
Exprimer ce que les mots ne peuvent pas transmettre; Ressentez les émotions les plus diverses entrelacées dans un ouragan de sentiments; rompre avec la terre, le ciel et même l'Univers lui-même, partir en voyage où il n'y a ni cartes, ni routes, ni panneaux; inventer, raconter et revivre toute une histoire qui restera toujours unique et inimitable. Tout cela vous permet de faire de la musique - un art qui existe depuis des milliers d'années et ravit nos oreilles et nos cœurs.
Cependant, la musique, ou plutôt la musique, peut servir non seulement pour le plaisir esthétique, mais aussi pour transmettre des informations encodées en eux, destinées à tout appareil et invisibles pour l'auditeur. Aujourd'hui, nous vous rencontrerons une étude très inhabituelle, dans laquelle des étudiants diplômés de l'Ecole supérieure technique suisse de Zurich ont pu insérer imperceptiblement certaines données dans des œuvres musicales pour l'oreille humaine, grâce à quoi la musique elle-même devient un canal de transmission de données. Comment exactement ont-ils réalisé leur technologie, les mélodies sont-elles très différentes avec et sans données embarquées, et que montrent les tests pratiques? Nous en apprenons à partir du rapport des chercheurs. Allons-y.
Base d'étude
Les chercheurs appellent leur technologie une technique de transmission de données acoustiques. Lorsqu'un locuteur reproduit une mélodie modifiée, une personne la perçoit comme d'habitude, mais, par exemple, un smartphone peut lire des informations codées entre les lignes, plus précisément entre les notes, si je puis dire. L'aspect le plus important dans la mise en œuvre de cette méthode de transfert de données, les scientifiques (le fait que ces gars-là sont encore des étudiants diplômés ne les empêchent pas d'être des scientifiques) appellent la vitesse et la fiabilité de la transmission tout en maintenant le niveau de ces paramètres, quel que soit le fichier audio sélectionné. La psychoacoustique, qui étudie les aspects psychologiques et physiologiques de la perception humaine des sons, aide à faire face à cette tâche.
Le cœur de la transmission de données acoustiques peut être appelé OFDM (multiplexage par répartition orthogonale de la fréquence), qui, avec l'adaptation des sous-porteuses à la musique originale au fil du temps, a permis de maximiser l'utilisation du spectre de fréquences transmis pour la transmission d'informations. Grâce à cela, il a été possible d'atteindre une vitesse de transmission de 412 bit / s sur une distance de 24 mètres (taux d'erreur <10%). Des expériences pratiques impliquant 40 volontaires ont confirmé le fait qu'il est presque impossible d'entendre la différence entre la mélodie originale et celle dans laquelle l'information était intégrée.
Où cette technologie peut-elle être appliquée dans la pratique? Les chercheurs ont leur propre réponse: presque tous les smartphones, ordinateurs portables et autres appareils portables modernes sont équipés de microphones, et dans de nombreux lieux publics (cafés, restaurants, centres commerciaux, etc.), il y a des haut-parleurs avec une musique de fond. Par exemple, les données de connexion à un réseau Wi-Fi peuvent être intégrées dans cette mélodie d'arrière-plan sans qu'il soit nécessaire d'effectuer des actions supplémentaires.
Les caractéristiques générales de la transmission de données acoustiques sont devenues claires pour nous, maintenant nous nous tournons vers une étude détaillée de la structure de ce système.
Description du système
L'incorporation de données dans une mélodie se produit en raison du masquage de fréquence. Dans les intervalles de temps, les fréquences de masquage sont identifiées et les sous-porteuses OFDM proches de ces éléments de masquage sont remplies de données.
