Photo prise de la publicationPrésentation
L'une des tâches les plus urgentes du traitement numérique du signal est de nettoyer le signal du bruit. Tout signal pratique contient non seulement des informations utiles, mais également des traces de certains effets externes d'interférences ou de bruit. De plus, lors des diagnostics de vibrations, les signaux des capteurs de vibrations ont un spectre de fréquences non stationnaire, ce qui complique la tâche de filtrage.
Il existe de nombreuses façons différentes de supprimer le bruit haute fréquence d'un signal. Par exemple, la bibliothèque Scipy contient des filtres basés sur diverses méthodes de filtrage: Kalman; lisser le signal en le faisant la moyenne le long de l'axe du temps, et autres.
Cependant, l'avantage de la méthode de transformation en ondelettes discrètes (DWT) est la variété des formes d'ondelettes. Vous pouvez sélectionner une ondelette, qui aura une forme caractéristique des phénomènes attendus. Par exemple, vous pouvez sélectionner un signal dans une gamme de fréquences donnée, dont la forme est responsable de l'apparition d'un défaut.
Le but de cette publication est d'analyser les méthodes de filtrage des signaux des capteurs de vibration en utilisant la conversion de signal DWT, le filtre de Kalman et la méthode de la moyenne mobile.
Données source pour l'analyse
Dans la publication, le fonctionnement des filtres basés sur diverses méthodes de filtrage sera analysé à l'aide d'
un ensemble de données de la NASA . Données obtenues sur la plateforme expérimentale PRONOSTIA:

Le kit contient des données sur les signaux des capteurs de vibration pour l'usure de divers types de roulements. La fonction des dossiers contenant les fichiers de signaux est indiquée dans le
tableau :
La surveillance de l'état des roulements est assurée par les signaux des capteurs de vibration (accéléromètres horizontaux et verticaux), la force et la température.

Signaux reçus pour trois charges différentes:
- Premières conditions de travail: 1800 tr / min et 4000 N;
- Deuxième conditions de travail: 1650 tr / min et 4200 N;
- Troisième conditions de fonctionnement: 1500 tr / min et 5000 N.
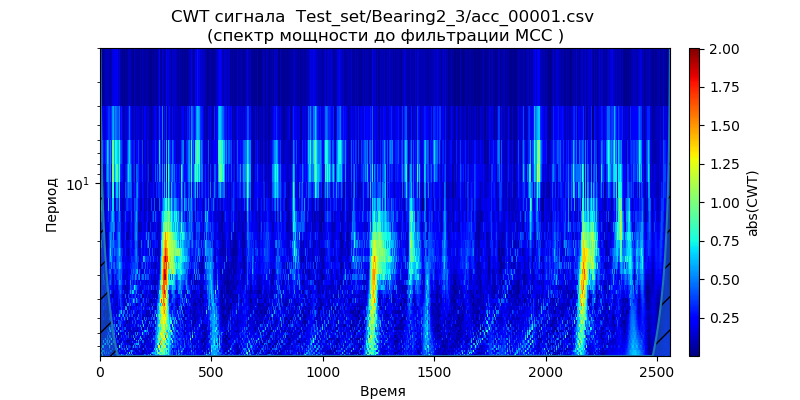
Pour ces conditions, en utilisant la conversion continue du signal en ondelettes, nous construisons les
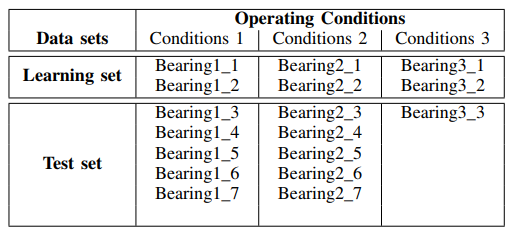
scalogrammes de puissance spectrale pour les données de l'ensemble de test - un fichier (pour un type de roulements) à partir des dossiers: ['Test_set / Bearing1_3 / acc_00001.csv', 'Test_set / Bearing2_3 / acc_00001. csv ',' Test_set / Bearing3_3 / acc_00001.csv '] (voir tableau 1).
