Les principaux problèmes liés à l'utilisation de la base de données sont liés aux fonctionnalités de l'appareil du système d'exploitation sur lequel la base de données fonctionne. Linux est désormais le principal système d'exploitation des bases de données. Solaris, Microsoft et même HPUX sont toujours utilisés dans l'entreprise, mais ils ne prendront jamais la première place, même lorsqu'ils sont combinés. Linux gagne du terrain en toute confiance car il existe de plus en plus de bases de données open source. Par conséquent, la question de l'interaction de la base de données avec le système d'exploitation concerne évidemment les bases de données Linux. Ceci est superposé au problème éternel de la base de données - les performances d'E / S. Il est bon que ces dernières années, Linux ait subi une refonte majeure de la pile d'E / S et il y a de l'espoir pour l'illumination.
Ilya Kosmodemyansky (
hydrobiont ) travaille pour Data Egret, une entreprise qui
consulte et prend en charge PostgreSQL, et en sait beaucoup sur l'interaction entre le système d'exploitation et les bases de données. Dans un rapport sur HighLoad ++, Ilya a parlé de l'interaction des E / S et des bases de données en utilisant l'exemple de PostgreSQL, mais a également montré comment d'autres bases de données fonctionnent avec les E / S. J'ai regardé la pile Linux IO, quelles nouvelles et bonnes choses y sont apparues et pourquoi tout n'est pas comme il y a quelques années. Pour rappel utile - une liste de contrôle des paramètres PostgreSQL et Linux pour des performances maximales du sous-système d'E / S dans les nouveaux noyaux.
La vidéo du rapport contient beaucoup d'anglais, dont la plupart ont été traduits dans l'article.Pourquoi parler d'IO?
Les E / S rapides sont la chose la plus critique pour les administrateurs de bases de données . Tout le monde sait ce qui peut être changé en travaillant avec le CPU, cette mémoire peut être étendue, mais les E / S peuvent tout gâcher. En cas de problème avec les disques et trop d'E / S, la base de données gémira. IO deviendra un goulot d'étranglement.
Pour que tout fonctionne bien, vous devez tout configurer.
Pas seulement la base de données ou seulement le matériel - c'est tout. Même Oracle de haut niveau, qui est lui-même un système d'exploitation à certains endroits, nécessite une configuration. Nous lisons les instructions dans le "Guide d'installation" d'Oracle: changez ces paramètres du noyau, changez les autres - il y a beaucoup de réglages. En plus du fait que dans le noyau incassable, une grande partie est déjà par défaut câblée à Oracle Linux.
Pour PostgreSQL et MySQL, encore plus de modifications sont nécessaires. En effet, ces technologies reposent sur des mécanismes de système d'exploitation. Un DBA qui fonctionne avec PostgreSQL, MySQL ou NoSQL moderne doit être un ingénieur d'exploitation Linux et tordre différents écrous du système d'exploitation.
Tous ceux qui veulent gérer les paramètres du noyau se tournent vers
LWN . La ressource est ingénieuse, minimaliste, contient beaucoup d'informations utiles, mais a été
écrite par les développeurs du noyau pour les développeurs du noyau . Qu'est-ce que les développeurs du noyau écrivent bien? Le noyau, pas l'article, comment l'utiliser. Par conséquent, je vais essayer de tout vous expliquer pour les développeurs et de les laisser écrire le noyau.
Tout est compliqué plusieurs fois par le fait qu'au départ, le développement du noyau Linux et le traitement de sa pile étaient en retard, et ces dernières années, ils sont allés très vite. Ni le fer ni les développeurs avec des articles derrière lui ne suivent.
Base de données typique
Commençons par les exemples pour PostgreSQL - voici les E / S tamponnées. Il a une mémoire partagée, qui est allouée dans
l'espace utilisateur du point de vue du système d'exploitation, et a le même cache dans le cache du
noyau dans l'
espace du noyau .
 La tâche principale d'une base de données moderne
La tâche principale d'une base de données moderne :
- récupérer des pages du disque en mémoire;
- lorsqu'un changement se produit, marquez les pages comme sales;
- écrire dans le journal d'écriture anticipée;
- synchronisez ensuite la mémoire afin qu'elle soit cohérente avec le disque.
Dans une situation PostgreSQL, il s'agit d'un aller-retour constant: depuis la mémoire partagée que PostgreSQL contrôle dans le noyau Page Cache, puis vers le disque à travers la pile Linux entière. Si vous utilisez une base de données sur un système de fichiers, il fonctionnera sur cet algorithme avec n'importe quel système de type UNIX et avec n'importe quelle base de données. Les différences sont, mais insignifiantes.
L'utilisation d'Oracle ASM sera différente - Oracle lui-même interagit avec le disque. Mais le principe est le même: avec Direct IO ou avec Page Cache, mais la tâche est
de dessiner des pages dans toute la pile d'E / S le plus rapidement possible , quelle qu'elle soit. Et des problèmes peuvent survenir à chaque étape.
Deux problèmes d'IO
Bien que tout soit en
lecture seule , il n'y a aucun problème. Ils lisent et, s'il y a suffisamment de mémoire, toutes les données qui doivent être lues sont placées dans la RAM. Le fait que dans le cas de PostgreSQL dans
Buffer Cache soit le même, nous ne sommes pas très inquiets.