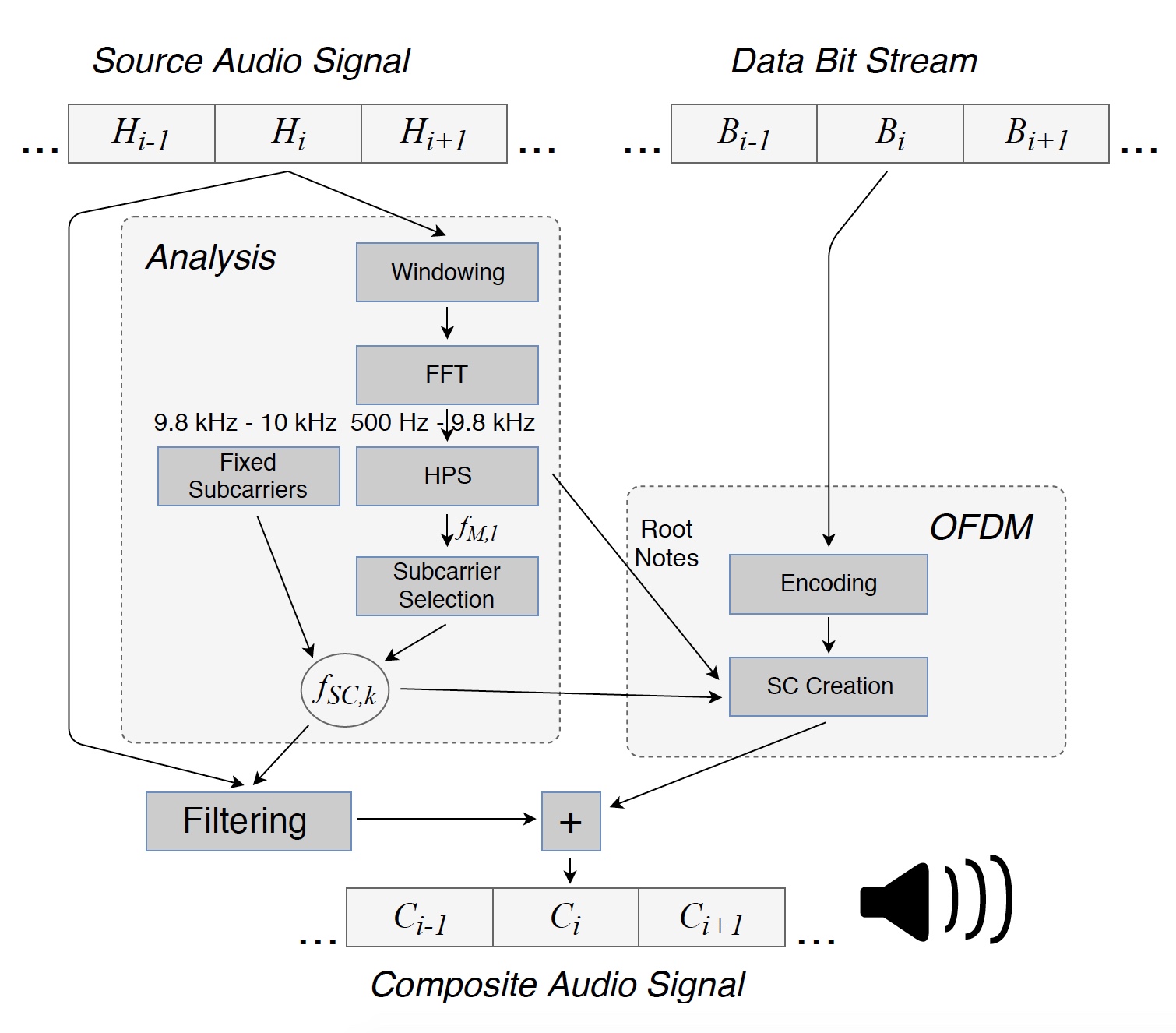 Image # 1: Convertissez le fichier source en un signal composite (mélodie + données) transmis par les haut-parleurs.
Image # 1: Convertissez le fichier source en un signal composite (mélodie + données) transmis par les haut-parleurs.Pour commencer, le signal audio d'origine est divisé en segments consécutifs pour analyse. Chacun de ces segments (H
i ) de L = 8820 échantillons, égal à 200 ms, est multiplié par une
fenêtre * pour minimiser les effets de frontière.
La fenêtre * est la fonction de poids utilisée pour contrôler les effets dus à la présence de lobes latéraux dans les estimations spectrales.
Ensuite, les fréquences dominantes du signal initial ont été trouvées dans la gamme de 500 Hz à 9,8 kHz, ce qui a permis d'obtenir des fréquences de masquage f
M, l pour ce segment. De plus, des données ont été transmises dans la petite plage de 9,8 à 10 kHz pour déterminer l'emplacement des sous-porteuses dans le récepteur. La limite supérieure de la plage de fréquences utilisée a été fixée à 10 kHz en raison de la faible sensibilité du microphone du smartphone aux hautes fréquences.