Liste des scalogrammesimport scaleogram as scg import pandas as pd from pylab import * import pywt filename_n = ['Test_set/Bearing1_3/acc_00001.csv', 'Test_set/Bearing2_3/acc_00001.csv', 'Test_set/Bearing3_3/acc_00001.csv'] for filename in filename_n: df = pd.read_csv(filename, header=None) signal = df[4].values wavelet = 'cmor1-0.5' ax = scg.cws(signal, scales=arange(1, 40), wavelet=wavelet, figsize=(8, 4), cmap="jet", cbar=None, ylabel=' ', xlabel=" ", yscale="log", title='- %s \n( )'%filename) show()


Il résulte des scalogrammes donnés que les moments d'augmentation de la puissance du spectre apparaissent plus tôt dans le temps et démontrent la fréquence des conditions de fonctionnement: 1650 tr / min et 4200 N, ce qui indique une dégradation accélérée des roulements dans cette bande de fréquence pour la force réduite. Nous utiliserons ce signal ('Test_set / Bearing2_3 / acc_00001.csv') pour analyser les méthodes d'élimination du bruit.
Déconstruction du signal à l'aide de DWT
Dans la
publication, nous avons vu comment un banc de filtres est implémenté sur le DWT qui peut déconstruire un signal dans ses sous-bandes de fréquence. Les coefficients d'approximation (cA) représentent la partie basse fréquence du signal (filtre de moyenne). Les coefficients de détail (cD) représentent la partie haute fréquence du signal. Ensuite, nous examinerons comment le DWT peut être utilisé pour déconstruire un signal dans ses sous-bandes de fréquence et restaurer le signal d'origine.
Il existe deux façons de résoudre le problème de déconstruction du signal à l'aide des outils PyWavelets:
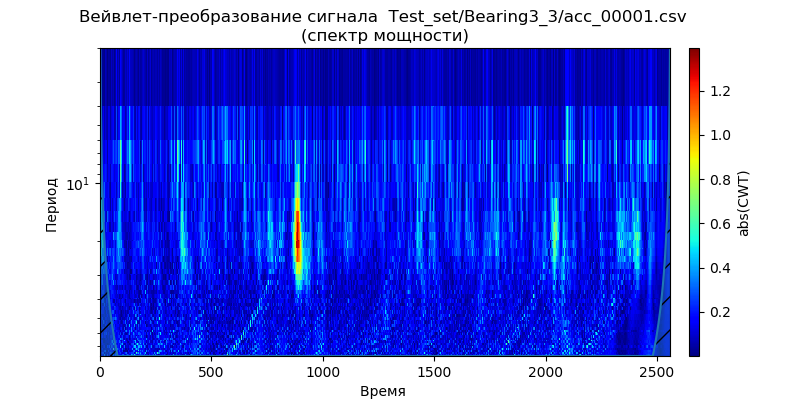
La première consiste à appliquer pywt.dwt () au signal pour extraire les coefficients d'approximation et de détail (cA1, cD1). Ensuite, pour restaurer le signal, nous utiliserons pywt.idwt ():
Annonce import pywt from scipy import * import pandas as pd from pylab import * filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values (cA1, cD1) = pywt .dwt (signal, 'db2', 'smooth') r_signal = pywt.idwt (cA1, cD1, 'db2', 'smooth') fig, ax =subplots(figsize=(8,4)) ax.plot(signal, 'b',label=' ') ax.plot(r_signal, 'r', label=' ', linestyle='--') ax.legend(loc='upper left') ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) ax.set_title(' ( pywt.dwt()) \n ( pywt.idwt()) ') show()
La deuxième façon d'appliquer la fonction pywt.wavedec () au signal est de restaurer tous les coefficients d'approximation et de détail à un certain niveau. Cette fonction prend le signal d'entrée et le niveau en entrée et renvoie un ensemble de coefficients d'approximation (nième niveau) et n ensembles de coefficients de détail (de 1 à nième niveau). Pour la déconstruction, appliquez pywt.waverec ():
Annonce import pywt import pandas as pd from pylab import * filename = 'Test_set/Bearing3_3/acc_00026.csv' df = pd.read_csv(filename, header=None) signal = df[4].values coeffs = pywt.wavedec(signal, 'db2', level=8) r_signal = pywt.waverec(coeffs, 'db2') fig, ax = plt.subplots(figsize=(8,4)) ax.plot(signal, 'b',label=' ') ax.plot(r_signal, 'r ',label= ' ', linestyle='--') ax.legend(loc='upper left') ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) ax.set_title(' - level.\n ( pywt.wavedec()) ') show()

La deuxième façon de déconstruire et de restaurer le signal est plus pratique, elle vous permet de définir immédiatement le niveau de déconstruction souhaité.
