Dans les grands projets, composés de dizaines et de centaines de services en interaction, une approche de la documentation en tant que code - des documents en tant que code - devient de plus en plus obligatoire.
Je montrerai comment appliquer cette philosophie dans les réalités du service classé, ou plutôt, je partirai de la première étape de sa mise en œuvre: l'automatisation de la mise à jour des données dans la documentation.
Kit d'outils
Le principe de la «documentation en tant que code» implique l'utilisation des mêmes outils lors de l'écriture de la documentation que lors de la création de code: langages de balisage de texte, systèmes de contrôle de version, révision de code et auto-tests. L'objectif principal: créer des conditions permettant à toute l'équipe de travailler ensemble sur le résultat final - une base de connaissances complète et des instructions pour l'utilisation des services de produits individuels. Ensuite, je parlerai des outils spécifiques que nous avons choisis pour résoudre ce problème.
En tant que langage de balisage de texte, nous avons décidé d'utiliser le plus universel - reStructuredText . En plus d'un grand nombre de directives qui fournissent toutes les fonctions de base pour structurer le texte, ce langage prend en charge les principaux formats finaux, y compris le HTML nécessaire à notre projet.
Les fichiers sont convertis de .rst en .html à l'aide du générateur de documentation Sphinx . Il vous permet de créer des sites statiques pour lesquels vous pouvez créer le vôtre ou utiliser des thèmes prêts à l'emploi. Notre projet utilise deux thèmes prêts à l'emploi - le thème stanford et le thème bootstrap . Le second contient des sous-thèmes qui vous permettent de définir différents schémas de couleurs pour les éléments d'interface clés.
Pour un accès pratique et rapide à la version actuelle de la documentation, nous utilisons un site statique hébergé par une machine virtuelle accessible depuis le réseau local de l'équipe de développement.
Les fichiers source du projet sont stockés dans le référentiel Bitbucket et le site est généré uniquement à partir des fichiers contenus dans la branche principale. La mise à jour des données n'est possible que par pull-request, ce qui vous permet de vérifier toutes les nouvelles sections de la documentation avant leur publication dans le domaine public.
Étant donné qu'entre l'achèvement d'une nouvelle section de la documentation et son envoi sur le site, il est nécessaire de vérifier son contenu, le processus clé dans toute la chaîne est le processus de construction du site et de mise à jour des données sur l'hébergeur. Cette procédure doit être répétée à chaque fois après la fusion de la demande d'extraction avec la mise à jour avec la branche principale du projet.
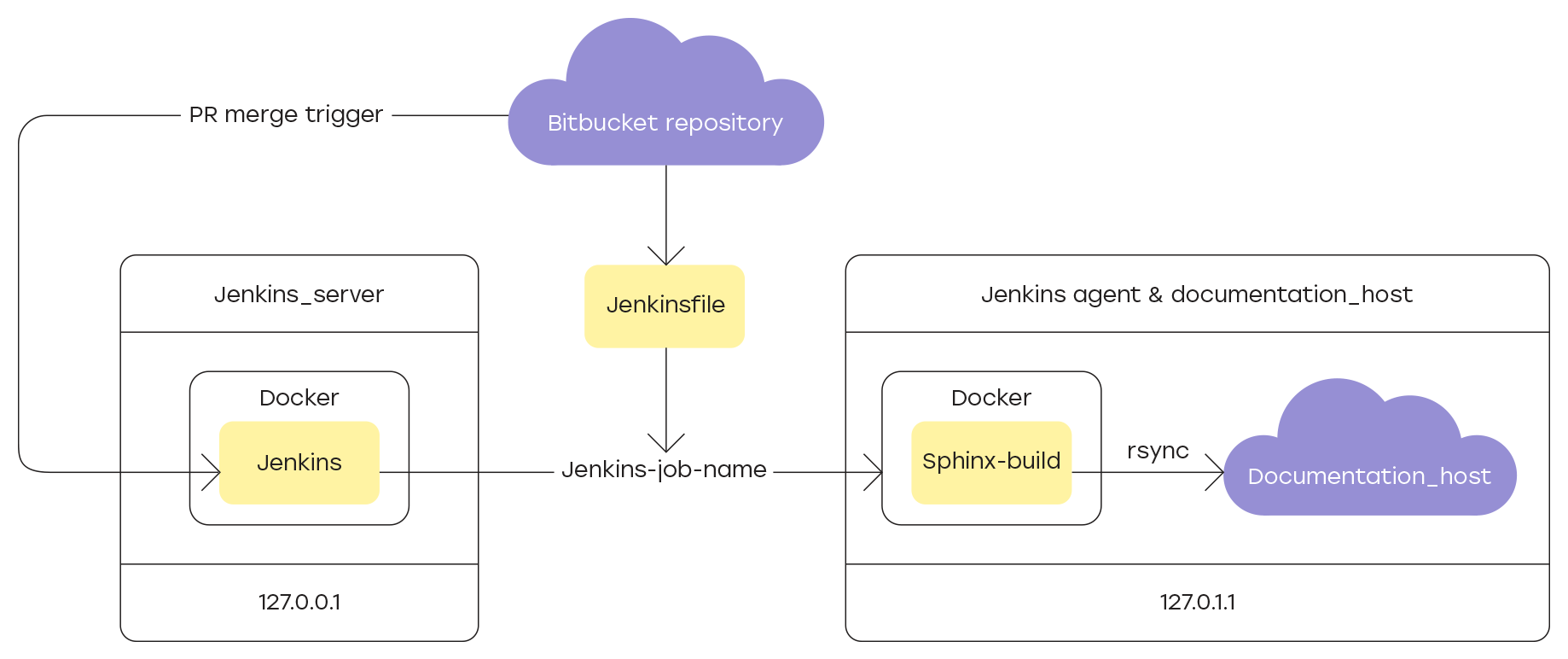
La mise en œuvre de cette logique permet à Jenkins - un système d'intégration continue de développement, dans notre cas - de la documentation. Je vais vous en dire plus sur les paramètres dans les sections:
- Ajout d'un nouveau nœud à Jenkins
- Description de Jenkinsfile
- Intégration de Jenkins et Bitbucket
Ajout d'un nouveau nœud à Jenkins
Pour créer et mettre à jour la documentation sur le site, vous devez enregistrer une machine préparée à l'avance en tant qu'agent Jenkins pour cela.
Préparation de la machine
Selon les exigences de Jenkins , JDK ou JRE doit être installé sur tous les composants inclus dans le système, y compris la machine principale et tous les nœuds d'agent enregistrés. Dans notre cas, JDK 8 sera utilisé, pour l'installation dont il suffit d'exécuter la commande:
sudo apt-get -y install java-1.8.0-openjdk git
La machine principale se connecte à l'agent pour effectuer les tâches qui lui sont attribuées. Pour ce faire, vous devez créer un utilisateur sur l'agent sous lequel toutes les opérations seront effectuées et dans lequel tous les fichiers générés par Jenkins seront stockés dans le dossier de base. Sur les systèmes Linux, exécutez simplement la commande:
sudo adduser jenkins \--shell /bin/bash su jenkins
Pour établir une connexion entre la machine maître et l'agent, vous devez configurer SSH et ajouter les clés d'autorisation nécessaires. Nous générerons les clés sur l'agent, après quoi nous ajouterons la clé publique au fichier authorized_keys pour l'utilisateur jenkins .
Nous allons construire le site avec la documentation dans un conteneur Docker en utilisant une image python prête à l'emploi : 3.7 . Suivez les instructions de la documentation officielle pour installer Docker sur l'agent. Pour terminer le processus d'installation, vous devez vous reconnecter à l'agent. Vérifiez l'installation en exécutant la commande qui charge l'image de test:
docker run hello-world
Pour ne pas avoir à exécuter les commandes Docker au nom du superutilisateur (sudo), il suffit d'ajouter le groupe docker utilisateur créé lors de l'étape d'installation, au nom duquel les commandes seront exécutées.
sudo usermod -aG docker $USER
Configuration du nouveau nœud Jenkins
Étant donné que la connexion à l'agent nécessite une autorisation, vous devez ajouter les informations d'identification appropriées dans les paramètres Jenkins. Des instructions détaillées sur la façon de procéder sur les machines Windows sont fournies dans la documentation officielle Jenkins .
IMPORTANT: L'identifiant spécifié dans la section Configurer Jenkins -> Gérer les environnements de génération -> Nom du nœud -> Configurer dans le paramètre Tags est utilisé dans Jenkinsfile pour indiquer l'agent sur lequel toutes les opérations seront effectuées.
Description de Jenkinsfile
La racine du référentiel de projet contient le fichier Jenkins , qui contient des instructions pour:
- Préparation de l'environnement de génération et installation des dépendances
- Créer un site avec Sphinx
- mise à jour des informations sur l'hôte.
Les instructions sont définies à l'aide de directives spéciales, dont l'application sera examinée plus loin sur l'exemple du fichier utilisé dans le projet.
