Maintenant, le cadre Vision est capable de reconnaître le texte pour de vrai, et non plus comme avant. Nous attendons avec impatience le moment où nous pourrons l'appliquer à Dodo IS. En attendant, une traduction d'un article sur la reconnaissance des cartes du jeu de société Magic The Gathering et leur extraction d'informations textuelles.
Le cadre Vision a été présenté pour la première fois au grand public à la WWDC en 2017, avec iOS 11.
Vision a été créé pour aider les développeurs à classer et identifier les objets, les plans horizontaux, les codes-barres, les expressions faciales et le texte.
Cependant, il y avait un problème avec la reconnaissance de texte: Vision pouvait trouver l'endroit où se trouve le texte, mais la reconnaissance de texte réelle ne s'est pas produite. Bien sûr, c'était agréable de voir la boîte englobante autour des fragments de texte individuels, mais ensuite ils devaient être retirés et reconnus indépendamment.
Ce problème a été résolu dans la mise à jour Vision, qui était incluse dans iOS 13. Désormais, le cadre Vision fournit une véritable reconnaissance de texte.
Pour tester cela, j'ai créé une application très simple qui peut reconnaître une carte du jeu de société Magic The Gathering et en extraire des informations textuelles:
- nom de la carte;
- code de version;
- numéro de collection (aka code postal).
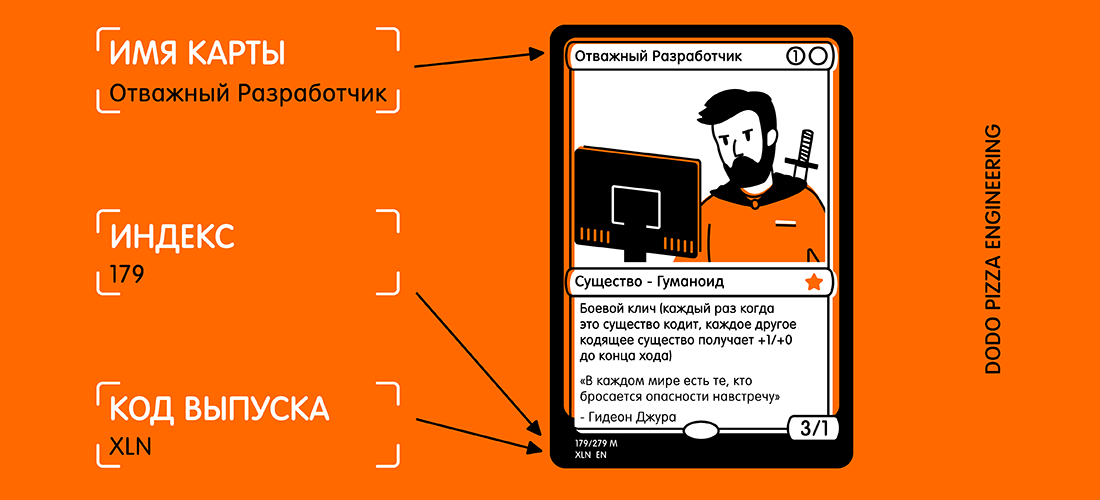
Voici un exemple de carte et de texte sélectionné que je souhaite recevoir.

En regardant la carte, vous pourriez penser: "Ce texte est plutôt petit, et il y a beaucoup d'autres textes sur la carte qui peuvent interférer." Mais pour Vision, ce n'est pas un problème.
Nous devons d'abord créer un
VNRecognizeTextRequest . Essentiellement, ceci est une description de ce que nous espérons reconnaître, ainsi qu'un paramètre de langue de reconnaissance et un niveau de précision:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"]
Le bloc d'achèvement a la forme
handleDetectedText(request: VNRequest?, error: Error?) . Nous la transmettons au constructeur
VNRecognizeTextRequest , puis définissons les propriétés restantes.
Deux niveaux de précision de reconnaissance sont disponibles:
.fast et
.accurate . Puisque notre carte a un texte plutôt petit en bas, j'ai choisi une précision plus élevée. L'option plus rapide est probablement mieux adaptée aux gros volumes de texte.
J'ai limité la reconnaissance à l'anglais britannique, car toutes mes cartes y sont. Vous pouvez spécifier plusieurs langues, mais vous devez comprendre que la numérisation et la reconnaissance peuvent prendre un peu plus de temps pour chaque langue supplémentaire.
Il y a deux autres propriétés qui méritent d'être mentionnées:
customWords : vous pouvez ajouter un tableau de chaînes à utiliser au-dessus du lexique intégré. Ceci est utile s'il y a des mots inhabituels dans votre texte. Je n'ai pas utilisé l'option pour ce projet. Mais si je devais faire l'application commerciale de reconnaissance de cartes Magic The Gathering, j'ajouterais certaines des cartes les plus complexes (par exemple, Fblthp, the Lost ) pour éviter les problèmes.minimumTextHeight : il s'agit d'une valeur flottante. Il indique la taille par rapport à la hauteur de l'image à laquelle le texte ne doit plus être reconnu. Si j'ai créé ce scanner juste pour obtenir le nom de la carte, il serait utile de supprimer tout autre texte qui n'est pas nécessaire. Mais j'ai besoin des plus petits morceaux de texte, donc pour l'instant j'ai ignoré cette propriété. Évidemment, si vous ignorez les petits textes, la vitesse de reconnaissance sera plus élevée.
