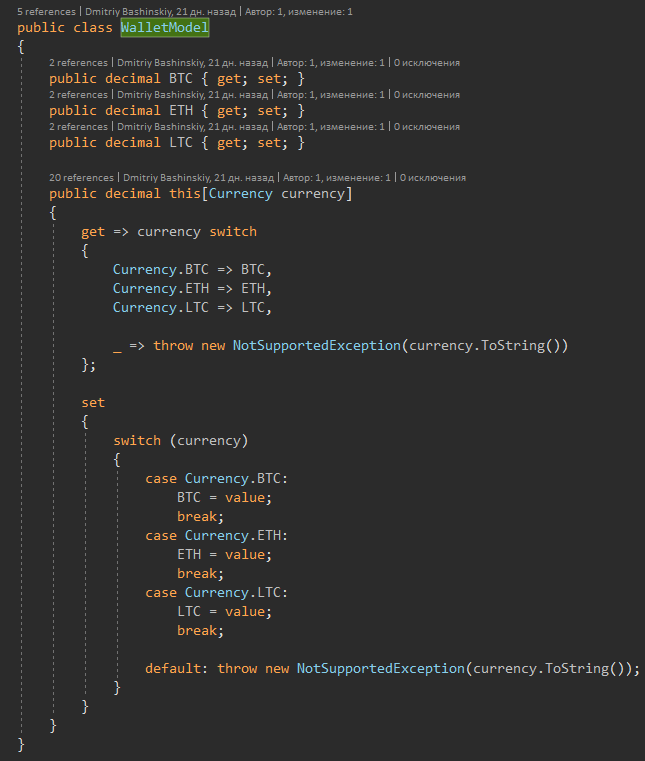
Par le modèle lui-même, je me garantis qu'il n'y aura pas d'équilibre nul, et en créant l'opérateur indexeur j'ai simplifié mon code dans tous les lieux d'interaction avec l'équilibre.
Les services
Cette couche me fournit des outils pratiques pour travailler avec divers services.
Dans mon projet, j'utilise MongoDB et pour un travail pratique avec lui, j'ai enveloppé les collections dans un tel référentiel.
Plus de détailsRéférentiel lui-même
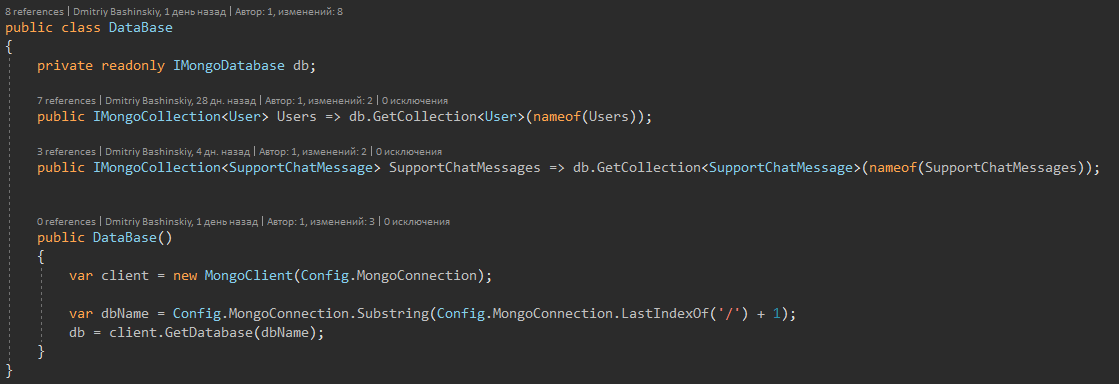
Monga bloque le document au moment de travailler avec lui, respectivement, cela nous aidera à résoudre les problèmes dans la compétition des demandes. Et dans le mong il y a des méthodes pour rechercher une entité + agir dessus, par exemple: "Trouver un utilisateur avec id et ajouter 10 à son solde actuel"
Et maintenant sur la fonctionnalité de C # 8.
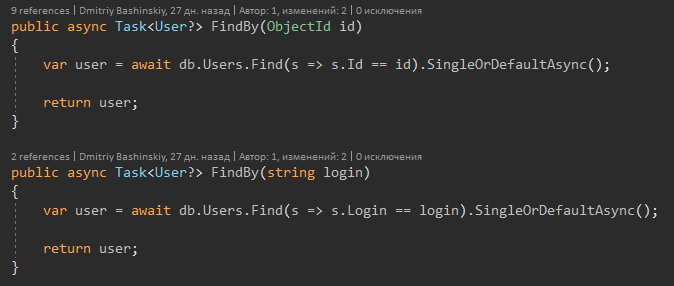
La signature de la méthode m'indique que l'utilisateur peut retourner, et peut-être Null, respectivement, quand je vois l'utilisateur? Je reçois immédiatement un avertissement du compilateur et effectue une vérification nulle.
