Pendant de nombreuses années, travaillant en tant que DBA SQL Server et faisant l'administration du serveur, puis l'optimisation des performances. En général, je voulais faire quelque chose d'utile dans mon temps libre pour l'Univers et nos collègues. Donc, à la fin, nous avons obtenu un petit
outil de maintenance d'index
open source pour SQL Server et Azure.
Idée
Parfois, lorsque vous travaillez sur leurs priorités, les gens peuvent ressembler à une batterie de type doigt - il y a suffisamment de charge de motivation pour un seul flash, puis c'est tout. Et jusqu'à récemment, je n'ai pas fait exception à cette observation de la vie. Souvent, j'ai été visité par des idées pour créer quelque chose de moi-même, mais les priorités ont changé et rien n'a été mis au point.
Une influence assez forte sur ma motivation et mon développement professionnel a été apportée par le travail dans la société Kharkov Devart, qui était engagée dans la création de logiciels pour le développement et l'administration de bases de données SQL Server, MySQL et Oracle.
Avant de venir à eux, je n'avais aucune idée des spécificités de la création de mon propre produit, mais déjà dans le processus, j'ai acquis beaucoup de connaissances sur la structure interne de SQL Server. Ayant optimisé les demandes de métadonnées dans leurs gammes de produits depuis plus d'un an, j'ai progressivement commencé à comprendre quelle fonctionnalité était plus demandée sur le marché que toute autre.
À un certain stade, l'idée est née de créer un nouveau produit de niche, mais en raison des circonstances, cette idée n'a pas décollé. A cette époque, pour le nouveau projet, il n'y avait pas assez de ressources libres suffisantes et ringardes au sein de l'entreprise sans compromettre le cœur de métier.
Déjà quand il travaillait dans un nouvel endroit et essayait de faire le projet par lui-même, il devait constamment faire des compromis. L'idée initiale de créer un grand produit plein de fonctionnalités est rapidement tombée à néant et s'est progressivement transformée dans une direction différente - pour diviser la fonctionnalité prévue en mini-outils séparés et les mettre en œuvre indépendamment les uns des autres.
En conséquence,
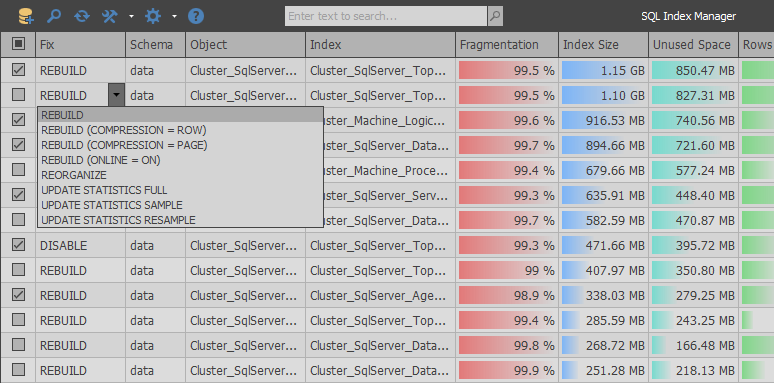
SQL Index Manager est né - un outil de maintenance d'index gratuit pour SQL Server et Azure. L'idée principale était de prendre comme base des alternatives commerciales de RedGate et Devart et d'essayer d'améliorer leurs fonctionnalités. Pour fournir, aux débutants comme aux utilisateurs expérimentés, la possibilité d'analyser et de maintenir facilement les index.
Implémentation
En termes, tout semble toujours simple ... il a jeté un coup d'œil à quelques vidosikov motivants, s'est tenu dans un rack et a commencé à fabriquer un produit cool. Mais en pratique, tout n'est pas aussi rose, car il existe de nombreux pièges lors de l'utilisation de la fonction de table système sys.dm_db_index_physical_stats et, en combinaison, le seul endroit d'où vous pouvez obtenir des informations pertinentes sur la fragmentation d'index.
Dès les premiers jours de développement, il y avait une excellente occasion de faire un chemin morne parmi les schémas standard et de copier la logique déjà déboguée du travail des applications concurrentes, tout en ajoutant un petit gag. Mais après avoir analysé les demandes de métadonnées, j'ai voulu faire quelque chose de plus optimisé qui, en raison de la bureaucratie des grandes entreprises, ne serait jamais apparu dans leurs produits.