Les fréquences de masquage ont été déterminées individuellement pour chaque segment analysé. En utilisant la méthode HPS (spectre harmonique des produits), trois fréquences dominantes ont été établies, après quoi elles ont été arrondies aux notes les plus proches de l'échelle chromatique harmonique. C'est ainsi que les notes principales f
F, i = 1 ... 3, situées entre les touches C0 (16,35 Hz) et B0 (30,87 Hz) ont été obtenues. En se basant sur le fait que les notes principales sont trop basses pour être utilisées dans la transmission de données, dans la plage de 500 Hz à 9,8 kHz, leurs octaves supérieures 2
k f
F, i ont été calculées. Beaucoup de ces fréquences (f
O, l 1 ) étaient plus prononcées en raison de la nature des HPS.
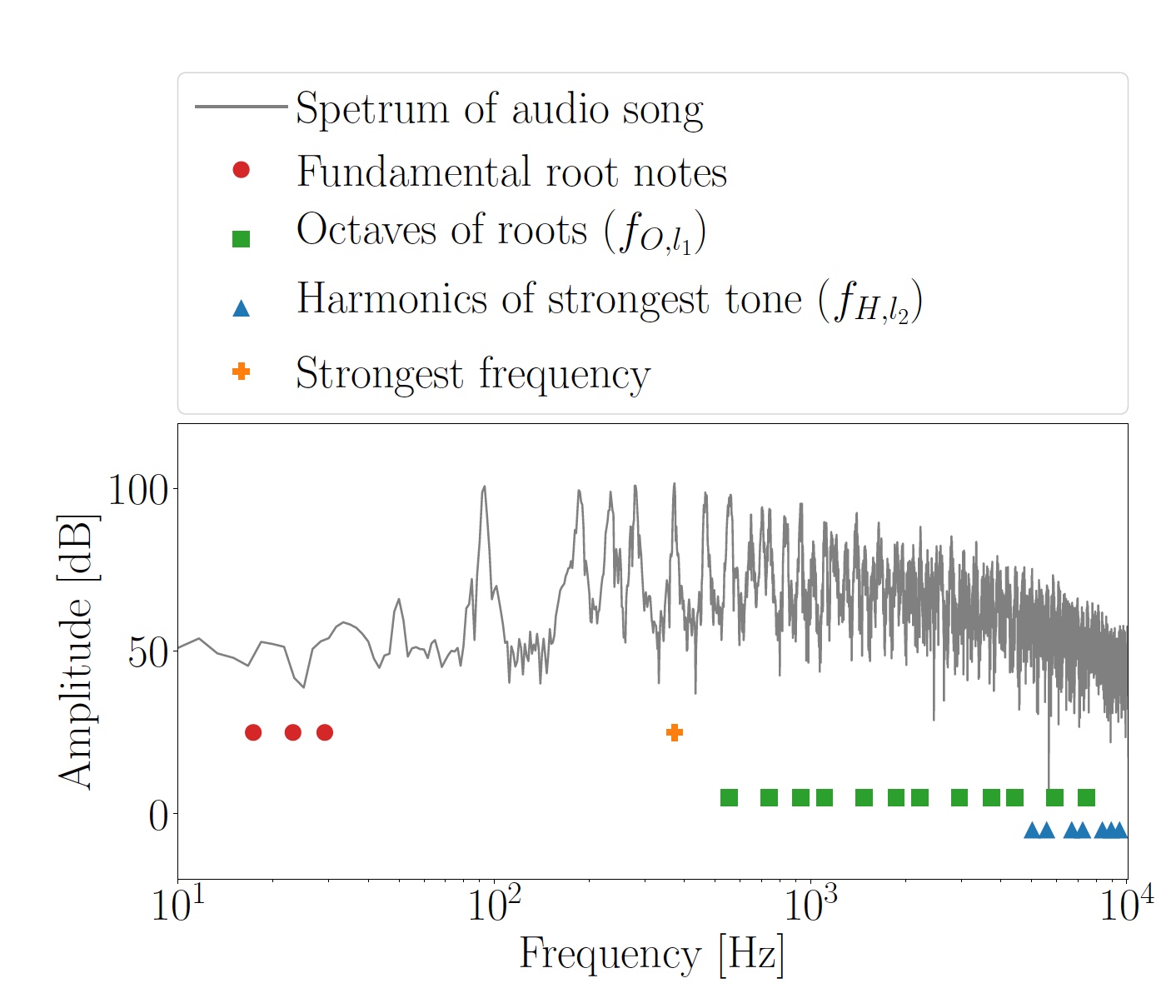 Image n ° 2: octaves calculées f O, l 1 pour les notes principales et harmoniques f H, l 2 du ton le plus fort.
