Réseaux de neurones - c'est un sujet qui suscite un grand intérêt et un désir de le comprendre. Mais, malheureusement, il ne se prête pas à tout le monde. Lorsque vous voyez des volumes de littérature obscure, vous perdez le désir d'étudier, mais vous voulez toujours vous tenir au courant de ce qui se passe.
En fin de compte, il me semblait qu'il n'y avait pas de meilleure façon de le comprendre que de simplement créer et créer votre propre petit projet.
Vous pouvez lire l'arrière-plan lyrique en développant le texte, ou vous pouvez sauter ceci et aller directement à la
description du réseau neuronal.Quel est l'intérêt de faire votre projet.Avantages:
- Vous comprenez mieux comment les neurones sont organisés
- Vous comprenez mieux comment travailler avec les bibliothèques existantes
- Apprendre quelque chose de nouveau en parallèle
- Chatouillez votre ego, en créant quelque chose qui vous appartient
Inconvénients:
- Vous créez un vélo, probablement pire que les vélos existants
- Personne ne se soucie de votre projet.
Le choix de la langue.Au moment de choisir le langage, je connaissais plus ou moins le C ++ et connaissais les bases de Python. Il est plus facile de travailler avec des neurones en Python, mais C ++ le savait mieux et il n'y a pas de parallélisation plus simple des calculs qu'OpenMP. Par conséquent, j'ai choisi C ++, et l'API pour Python, afin de ne pas déranger, va créer un
swig qui fonctionne sur Windows et Linux. (
Un exemple de la façon de créer une bibliothèque Python à partir de code C ++)
Accélération OpenMP et GPU.Actuellement, OpenMP version 2.0 est installé dans Visual Studio, dans lequel il n'y a que l'accélération CPU. Cependant, à partir de la version 3.0, OpenMP prend également en charge l'accélération GPU, tandis que la syntaxe des directives n'est pas compliquée. Il ne reste plus qu'à attendre qu'OpenMP 3.0 soit supporté par tous les compilateurs. En attendant, pour plus de simplicité, seul le CPU.
Mon premier râteau.Dans le calcul de la valeur d'un neurone, il y a le point suivant: avant de calculer la fonction d'activation, nous devons ajouter la multiplication des poids aux données d'entrée. Comment apprendre à le faire à l'université: avant de sommer un grand vecteur de petits nombres, il faut le trier par ordre croissant. Alors voilà. Dans les réseaux de neurones, à part ralentir le programme N fois, cela ne donne rien. Mais je ne l'ai réalisé que lorsque j'avais déjà testé mon réseau sur MNIST.
Mettre un projet sur GitHub.Je ne suis pas le premier à poster ma création sur GitHub. Mais dans la plupart des cas, en suivant le lien, vous ne voyez qu'un tas de code avec l'inscription dans README.md
"Ceci est mon réseau de neurones, regardez et étudiez .
" Pour être meilleur que les autres, au moins en cela, il a plus ou moins décrit
README.md et rempli le
Wiki . Le message est simple -
remplissez le Wiki. Une observation intéressante: si le titre du Wiki sur GitHub est écrit en russe, alors l'
ancre de ce titre ne fonctionne pas.
LicenceLorsque vous créez votre petit projet, une licence est à nouveau un moyen de titiller votre ego. Voici un
article intéressant sur l'utilisation d'une licence. J'ai opté pour
APACHE 2.0 .
Description du réseau.
CARACTÉRISTIQUES
Le principal avantage de ma bibliothèque est la création d'un réseau avec une seule ligne de code.
Il est facile de voir que dans les couches linéaires, le nombre de neurones dans une couche est égal au nombre de paramètres d'entrée dans la couche suivante. Une autre déclaration évidente - le nombre de neurones dans la dernière couche est égal au nombre de valeurs de sortie du réseau.
Créons un réseau qui reçoit trois paramètres à l'entrée, qui a trois couches avec 5, 4 et 2 neurones.
import foxnn nn = foxnn.neural_network([3, 5, 4, 2])
Si vous regardez l'image, vous pouvez juste voir: 3 premiers paramètres d'entrée, puis une couche avec 5 neurones, puis une couche avec 4 neurones et, enfin, la dernière couche avec 2 neurones.