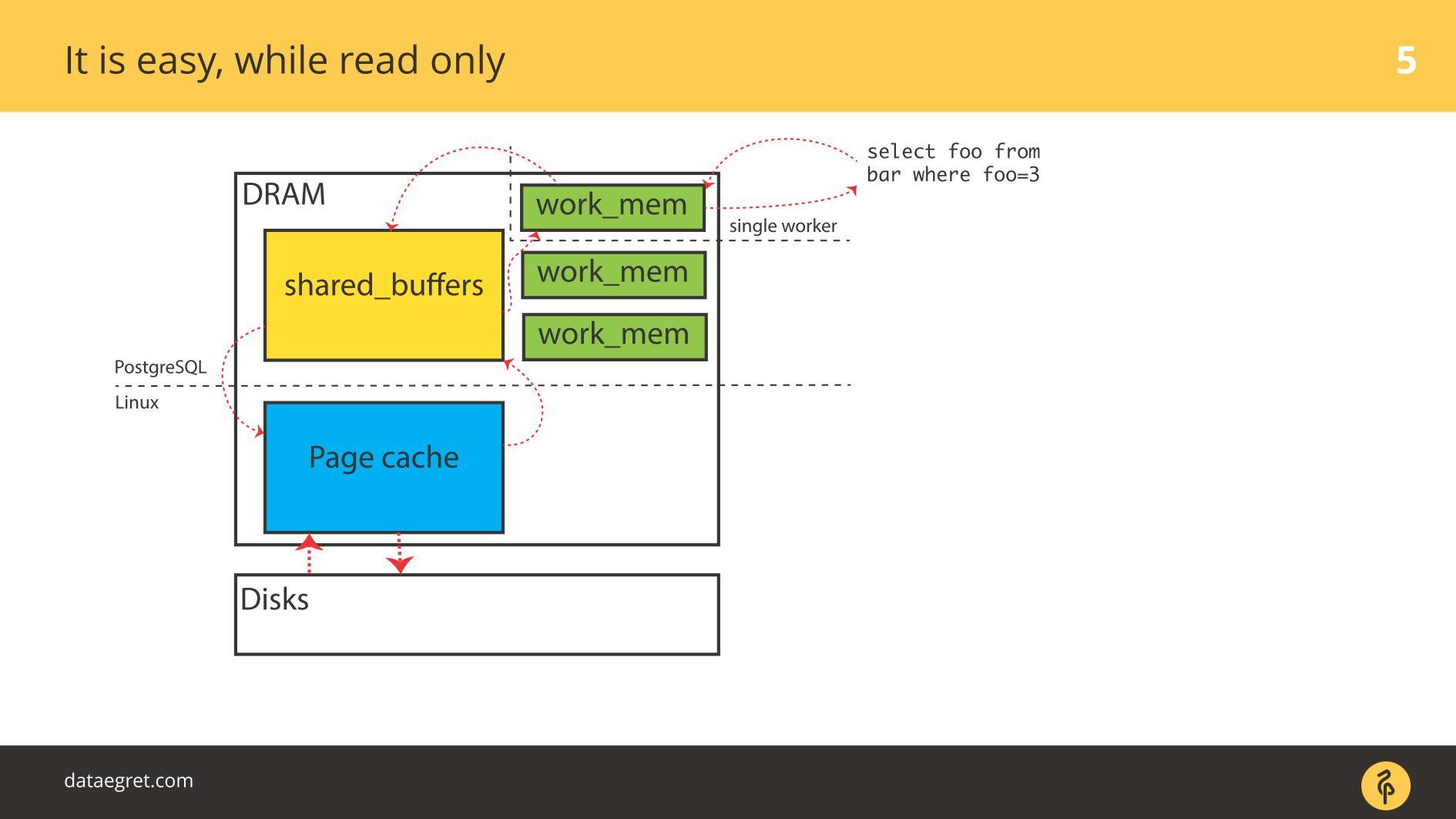 Le premier problème avec IO est la synchronisation du cache.
Le premier problème avec IO est la synchronisation du cache. Se produit lorsque l'enregistrement est requis. Dans ce cas, vous devrez parcourir beaucoup plus de mémoire.
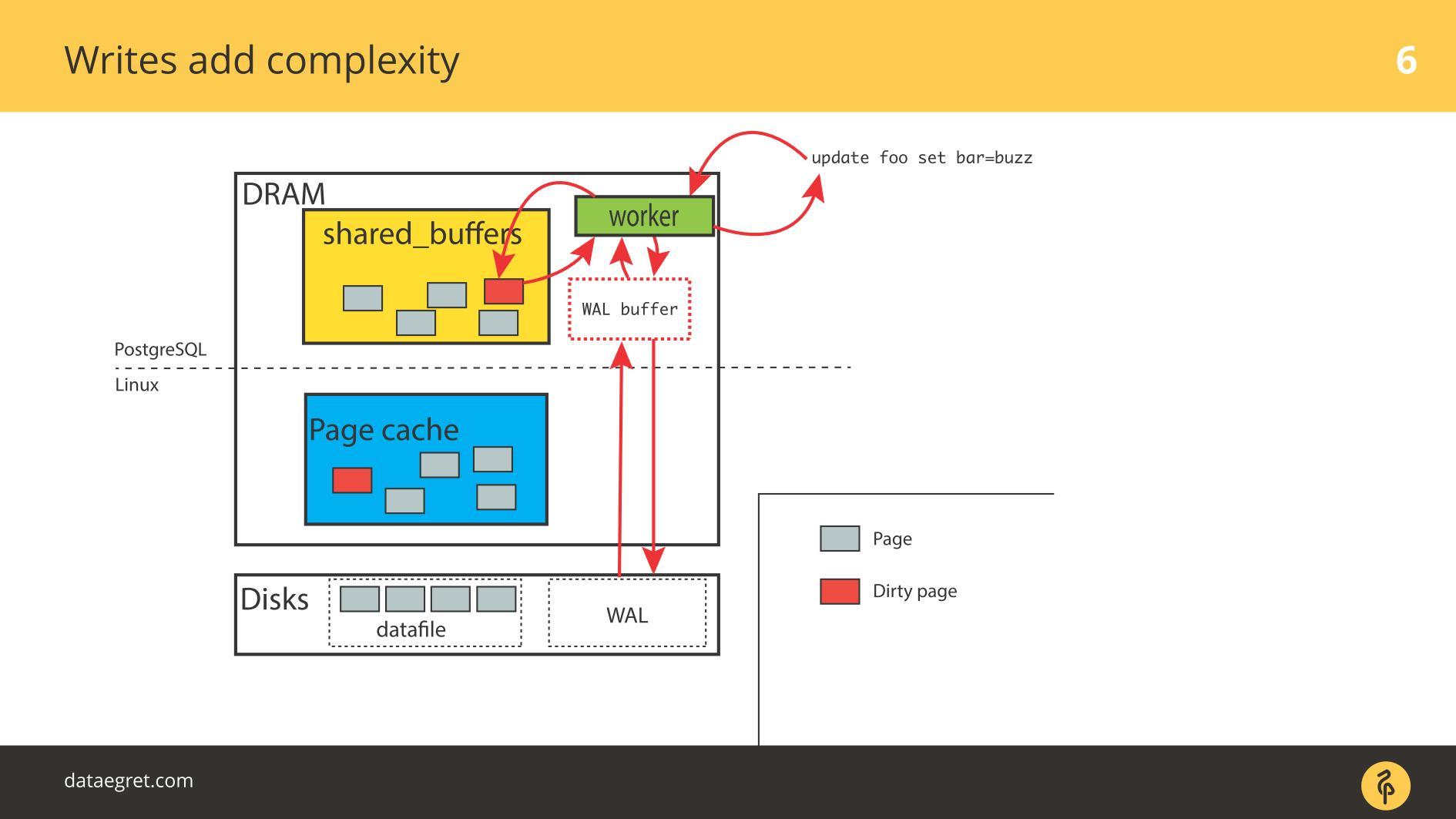
En conséquence, vous devez configurer PostgreSQL ou MySQL de sorte que tout cela arrive sur le disque à partir de la mémoire partagée. Dans le cas de PostgreSQL - vous devez toujours affiner la triche en arrière-plan des pages sales sous Linux pour tout envoyer sur le disque.