Image n ° 2: octaves calculées f O, l 1 pour les notes principales et harmoniques f H, l 2 du ton le plus fort.La totalité des octaves et des harmoniques a été utilisée comme fréquences de masquage, sur la base desquelles les fréquences OFDM de la sous-porteuse f
SC, k ont été obtenues. Au-dessous et au-dessus de chaque fréquence de masquage, deux sous-porteuses ont été insérées.
Ensuite, le spectre du segment audio H
i a été filtré aux fréquences de sous-porteuses f
SC, k . Ensuite, sur la base des bits d'information dans Bi, un symbole OFDM a été créé, grâce auquel le segment composite C
i pouvait être transmis par le haut-parleur. Les valeurs et les phases des sous-porteuses doivent être sélectionnées afin que le récepteur puisse récupérer les données transmises, tandis que l'auditeur ne remarque pas de changements dans la mélodie.
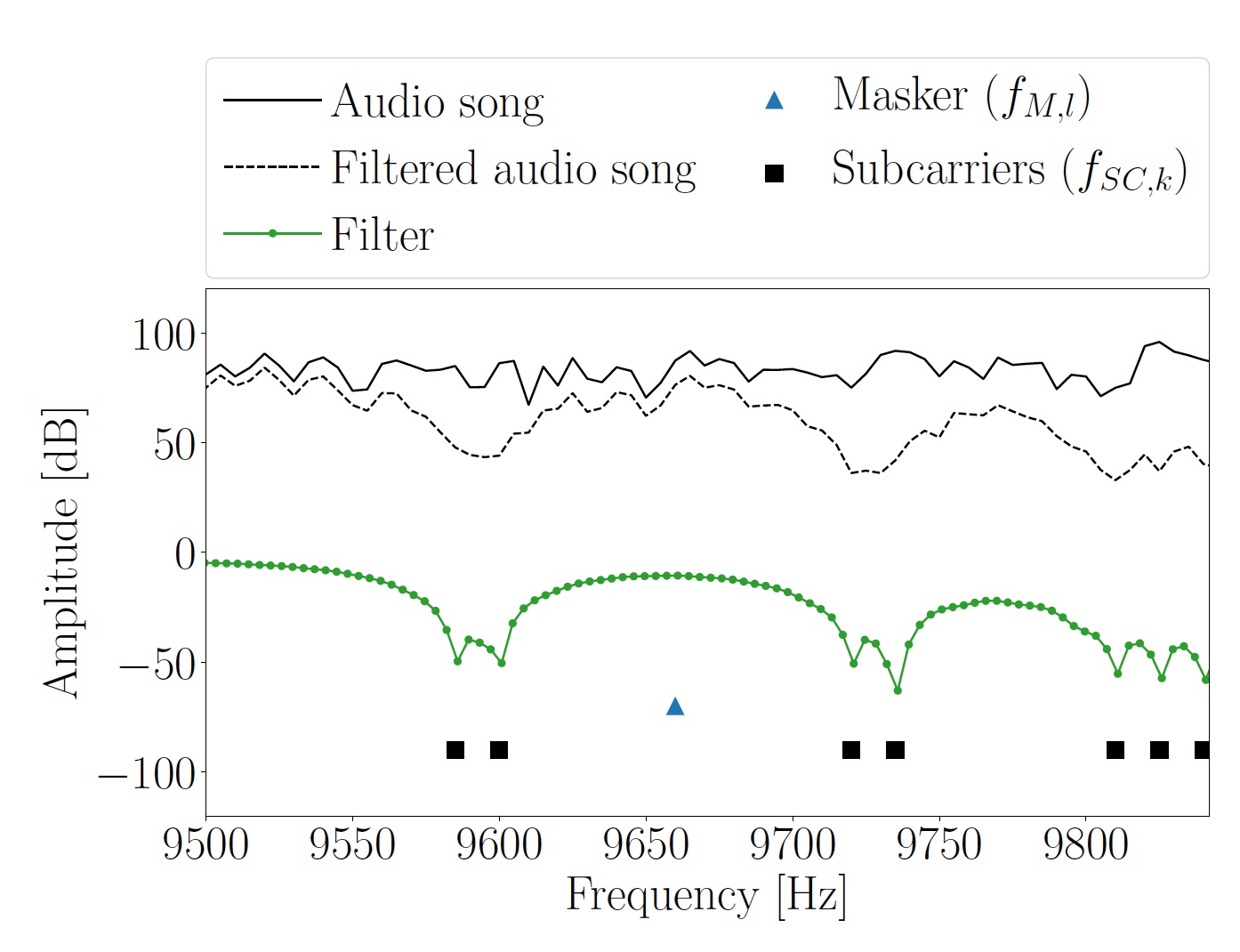 Image 3: tracé du spectre et de la fréquence des sous-porteuses du segment Hi de la mélodie originale.