Lors de l'analyse du gestionnaire d'index SQL de RedGate (1.1.9.1378 - 155 $), vous pouvez voir que l'application utilise une approche très simple: avec une requête, nous obtenons une liste de tables et de vues utilisateur, et après la deuxième requête, une liste de tous les index de la base de données sélectionnée est renvoyée.
SELECT objects.name AS tableOrViewName , objects.object_id AS tableOrViewId , schemas.name AS schemaName , CAST(ISNULL(lobs.NumLobs, 0) AS BIT) AS ContainsLobs , o.is_memory_optimized FROM sys.objects AS objects JOIN sys.schemas AS schemas ON schemas.schema_id = objects.schema_id LEFT JOIN ( SELECT object_id , COUNT(*) AS NumLobs FROM sys.columns WITH (NOLOCK) WHERE system_type_id IN (34, 35, 99) OR max_length = -1 GROUP BY object_id ) AS lobs ON objects.object_id = lobs.object_id LEFT JOIN sys.tables AS o ON o.object_id = objects.object_id WHERE objects.type = 'U' OR objects.type = 'V' SELECT i.object_id AS tableOrViewId , i.name AS indexName , i.index_id AS indexId , i.allow_page_locks AS allowPageLocks , p.partition_number AS partitionNumber , CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex FROM sys.indexes AS i JOIN sys.partitions AS p ON p.index_id = i.index_id AND p.object_id = i.object_id JOIN ( SELECT COUNT(*) AS numPartitions , object_id , index_id FROM sys.partitions GROUP BY object_id , index_id ) AS c ON c.index_id = i.index_id AND c.object_id = i.object_id WHERE i.index_id > 0 -- ignore heaps AND i.is_disabled = 0 AND i.is_hypothetical = 0
Ensuite, dans un cycle, pour chaque section de l'index, une demande est envoyée pour déterminer sa taille et son niveau de fragmentation. À la fin de l'analyse, les index dont le poids est inférieur au seuil d'entrée sont ignorés sur le client.
EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 1, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 2, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 3, @partitionNr = 1
Lors de l'analyse de la logique de cette application, vous pouvez trouver de nombreuses lacunes. Par exemple, si vous trouvez un problème avec des bagatelles, puis avant d'envoyer une demande, aucune vérification n'est effectuée pour savoir si la section actuelle contient des chaînes afin d'exclure des sections vides de l'analyse.
Mais le problème est plus aigu sous un autre aspect: le nombre de demandes de serveur sera approximativement égal au nombre total de lignes de sys.partitions. Étant donné que de vraies bases de données peuvent contenir des dizaines de milliers de sections, cette nuance peut conduire à un grand nombre de requêtes similaires au serveur. Dans une situation où la base de données est distante, le temps d'analyse deviendra encore plus long en raison de l'augmentation des retards réseau pour chaque demande, même la plus simple.
Contrairement à RedGate, un produit similaire développé dans Devart - dbForge Index Manager pour SQL Server (1.10.38 - 99 $) reçoit les informations dans une grande requête, puis affiche tout sur le client:
SELECT SCHEMA_NAME(o.[schema_id]) AS [schema_name] , o.name AS parent_name , o.[type] AS parent_type , i.name , i.type_desc , s.avg_fragmentation_in_percent , s.page_count , p.partition_number , p.[rows] , ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy , ISNULL(lob.is_lob, 0) AS is_lob , CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s JOIN sys.partitions p ON s.[object_id] = p.[object_id] AND s.index_id = p.index_id AND s.partition_number = p.partition_number JOIN sys.indexes i ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id LEFT JOIN ( SELECT c.[object_id] , index_id = ISNULL(i.index_id, 1) , is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END) , is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END) FROM sys.columns c LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id AND i.index_id > 0 WHERE c.system_type_id IN (34, 35, 99) OR c.max_length = -1 GROUP BY c.[object_id], i.index_id ) lob ON lob.[object_id] = i.[object_id] AND lob.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = i.[object_id] JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id WHERE i.[type] IN (1, 2) AND i.is_disabled = 0 AND i.is_hypothetical = 0 AND s.index_level = 0 AND s.alloc_unit_type_desc = 'IN_ROW_DATA' AND o.[type] IN ('U', 'V')
Nous avons réussi à nous débarrasser du problème principal avec le voile du même type de requêtes dans un produit concurrent, mais les inconvénients de cette implémentation sont qu'aucun paramètre supplémentaire n'est transmis à la fonction sys.dm_db_index_physical_stats, ce qui peut limiter l'analyse des index évidemment inutiles. En fait, cela conduit à obtenir des informations sur tous les indices du système et à charger des disques supplémentaires au stade de l'analyse.