Le deuxième problème courant est l'échec d'écriture du journal d'écriture anticipée . Il apparaît lorsque la charge est si puissante que même un journal enregistré séquentiellement repose sur le disque. Dans cette situation, il doit également être enregistré rapidement.
La situation n'est pas très différente de
la synchronisation du
cache . Dans PostgreSQL, nous travaillons avec un grand nombre de tampons partagés, la base de données dispose de mécanismes pour un enregistrement efficace du journal d'écriture anticipée, elle est optimisée à la limite. La seule chose qui peut être faite pour rendre le journal lui-même plus efficace est de modifier les paramètres Linux.
Les principaux problèmes de travail avec la base de données
Le segment de mémoire partagée peut être très volumineux . J'ai commencé à en parler lors de conférences en 2012. Puis j'ai dit que la mémoire avait baissé de prix, même il y a des serveurs avec 32 Go de RAM. En 2019, il y en a peut-être déjà plus sur les ordinateurs portables, de plus en plus souvent sur les serveurs 128, 256, etc.
Vraiment beaucoup de mémoire . L'enregistrement banal prend du temps et des ressources, et les
technologies que nous utilisons pour cela sont conservatrices . Les bases de données sont anciennes, elles sont développées depuis longtemps, elles évoluent lentement. Les mécanismes des bases de données ne correspondent pas exactement aux dernières technologies.
La synchronisation des pages en mémoire avec le disque entraîne d'énormes opérations d'E / S. Lorsque nous synchronisons des caches, un grand flux d'E / S survient et un autre problème survient -
nous ne pouvons pas tordre quelque chose et regarder l'effet. Dans une expérience scientifique, les chercheurs modifient un paramètre - obtenir l'effet, le second - obtenir l'effet, le troisième. Nous ne réussirons pas. Nous tordons certains paramètres dans PostgreSQL, configurons les points de contrôle - nous n'avons pas vu l'effet. Ensuite, configurez à nouveau toute la pile afin d'obtenir au moins un résultat. Twist un paramètre ne fonctionne pas - nous sommes obligés de tout configurer à la fois.
La plupart des IO PostgreSQL génèrent la synchronisation des pages: points de contrôle et autres mécanismes de synchronisation. Si vous avez travaillé avec PostgreSQL, vous pourriez avoir vu des pointes de contrôle quand une «scie» apparaît périodiquement sur les graphiques. Auparavant, beaucoup étaient confrontés à ce problème, mais maintenant il existe des manuels sur la façon de le résoudre, il est devenu plus facile.
Aujourd'hui, les SSD sauvent considérablement la situation. Chez PostgreSQL, quelque chose repose rarement directement sur l'enregistrement de valeur. Tout dépend de la synchronisation: quand un point de contrôle se produit, fsync est appelé et il y a une sorte de «frapper» un point de contrôle sur un autre. Trop d'E / S. Un point de contrôle n'est pas encore terminé, n'a pas terminé tous ses fsyncs, mais a déjà gagné un autre point de contrôle, et il a commencé!
PostgreSQL a une fonctionnalité unique -
autovacuum . Il s'agit d'une longue histoire de béquilles pour l'architecture de base de données. Si l'autovacuum ne résiste pas, il est généralement configuré pour fonctionner de manière agressive et ne pas interférer avec le reste: il y a beaucoup de travailleurs de l'autovacuum, se déclenchant fréquemment un peu, traitant rapidement les tables. Sinon, il y aura des problèmes avec DDL et avec les verrous.
Mais lorsque l'Autovacuum est agressif, il commence à mâcher les E / S.
Si l'auto-vide est superposé aux points de contrôle, la plupart du temps, les disques sont recyclés à près de 100%, et c'est la source des problèmes.
Curieusement, il y a un problème de
remplissage du cache . Elle est généralement moins connue pour DBA. Un exemple typique: la base de données a démarré et pendant un certain temps, tout ralentit tristement. Par conséquent, même si vous avez beaucoup de RAM, achetez de bons disques pour que la pile réchauffe le cache.