Image 3: tracé du spectre et de la fréquence des sous-porteuses du segment Hi de la mélodie originale.Lorsqu'un signal audio contenant les informations encodées est reproduit par les haut-parleurs, le microphone de l'appareil récepteur l'enregistre. Pour trouver les positions de départ des symboles OFDM intégrés, les entrées doivent d'abord être ignorées via le filtrage passe-bande. De cette manière, la plage de fréquence supérieure est extraite là où il n'y a pas de signal d'interférence musicale entre les sous-porteuses. Vous pouvez trouver le début des symboles OFDM en utilisant un préfixe cyclique.
Après avoir détecté le début des symboles OFDM, le récepteur obtient des informations sur les notes les plus dominantes en décodant le domaine de fréquence supérieur. De plus, l'OFDM est suffisamment robuste contre les sources d'interférence à bande étroite, car elles n'affectent que certaines des sous-porteuses.
Tests pratiques
Le haut-parleur KRK Rokit 8 a agi comme la source des mélodies modifiées et le smartphone Nexus 5X a joué le côté hôte.
 Image 4: Différence entre les manifestations réelles de l'OFDM et les pics de corrélation mesurés à l'intérieur à une distance de 5 m entre le haut-parleur et le microphone.
Image 4: Différence entre les manifestations réelles de l'OFDM et les pics de corrélation mesurés à l'intérieur à une distance de 5 m entre le haut-parleur et le microphone.La plupart des points OFDM vont de 0 à 25 ms, vous pouvez donc trouver un début valide dans le préfixe cyclique de 66,6 ms. Les chercheurs notent que le récepteur (dans cette expérience, un smartphone) tient compte du fait que les symboles OFDM sont reproduits périodiquement, ce qui améliore leur détection.
La première chose à vérifier était l'effet de la distance sur le taux d'erreur sur les bits (BER). Pour ce faire, trois tests ont été réalisés dans différents types de pièces: un couloir avec moquette, un bureau avec du linoléum au sol et un public avec du parquet.
La chanson «And The Cradle Will Rock» de Van Halen a été choisie comme «sujet de test».Le volume sonore a été réglé de sorte que le niveau sonore mesuré par le smartphone à une distance de 2 m du haut-parleur soit de 63 dB.
