Dans cet article, nous verrons comment créer un programme Go, tel qu'un compilateur ou un analyseur statique, qui interagit avec le cadre de compilation LLVM à l'aide du langage d'assemblage LLVM IR.
TL; DR, nous avons écrit une bibliothèque pour interagir avec LLVM IR sur Pure Go, voir les liens vers le code et un exemple de projet.
Un exemple simple sur LLVM IR
(Ceux d'entre vous qui connaissent LLVM IR peuvent passer à la section suivante).
LLVM IR est la représentation intermédiaire de bas niveau utilisée par le cadre de compilation LLVM. Vous pouvez considérer LLVM IR comme un assembleur indépendant de la plate-forme avec un nombre infini de registres locaux.
Lors de la conception d'un compilateur, il y a un énorme avantage à compiler le langage source dans une représentation intermédiaire (IR, représentation intermédiaire) au lieu de le compiler dans l'architecture cible (par exemple, x86).
SpoilerL'idée d'utiliser un langage intermédiaire dans les compilateurs est répandue. GCC utilise GIMPLE, Roslyn utilise CIL, LLVM utilise LLVM IR.
Étant donné que de nombreuses techniques d'optimisation sont courantes (par exemple, la suppression de code inutilisé, la distribution de constantes), ces passes d'optimisation peuvent être effectuées directement au niveau IR et utilisées par toutes les plates-formes cibles.
SpoilerL'utilisation d'un langage intermédiaire (IR) réduit ainsi le nombre de combinaisons requises pour n langages source et m architectures cibles (backends) de n * m à n + m.
Ainsi, les compilateurs se composent souvent de trois parties: frontend, middleland et backend, chacun d'eux accomplit sa propre tâche, acceptant l'entrée et / ou donnant la sortie IR.
- Frontend: compile le langage source en IR
- Middleland: optimise l'IR
- Backend: compile IR en code machine
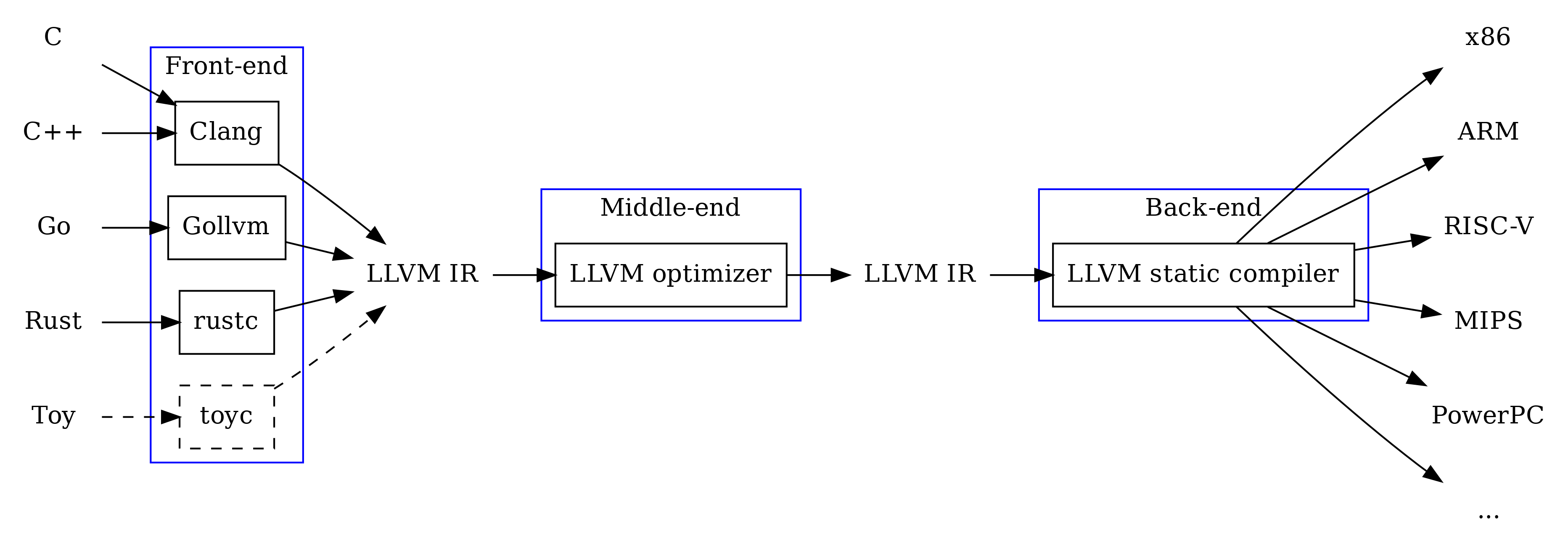
Exemple de programme d'assembleur IR LLVM
Afin d'avoir une idée de ce à quoi ressemble l'assembleur IR LLVM, considérez le programme suivant.