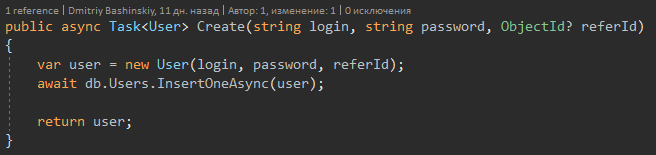
Lorsque la méthode renvoie Utilisateur, je travaille avec elle en toute confiance.
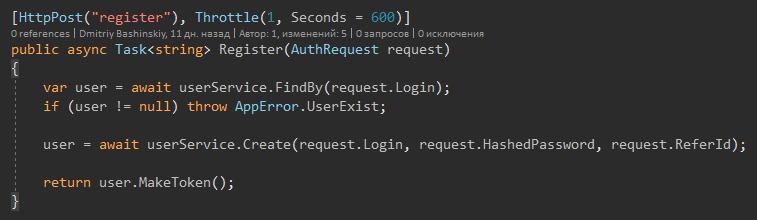
Je veux également attirer l'attention sur le fait qu'il n'y a pas de prise d'essai car les exceptions ne peuvent provenir que de "situations étranges" et de données incorrectes qui ne devraient pas arriver ici car il y a validation. Il n'y a pas non plus de catch try dans la couche API, il n'y a qu'un seul gestionnaire d'exceptions global.
Il n'y a qu'une seule méthode qui lève Exception est la méthode Update.
Il implémente une protection contre la perte de données en mode multi-thread.
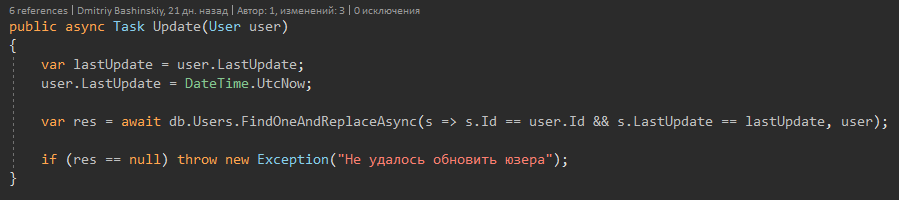
Pourquoi n'avez-vous pas utilisé les méthodes monga mentionnées ci-dessus?
Il y a des endroits où je ne sais toujours pas avec certitude si je peux même travailler avec l'utilisateur, peut-être qu'il n'a pas d'argent pour cette action, donc au début je fais sortir l'utilisateur et le vérifie, puis mute et l'enregistre.
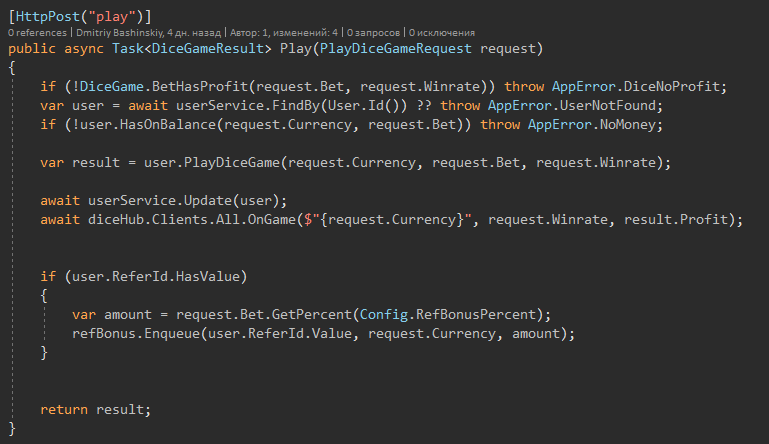
Mon application en théorie va changer l'équilibre de l'utilisateur plus d'une fois par seconde, car ce seront des jeux rapides.