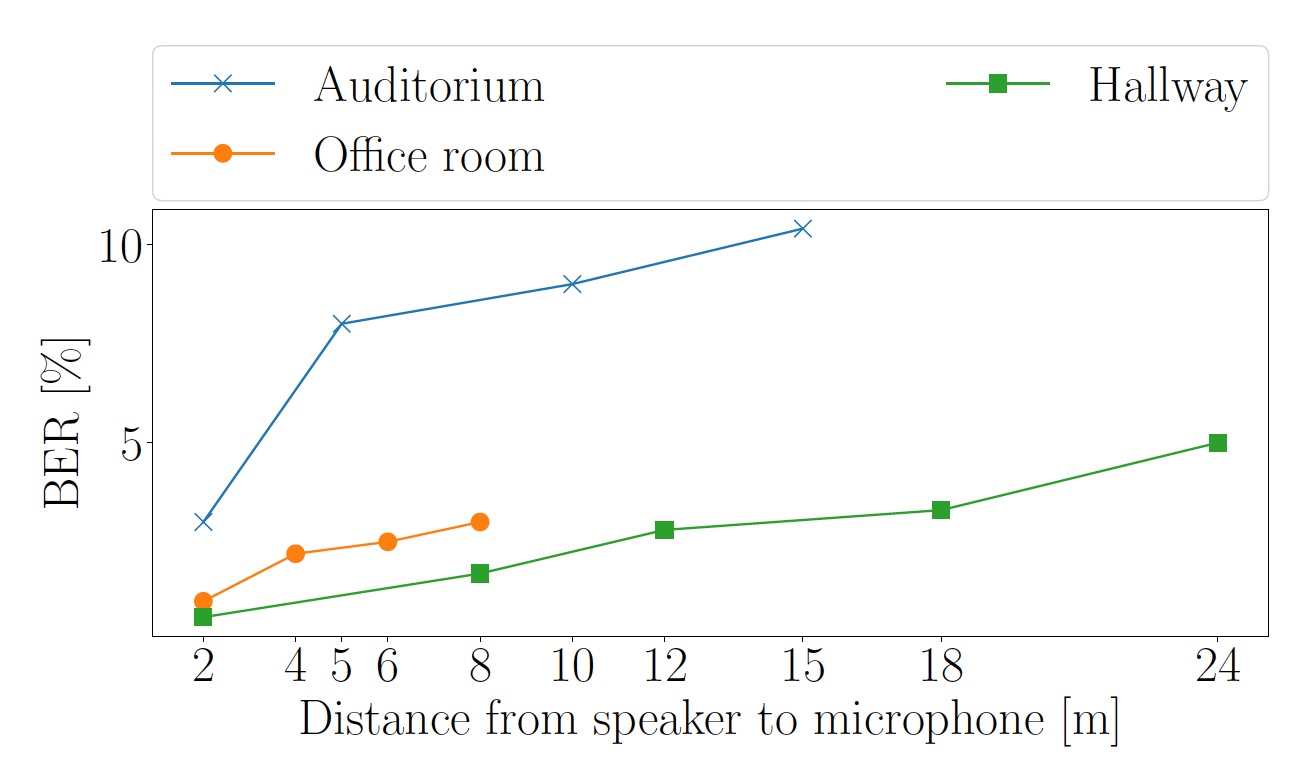 Image n ° 5: indicateurs BER en fonction de la distance entre le haut-parleur et le microphone (ligne bleue - public, vert - couloir, orange - bureau).
Image n ° 5: indicateurs BER en fonction de la distance entre le haut-parleur et le microphone (ligne bleue - public, vert - couloir, orange - bureau).Dans le couloir, un son de 40 dB a été capté par un smartphone à une distance maximale de 24 mètres du haut-parleur. Dans le public à une distance de 15 m, le son était de 55 dB, et dans le bureau à une distance de 8 mètres, le niveau de son perçu par le smartphone atteignait 57 dB.
Du fait que l'audience et le bureau sont plus réverbérants, les échos des symboles OFDM tardifs dépassent la longueur du préfixe cyclique et augmentent le BER.
Reverb * - une diminution progressive de l'intensité sonore en raison de sa réflexion multiple.
De plus, les chercheurs ont démontré la polyvalence de leur système en l'appliquant à 6 chansons différentes de trois genres (tableau ci-dessous).