int f(int a, int b) { return a + 2*b; } int main() { return f(10, 20); }
Nous utilisons Clang et compilons le code C ci-dessus dans l'assembleur IR LLVM.
Clangclang -S -emit-llvm -o foo.ll foo.c.
define i32 @f(i32 %a, i32 %b) { ; <label>:0 %1 = mul i32 2, %b %2 = add i32 %a, %1 ret i32 %2 } define i32 @main() { ; <label>:0 %1 = call i32 @f(i32 10, i32 20) ret i32 %1 }
En regardant le code assembleur LLVM IR ci-dessus, nous pouvons remarquer quelques fonctionnalités remarquables LLVM IR, à savoir:
LLVM IR est de type statique (c'est-à-dire que les entiers 32 bits sont intersectés par le type i32).
Les variables locales ont une portée dans la fonction (c'est-à-dire que% 1 dans le
principal est différent de% 1 dans @f).
Les sans nom (registres temporaires) reçoivent des identifiants locaux (par exemple,% 1,% 2), dans l'ordre croissant, dans chacune des fonctions. Chaque fonction peut utiliser un nombre infini de registres (non limité à 32 registres à usage général). Les identifiants globaux (par exemple @f) et les identifiants locaux (par exemple% a,% 1) sont distingués par un préfixe (@ et%, respectivement).
La plupart des commandes font ce que vous attendez, donc mul multiplie, ajoute des ajouts, etc.
Les commentaires commencent par, comme c'est la coutume dans les langages d'assemblage.
Structure de l'assembleur IR LLMV
Le contenu du fichier d'assemblage LLVM IR est un module. Le module contient des déclarations de haut niveau, telles que des variables et des fonctions globales.
Une déclaration de fonction ne contient pas de blocs de base, une définition de fonction contient un ou plusieurs blocs de base (c'est-à-dire un corps de fonction).
Un exemple plus détaillé du module IR LLVM est donné ci-dessous. y compris la définition de la variable globale @foo et la définition de la fonction @f contenant trois blocs de base (% entry,% block_1 et% block_2).
; , 32- 21 @foo = global i32 21 ; f 42, cond , 0 define i32 @f(i1 %cond) { ; , ; entry: ; br block_1, %cond ; , block_2 . br i1 %cond, label %block_1, label %block_2 ; , , block_1: %tmp = load i32, i32* @foo %result = mul i32 %tmp, 2 ret i32 %result ; , , block_2: ret i32 0 }
Unité de base
Une unité de base est une séquence de commandes qui ne sont pas des commandes de transition (commandes de terminaison). L'idée clé de l'unité de base est que si une commande de l'unité de base est exécutée, toutes les autres commandes de l'unité de base sont exécutées. Cela simplifie l'analyse du flux d'exécution.
L'équipe
Une commande qui n'est pas une commande de saut effectue généralement des calculs ou un accès à la mémoire (par exemple, ajouter, charger), mais ne modifie pas le flux de contrôle du programme.
Équipe de résiliation
La commande de terminaison est située à la fin de chaque unité de base et détermine où la transition sera effectuée à la fin de l'unité de base. Par exemple, la commande ret de fin renvoie le flux de contrôle de la fonction appelante et br effectue la transition, conditionnelle ou inconditionnelle.
