
À un certain stade de maturité de la sécurité de l'information, de nombreuses entreprises commencent à réfléchir à la manière d'obtenir et d'utiliser des informations sur les cybermenaces qui les concernent. Selon les spécificités du secteur de l'organisation, différents types de menaces peuvent susciter de l'intérêt. L'approche de l'utilisation de ces informations a été formulée par Lockheed Martin dans le matériel
Intelligence Driven Defense .
Heureusement, les services de sécurité de l'information disposent de nombreuses sources pour les obtenir, et même d'une classe de solutions distincte - Threat Intelligence Platform (TIP), qui vous permet de gérer les processus de réception, de génération et d'intégration dans les outils de sécurité.
En tant que centre de surveillance et de réponse aux incidents de sécurité de l'information, il est extrêmement important pour nous que les informations sur les cybermenaces que nous recevons et générons soient pertinentes, applicables et, surtout, gérables. Après tout, la sécurité des organisations qui nous ont confié la protection de leurs infrastructures en dépend.
Nous avons décidé de partager notre vision de TI chez Jet CSIRT et de discuter de l'adaptation de diverses approches potentiellement utiles à la gestion des renseignements sur les cybermenaces.
Dans le domaine de la cybersécurité, peu de travaux sur le principe de set'n'forget. Le pare-feu ne bloque pas les paquets tant que les filtres ne sont pas configurés, IPS ne détecte aucun signe d'activité malveillante dans le trafic, tant que les signatures n'y sont pas téléchargées et SIEM commence à écrire indépendamment des règles de corrélation et à déterminer les faux positifs. Threat Intelligence ne fait pas exception.
La complexité de la mise en œuvre d'une solution qui refléterait vraiment le concept Threat Intelligence réside dans sa définition même.
Threat Intelligence est un processus de recherche et d'analyse de
certaines sources d' information pour obtenir et accumuler des
informations sur les cybermenaces actuelles afin de prendre des mesures pour améliorer la cybersécurité et accroître la sensibilisation à la sécurité de l'information d'une
certaine communauté de la sécurité de l'information .
Certaines sources peuvent inclure:
- Des sources d'information ouvertes. Tout cela peut être trouvé en utilisant Google, Yandex, Bing et des outils plus spécialisés tels que Shodan, Censys, nmap. Le processus d'analyse de ces sources est appelé Open Source Intelligence (OSINT). Il convient de noter que les informations obtenues via OSINT proviennent de sources ouvertes (non classifiées). Si la source est payée, cela peut ne pas la rendre secrète, ce qui signifie que l'analyse d'une telle source est également OSINT.
- Les médias. Tout ce que l'on retrouve dans les médias et sur les plateformes sociales Sosial Media Intelligence (SOCMINT). Ce type d'acquisition de données fait essentiellement partie intégrante d'OSINT.
- Lieux fermés et forums qui discutent des détails des cybercrimes à venir (deepweb, darknet). Surtout dans les zones d'ombre, vous pouvez obtenir des informations sur les attaques DDoS ou sur la création d'un nouveau malware que les pirates tentent de vendre là-bas.
- Personnes ayant accès à l'information. Les «collègues» et les personnes qui succombent aux méthodes d'ingénierie sociale sont également des sources qui peuvent partager des informations.
Des méthodes plus sérieuses ne sont disponibles que pour les services spécialisés. Dans ce cas, les données peuvent provenir d'agents travaillant sous couverture dans un environnement de cybercriminalité ou de personnes impliquées dans la cybercriminalité et collaborant à l'enquête. En un mot, tout cela s'appelle HUMan Intelligence (HUMINT). Bien sûr, nous ne pratiquons pas HUMINT chez Jet CSIRT.
Mettre tous ces processus dans une «boîte» qui fonctionnera de manière autonome est impossible. Par conséquent, en ce qui concerne la solution TI, sa principale proposition de valeur pour le consommateur est probablement les
informations mêmes
sur les cybermenaces et la façon de les gérer, dont l'accès sous une forme ou une autre obtient la
communauté de la sécurité de l'
information .
Informations sur les cybermenaces
En 2015, MWR Infosecurity, en collaboration avec le CERT et le National Infrastructure Protection Center de Grande-Bretagne, a publié une
brochure d'information qui met en évidence 4 catégories d'informations résultant du processus TI. Cette classification est désormais universellement appliquée:
- Fonctionnement Informations sur les cyberattaques à venir et en cours, obtenues, en règle générale, par des services spéciaux à la suite du processus HUMINT ou en utilisant l'écoute électronique des canaux de communication des attaquants.
- Stratégique. Informations relatives à l'évaluation des risques pour qu'une organisation soit victime d'une cyberattaque. Ils ne contiennent aucune information technique et ne peuvent en aucun cas être utilisés sur des équipements de protection.
- Tactique. Informations sur les techniques, tactiques, procédures (TTP) et outils que les cybercriminels utilisent dans le cadre d'une campagne malveillante.
Case in Point - LockerGoga récemment ouvert- Outil : cmd.exe.
- Technique : un crypto-locker est lancé, qui crypte tous les fichiers sur l'ordinateur de la victime (y compris les fichiers du noyau Windows) en utilisant l'algorithme AES en mode de chiffrement par bloc (CTR) avec une longueur de clé de 128 bits. La clé de fichier et le vecteur d'initialisation (IV) sont chiffrés à l'aide de l'algorithme RSA-1024 à l'aide de la fonction de génération de masque MGF1 (SHA-1). À son tour, pour augmenter la force cryptographique de cette fonction, le schéma de remplissage OAEP est utilisé. Les clés cryptées du fichier et IV sont ensuite stockées dans l'en-tête du fichier crypté lui-même.
- Procédure : De plus, le logiciel malveillant démarre plusieurs processus enfants parallèles, ne chiffrant que tous les 80 000 octets de chaque fichier, ignorant les 80 000 octets suivants pour accélérer le chiffrement.
- Tactique : il faut alors une rançon en bitcoins pour que la clé décrypte les fichiers.