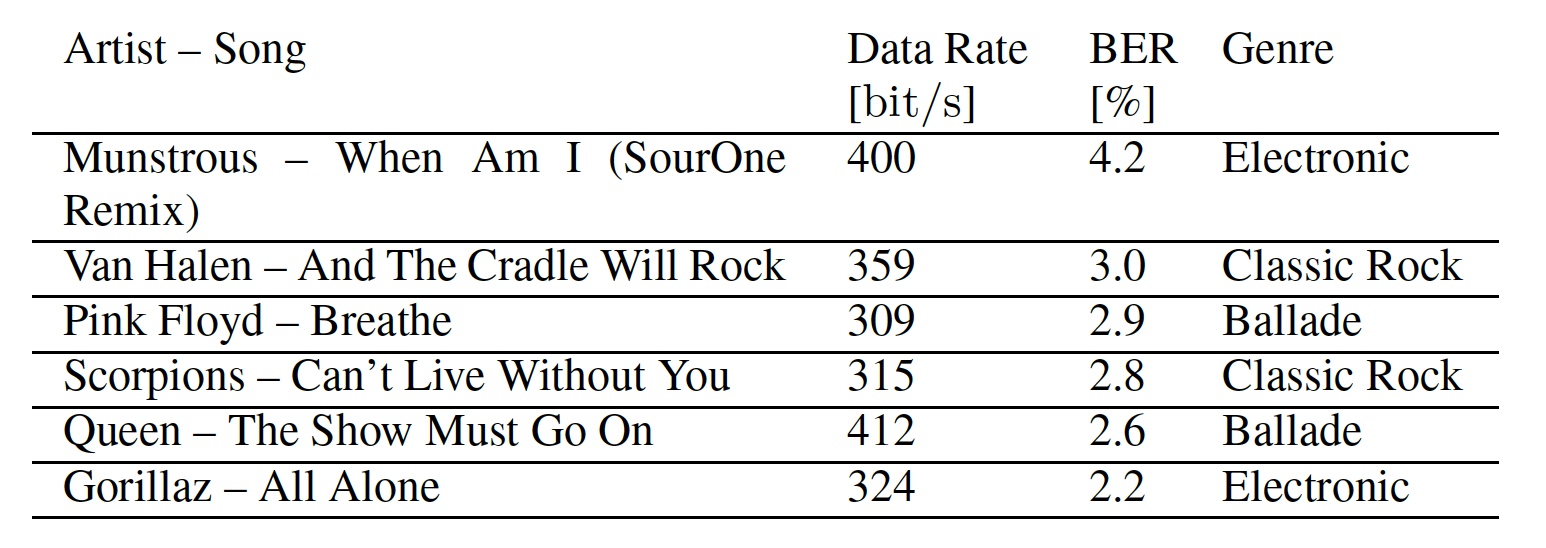 Tableau n ° 1: chansons utilisées dans les tests.
Tableau n ° 1: chansons utilisées dans les tests.De plus, grâce aux données du tableau, nous pouvons voir le débit binaire et les taux d'erreur binaire pour chaque morceau. La vitesse de transfert de données est différente car le BPSK différentiel (incrémentation de déphasage) fonctionne mieux lorsque les mêmes sous-porteuses sont utilisées. Et cela est possible lorsque des segments adjacents contiennent les mêmes éléments de masquage. Les chansons continuellement fortes fournissent une base optimale pour masquer les données, car les fréquences de masquage sont plus prononcées dans une large gamme de fréquences. Une musique qui change rapidement ne peut masquer les symboles OFDM que partiellement en raison de la longueur fixe de la fenêtre d'analyse.
Ensuite, les gens ont commencé à tester le système, qui était censé déterminer quelle mélodie était originale et laquelle avait été modifiée par les informations qui y étaient intégrées. Pour cela, des extraits de chansons de 12 secondes de la table n ° 1 ont été postés sur un site spécial.
Dans la première expérience (E1), chaque participant a reçu un fragment modifié ou original pour l'écoute, et il a dû décider si ce fragment était original ou changé. Dans la deuxième expérience (E2), les participants pourraient écouter les deux options autant de fois qu'ils le souhaitent, puis décider laquelle est originale et laquelle est modifiée.