Formulaire SSA
Une propriété très importante de LLVM IR est qu'il est écrit sous la forme SSA (Static Single Assignment), ce qui signifie essentiellement que chaque registre n'est affecté qu'une seule fois. Cette propriété simplifie l'analyse statique du flux de données.
Pour traiter les variables qui sont affectées plusieurs fois dans le code source d'origine, la commande phi est utilisée dans LLVM IR. La commande phi renvoie essentiellement une valeur unique à partir d'un ensemble de valeurs d'entrée, selon le chemin d'exécution auquel cette commande a été atteinte. Chaque valeur d'entrée est ainsi associée à un bloc d'entrée précédent.
Par exemple, considérons la fonction IR LLVM suivante:
define i32 @f(i32 %a) { ; <label>:0 switch i32 %a, label %default [ i32 42, label %case1 ] case1: %x.1 = mul i32 %a, 2 br label %ret default: %x.2 = mul i32 %a, 3 br label %ret ret: %x.0 = phi i32 [ %x.2, %default ], [ %x.1, %case1 ] ret i32 %x.0 }
La commande phi (également appelée parfois nœud phi) dans l'exemple ci-dessus simule diverses affectations à l'aide d'un ensemble de valeurs d'entrée possibles, une pour chaque chemin possible dans le thread d'exécution, conduisant à une affectation de variable. Par exemple, l'un des chemins correspondants dans le flux de données est le suivant:
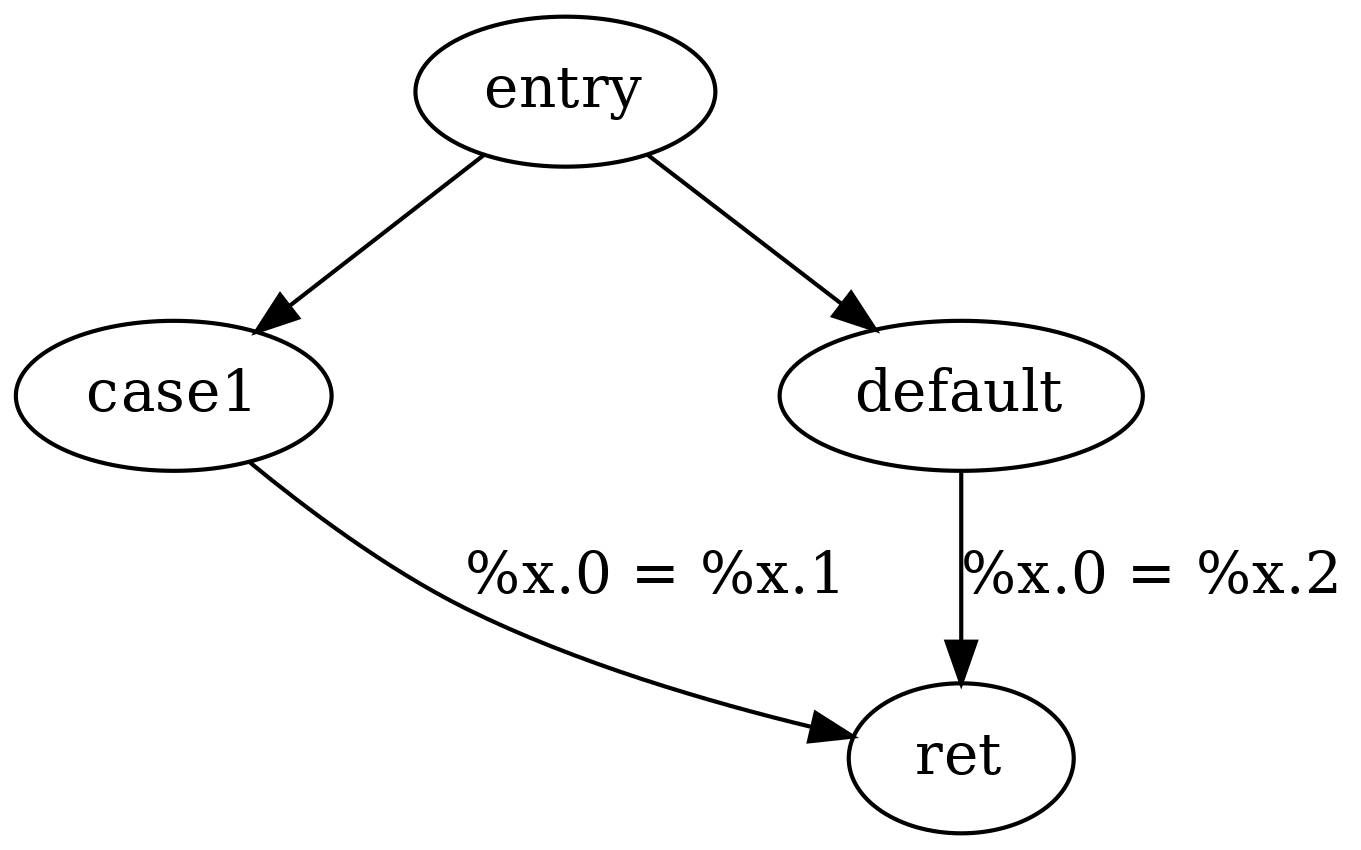
En général, lors du développement d'un compilateur qui convertit le code source en LLVM IR, toutes les variables de code source locales peuvent être converties au format SSA, à l'exception des variables pour lesquelles leur adresse est prise.
Pour simplifier la mise en œuvre du frontend LLVM, il est recommandé de modéliser les variables locales dans le langage source en tant que variables allouées en mémoire (en utilisant alloca), en simulant les affectations aux variables locales en tant qu'écritures en mémoire et en utilisant une variable locale en tant que lectures depuis la mémoire. La raison en est qu'il peut être une tâche non triviale de traduire directement la langue source en LLVM IR sous forme SSA. Tant que les accès à la mémoire suivent certains modèles, nous pouvons compter sur la passe d'optimisation mem2reg dans le cadre de LLVM pour convertir les variables locales allouées en mémoire en registres sous forme SSA (en utilisant des nœuds phi si nécessaire).