Suppression du bruit haute fréquence en éliminant certains des coefficients de détail lors de la déconstruction du signal
Nous allons restaurer le signal en supprimant certains des coefficients de détail. Étant donné que les coefficients de détail représentent la partie haute fréquence du signal, nous filtrons simplement cette partie du spectre de fréquence. S'il y a du bruit haute fréquence dans le signal, c'est une façon de le filtrer.
Dans la bibliothèque PyWavelets, cela peut être fait en utilisant la fonction de traitement de seuil pywt.threshol ():
pywt.threshold (data, value, mode = 'soft', substitute = 0) ¶
données: array_like
Données numériques.valeur: scalaire
Valeur seuil.mode: {'doux', 'dur', 'garrote', 'plus grand', 'moins'}
Définit le type de seuil qui sera appliqué à l'entrée. La valeur par défaut est «douce».substitut: flotteur, facultatif
Valeur de substitution (par défaut: 0).sortie: tableau
Tableau de seuil.L'application de la fonction de traitement de seuil pour une valeur de seuil donnée est mieux envisagée à l'aide de l'exemple suivant:
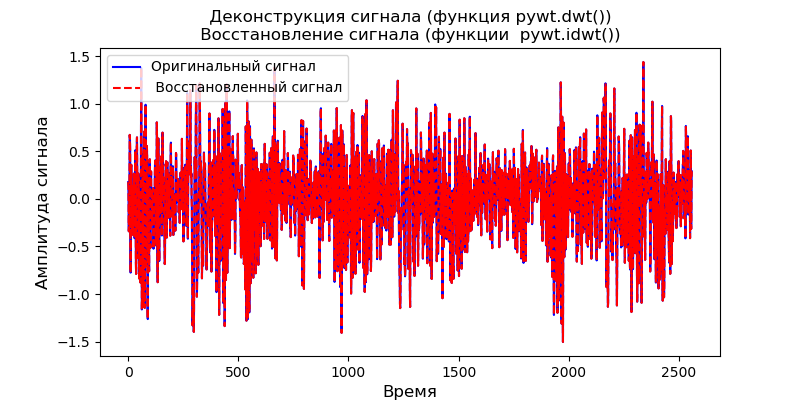
>>>> from scipy import* >>> import pywt >>> data =linspace(1, 4, 7) >>> data array([1. , 1.5, 2. , 2.5, 3. , 3.5, 4. ]) >>> pywt.threshold(data, 2, 'soft') array([0. , 0. , 0. , 0.5, 1. , 1.5, 2. ]) >>> pywt.threshold(data, 2, 'hard') array([0. , 0. , 2. , 2.5, 3. , 3.5, 4. ]) >>> pywt.threshold(data, 2, 'garrote') array([0. , 0. , 0., 0.9,1.66666667, 2.35714286, 3.])