Maintenant que nous avons notre demande, nous devons la transmettre avec l'image au gestionnaire de demande:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } }
J'utilise l'image directement depuis la caméra, en la convertissant de
UIImage en
CGImage . Il est utilisé dans
VNImageRequestHandler avec l'indicateur d'orientation pour aider le gestionnaire à comprendre le texte qu'il doit reconnaître.
Dans le cadre de cette démo, j'utilise le téléphone uniquement en orientation portrait. Alors naturellement, j'ajoute l'orientation. Alors padaji!
Il s'avère que l'orientation de l'appareil photo sur votre appareil est complètement distincte de la rotation de l'appareil et est toujours considérée à gauche (comme c'était le cas par défaut en 2009, pour prendre des photos, vous devez garder le téléphone en orientation paysage). Bien sûr, les temps ont changé et nous prenons essentiellement des photos et des vidéos au format portrait, mais l'appareil photo est toujours aligné à gauche.
Dès que notre gestionnaire est configuré, nous entrons dans le flux avec la priorité
.userInitiated et essayons de répondre à nos demandes. Vous remarquerez peut-être qu'il s'agit d'un tableau de requêtes. Cela se produit car vous pouvez essayer d'extraire plusieurs éléments de données en une seule passe (c'est-à-dire identifier les visages et le texte de la même image). S'il n'y a pas d'erreur, le rappel créé à l'aide de notre demande sera appelé après la détection du texte:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } }
Notre gestionnaire renvoie notre requête, qui a maintenant la propriété results. Chaque résultat est une
VNRecognizedTextObservation , qui pour nous a plusieurs options pour le résultat (ci-après - les candidats).
Vous pouvez obtenir jusqu'à 10 candidats pour chaque unité de texte reconnu, et ils sont triés par ordre décroissant de confiance. Cela peut être utile si vous avez une terminologie que l'analyseur ne reconnaît pas correctement lors du premier essai. Mais le détermine correctement plus tard, même s'il est moins confiant dans l'exactitude du résultat.
Dans cet exemple, nous n'avons besoin que du premier résultat, nous parcourons donc
observation.topCandidates(1) et extrayons à la fois le texte et la confiance. Bien que le candidat lui-même ait un texte et une confiance différents, la
.boundingBox reste la même.
.boundingBox utilise un système de coordonnées normalisé avec l'origine dans le coin inférieur gauche, donc s'il doit être utilisé dans UIKit à l'avenir, pour votre commodité, il doit être converti.
C'est presque tout ce dont vous avez besoin. Si j'exécute une
photo de la carte , j'obtiens le résultat suivant en moins de 0,5 seconde sur l'iPhone XS Max:
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
C'est incroyable! Chaque morceau de texte a été reconnu, placé dans sa propre boîte englobante et retourné en conséquence avec une note de confiance de 1,0.
Même un très petit droit d'auteur est généralement correct. Tout cela a été fait sur une image 3024x4032 pesant 3,1 Mo. Le processus serait encore plus rapide si je réduisais d'abord l'image. Il convient également de noter que ce processus est beaucoup plus rapide sur les nouvelles puces bioniques A12, qui ont un moteur neuronal spécial.
Lorsque le texte est reconnu, la dernière chose à faire est de retirer les informations dont j'ai besoin. Je ne mettrai pas tout le code ici, mais la logique clé est d'
.boundingBox sur chaque
.boundingBox déterminer l'emplacement, afin que je puisse sélectionner le texte dans le coin inférieur gauche et dans le coin supérieur gauche, en ignorant tout ce qui se trouve plus à droite.
Le résultat final est une application de carte de numérisation et me renvoie le résultat en moins d'une seconde.
PS En fait, je n'ai besoin que d'un code de version et d'un numéro de collection (c'est un index). Ensuite, ils peuvent être utilisés dans l'API du service Scryfall pour obtenir toutes les informations possibles sur cette carte, y compris les règles du jeu et le coût.
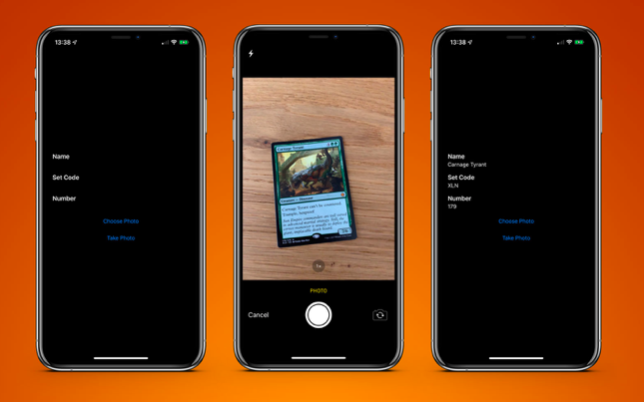
Un exemple d'application est disponible sur
GitHub .