Lisez plus
ici .
Ces informations apparaissent à la suite d'une enquête approfondie sur une campagne malveillante, qui peut prendre un certain temps. Les résultats de ces études sont des newsletters et des rapports de sociétés commerciales telles que Cisco Talos, FireEye, Symantec, Group-IB, Kaspersky GREAT, des organisations gouvernementales et des régulateurs (FinCERT, NCCCI, US-CERT, FS-ISAC), ainsi que des chercheurs indépendants.
Les informations tactiques peuvent et doivent être utilisées sur les équipements de sécurité et lors de la construction d'une architecture réseau.
- Technique Informations sur les signes et les essences d'une activité malveillante ou sur la façon de les identifier.
Par exemple, lors de l'analyse d'un malware, il s'est avéré qu'il se propage sous forme de fichier .pdf avec les paramètres suivants:
- nommé price_december.pdf ,
- démarrage du processus pureevil.exe ,
- ayant un hachage MD5 de 81a284a2b84dde3230ff339415b0112a ,
- qui tente d'établir des connexions avec le serveur C & C au 123.45.67.89 sur le port TCP 1337 .
Dans cet exemple, les entités sont les noms de fichier et de processus, la valeur de hachage, l'adresse du serveur et le numéro de port. Les signes sont l'interaction de ces entités entre elles et les composants de l'infrastructure: démarrage du processus, interaction réseau sortante avec le serveur, modification des clés de registre, etc.
Ces informations sont étroitement liées au concept d'indicateur de compromis (IoC). Techniquement, tant que l'entité ne se trouve pas dans l'infrastructure, elle ne dit toujours rien. Mais si, par exemple, vous trouvez sur le réseau le fait de tentatives de connexion de l'hôte au serveur C & C à
123.45.67.89:1337 ou au début du processus
pureevil.exe , et même avec la somme MD5
81a284a2b84dde3230ff339415b0112a , alors c'est déjà un indicateur de compromis.
Autrement dit, l'indicateur de compromis est une combinaison de certaines entités, des signes d'activité malveillante et des informations contextuelles qui nécessitent une réponse des services de sécurité de l'information.
Dans le même temps, dans le domaine de la sécurité de l'information, il est habituel d'appeler des indicateurs de compromis uniquement des entités qui ont été remarquées par une personne malveillante (adresses IP, noms de domaine, sommes de hachage, URL, noms de fichiers, clés de registre, etc.).
La détection d'un indicateur de compromis signale seulement que ce fait doit être pris en compte et analysé pour déterminer d'autres actions. Il n'est absolument pas recommandé de bloquer immédiatement l'indicateur sur le SZI sans clarifier toutes les circonstances. Mais nous en reparlerons plus loin.
Les indicateurs de compromis sont également commodément divisés en:
- Atomique. Ils ne contiennent qu'une seule fonctionnalité qui ne peut pas être divisée davantage, par exemple:
- Adresse IP du serveur C & C - 123.45.67.89
- Le montant de hachage est 81a284a2b84dde3230ff339415b0112a
- Composite Ils contiennent deux ou plusieurs entités détectées lors d'activités malveillantes, par exemple:
- Prise - 123.45.67.89:5900
- Le fichier price_december.pdf générera le processus pureevil.exe avec un hachage de 81a284a2b84dde3230ff339415b0112a
De toute évidence, la détection d'un indicateur composite indiquera plus probablement un compromis du système.
Les informations techniques peuvent également inclure diverses entités pour détecter et bloquer les indicateurs de compromis, par exemple, les règles Yara, les règles de corrélation pour SIEM, diverses signatures pour détecter les attaques et les logiciels malveillants. Ainsi, les informations techniques peuvent être clairement appliquées aux équipements de protection.
Problèmes d'utilisation efficace des informations techniques TI
Le plus rapidement, les fournisseurs de services TI peuvent obtenir exactement les informations techniques sur les cybermenaces, et la façon de les appliquer est entièrement une question pour le consommateur. C'est là que réside la plupart des problèmes.
Par exemple, des indicateurs de compromis peuvent être appliqués à plusieurs étapes de la réponse à un incident SI:
- au stade de la préparation (Préparation), bloquer de manière proactive l'indicateur sur le SIS (bien sûr, après l'exception des faux positifs);
- au stade de la détection, suivre le fonctionnement des règles d'identification de l'indicateur en temps réel par des outils de surveillance (SIEM, SIM, LM);
- au stade de l'enquête sur l'incident, utilisation de l'indicateur lors de contrôles rétrospectifs;
- au stade d'une analyse plus approfondie des actifs concernés, par exemple lors de l'analyse du code source d'un échantillon malveillant.
Plus un travail manuel est impliqué à un stade ou à un autre, plus l'analyse (enrichissant l'essence de l'indicateur avec des informations contextuelles) sera nécessaire de la part des fournisseurs d'indicateurs de compromis. Dans ce cas, nous parlons d'informations contextuelles externes, c'est-à-dire de ce que les autres connaissent déjà de cet indicateur.
En règle générale, les indicateurs de compromis sont fournis sous la forme de
flux de menaces ou de
flux . Il s'agit d'une telle liste structurée de données sur les menaces dans différents formats.
Par exemple, ce qui suit est un flux de hachage malveillant au format json:

Voici un exemple d'un bon flux riche en contexte:
- contient un lien vers l'analyse des menaces;
- nom, type et catégorie de menace;
- horodatage de la publication.
Tout cela vous permet de gérer les indicateurs de compromis de ce flux lors du téléchargement vers des outils de protection et de surveillance des informations, et réduit également le temps d'analyse des incidents qui ont fonctionné.
Mais il existe d'autres flux de qualité (généralement open source). Par exemple, ce qui suit est un exemple des adresses de serveurs soi-disant C&C à partir d'une source ouverte:

Comme vous pouvez le voir, les informations contextuelles sont complètement absentes ici. Chacune de ces adresses IP peut héberger un service légitime, dont certains peuvent être des robots Yandex ou Google qui indexent des sites. Nous ne pouvons rien dire sur cette liste.