Tout cela affecte sérieusement les performances. Les problèmes ne commencent pas immédiatement après le redémarrage de la base de données, mais ultérieurement. Par exemple, le point de contrôle a réussi et de nombreuses pages sont sales dans la base de données. Ils sont copiés sur le disque car vous devez les synchroniser. Ensuite, les demandes demandent une nouvelle version des pages du disque et la base de données s'affaisse. Les graphiques montreront comment la recharge du cache après chaque point de contrôle contribue à un certain pourcentage de la charge.
La chose la plus désagréable dans les entrées / sorties de la base de données est
Worker IO. Lorsque chaque travailleur que vous demandez, commence à générer son E / S. Dans Oracle, c'est plus facile avec, mais dans PostgreSQL c'est un problème.
Il existe de nombreuses raisons aux problèmes rencontrés avec
Worker IO : il n'y a pas suffisamment de cache pour «publier» de nouvelles pages à partir du disque. Par exemple, il arrive que tous les tampons soient partagés, ils sont tous sales, les points de contrôle ne l'ont pas encore été. Pour que le travailleur effectue la sélection la plus simple, vous devez prendre le cache quelque part. Pour ce faire, vous devez d'abord tout enregistrer sur le disque. Vous n'avez pas de processus de pointeur de contrôle spécialisé, et le travailleur démarre fsync pour le libérer et le remplir avec quelque chose de nouveau.
Cela pose un problème encore plus important: le travailleur est une chose non spécialisée, et l'ensemble du processus n'est pas du tout optimisé. Il est possible d'optimiser quelque part au niveau Linux, mais dans PostgreSQL, c'est une mesure d'urgence.
Problème d'E / S principal pour DB
Quel problème résolvons-nous lorsque nous mettons en place quelque chose? Nous voulons maximiser le trajet des pages sales entre le disque et la mémoire.
Mais il arrive souvent que ces choses ne touchent pas directement le disque. Un cas typique - vous voyez une très grande moyenne de charge. Pourquoi Parce que quelqu'un attend le disque et tous les autres processus attendent également. Il semble qu'il n'y ait pas d'utilisation explicite des disques, juste quelque chose qui bloque le disque là-bas, et le problème vient de toute façon de l'entrée / sortie.
Les problèmes d'E / S de base de données ne concernent pas toujours uniquement les disques.
Tout est impliqué dans ce problème: disques, mémoire, CPU, IO Schedulers, systèmes de fichiers et paramètres de base de données. Passons maintenant en revue la pile, voyons quoi en faire et quelles bonnes choses ont été inventées sous Linux pour que tout fonctionne mieux.
Disques
Pendant de nombreuses années, les disques étaient terriblement lents et personne n'était impliqué dans la latence ou l'optimisation des étapes de transition. L'optimisation de fsyncs n'avait aucun sens. Le disque tournait, les têtes se déplaçaient comme un disque phonographique et fsyncs était si long que les problèmes ne se posaient pas.
La mémoire
Il est inutile de consulter les principales requêtes sans régler la base de données. Vous allez configurer une quantité suffisante de mémoire partagée, etc., et vous aurez une nouvelle requête supérieure - vous devrez la reconfigurer. Voici la même histoire. La pile Linux entière a été créée à partir de ce calcul.
Bande passante et latence
Maximiser les performances d'E / S en maximisant le débit est facile jusqu'à un certain point. Un processus PageWriter auxiliaire a été inventé dans PostgreSQL qui déchargeait le point de contrôle. Le travail est devenu parallèle, mais il reste encore des bases pour l'ajout du parallélisme. Et minimiser la latence est la tâche du dernier kilomètre, pour laquelle des super technologies sont nécessaires.
Ces super technologies sont des SSD. Lorsqu'elles sont apparues, la latence a fortement chuté. Mais à toutes les autres étapes de la pile, des problèmes sont apparus: tant du côté des fabricants de bases de données que des fabricants Linux. Les problèmes doivent être résolus.
Le développement de la base de données s'est concentré sur la maximisation du débit, tout comme le développement du noyau Linux. De nombreuses méthodes pour optimiser l'ère d'E / S des disques en rotation ne sont pas aussi bonnes pour les SSD.
Entre les deux, nous avons été contraints de sauvegarder pour l'infrastructure Linux actuelle, mais avec de nouveaux disques. Nous avons regardé les tests de performances du fabricant avec un grand nombre d'IOPS différents, et la base de données ne s'est pas améliorée, car la base de données n'est pas seulement et pas tellement sur IOPS. Il arrive souvent que nous puissions sauter 50 000 IOPS par seconde, ce qui est bien. Mais si nous ne connaissons pas la latence, ne connaissons pas sa distribution, alors nous ne pouvons rien dire sur les performances. À un moment donné, la base de données commencera à vérifier et la latence augmentera considérablement.
Pendant longtemps, comme maintenant, cela a été un gros problème de performances sur les bases de données virtuala. Les E / S virtuelles se caractérisent par une latence inégale, ce qui, bien sûr, entraîne également des problèmes.