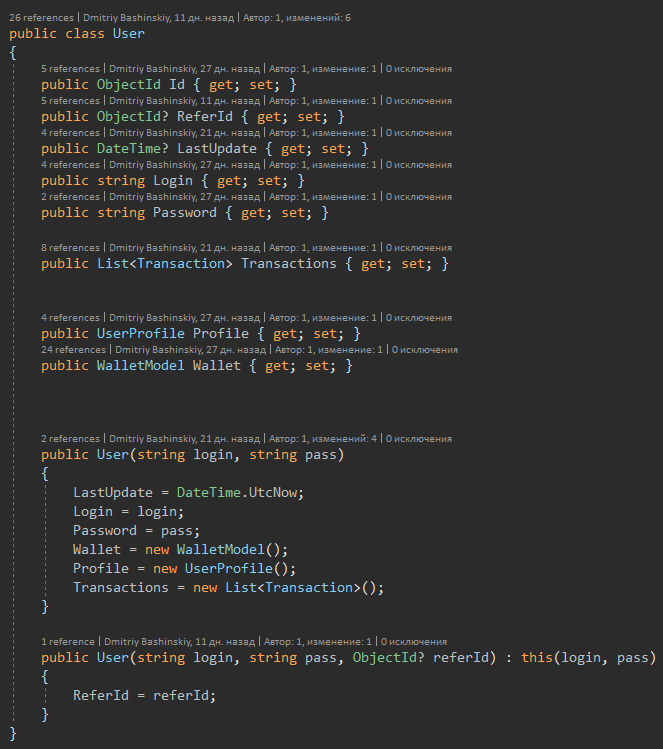
Mais le modèle de l'utilisateur lui-même, il est clairement visible que la référence de l'utilisateur est facultative, et vous pouvez travailler avec tout le reste sans penser à null.
Enfin des tests
Comme je l'ai dit, il suffit de tester la logique, et la logique de notre fonction est sans effets secondaires.
Par conséquent, nous pouvons exécuter nos tests très rapidement et avec différents paramètres.
Plus de détailsJ'ai téléchargé le nuget FSCheck qui génère des données entrantes au hasard et permet de nombreux cas différents.
Il me suffit de créer différents utilisateurs, d'alimenter leur test et de vérifier les modifications.
Il existe un petit générateur pour créer de tels utilisateurs, mais il est facile à étendre.

Et voici les tests eux-mêmes
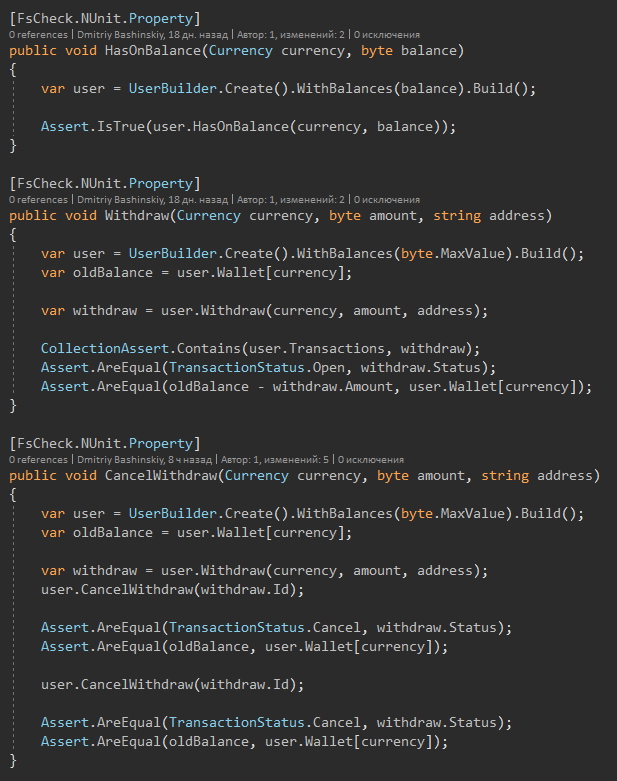
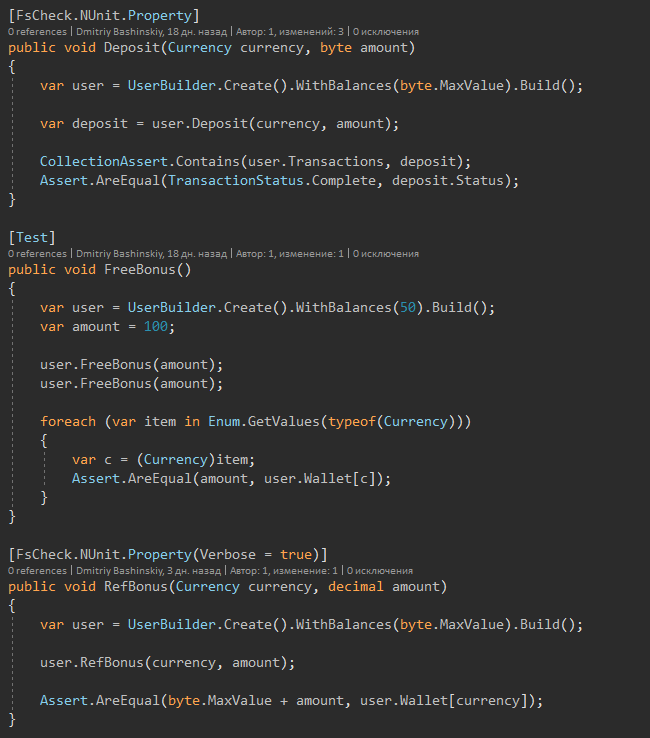
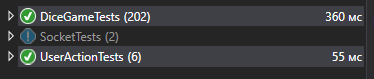
Après quelques changements, je lance les tests, après 1-2 secondes je vois que tout est en ordre.