Indication de l'agent
Au début du fichier Jenkins, spécifiez le libellé de l'agent dans Jenkins , sur lequel toutes les opérations seront effectuées. Pour ce faire, utilisez la directive agent :
agent { label '-' }
Préparation de l'environnement
Pour exécuter la commande sphinx-build site build, vous devez définir des variables d'environnement dans lesquelles les chemins de données réels seront stockés. De plus, pour mettre à jour les informations sur l'hôte, vous devez spécifier à l'avance les chemins où les données du site avec la documentation sont stockées. La directive environnement vous permet d'affecter ces valeurs à des variables:
environment { SPHINX_DIR = '.' //, Sphinx BUILD_DIR = 'project_home_built' // SOURCE_DIR = 'project_home_source' // .rst .md DEPLOY_HOST = 'username@127.1.1.0:/var/www/html/' //@IP__:__ }
Actions principales
Les principales instructions qui seront exécutées dans Jenkinsfile sont contenues dans la directive stages , qui comprend les différentes étapes décrites par les directives stage . Un exemple simple d'un pipeline CI en trois étapes:
pipeline { agent any stages { stage('Build') { steps { echo 'Building..' } } stage('Test') { steps { echo 'Testing..' } } stage('Deploy') { steps { echo 'Deploying....' } } } }
Lancer le conteneur Docker et installer les dépendances
Tout d'abord, exécutez le conteneur Docker avec l'image python terminée : 3.7 . Pour ce faire, utilisez la commande docker run avec les indicateurs --rm et -i . Effectuez ensuite les étapes suivantes:
- installez python virtualenv ;
- créer et activer un nouvel environnement virtuel;
- y installer toutes les dépendances nécessaires répertoriées dans le fichier
requirements.txt, qui est stocké à la racine du référentiel de projet.
stage('Install Dependencies') { steps { sh ''' docker run --rm -i python:3.7 python3 -m pip install --user --upgrade pip python3 -m pip install --user virtualenv python3 -m virtualenv pyenv . pyenv/bin/activate pip install -r \${SPHINX\_DIR}/requirements.txt ''' } }
Créer un site avec de la documentation
Construisons maintenant un site. Pour ce faire, exécutez la commande sphinx-build avec les indicateurs suivants:
-q : enregistre uniquement les avertissements et les erreurs;
-w : écrire un journal dans le fichier spécifié après l'indicateur;
-b : nom du constructeur du site;
-d : spécifiez le répertoire de stockage des fichiers mis en cache - pickles doctree.
Avant de démarrer l'assembly, à l'aide de la rm -rf supprimez l'assembly de site et les journaux précédents. En cas d'erreur à l'une des étapes, le journal d'exécution de construction de sphinx apparaîtra dans la console Jenkins .
stage('Build') { steps { // clear out old files sh 'rm -rf ${BUILD_DIR}' sh 'rm -f ${SPHINX_DIR}/sphinx-build.log' sh ''' ${WORKSPACE}/pyenv/bin/sphinx-build -q -w ${SPHINX_DIR}/sphinx-build.log \ -b html \ -d ${BUILD_DIR}/doctrees ${SOURCE\_DIR} ${BUILD\_DIR} ''' } post { failure { sh 'cat ${SPHINX_DIR}sphinx-build.log' } } }
Mise à jour du site hôte
Enfin, nous mettrons à jour les informations sur l'hôte desservant le site avec la documentation produit disponible dans l'environnement local. Dans l'implémentation actuelle, l'hôte est la même machine virtuelle qui est enregistrée en tant qu'agent Jenkins pour la tâche d'assemblage et de mise à jour de la documentation.
En tant qu'outil de synchronisation, nous utilisons l'utilitaire rsync . Pour que cela fonctionne correctement, il est nécessaire de configurer une connexion SSH entre le conteneur Docker, dans lequel se trouvait le site avec la documentation, et l'hôte.
Afin de configurer la connexion SSH à l'aide de Jenkinsfile , les plugins suivants doivent être installés dans Jenkins :
- SSH Agent Plugin - vous permet d'utiliser l'étape
sshagent dans les scripts pour fournir les informations d'identification du formulaire nom d'utilisateur / clé . - SSH Credentials Plugin - vous permet d'enregistrer les informations d'identification du formulaire nom d'utilisateur / clé dans les paramètres Jenkins .