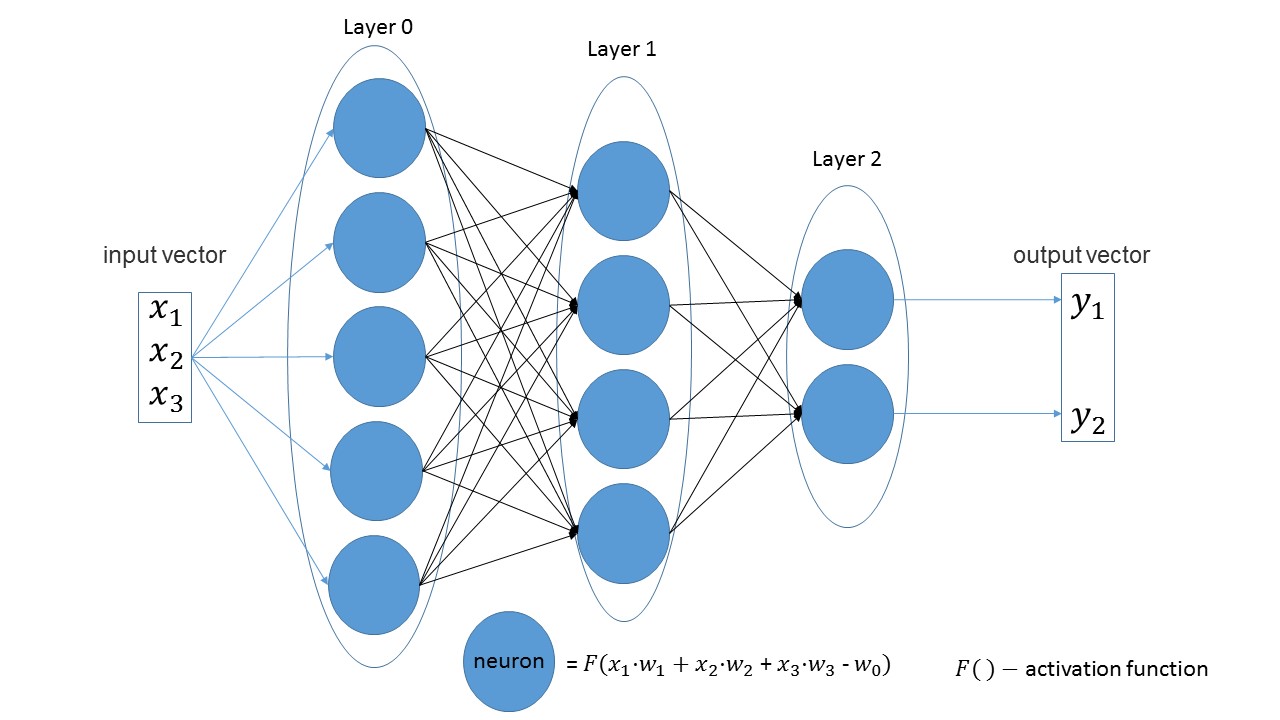
Par défaut, toutes les fonctions d'activation sont sigmoïdes (je les aime plus).
Si vous le souhaitez, sur n'importe quel calque peut être changé pour une autre fonction.
Les fonctionnalités d'activation les plus populaires sont disponibles. nn.get_layer(0).set_activation_function("gaussian")
Ensemble d'entraînement facile à créer. Le premier vecteur est les données d'entrée, le deuxième vecteur est les données cibles.
data = foxnn.train_data() data.add_data([1, 2, 3], [1, 0])
Formation réseau:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
Activation de l'optimisation:
nn.settings.set_mode("Adam")
Et une méthode pour simplement obtenir la valeur du réseau:
nn.get_out([0, 1, 0.1])
Un peu sur le nom de la méthode.Séparément, get traduit comment obtenir , et out signifie sortie . Je voulais obtenir le nom " donner la valeur de sortie ", et je l'ai eu. Ce n'est que plus tard que j'ai remarqué qu'il s'est avéré sortir . Mais c'est plus amusant et j'ai décidé de partir.
Test
Il est déjà devenu une tradition non écrite de tester tout réseau basé sur
MNIST . Et je n'ai pas fait exception. Tout le code avec commentaires peut être trouvé
ici .
Crée un exemple de formation: from mnist import MNIST import foxnn mndata = MNIST('C:download/') mndata.gz = True imagesTrain, labelsTrain = mndata.load_training() def get_data(images, labels): train_data = foxnn.train_data() for im, lb in zip(images, labels): data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Créez un réseau: trois couches, 784 paramètres pour l'entrée et 10 pour la sortie: nn = foxnn.neural_network([784, 512, 512, 10]) nn.settings.n_threads = 7
Nous formons: nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
Que s'est-il passé:
En 10 minutes environ (accélération du processeur uniquement), une précision de 75% peut être obtenue. Avec l'optimisation Adam, une précision de 88% peut être obtenue en 5 minutes. Au final, j'ai réussi à atteindre une précision de 97%.
Les principaux inconvénients (il existe déjà des plans de révision):- En Python, aucune erreur n'a encore été commise, c'est-à-dire en python, l'erreur ne sera pas interceptée et le programme se terminera simplement avec une erreur.
- Alors que la formation est indiquée dans les itérations, et non dans les époques, comme c'est la coutume dans d'autres réseaux.
- Pas d'accélération GPU
- Il n'y a pas encore d'autres types de calques.
- Nous devons télécharger le projet sur PyPi.
Pour un petit achèvement du projet, cet article faisait défaut. Si au moins dix personnes sont intéressées et jouent, alors il y aura déjà une victoire. Bienvenue dans mon
github .
PS: Si vous avez besoin de créer quelque chose de vous-même pour le comprendre, n'ayez pas peur et créez.