Nous traçons le graphique de la fonction de seuil à l'aide de la liste suivante:
Annonce from scipy import* from pylab import* import pywt s = linspace(-4, 4, 1000) s_soft = pywt.threshold(s, value=0.5, mode='soft') s_hard = pywt.threshold(s, value=0.5, mode='hard') s_garrote = pywt.threshold(s, value=0.5, mode='garrote') figsize=(10, 4) plot(s, s_soft) plot(s, s_hard) plot(s, s_garrote) legend(['soft (0.5)', 'hard (0.5)', 'non-neg. garrote (0.5)']) xlabel(' ') ylabel(' ') show()
Le graphique montre que le seuil de Garott non négatif est intermédiaire entre le seuil doux et dur. Une paire de seuils est nécessaire pour définir la largeur de la région de transition.
L'influence de la fonction de seuil sur les caractéristiques du filtre
Comme il ressort du graphique ci-dessus, seules deux fonctions de seuil «soft» et «garrote» nous conviennent, pour étudier leur influence sur les caractéristiques du filtre, nous notons la liste:
Annonce import pandas as pd from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values v='bior4.4' thres=['soft' ,'garrote'] for w in thres: def lowpassfilter(signal, thresh, wavelet=v): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, level=8,mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode=w ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' :%s\n :%s'%(v,w), fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) show()

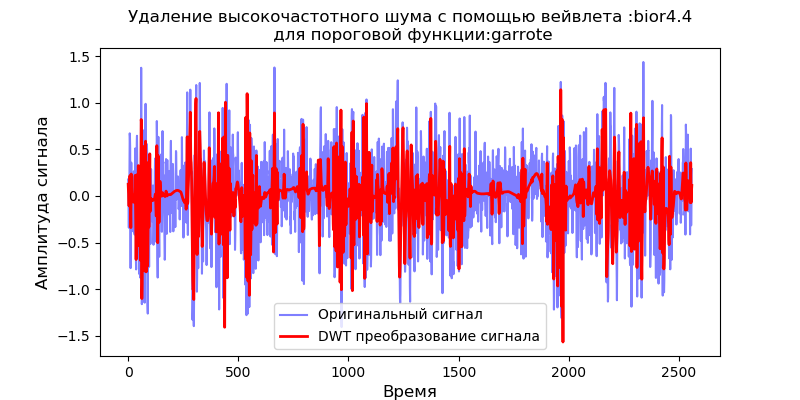
Comme il ressort des graphiques, la fonction douce offre un meilleur lissage que la fonction «garrote», nous utiliserons donc la fonction douce à l'avenir.
L'influence du seuil de détail sur les caractéristiques du filtre
Pour le type de filtre considéré, le seuil de modification des coefficients de détail est une caractéristique importante, nous étudions donc son effet à l'aide de la liste suivante:
Annonce import pandas as pd from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values v='bior4.4' thres=[0.1,0.4,0.6] for w in thres: def lowpassfilter(signal, thresh, wavelet=v): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, level=8,mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode='soft' ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal,w) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' :%s\n %s'%(v,w), fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) show()



Comme il ressort des graphiques obtenus, le seuil de niveau de détail affecte l'échelle des pièces filtrées. Avec une augmentation du seuil, l'ondelette soustrait le bruit d'un niveau toujours croissant jusqu'à ce qu'un agrandissement excessif de l'échelle de détail se produise et que la transformation commence à déformer la forme du signal d'origine. Pour notre signal, le seuil ne doit pas être supérieur à 0,63.