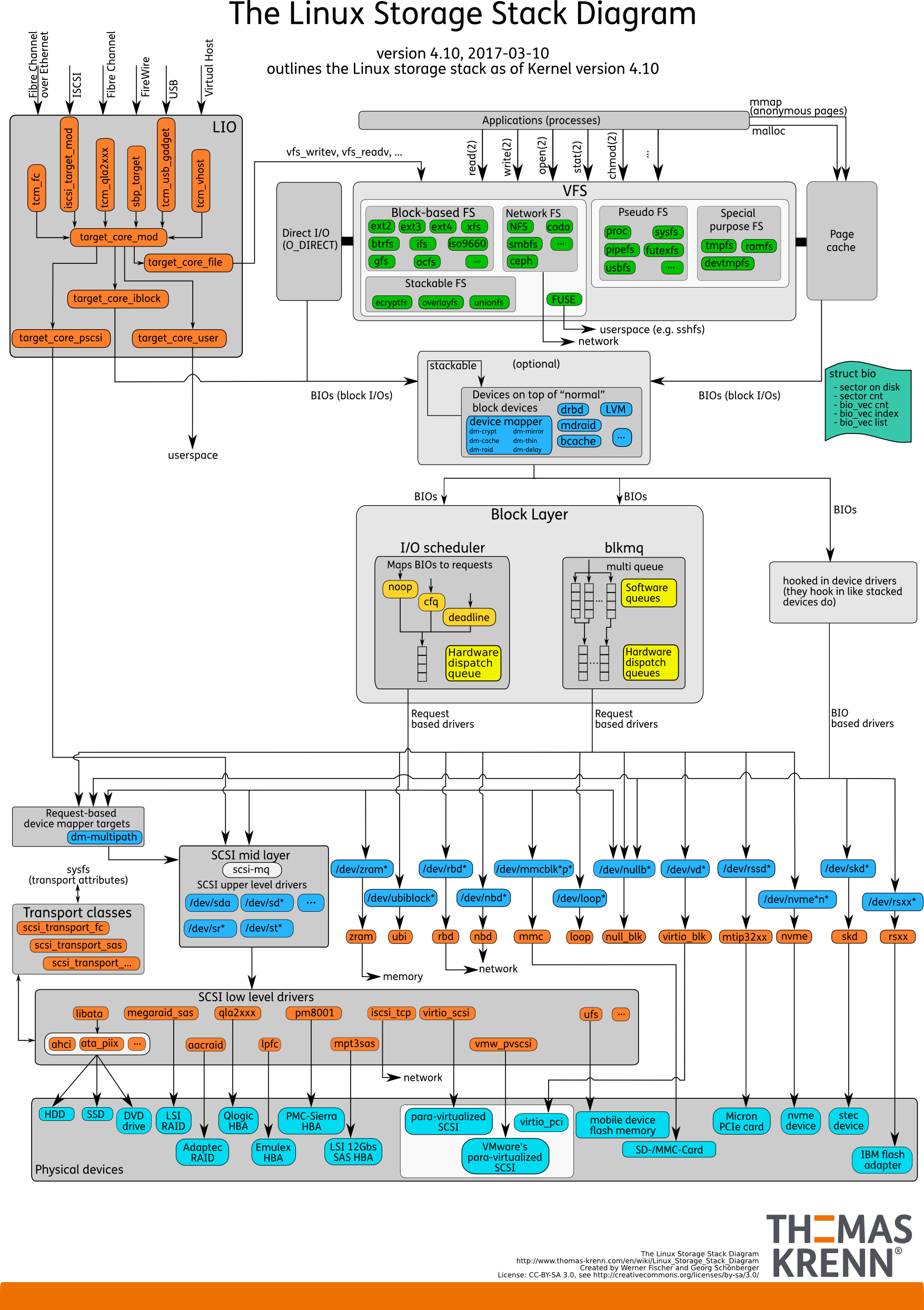
Pile d'E / S. Comme avant
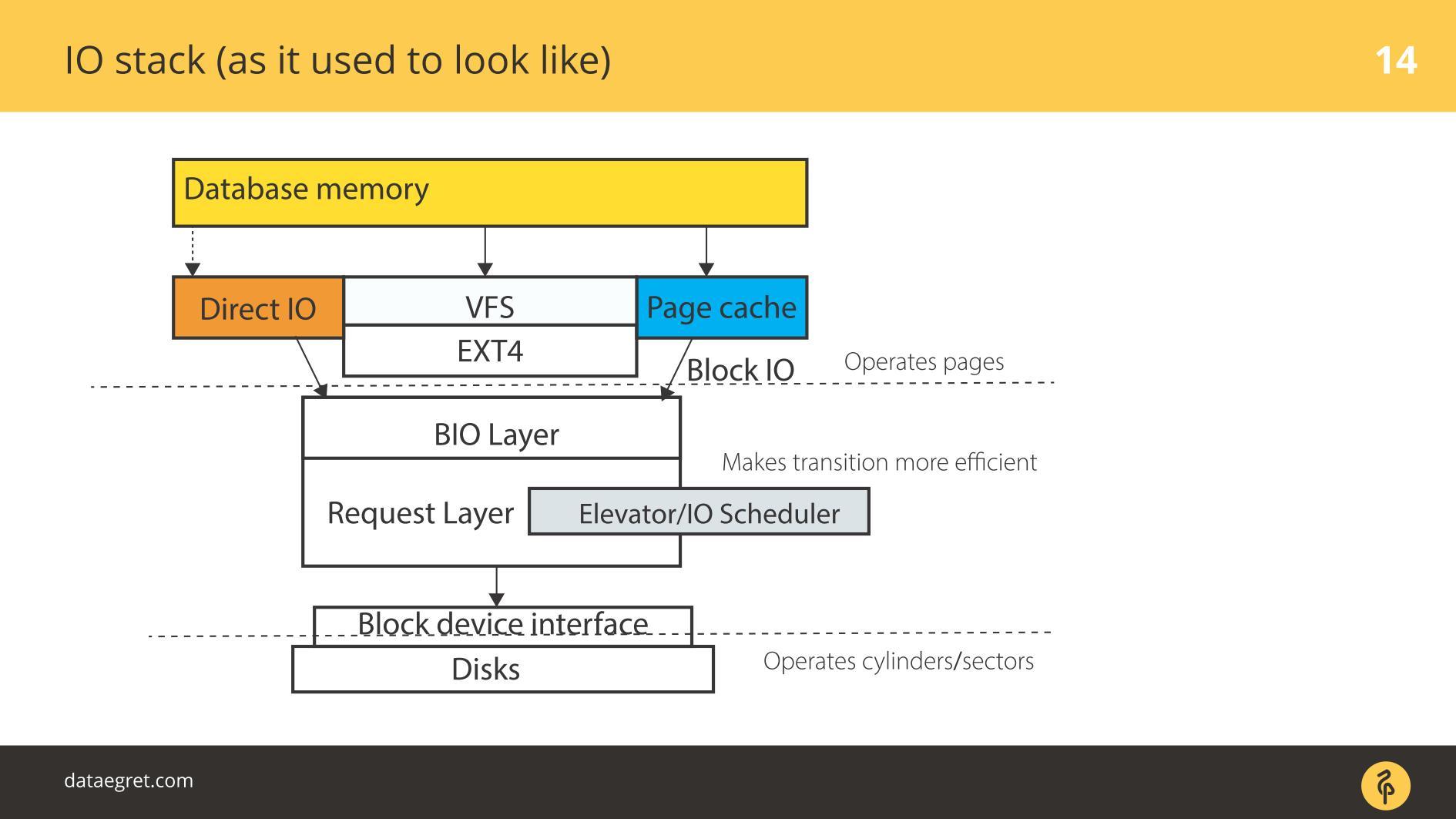
Il y a de l'espace utilisateur - cette mémoire, qui est gérée par la base de données elle-même. Dans une base de données configurée pour que tout fonctionne comme il se doit. Cela peut être fait dans un rapport séparé, et même pas un. Ensuite, tout passe inévitablement par Page Cache ou par l'interface Direct IO, il entre dans la
couche Block Input / Output .