L'absence ou l'insuffisance de contexte dans les flux de menaces est l'un des principaux problèmes des consommateurs d'informations techniques. Sans contexte, l'entité du flux n'est pas applicable et, en fait, n'est pas un indicateur de compromis. En d'autres termes, le blocage de toute adresse IP sur SZI, ainsi que le téléchargement de ce flux vers des outils de surveillance, est susceptible de conduire à un grand nombre de faux positifs (faux positifs - FP).
Si l'on considère l'utilisation d'indicateurs de compromis du point de vue de la détection sur les outils de surveillance, alors simplifié ce processus est une séquence:
- intégration des indicateurs dans les outils de suivi;
- déclencher la règle de détection d'indicateur;
- Analyse de la réponse du service SI.
En raison de la présence d'une ressource humaine dans cette séquence, nous souhaitons analyser uniquement les cas d'identification d'indicateurs qui indiquent réellement une menace pour l'organisation et réduisent le nombre de PF.
Fondamentalement, les faux positifs sont déclenchés par la détection de l'essence des ressources populaires (Google, Microsoft, Yandex, Adobe, etc.) comme potentiellement malveillantes.
Un exemple simple: il examine les logiciels malveillants qui ont atteint l'hôte. On découvre qu'il vérifie l'accès à Internet en interrogeant
update.googleapis.com . L'actif
update.googleapis.com est
répertorié dans le flux de menaces comme indicateur de compromis et appelle FP. De même, la somme de hachage d'une bibliothèque ou d'un fichier légitime utilisé par des logiciels malveillants, des adresses DNS publiques, des adresses de divers robots et araignées, des ressources pour vérifier les certificats CRL révoqués (liste de révocation de certificats) et les abréviations d'URL (bit.ly, goo) peuvent entrer dans le flux. gl, etc.).
Tester ce type de réponse, non enrichi dans un contexte externe, peut prendre un temps assez long pour l'analyste, au cours duquel un incident réel peut être manqué.
Soit dit en passant, il existe des flux d'indicateurs qui peuvent déclencher la PF. Un tel exemple est la
ressource misp-warninglist .
Priorisation des indicateurs de compromis
Un autre problème est la hiérarchisation des réponses. Relativement parlant, quel type de SLA aurons-nous lors de la détection d'un indicateur particulier de compromis. En effet, les fournisseurs de flux de menaces ne priorisent pas les entités qu'ils contiennent. Pour aider les consommateurs, ils peuvent ajouter un certain degré de confiance dans la nocivité d'une entité, comme cela se fait dans les flux de Kaspersky Lab:

Cependant, prioriser les événements d’identification des indicateurs est la tâche du consommateur.
Pour résoudre ce problème chez Jet CSIRT, nous avons adapté l'
approche présentée par Ryan Kazanciyan lors de COUNTERMEASURE 2016. Son essence est que tous les indicateurs de compromis que l'on peut trouver dans l'infrastructure soient considérés du point de vue de l'appartenance aux
domaines système et
aux domaines de données .
Les domaines de données sont répartis en 3 catégories:
- Activité en temps réel sur la source (ce qu'elle stocke actuellement en mémoire; détectée au moyen d'une analyse des événements de sécurité des informations en temps réel):
- démarrage de processus, modification des clés de registre, création de fichiers;
- activité réseau, connexions actives;
- d'autres événements viennent d'être générés.
Si un indicateur de cette catégorie est détecté, le temps de réponse des services SI est minimal .
- Activité historique (ce qui s'est déjà produit; révélé lors de contrôles rétrospectifs):
- journaux historiques;
- télémétrie;
- déclenché des alertes.
Si un indicateur de cette catégorie est détecté, le temps de réaction des services SI est autorisé de manière limitée .
- Données au repos (ce qui était déjà avant de connecter la source à la surveillance; elles sont révélées dans le cadre de contrôles rétrospectifs de sources longtemps inutilisées):
- les fichiers stockés depuis longtemps sur la source;
- clés de registre;
- d'autres objets inutilisés.
Si un indicateur de cette catégorie est détecté, le temps de réaction des services SI est limité par la durée de l'enquête complète de l'incident .
Habituellement, des rapports détaillés et des bulletins d'information sont compilés sur la base de ces enquêtes avec une ventilation des actions des attaquants, mais la pertinence de ces données est relativement faible.
C'est-à-
dire que les domaines de données sont l'état des données analysées dans lequel un indicateur de compromis a été détecté.
Les domaines système sont l'affiliation de la source de l'indicateur de compromis à l'un des sous-systèmes d'infrastructure:
- Postes de travail. Sources utilisées directement par l'utilisateur pour effectuer le travail quotidien: postes de travail, ordinateurs portables, tablettes, smartphones, terminaux (VoIP, VKS, IM), programmes d'application (CRM, ERP, etc.).
- Serveurs. Cela fait référence à d'autres appareils desservant l'infrastructure, c'est-à-dire appareils pour le fonctionnement du complexe informatique: SZI (FW, IDS / IPS, AV, EDR, DLP), appareils réseau, serveurs de fichiers / web / proxy, systèmes de stockage, ACS, contrôle environnemental. environnement etc.