L'effet des ondelettes sur les caractéristiques du filtre
La bibliothèque PyWavelets a un nombre suffisant d'ondelettes pour la conversion DWT, qui peuvent être obtenues comme ceci:
>>> import pywt >>> print(pywt.wavelist(kind= 'discrete')) ['bior1.1', 'bior1.3', 'bior1.5', 'bior2.2', 'bior2.4', 'bior2.6', 'bior2.8', 'bior3.1', 'bior3.3', 'bior3.5', 'bior3.7', 'bior3.9', 'bior4.4', 'bior5.5', 'bior6.8', 'coif1', 'coif2', 'coif3', 'coif4', 'coif5', 'coif6', 'coif7', 'coif8', 'coif9', 'coif10', 'coif11', 'coif12', 'coif13', 'coif14', 'coif15', 'coif16', 'coif17', 'db1', 'db2', 'db3', 'db4', 'db5', 'db6', 'db7', 'db8', 'db9', 'db10', 'db11', 'db12', 'db13', 'db14', 'db15', 'db16', 'db17', 'db18', 'db19', 'db20', 'db21', 'db22', 'db23', 'db24', 'db25', 'db26', 'db27', 'db28', 'db29', 'db30', 'db31', 'db32', 'db33', 'db34', 'db35', 'db36', 'db37', 'db38', 'dmey', 'haar', 'rbio1.1', 'rbio1.3', 'rbio1.5', 'rbio2.2', 'rbio2.4', 'rbio2.6', 'rbio2.8', 'rbio3.1', 'rbio3.3', 'rbio3.5', 'rbio3.7', 'rbio3.9', 'rbio4.4', 'rbio5.5', 'rbio6.8', 'sym2', 'sym3', 'sym4', 'sym5', 'sym6', 'sym7', 'sym8', 'sym9', 'sym10', 'sym11', 'sym12', 'sym13', 'sym14', 'sym15', 'sym16', 'sym17', 'sym18', 'sym19', 'sym20']
L'influence de l'ondelette sur la caractéristique du filtre dépend de sa fonction primitive. Pour démontrer cette dépendance, nous sélectionnons deux ondelettes de la famille Dobeshi - db1 et db38, et considérons ces familles:
Annonce import pywt from pylab import* db_wavelets = ['db1', 'db38'] fig, axarr = subplots(ncols=2, nrows=5, figsize=(14,8)) fig.suptitle(' : db1,db38', fontsize=14) for col_no, waveletname in enumerate(db_wavelets): wavelet = pywt.Wavelet(waveletname) no_moments = wavelet.vanishing_moments_psi family_name = wavelet.family_name for row_no, level in enumerate(range(1,6)): wavelet_function, scaling_function, x_values = wavelet.wavefun(level = level) axarr[row_no, col_no].set_title("{} : {}. : {}. :: {} ".format( waveletname, level, no_moments, len(x_values)), loc='left') axarr[row_no, col_no].plot(x_values, wavelet_function, 'b--') axarr[row_no, col_no].set_yticks([]) axarr[row_no, col_no].set_yticklabels([]) tight_layout() subplots_adjust(top=0.9) show()
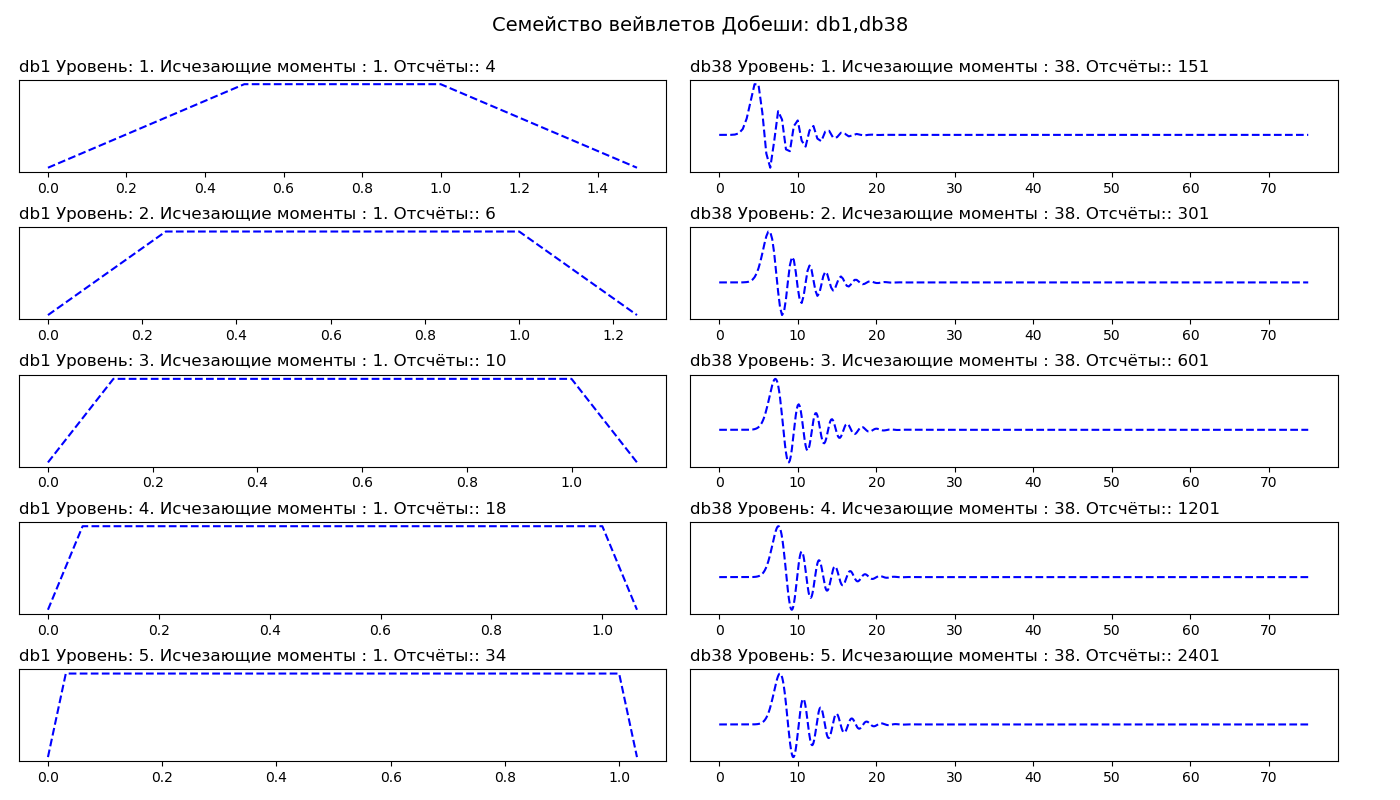
Dans la première colonne, nous voyons des ondelettes de Daubeshi du premier ordre (db1), dans la deuxième colonne du trente-huitième ordre (db38). Ainsi, db1 a un moment d'extinction et db38 a 38 moments d'extinction. Le nombre de moments de disparition est lié à l'ordre d'approximation et au lissé de l'ondelette. Si une ondelette a P points de disparition, elle peut se rapprocher des polynômes de degré P - 1.
Des ondelettes plus lisses créent une approximation de signal plus douce, et vice versa - des ondelettes «courtes» suivent mieux les pics de la fonction approchée. Lors du choix d'une ondelette, nous pouvons également indiquer quel doit être le niveau de décomposition. Par défaut, PyWavelets sélectionne le niveau de décomposition maximum possible pour le signal d'entrée. Le niveau de décomposition maximum dépend de la longueur du signal d'entrée et de l'ondelette:
Annonce import pandas as pd import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) data = df[4].values w=['db1', 'db38'] for v in w: n_level=pywt.dwt_max_level(len(data),v) print(' %s : %s ' %(v,n_level))