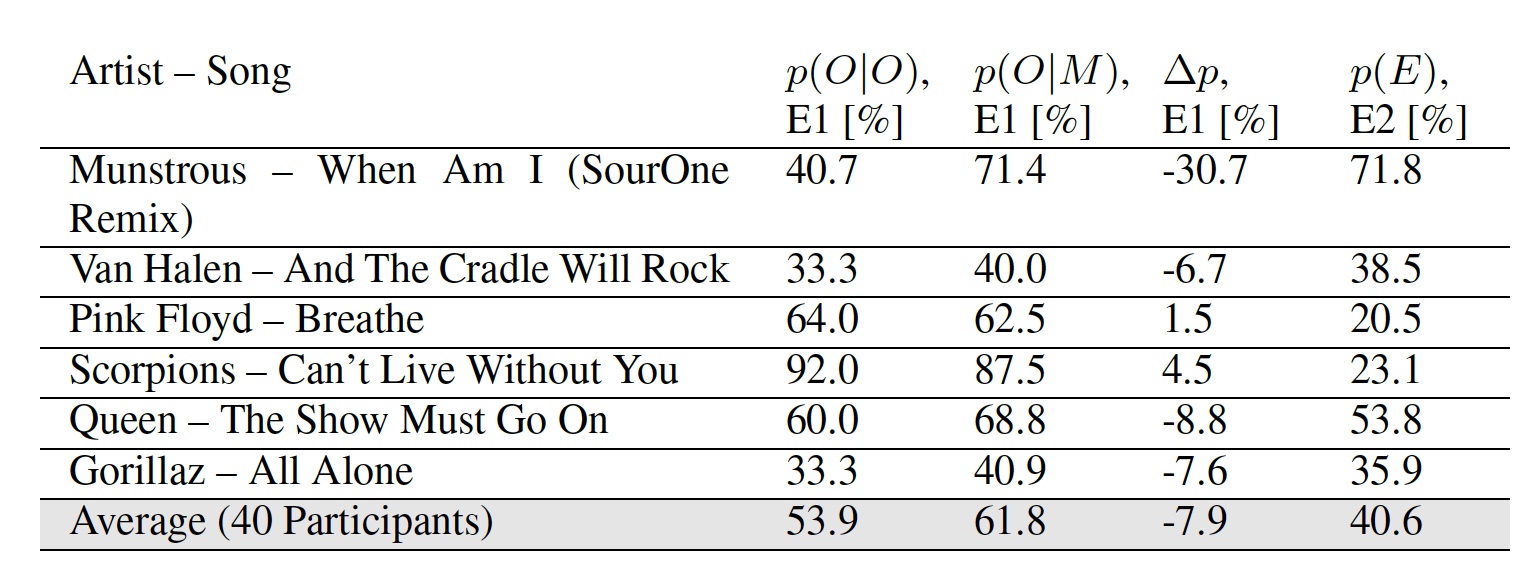 Tableau n ° 2: résultats des expériences E1 et E2.
Tableau n ° 2: résultats des expériences E1 et E2.Les résultats de la première expérience ont deux indicateurs: p ( | ) - pourcentage de participants qui ont correctement marqué la mélodie originale et p ( | ) - pourcentage de participants qui ont marqué la version modifiée de la mélodie comme originale.
Il est curieux que certains participants, selon les chercheurs, aient considéré certaines mélodies modifiées comme plus originales que l'original. L'indicateur moyen des deux expériences suggère que l'auditeur moyen ne remarquera pas la différence entre une mélodie régulière et celle dans laquelle les données ont été intégrées.
Naturellement, les connaisseurs de musique et les musiciens pourront attraper des inexactitudes et des éléments suspects dans les mélodies modifiées, mais ces éléments ne sont pas suffisamment importants pour causer de l'inconfort.
Et maintenant, nous pouvons nous-mêmes participer à l'expérience. Voici deux options pour la même mélodie - originale et modifiée. Entendez-vous la différence?
La version originale de la mélodievs
Version modifiée de la mélodiePour une connaissance plus détaillée des nuances de l'étude, je vous recommande de consulter le
rapport du groupe de recherche.
Vous pouvez également télécharger l'archive ZIP des fichiers audio des mélodies originales et modifiées utilisées dans l'étude à
ce lien .
Épilogue
Dans ce travail, des étudiants diplômés de l'Ecole supérieure technique suisse de Zurich ont décrit un incroyable système de transfert de données dans la musique. Pour ce faire, ils ont utilisé le masquage de fréquence, ce qui a permis d'intégrer des données dans une mélodie jouée par le locuteur. Cette mélodie est perçue par le microphone de l'appareil, qui reconnaît les données cachées et les décode, tandis que l'auditeur moyen ne remarque même pas la différence. À l'avenir, les gars prévoient de développer leur système, en choisissant des méthodes plus avancées pour intégrer des données dans l'audio.
Quand quelqu'un arrive avec quelque chose d'inhabituel, et surtout de travailler, nous sommes toujours heureux. Mais encore plus de joie est que cette invention a été créée par des jeunes. La science n'a pas de restrictions d'âge. Et si les jeunes considèrent la science ennuyeuse, elle est présentée sous le mauvais angle, pour ainsi dire. Après tout, comme nous le savons, la science est un monde étonnant qui ne cesse d'étonner.
Vendredi hors-dessus:
Puisque nous parlons de musique, et plus spécifiquement de musique rock, voici un merveilleux voyage à travers les étendues du rock.
Reine, Radio Ga Ga (1984).
Merci de votre attention, restez curieux et passez un bon week-end à tous, les gars! :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?