Imaginez une interface de système de fichiers. Les pages qui se trouvaient dans le Buffer Cache, comme elles étaient à l'origine dans la base de données, c'est-à-dire les blocs, disparaissent à travers elle. La couche Block IO traite des éléments suivants. Il existe une structure C qui décrit un bloc dans le noyau. La structure prend ces blocs et en recueille des vecteurs (tableaux) de requêtes d'entrée ou de sortie. Sous la couche BIO se trouve la couche demandeur. Les vecteurs sont collectés sur cette couche et iront plus loin.
Pendant longtemps, ces deux couches sous Linux ont été affinées pour un enregistrement efficace sur disques magnétiques. Il était impossible de se passer d'une transition. Il existe des blocs faciles à gérer à partir de la base de données. Il est nécessaire d'assembler ces blocs en vecteurs qui sont commodément écrits sur le disque afin qu'ils se trouvent quelque part à proximité. Pour que cela fonctionne efficacement, ils ont mis au point des ascenseurs ou des planificateurs IO.
Ascenseurs
Les ascenseurs étaient principalement impliqués dans la combinaison et le tri des vecteurs. Tout cela pour que le pilote de bloc SD - le pilote de quasi-disque - les blocs d'enregistrement arrivent dans l'ordre qui lui convient. Le pilote a traduit des blocs dans ses secteurs et écrit sur le disque.
Le problème était qu'il fallait faire plusieurs transitions, et à chaque implémenter leur propre logique du processus optimal.
Ascenseurs: jusqu'au noyau 2.6
Avant le noyau 2.6, il y avait Linus Elevator - le planificateur d'E / S le plus primitif, écrit par vous qui devinez qui. Pendant longtemps, il a été considéré comme absolument inébranlable et bon, jusqu'à ce qu'ils développent quelque chose de nouveau.
Linus Elevator a eu beaucoup de problèmes.
Il a combiné et trié selon la façon d'enregistrer plus efficacement . Dans le cas des disques mécaniques rotatifs, cela a conduit à l'émergence de la "
famine" : une situation où l'efficacité d'enregistrement dépend de la rotation du disque. Si vous avez soudainement besoin de lire efficacement en même temps, mais qu'il est déjà mal tourné, il est mal lu à partir d'un tel disque.
Peu à peu, il est devenu clair que c'était une manière inefficace. Par conséquent, à partir du noyau 2.6, tout un zoo d'ordonnanceurs a commencé à apparaître, destiné à différentes tâches.
Ascenseurs: entre 2,6 et 3
Beaucoup de gens confondent ces planificateurs avec les planificateurs du système d'exploitation car ils ont des noms similaires.
CFQ - Completely Fair Queuing n'est pas la même chose que les planificateurs de système d'exploitation. Seuls les noms sont similaires. Il a été inventé comme un planificateur universel.
Qu'est-ce qu'un planificateur universel? Pensez-vous que vous avez une charge moyenne ou, au contraire, unique? Les bases de données ont une très faible polyvalence. La charge universelle peut être imaginée comme un ordinateur portable ordinaire. Tout s'y passe: on écoute de la musique, on joue, on tape du texte. Pour cela, seuls des ordonnanceurs universels ont été écrits.
La tâche principale de l'ordonnanceur universel: dans le cas de Linux, pour chaque terminal virtuel et processus, créer une file d'attente de requêtes. Lorsque nous voulons écouter de la musique dans un lecteur audio, IO pour le lecteur prend une file d'attente. Si nous voulons sauvegarder quelque chose en utilisant la commande cp, quelque chose d'autre est impliqué.
Dans le cas des bases de données, un problème se produit. En règle générale, une base de données est un processus qui a démarré et, pendant son fonctionnement, des processus parallèles sont apparus qui se terminent toujours dans la même file d'attente d'E / S. La raison en est qu'il s'agit de la même application, du même processus parent. Pour de très petites charges, une telle programmation était appropriée, pour le reste cela n'avait pas de sens. Il était plus facile de l'éteindre et de ne pas l'utiliser si possible.
Progressivement, le
planificateur de délais est apparu - il fonctionne de manière plus astucieuse, mais il s'agit essentiellement de fusion et de tri pour les disques en rotation. Étant donné la conception d'un sous-système de disque spécifique, nous collectons des vecteurs de bloc pour les écrire de la manière optimale. Il avait moins de problèmes de
famine , mais ils étaient là.
Par conséquent, plus près du troisième noyau Linux est apparu
noop ou
none , ce qui fonctionnait beaucoup mieux avec la propagation des SSD. En incluant l'ordonnanceur noop, nous désactivons en fait l'ordonnancement: il n'y a pas de tri, de fusion et d'autres choses similaires à CFQ et à la date limite.