Bibliothèque LLVM IR sur Pure Go
Il existe deux bibliothèques principales pour travailler avec LLVM IR in Go:
https://godoc.org/llvm.org/llvm/bindings/go/llvm : liaisons officielles LLVM pour la langue Go.
github.com/llir/llvm : une bibliothèque Go propre pour interagir avec LLVM IR.
Les liaisons LLVM officielles pour le langage Go utilisent Cgo pour fournir l'accès aux API riches et puissantes du framework de compilation LLVM, tandis que le projet llir / llvm est entièrement écrit en Go et utilise LLVM IR pour interagir avec le framework LLVM.
Cet article se concentre sur llir / llvm, mais peut être généralisé pour fonctionner avec d'autres bibliothèques.
Pourquoi écrire une nouvelle bibliothèque?
La principale motivation pour développer une bibliothèque Go propre pour interagir avec LLVM IR était de faire des compilateurs d'écriture et des outils d'analyse statique, basés sur le cadre de compilation LLVM IR, une tâche plus amusante. Il a également été influencé par le fait que le temps de compilation d'un projet basé sur les liaisons LLVM officielles avec Go peut être important (grâce à @aykevl, l'auteur de TinyGo, il est désormais possible d'accélérer la compilation grâce à la liaison dynamique, contrairement à la version standard de LLVM 4).
Une autre grande motivation était d'essayer de développer l'API Go à partir de zéro. La principale différence entre les API de liaison LLVM pour Go et llir / llvm est la façon dont les valeurs LLVM sont modélisées. Dans les classeurs LLVM pour Go, les valeurs LLVM sont modélisées comme un type de structure en béton, qui, en substance, contient toutes les méthodes possibles pour toutes les valeurs LLVM possibles. Mon expérience personnelle en utilisant cette API suggère qu'il est difficile de savoir quel sous-ensemble de méthodes est autorisé à appeler pour une valeur donnée. Par exemple, pour obtenir un opcode d'instruction, vous appelez la méthode InstructionOpcode, qui est intuitive. Cependant, si vous appelez à la place la méthode Opcode, qui est conçue pour obtenir l'opcode d'une expression constante, vous obtiendrez une erreur d'exécution: "argument cast () de type incompatible!" (conversion d'argument en type incompatible).