En combinant ces informations avec la composition des signes d'un indicateur de compromis
(atome, composite) , en fonction du temps de réaction acceptable, vous pouvez formuler la priorité de l'incident lorsqu'il est détecté:
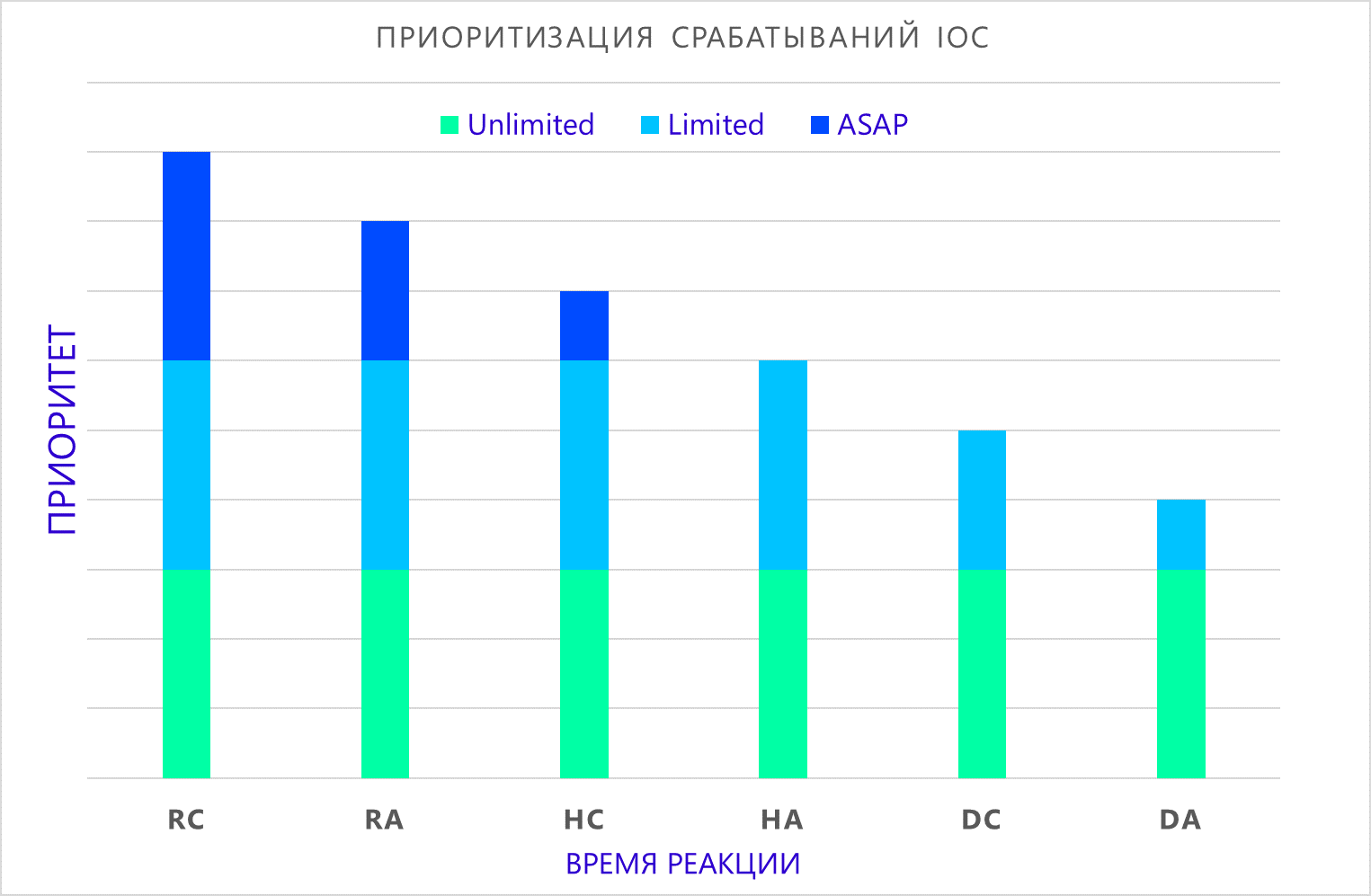
- DÈS QUE POSSIBLE La détection d'un indicateur nécessite une réponse immédiate de l'équipe d'intervention.
- Limité La détection de l'indicateur nécessite une analyse supplémentaire pour clarifier les circonstances de l'incident et décider des actions futures.
- Illimité La détection de l'indicateur nécessite une enquête approfondie et la préparation d'un rapport sur les activités des attaquants. En règle générale, ces résultats sont étudiés dans le cadre de la criminalistique, qui peut durer des années.
Où:
- RC - détection d'indicateur composite en temps réel;
- RA - détection d'un indicateur atomique en temps réel;
- HC - détection d'un indicateur composite dans le cadre d'une vérification rétrospective;
- HA - détection d'un indicateur atomique dans le cadre d'une vérification rétrospective;
- DC - détection d'un indicateur composite dans des sources longtemps inutilisées;
- DA - détection d'un indicateur atomique dans des sources longtemps inutilisées.
Je dois dire que la priorité ne diminue pas l’importance de détecter un indicateur, mais montre plutôt le temps approximatif dont nous disposons pour empêcher un éventuel compromis sur l’infrastructure.
Il est également juste de noter qu'une telle approche ne peut pas être utilisée indépendamment de l'infrastructure observée, nous y reviendrons.
Suivi de la durée de vie des indicateurs de compromis
Certaines entités malveillantes laissent à jamais l'indicateur de compromis. Il n'est pas recommandé de supprimer ces informations, même après une longue période de temps. Cela devient souvent pertinent dans les audits rétrospectifs
(NA / HA) et lors de la vérification des sources longtemps inutilisées
(DC / DA) .
Certains centres de surveillance et fournisseurs d'indicateurs de compromis jugent inutile de contrôler la durée de vie de tous les indicateurs en général. Cependant, dans la pratique, cette approche devient inefficace. En effet, des indicateurs de compromis tels que, par exemple, les hachages de fichiers malveillants, les clés de registre générées par des logiciels malveillants et les URL par lesquelles un nœud est infecté, ne deviendront jamais des entités légitimes, c'est-à-dire leur validité n'est pas limitée.Exemple concret: analyse SHA-256 de la somme d'un fichier RAT Vermin avec un protocole SOAP encapsulé pour l'échange de données avec un serveur C & C. L'analyse montre que le fichier a été créé en 2015. Récemment, nous l'avons trouvé sur l'un des serveurs de fichiers de nos clients.