Après avoir installé les plugins, vous devez spécifier les informations d'identification actuelles pour vous connecter à l'hôte en remplissant le formulaire dans la section Informations d'identification :
- ID : identifiant qui sera utilisé dans Jenkinsfile à l'étape
sshagent pour indiquer des informations d'identification spécifiques ( docs-deployer ); - Nom d'utilisateur : nom d'utilisateur sous lequel les opérations de mise à jour des données du site seront effectuées (l'utilisateur doit avoir un accès en écriture au dossier
/var/html de l'hôte); - Clé privée : une clé privée pour accéder à l'hôte;
- Phrase secrète : mot de passe de la clé, s'il a été défini lors de la génération.
Vous trouverez ci-dessous le code de script qui se connecte via SSH et met à jour les informations sur l'hôte à l'aide des variables système spécifiées au stade de la préparation de l'environnement avec les chemins d'accès aux données nécessaires. Le résultat de la commande rsync est écrit dans le journal, qui sera affiché dans la console Jenkins en cas d'erreurs de synchronisation.
stage('Deploy') { steps { sshagent(credentials: ['docs-deployer']) { sh ''' #!/bin/bash rm -f ${SPHINX_DIR}/rsync.log RSYNCOPT=(-aze 'ssh -o StrictHostKeyChecking=no') rsync "${RSYNCOPT[@]}" \ --delete \ ${BUILD_DIR_CI} ${DEPLOY_HOST}/ ''' } } post { failure { sh 'cat ${SPHINX_DIR}/rsync.log' } } }
Intégration de Jenkins et Bitbucket
Il existe de nombreuses façons d'organiser l'interaction de Jenkins et Bitbucket , mais dans notre projet, nous avons décidé d'utiliser le plugin Builds paramétré pour Jenkins . La documentation officielle contient des instructions détaillées pour l'installation du plugin, ainsi que les paramètres qui doivent être spécifiés pour les deux systèmes. Pour travailler avec ce plugin, vous devez créer un utilisateur Jenkins et générer un jeton spécial pour lui qui permettra à cet utilisateur de se connecter au système.
Création d'un jeton utilisateur et API
Pour créer un nouvel utilisateur dans Jenkins , accédez à Paramètres Jenkins -> Gestion des utilisateurs -> Créer un utilisateur et remplissez toutes les informations d'identification nécessaires dans le formulaire.
Le mécanisme d'authentification qui permet à des scripts ou applications tiers d'utiliser l'API Jenkins sans réellement transmettre le mot de passe utilisateur est un jeton API spécial qui peut être généré pour chaque utilisateur Jenkins . Pour ce faire:
- connectez-vous à la console de gestion en utilisant les détails de l'utilisateur créé précédemment;
- allez dans Configurer Jenkins -> Gestion des utilisateurs ;
- cliquez sur l'icône d'engrenage à droite du nom d'utilisateur sous lequel ils sont autorisés dans le système;
- recherchez l'API Token dans la liste des paramètres et cliquez sur le bouton Ajouter un nouveau jeton ;
- dans le champ qui apparaît, spécifiez l'identifiant du token API et cliquez sur le bouton Générer ;
- en suivant l'invite à l'écran, copiez et enregistrez le jeton d'API généré.
Maintenant, dans les paramètres du serveur Bitbucket , vous pouvez spécifier l'utilisateur par défaut pour se connecter à Jenkins .
Conclusion
Si auparavant, le processus comportait plusieurs étapes:
- Téléchargez la mise à jour dans le référentiel
- attendre la confirmation de l'exactitude;
- créer un site Web avec de la documentation;
- mettre à jour les informations sur l'hôte;
il suffit maintenant de cliquer sur un bouton Fusionner dans Bitbucket. Si, après vérification, il n'est pas nécessaire d'apporter des modifications aux fichiers source, la version actuelle de la documentation est mise à jour immédiatement après avoir confirmé l'exactitude des données.
Cela simplifie considérablement la tâche du rédacteur technique, lui évitant un grand nombre d'actions manuelles, et les chefs de projet disposent d'un outil pratique pour suivre les ajouts de documentation et les commentaires.
L'automatisation de ce processus est la première étape de la construction d'une infrastructure de gestion de la documentation. À l'avenir, nous prévoyons d'ajouter des tests automatiques qui vérifieront l'exactitude des liens externes utilisés dans la documentation, et souhaitons également créer des objets d'interface interactifs qui sont intégrés dans des thèmes prêts à l'emploi pour Sphinx .
Merci à ceux qui ont lu ceci pour votre attention, nous continuerons bientôt à partager les détails de la création de la documentation dans notre projet!