Il est important de noter que les données obtenues à partir de sys.dm_db_index_physical_stats ne sont pas mises en cache de manière permanente dans le pool de mémoire tampon.Par conséquent, la minimisation des lectures physiques lors de l'obtention d'informations sur la fragmentation d'index était l'une des tâches prioritaires pendant le développement.
Après plusieurs expériences, il s'est avéré combiner les deux approches, divisant le scan en deux parties. Tout d'abord, une grande requête détermine la taille des sections, en pré-filtrant celles qui ne sont pas dans la plage de filtrage:
INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages) SELECT [container_id] , SUM([total_pages]) , SUM([used_pages]) FROM sys.allocation_units WITH(NOLOCK) GROUP BY [container_id] HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize
Ensuite, nous obtenons uniquement les sections qui contiennent des données afin d'éviter des opérations de lecture inutiles à partir d'index vides.
SELECT [object_id] , [index_id] , [partition_id] , [partition_number] , [rows] , [data_compression] INTO #Partitions FROM sys.partitions WITH(NOLOCK) WHERE [object_id] > 255 AND [rows] > 0 AND [object_id] NOT IN (SELECT * FROM #ExcludeList)
Selon les paramètres, seuls les types d'index sont obtenus que l'utilisateur souhaite analyser (le travail avec les segments, les index cluster / non cluster et les indicateurs de colonne est pris en charge).
INSERT INTO #Indexes SELECT ObjectID = i.[object_id] , IndexID = i.index_id , IndexName = i.[name] , PagesCount = a.ReservedPages , UnusedPagesCount = a.ReservedPages - a.UsedPages , PartitionNumber = p.[partition_number] , RowsCount = ISNULL(p.[rows], 0) , IndexType = i.[type] , IsAllowPageLocks = i.[allow_page_locks] , DataSpaceID = i.[data_space_id] , DataCompression = p.[data_compression] , IsUnique = i.[is_unique] , IsPK = i.[is_primary_key] , FillFactorValue = i.[fill_factor] , IsFiltered = i.[has_filter] FROM #AllocationUnits a JOIN #Partitions p ON a.ContainerID = p.[partition_id] JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id] AND p.[index_id] = i.[index_id] WHERE i.[type] IN (0, 1, 2, 5, 6) AND i.[object_id] > 255
Après cela, un peu de magie commence: pour tous les petits indices, nous déterminons le niveau de fragmentation en appelant à plusieurs reprises la fonction sys.dm_db_index_physical_stats avec une indication complète de tous les paramètres.
INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation) SELECT i.ObjectID , i.IndexID , i.PartitionNumber , r.[avg_fragmentation_in_percent] FROM #Indexes i CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r WHERE i.PagesCount <= @PreDescribeSize AND r.[index_level] = 0 AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA' AND i.IndexType IN (0, 1, 2)
Ensuite, nous renvoyons toutes les informations possibles au client, en filtrant les données excédentaires:
SELECT i.ObjectID , i.IndexID , i.IndexName , ObjectName = o.[name] , SchemaName = s.[name] , i.PagesCount , i.UnusedPagesCount , i.PartitionNumber , i.RowsCount , i.IndexType , i.IsAllowPageLocks , u.TotalWrites , u.TotalReads , u.TotalSeeks , u.TotalScans , u.TotalLookups , u.LastUsage , i.DataCompression , f.Fragmentation , IndexStats = STATS_DATE(i.ObjectID, i.IndexID) , IsLobLegacy = ISNULL(lob.IsLobLegacy, 0) , IsLob = ISNULL(lob.IsLob, 0) , IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT) , IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT) , FileGroupName = fg.[name] , i.IsUnique , i.IsPK , i.FillFactorValue , i.IsFiltered , a.IndexColumns , a.IncludedColumns FROM #Indexes i JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id] LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID AND a.IndexID = i.IndexID LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID AND f.IndexID = i.IndexID AND f.PartitionNumber = i.PartitionNumber LEFT JOIN ( SELECT ObjectID = [object_id] , IndexID = [index_id] , TotalWrites = NULLIF([user_updates], 0) , TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0) , TotalSeeks = NULLIF([user_seeks], 0) , TotalScans = NULLIF([user_scans], 0) , TotalLookups = NULLIF([user_lookups], 0) , LastUsage = ( SELECT MAX(dt) FROM ( VALUES ([last_user_seek]) , ([last_user_scan]) , ([last_user_lookup]) , ([last_user_update]) ) t(dt) ) FROM sys.dm_db_index_usage_stats WITH(NOLOCK) WHERE [database_id] = @DBID ) u ON i.ObjectID = u.ObjectID AND i.IndexID = u.IndexID LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID AND lob.IndexID = i.IndexID LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id] JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id] WHERE o.[type] IN ('V', 'U') AND ( f.Fragmentation >= @Fragmentation OR i.PagesCount > @PreDescribeSize OR i.IndexType IN (5, 6) )
Après cela, les requêtes ponctuelles déterminent le niveau de fragmentation pour les grands indices.
EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1044198770, @IndexId = 1, @PartitionNumber = 1 EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1
En raison de cette approche, lors de la génération de requêtes, il a été possible de résoudre les problèmes de performances de numérisation rencontrés dans les applications des concurrents. Cela pourrait être terminé, mais au cours du développement, de nouvelles idées sont progressivement apparues qui ont permis d'élargir le champ d'application de votre produit.
Initialement, le support pour travailler avec WAIT_AT_LOW_PRIORITY a été implémenté, puis il est devenu possible d'utiliser DATA_COMPRESSION et FILL_FACTOR pour reconstruire les indices.

L'application était légèrement surchargée de fonctionnalités auparavant non planifiées, telles que la maintenance des colonnes de colonnes:
SELECT * FROM ( SELECT IndexID = [index_id] , PartitionNumber = [partition_number] , PagesCount = SUM([size_in_bytes]) / 8192 , UnusedPagesCount = ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) / 8192 , Fragmentation = CAST(ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) * 100. / SUM([size_in_bytes]) AS FLOAT) FROM sys.fn_column_store_row_groups(@ObjectID) GROUP BY [index_id] , [partition_number] ) t WHERE Fragmentation >= @Fragmentation AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize
Ou la possibilité de créer des index non clusterisés basés sur les informations de dm_db_missing_index:
SELECT ObjectID = d.[object_id] , UserImpact = gs.[avg_user_impact] , TotalReads = gs.[user_seeks] + gs.[user_scans] , TotalSeeks = gs.[user_seeks] , TotalScans = gs.[user_scans] , LastUsage = ISNULL(gs.[last_user_scan], gs.[last_user_seek]) , IndexColumns = CASE WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NOT NULL THEN d.[equality_columns] + ', ' + d.[inequality_columns] WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NULL THEN d.[equality_columns] ELSE d.[inequality_columns] END , IncludedColumns = d.[included_columns] FROM sys.dm_db_missing_index_groups g WITH(NOLOCK) JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle] JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle] WHERE d.[database_id] = DB_ID()
Résumé
Après six mois de la phase de développement actif, je suis heureux que les plans ne s'arrêtent pas là, car je veux continuer à développer ce produit. L'étape suivante consiste à ajouter des fonctionnalités pour rechercher des index en double ou inutilisés, ainsi qu'à implémenter une prise en charge complète pour la diffusion de statistiques dans SQL Server.
Basé sur le fait qu'il existe de nombreuses solutions payantes sur le marché, je veux croire qu'en raison du positionnement libre, d'une description des métadonnées plus optimisée et de la présence de diverses petites choses utiles pour quelqu'un, ce produit deviendra certainement utile dans les tâches quotidiennes.
La version actuelle de l'application peut être téléchargée sur
GitHub . Les sources sont au même endroit.