En effet, des indicateurs de compromis tels que, par exemple, les hachages de fichiers malveillants, les clés de registre générées par des logiciels malveillants et les URL par lesquelles un nœud est infecté, ne deviendront jamais des entités légitimes, c'est-à-dire leur validité n'est pas limitée.Exemple concret: analyse SHA-256 de la somme d'un fichier RAT Vermin avec un protocole SOAP encapsulé pour l'échange de données avec un serveur C & C. L'analyse montre que le fichier a été créé en 2015. Récemment, nous l'avons trouvé sur l'un des serveurs de fichiers de nos clients.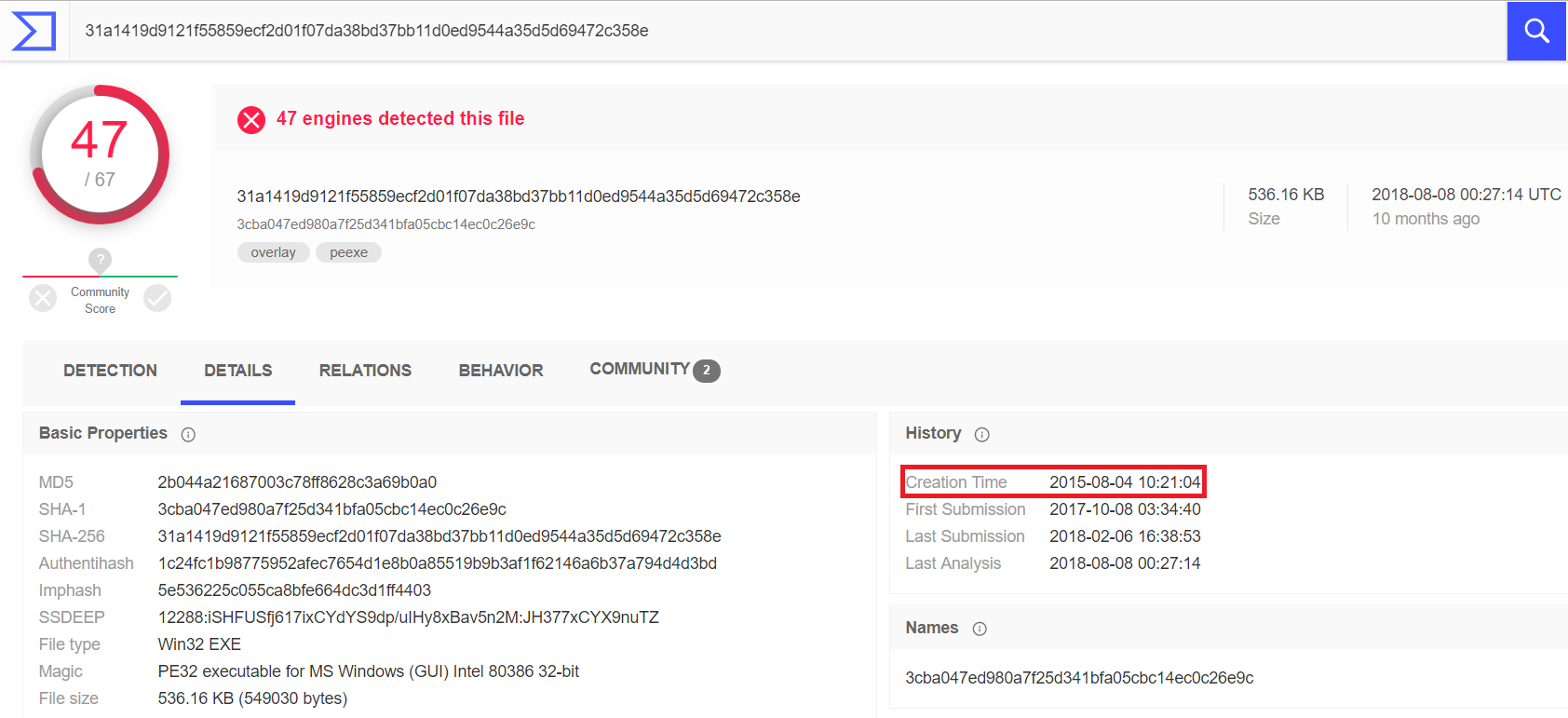 Cependant, une image complètement différente sera avec le type d'entités qui ont été créées ou «empruntées» pendant un certain temps pour une campagne malveillante. Autrement dit, ce sont des points d'extrémité sous le contrôle d'intrus.Ces entités peuvent redevenir légitimes une fois que leurs propriétaires ont effacé les nœuds compromis ou lorsque les attaquants ont cessé d'utiliser la prochaine infrastructure.En tenant compte de ces facteurs, il est possible de construire un tableau approximatif d'indicateurs de compromis en référence aux domaines de données, la période de leur pertinence et la nécessité de contrôler leur cycle de vie:
Cependant, une image complètement différente sera avec le type d'entités qui ont été créées ou «empruntées» pendant un certain temps pour une campagne malveillante. Autrement dit, ce sont des points d'extrémité sous le contrôle d'intrus.Ces entités peuvent redevenir légitimes une fois que leurs propriétaires ont effacé les nœuds compromis ou lorsque les attaquants ont cessé d'utiliser la prochaine infrastructure.En tenant compte de ces facteurs, il est possible de construire un tableau approximatif d'indicateurs de compromis en référence aux domaines de données, la période de leur pertinence et la nécessité de contrôler leur cycle de vie: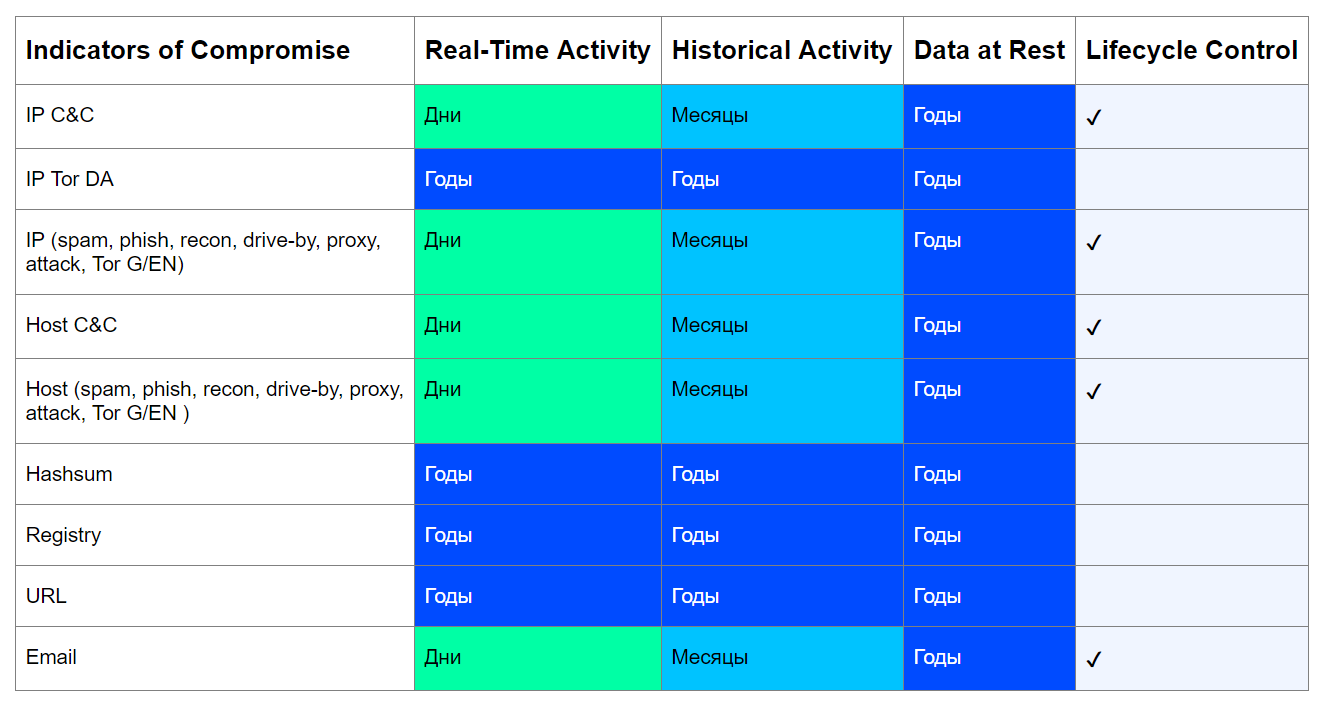 Le but de ce tableau est de répondre à trois questions:
Le but de ce tableau est de répondre à trois questions:- Cet indicateur peut-il devenir légitime au fil du temps?
- Quelle est la période minimale de pertinence d'un indicateur en fonction de l'état des données analysées?
- Faut-il contrôler la durée de vie de cet indicateur?
Considérez cette approche en utilisant l'exemple d'un serveur IP C & C. Aujourd'hui, les attaquants préfèrent mettre en place une infrastructure distribuée, changeant souvent d'adresse afin de passer inaperçus et éviter les éventuels blocages du fournisseur. Dans le même temps, C&C est souvent déployé sur des nœuds piratés, comme par exemple dans le cas d' Emotet . Cependant, les botnets sont liquidés, les méchants sont pris, donc un indicateur tel que l'adresse IP du serveur C & C peut certainement devenir une entité légitime, ce qui signifie que sa vie peut être contrôlée.Si nous trouvons des appels vers le serveur