La bibliothèque llir / llvm a été conçue pour vérifier les types au moment de la compilation et s'assurer qu'ils sont utilisés correctement avec le système de types Go. Les valeurs LLVM dans llir / llvm sont modélisées en tant que types d'interface. Cette approche ne rend disponible qu'un ensemble minimal de méthodes, partagé par toutes les valeurs, et si vous souhaitez accéder à des méthodes ou des champs spécifiques, utilisez le changement de type (comme illustré dans l'exemple ci-dessous).
Exemple d'utilisation
Voyons maintenant quelques exemples d'utilisations spécifiques. laissez-nous avoir une bibliothèque, mais que devons-nous faire avec le LLVM IR?
Tout d'abord, nous pourrions vouloir analyser l'IR LLVM généré par un autre outil, tel que Clang et l'optimiseur LLVM opt (voir l'exemple d'entrée ci-dessous).
Deuxièmement, nous pouvons vouloir traiter l'IR LLVM et effectuer notre propre analyse sur celui-ci, ou faire nos propres passes d'optimisation, ou implémenter un interpréteur ou un compilateur JIT (voir l'exemple d'analyse ci-dessous).
Troisièmement, nous pouvons vouloir générer un LLVM IR, qui sera une entrée pour d'autres instruments. Cette approche peut être choisie si nous développons une interface pour un nouveau langage de programmation (voir l'exemple de code de sortie ci-dessous).
Exemple de code d'entrée - Analyse LLVM IR
Exemple d'analyse - Traitement LLVM IR
Exemple de code de sortie - Génération IR LLVM
Conclusion
Le développement et la mise en œuvre de llir / llvm ont été réalisés et dirigés par une communauté de contributeurs qui ont non seulement écrit du code, mais aussi dirigé des discussions, jumelé des sessions de programmation, débogué, profilé et montré de la curiosité dans le processus d'apprentissage.
L'une des parties les plus difficiles du projet llir / llvm a été la construction d'une grammaire EBNF pour LLVM IR, couvrant l'ensemble du langage LLVM IR jusqu'à la version LLVM 7.0. La difficulté ici n'est pas dans le processus lui-même, mais dans le fait qu'il n'y a pas de grammaire officiellement publiée couvrant toute la langue. Certaines communautés open source ont essayé de définir une grammaire formelle pour l'assembleur LLVM, mais elles ne couvrent, à notre connaissance, que des sous-ensembles du langage.
La grammaire LLVM IR ouvre la voie à des projets intéressants. Par exemple, la génération d'un assembleur LLVM IR syntaxiquement valide peut être utilisée pour divers outils et bibliothèques utilisant LLVM IR, une approche similaire est utilisée dans GoSmith. Cela peut être utilisé pour la validation croisée des projets LLVM implémentés dans d'autres langues, ainsi que pour vérifier les vulnérabilités et les bogues d'implémentation.
L'avenir est merveilleux, bon piratage!
Les références
1. Un
chapitre très bien écrit sur LLVM, écrit par Chris Lattner, l'auteur du projet LLVM initial, dans le livre «Architecture of Open Source Applications».
2.
Le tutoriel Implémenter un langage avec LLVM - souvent aussi appelé le Guide du langage du kaléidoscope - décrit en détail comment implémenter un langage de programmation simple compilé dans LLVM IR. L'article décrit toutes les étapes principales de l'écriture d'un frontend, y compris un analyseur lexical, un analyseur et la génération de code.
3. Pour ceux qui sont intéressés à écrire un compilateur du langage d'entrée vers LLVM IR, le livre "
Mapping High Level Constructs to LLVM IR " est recommandé.
Un bon ensemble de diapositives est
LLVM, en détail , qui décrit les concepts IR LLVM importants, fournit une introduction à l'API LLVM C ++ et décrit quelques passages d'optimisation LLVM très utiles.
Les fixations Go officielles pour LLVM conviennent à de nombreux projets, elles représentent l'API C LLVM, puissante et stable.
Un bon ajout à l'article est
une introduction à LLVM in Go.