Il est également prévu d'écrire des tests E2E afin de vérifier l'ensemble de l'API de l'extérieur et de s'assurer qu'il fonctionne comme il se doit, de la demande à la réponse.
Chips
Des trucs sympas dont vous pourriez avoir besoinChacune de mes requêtes est dopée, lorsqu'un bug se produit, je trouve requestId et je peux facilement reproduire le bug en répétant la requête, car mon API n'a pas d'état, et chaque requête ne dépend que des paramètres de la requête.
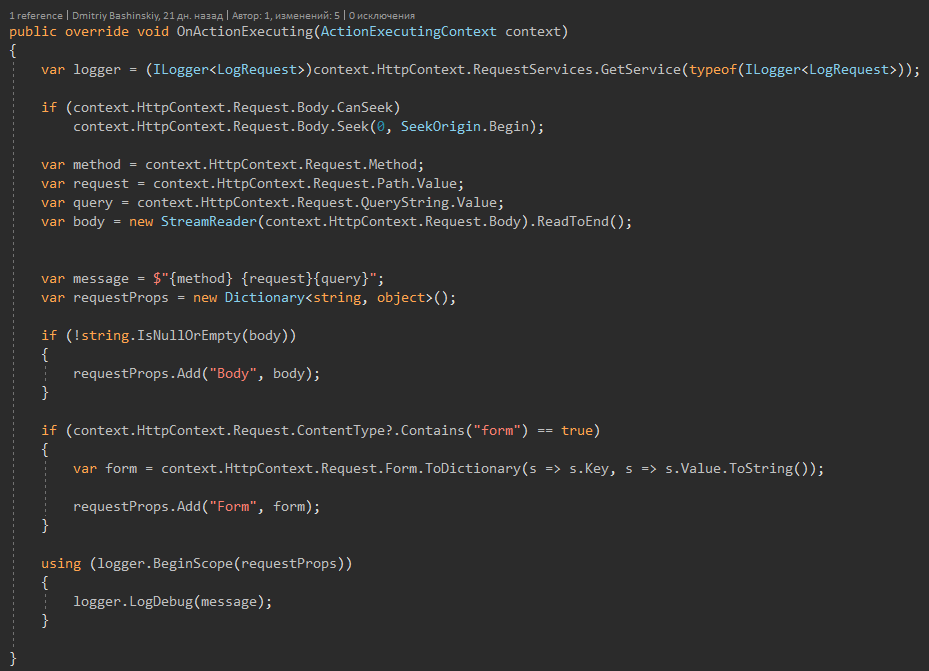
Pour résumer.
Nous avons vraiment écrit une solution, et non un cadre dans lequel un tas d'abstractions supplémentaires, ainsi que mok. Nous avons fait la gestion des erreurs en un seul endroit et elles devraient se produire très rarement. Nous avons séparé BL et les effets secondaires, maintenant BL n'est plus qu'une logique locale qui peut être réutilisée. Nous n'avons pas écrit de fonctions supplémentaires qui transfèrent simplement l'appel à d'autres fonctions. Je vais lire activement les commentaires et compléter l'article, merci!