IP C&C en temps réel (RA / RC), alors la période de sa pertinence pour nous sera calculée en jours. Après tout, il est peu probable que le lendemain de la découverte, cette adresse n'héberge plus C&C.La détection d'un tel indicateur dans les contrôles rétrospectifs (HA / HC), qui ont généralement des intervalles plus longs (une fois toutes les quelques semaines / mois), indiquera également une période minimale de pertinence égale à l'intervalle correspondant. Dans le même temps, C&C lui-même peut ne plus être actif, mais si nous trouvons un fait de circulation dans notre infrastructure, alors l'indicateur sera pertinent pour nous.La même logique s'applique aux autres types d'indicateurs. Les exceptions sont les quantités de hachage, les clés de registre, les nœuds de réseau Tor URL et les URL.Avec les hachages et les valeurs de registre, tout est simple - ils ne peuvent pas être retirés de la nature, donc cela n'a aucun sens de contrôler leur durée de vie. Mais les URL malveillantes peuvent être supprimées, bien sûr, elles ne deviendront pas légitimes, mais elles seront inactives. Cependant, ils sont également uniques et sont créés spécifiquement pour une campagne malveillante, ils ne peuvent donc pas devenir légitimes.Les adresses IP des nœuds DA du réseau Tor sont bien connues et inchangées, leur durée de vie n'est limitée que par la durée de vie du réseau Tor lui-même, de tels indicateurs sont donc toujours pertinents.Comme vous pouvez le voir, pour la plupart des types d'indicateurs du tableau, le contrôle de leur durée de vie est nécessaire.Chez Jet CSIRT, nous préconisons cette approche pour les raisons suivantes.- , - , - , , , .
, Microsoft 99 , APT35. - Microsoft .
IP- , -. , IP- «», , . - , .
, , , . - .
, . 1 MS Office, -, . , , , .
C'est pourquoi nous considérons qu'il est important maintenant de nous efforcer d'adapter les processus et de développer des approches pour contrôler la durée de vie des indicateurs qui sont intégrés dans les moyens de protection.Une telle approche est décrite dans les indicateurs de dégradation du compromis du Centre informatique de réponse d'urgence du Luxembourg (CIRCL), dont le personnel a créé une plate-forme pour l'échange d'informations sur les menaces MISP . C'est au MISP qu'il est prévu d'appliquer les idées de ce matériel. Pour ce faire, fondamentalement, les référentiels de projets ont déjà ouvert la branche appropriée , ce qui prouve une fois de plus la pertinence de ce problème pour la communauté de la sécurité de l'information.Cette approche suppose que la durée de vie de certains indicateurs n'est pas homogène et peut changer comme:- les attaquants cessent d'utiliser leur infrastructure dans les cyberattaques;
- il découvre de plus en plus de cyberattaques spécialistes de la sécurité de l'information et met des indicateurs dans le bloc sur le SZI, forçant les attaquants à changer les éléments utilisés.