Cela fonctionne mieux avec les SSD, car les SSD sont intrinsèquement parallèles: il a des cellules de mémoire. Plus il y a de ces éléments à entasser sur une carte PCIe, plus il fonctionnera efficacement.
Scheduler de certains de ses autres mondes, du point de vue du SSD, considérations, recueille certains vecteurs et les envoie quelque part. Tout se termine par un entonnoir. Donc, nous tuons la concurrence des SSD, ne les utilisez pas au maximum. Par conséquent, un simple arrêt, lorsque les vecteurs vont au hasard sans aucun tri, a mieux fonctionné en termes de performances. Pour cette raison, on pense que les lectures aléatoires, l'écriture aléatoire sont meilleures sur les SSD.
Ascenseurs: à partir de 3,13
À partir du noyau 3.13,
blk-mq est apparu . Un peu plus tôt, il y avait un prototype, mais en 3.13 une version fonctionnelle est apparue pour la première fois.
Blk-mq a commencé comme un planificateur, mais il est difficile de l'appeler un planificateur - il est autonome sur le plan architectural. Il s'agit d'un remplacement pour la couche de demande dans le noyau. Lentement, le développement de blk-mq a conduit à une refonte majeure de l'ensemble de la pile d'E / S Linux.
L'idée est la suivante: utilisons la capacité native des SSD pour effectuer une concurrence efficace pour les E / S. Selon le nombre de flux d'E / S parallèles que vous pouvez utiliser, il existe des files d'attente honnêtes à travers lesquelles nous écrivons simplement telles quelles sur le SSD. Chaque CPU a sa propre file d'attente pour l'enregistrement.
Actuellement,
blk-mq se développe et fonctionne activement. Il n'y a aucune raison de ne pas l'utiliser. Dans les cœurs modernes, à partir de 4 et plus, à partir de
blk-mq, le gain est perceptible - pas 5-10%, mais beaucoup plus.
blk-mq est probablement la meilleure option pour travailler avec des SSD.
Dans sa forme actuelle,
blk-mq est directement lié au pilote
NVMe Linux. Il n'y a pas seulement un pilote pour Linux, mais aussi un pilote pour Microsoft. Mais l'idée de faire
blk-mq et le pilote NVMe est le traitement même de la pile Linux, dont les bases de données ont grandement bénéficié.
Un consortium de plusieurs sociétés a décidé de faire une spécification, ce protocole même. Maintenant, il fonctionne déjà bien en version de production pour les SSD PCIe locaux. Solution presque prête pour les baies de disques connectées via des optiques.
Le pilote blk-mq et NVMe sont plus qu'un planificateur. Le système vise à remplacer l'ensemble du niveau des demandes.
Plongeons-nous pour comprendre ce que c'est. La spécification NVMe est grande, donc nous ne prendrons pas en compte tous les détails, mais passons simplement en revue.
Ancienne approche des ascenseurs

Le cas le plus simple: il y a un CPU, il y a son tour, et en quelque sorte on va sur disque.
Les ascenseurs plus avancés fonctionnaient différemment. Il y a plusieurs CPU et plusieurs files d'attente. D'une manière ou d'une autre, par exemple, en fonction du processus parent auquel les travailleurs de la base de données ont filé, IO est mis en file d'attente sur les disques.
Une nouvelle approche des ascenseurs
blk-mq est une approche complètement nouvelle. Chaque CPU, chaque zone NUMA ajoute à son tour sa propre entrée / sortie. De plus, les données tombent sur les disques, quelle que soit leur connexion, car le pilote est nouveau. Il n'y a pas de pilote SD qui fonctionne avec les concepts de cylindres, de blocs.
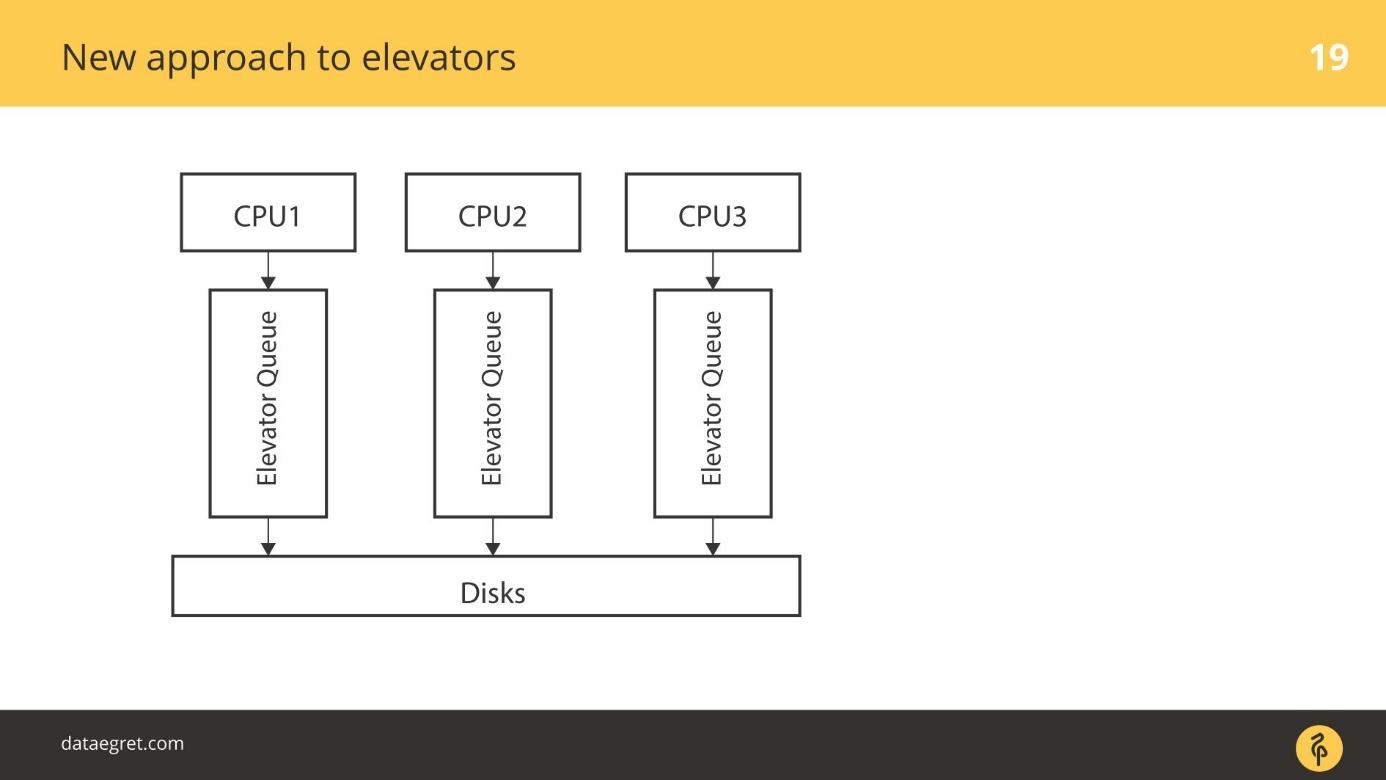
Il y a eu une période de transition. À un moment donné, tous les fournisseurs de baies RAID ont commencé à vendre des modules complémentaires qui leur permettaient de contourner le cache RAID. Si les SSD sont connectés, écrivez directement à cet endroit. Ils ont désactivé l'utilisation du pilote SD pour leurs produits, comme blq-mq.