Ainsi, la durée de vie de tels indicateurs peut être décrite sous la forme d'une certaine fonction caractérisant le taux de sortie de la date d'expiration de chaque indicateur dans le temps.Les collègues du CIRCL construisent leur modèle en utilisant les conditions utilisées dans MISP, cependant, l'idée générale du modèle peut être utilisée en dehors de leur produit:- l'indicateur de compromis (a) se voit attribuer une certaine évaluation de base ( ), qui varie de 0 à 100;
Dans le matériau CIRCL, il est pris en compte par la fiabilité / confiance dans le fournisseur d'indicateurs et les taxonomies associées. Dans le même temps, lors de la détection répétée de l'indicateur, l'évaluation de base peut changer - augmenter ou diminuer, selon les algorithmes du fournisseur.- L'heure est entrée , où son score total doit être égal à 0;
- Le concept du taux de sortie du taux d'expiration de l'indicateur (decay_rate) est introduit. , qui caractérise le taux de déclin du score global de l'indicateur au fil du temps;
- Horodatages saisis et , caractérisant respectivement l'heure actuelle et l'heure à laquelle l'indicateur a été vu pour la dernière fois.
Compte tenu de toutes les conditions ci-dessus, les collègues du CIRCL donnent la formule suivante pour calculer le score global (1):
O WhereParamètreproposé pour être considéré comme ,
O Where- heure de la première détection de l'indicateur;- heure de la dernière détection de l'indicateur;- le temps maximum entre deux détections de l'indicateur. L'idée est que lorsque le score est = 0, alors l'indicateur correspondant peut être retiré. Selon nos données, certains fournisseurs de flux de menaces mettent en œuvre d'autres méthodes pour contrôler la pertinence et filtrer les indicateurs de compromis utilisés à un niveau préventif. Cependant, la plupart de ces techniques sont assez simples. Nous avons essayé d'appliquer l'algorithme du matériau CIRCL pour les indicateurs qui ont été détectés au stade de la détection et appliqués en tant que règles de blocage sur le SIS pendant le processus de réponse et l'activité post-incident. De toute évidence, cette approche ne peut être appliquée sans ambiguïté qu'aux types d'indicateurs pour lesquels elle est connue..
Le matériel CIRCL donne un exemple du soi-disant temps de grâce - un temps fixe pour la correction, que le fournisseur donne au propriétaire de la ressource, remarqué dans une activité suspecte, avant de déconnecter la ressource. Mais pour la plupart des types d'indicateurs est encore inconnu.Malheureusement, nous ne pouvons pas prédire avec précision le moment où une entité particulière deviendra légitime. Cependant, nous avons presque toujours (auprès du fournisseur de l'indicateur ou de l'analyse des sources ouvertes) des informations sur le moment où cette entité a été découverte la première et la dernière fois, ainsi qu'une sorte d'évaluation de base. Ainsi, afin de savoir quand il sera possible de radier l'indicateur selon le matériau CIRCL, une seule variable nous sépare - decay_rate. Cependant, il ne suffit pas de le rendre constant pour tous les indicateurs, et surtout, pour toutes les infrastructures.Nous avons donc tenté de lier chaque type d'indicateur, pour lequel le contrôle du cycle de vie est possible, à son taux d'expiration (decay_rate), au type d'infrastructure observé et à son niveau de maturité de la sécurité de l'information.En faisant l'inventaire de l'infrastructure protégée spécifique, en découvrant l'âge du logiciel et de l'équipement qu'il utilise, nous déterminons le taux de dégradation pour chaque type d'indicateur de compromis. Un résultat approximatif de ces travaux peut être présenté sous la forme d'un tableau: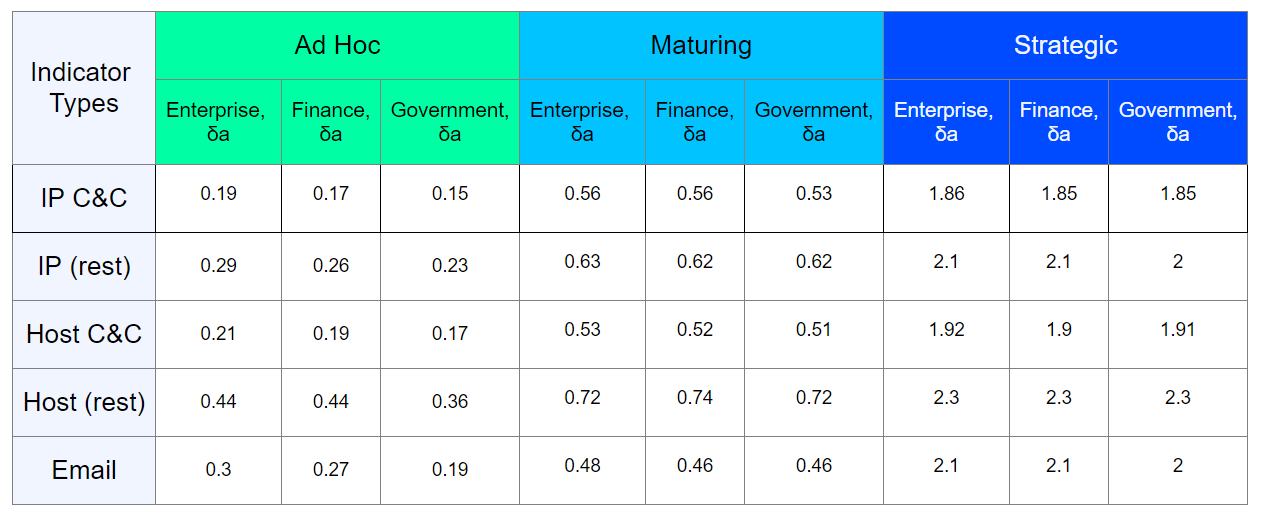 je souligne une fois de plus que le résultat dans le tableau est approximatif, en réalité, l'évaluation doit être effectuée individuellement pour une infrastructure spécifique.Avec l'arrivée des dates d'expiration de chaque indicateur, nous pouvons déterminer l'heure approximative à laquelle ils peuvent être radiés. Il convient également de noter que le calcul du temps de radiation ne doit être effectué que lorsqu'il y a une tendance à une diminution du score de l'indicateur de base.Par exemple, considérons un indicateur avec une note de base de 80, le temps = 120 et différents taux de décroissance (
je souligne une fois de plus que le résultat dans le tableau est approximatif, en réalité, l'évaluation doit être effectuée individuellement pour une infrastructure spécifique.Avec l'arrivée des dates d'expiration de chaque indicateur, nous pouvons déterminer l'heure approximative à laquelle ils peuvent être radiés. Il convient également de noter que le calcul du temps de radiation ne doit être effectué que lorsqu'il y a une tendance à une diminution du score de l'indicateur de base.Par exemple, considérons un indicateur avec une note de base de 80, le temps = 120 et différents taux de décroissance ( )
 Comme le montrent les graphiques, en déterminant la limite de criticité approximative de l'évaluation (dans notre cas - 20, avec une évaluation initiale de 80), nous pouvons définir le temps de vérification de la pertinence de cet indicateur. Plus le taux de décroissance est élevé, plus ce temps arrive vite. Par exemple, avec decay_rate = 3 et une limite d'évaluation = 20, on pourrait vérifier cet indicateur pendant environ 50 jours de son fonctionnement dans le SZI.L'approche décrite est assez difficile à mettre en œuvre, mais son charme est que nous pouvons effectuer des tests sans affecter les processus établis de sécurité de l'information et l'infrastructure des clients. Nous exécutons maintenant l'algorithme de surveillance de la durée de vie d'un certain échantillon d'indicateurs, qui pourraient hypothétiquement tomber sous le déclassement. Cependant, en fait, ces indicateurs restent opérationnels à la SZI. Relativement parlant, nous prenons un échantillon d'indicateurs, nous les considérons et, ayant remarqué une tendance à la baisse de l'estimation de base, les marquer comme «radiés» si le chèque confirme leur non-pertinence.Il est trop tôt pour parler de l'efficacité de cette approche, mais les résultats des tests nous aideront à déterminer s'il vaut la peine de la traduire «en production».Une telle technique peut potentiellement aider à contrôler non seulement les indicateurs qui sont exploités sur SIS en raison de la réponse à l'incident. L'adaptation réussie de cette approche par les fournisseurs d'informations sur les cybermenaces leur permettra de profiler les flux de menaces afin qu'ils contiennent des indicateurs de compromis avec une certaine durée de vie pour des clients et des infrastructures spécifiques.
Comme le montrent les graphiques, en déterminant la limite de criticité approximative de l'évaluation (dans notre cas - 20, avec une évaluation initiale de 80), nous pouvons définir le temps de vérification de la pertinence de cet indicateur. Plus le taux de décroissance est élevé, plus ce temps arrive vite. Par exemple, avec decay_rate = 3 et une limite d'évaluation = 20, on pourrait vérifier cet indicateur pendant environ 50 jours de son fonctionnement dans le SZI.L'approche décrite est assez difficile à mettre en œuvre, mais son charme est que nous pouvons effectuer des tests sans affecter les processus établis de sécurité de l'information et l'infrastructure des clients. Nous exécutons maintenant l'algorithme de surveillance de la durée de vie d'un certain échantillon d'indicateurs, qui pourraient hypothétiquement tomber sous le déclassement. Cependant, en fait, ces indicateurs restent opérationnels à la SZI. Relativement parlant, nous prenons un échantillon d'indicateurs, nous les considérons et, ayant remarqué une tendance à la baisse de l'estimation de base, les marquer comme «radiés» si le chèque confirme leur non-pertinence.Il est trop tôt pour parler de l'efficacité de cette approche, mais les résultats des tests nous aideront à déterminer s'il vaut la peine de la traduire «en production».Une telle technique peut potentiellement aider à contrôler non seulement les indicateurs qui sont exploités sur SIS en raison de la réponse à l'incident. L'adaptation réussie de cette approche par les fournisseurs d'informations sur les cybermenaces leur permettra de profiler les flux de menaces afin qu'ils contiennent des indicateurs de compromis avec une certaine durée de vie pour des clients et des infrastructures spécifiques.Conclusion
Treat Intelligence est, bien sûr, un concept de sécurité de l'information nécessaire et utile qui peut considérablement améliorer la sécurité de l'infrastructure de l'entreprise. Pour parvenir à une utilisation efficace de TI, vous devez comprendre comment nous pouvons utiliser les diverses informations obtenues grâce à ce processus.En ce qui concerne les informations techniques de Threat Intelligence, telles que les flux de menaces et les indicateurs de compromis, nous devons nous rappeler que la méthode de leur utilisation ne doit pas être basée sur une liste noire aveugle. En apparence, l'algorithme simple pour détecter puis bloquer la menace présente en fait de nombreux «écueils», donc, pour une utilisation efficace des informations techniques, il est nécessaire d'évaluer correctement leur qualité, de déterminer la priorité des détections, mais aussi de contrôler leur durée de vie afin de réduire la charge sur le SPI.Cependant, comptez uniquement sur les connaissances techniques de Threat Intelligence. Il est beaucoup plus important d'adapter les informations tactiques aux processus de défense. Après tout, il est beaucoup plus difficile pour les attaquants de changer de tactiques, de techniques et d'outils, plutôt que de nous faire chasser une autre partie des indicateurs de compromis, qui a été découverte après une attaque de pirate. Mais nous en parlerons dans nos prochains articles.Auteur: Alexander Akhremchik, expert au Jet Infosystems Jet Infrastructure Jet Monitoring and Response Center, Jet CSIRT