Nouvelle pile avec blk-mq
Voici à quoi ressemble la pile sous une nouvelle forme.

D'en haut, tout reste aussi. Par exemple, les bases de données sont loin derrière. Les E / S de la base de données, comme précédemment, tombent dans la couche Block IO. Il y a le très
blk-mq qui remplace la couche de requête, pas le planificateur.
Dans le noyau 3.13, toute l'optimisation s'est terminée à peu près à ce sujet, mais de nouvelles technologies sont utilisées dans les noyaux modernes. Des ordonnanceurs spéciaux pour
blk-mq ont commencé à apparaître, qui sont conçus pour un parallélisme plus fort. Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
, , , Elevators, .
, , .
NVM Express
NVM Express NVMe — , , SSD. Linux. Linux — .
. 20 / SSD , NVMe , , —
32 / . SD , , .
, , .
Une fois que les bases de données ont été écrites pour les disques rotatifs et orientées vers eux, elles ont des index sous la forme d'un arbre B, par exemple. La question se pose:
les bases de données sont-elles prêtes pour NVMe ? Les bases de données sont-elles capables de mâcher une telle charge?
Pas encore, mais ils s'adaptent. La liste de diffusion PostgreSQL a récemment eu quelques
pwrite() et des choses similaires. Les développeurs PostgreSQL et MySQL interagissent avec les développeurs du noyau. Bien sûr, j'aimerais plus d'interaction.
Développements récents
Au cours de la dernière année et demie, NVMe a ajouté le
sondage IO .
Au début, il y avait des disques qui tournaient avec une latence élevée. Viennent ensuite les SSD, qui sont beaucoup plus rapides. Mais il y avait un jambage: fsync continue, l'enregistrement démarre et à un niveau très bas - profondément dans le pilote, une demande est envoyée directement au matériel - notez-le.
Le mécanisme était simple - ils l'ont envoyé et nous attendons que l'interruption soit traitée. L'attente du traitement d'interruption n'est pas un problème par rapport à l'écriture sur un disque en rotation. Il a fallu si longtemps pour attendre que dès la fin de l'enregistrement, l'interruption a fonctionné.
Depuis que le SSD écrit très rapidement, un mécanisme pour interroger le matériel sur l'enregistrement est apparu de force. Dans les premières versions, l'augmentation de la vitesse d'E / S a atteint 50% du fait que nous n'attendons pas d'interruption, mais nous demandons activement le morceau de fer à propos du record.
Ce mécanisme est appelé interrogation IO .
Il a été introduit dans les versions récentes. Dans la version 4.12, des
ordonnanceurs IO sont apparus, spécialement affinés pour travailler avec
blk-mq et NVMe, à propos desquels j'ai dit
Kyber et BFQ . Ils sont déjà officiellement dans le noyau, ils peuvent être utilisés.
Maintenant, sous une forme utilisable, il y a ce qu'on appelle le
marquage IO . La plupart des fabricants de clouds et de machines virtuelles contribueront à ce développement. En gros, l'apport d'une application spécifique peut être cloué et lui donner la priorité. Les bases de données ne sont pas encore prêtes pour cela, mais restez à l'écoute. Je pense que ce sera bientôt le courant dominant.
Notes d'E / S directes
PostgreSQL ne prend pas en charge Direct IO, et il existe un certain nombre de problèmes qui rendent difficile l'activation de la prise en charge . Maintenant, cela n'est pris en charge que pour la valeur, et uniquement si la réplication n'est pas activée. Il est nécessaire
d'écrire beaucoup de code spécifique au système d'exploitation , et pour l'instant tout le monde s'en abstient.
Malgré le fait que Linux jure fortement sur l'idée de Direct IO et sur la façon dont il est implémenté, toutes les bases de données y vont. Dans Oracle et MySQL, Direct IO est largement utilisé. PostgreSQL est la seule base de données que Direct IO ne tolère pas.
Liste de contrôle
Comment vous protéger des surprises fsync dans PostgreSQL:
- Configurez des points de contrôle pour qu'ils soient moins fréquents et plus grands.
- Configurez un rédacteur en arrière-plan pour aider à vérifier
- Tirez Autovacuum pour qu'il n'y ait pas d'E / S parasites inutiles.
Selon la tradition, en novembre, nous attendons des développeurs professionnels de services hautement chargés à Skolkovo sur HighLoad ++ . Il reste encore un mois pour demander un rapport, mais nous avons déjà accepté les premiers rapports au programme . Inscrivez-vous à notre newsletter et découvrez de nouveaux sujets de première main.