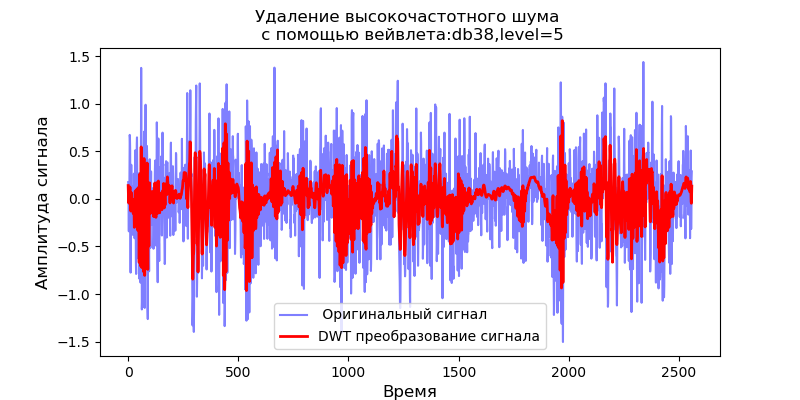
Pour ondelette db1, niveau de décomposition maximum: 11
Pour ondelette db38, niveau de décomposition maximum: 5
Pour les valeurs obtenues des niveaux maximaux de décomposition en ondelettes, nous considérons le fonctionnement du filtre pour éliminer le bruit haute fréquence:
Annonce import pandas as pd import scaleogram as scg from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values discrete_wavelets =[('db38', 5),('db1',11)] for v in discrete_wavelets: def lowpassfilter(signal, thresh = 0.63, wavelet=v[0]): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode='soft' ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal wavelet = pywt.DiscreteContinuousWavelet(v[0]) phi, psi, x = wavelet.wavefun(level=v[1]) fig, ax = subplots(figsize=(8,4)) ax.set_title(" : %s,level=%s"%(v[0],v[1]), fontsize=12) ax.plot(x,phi,linewidth=2) fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' \n :%s,level=%s'%(v[0],v[1]),fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) wavelet = 'cmor1-0.5' ax = ax = scg.cws(rec, scales=arange(1,128), wavelet=wavelet,figsize=(8, 4), cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT \n( DWT )') show()

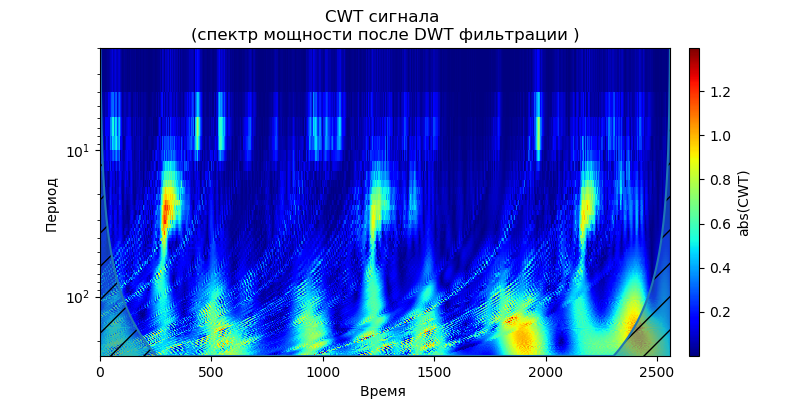

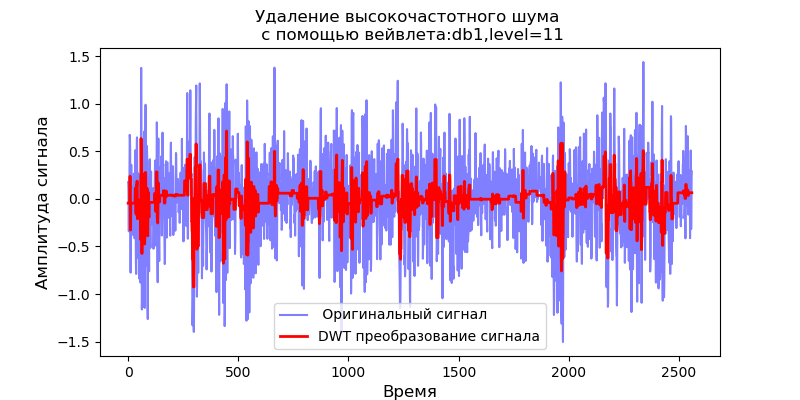

Il résulte des scalogrammes donnés des signaux à la sortie du filtre que, pour l'ondelette db38, la puissance de crête du spectre est suivie de régions localisées, pour l'ondelette db1 ces régions disparaissent. Vous pouvez choisir une ondelette dont la fonction antidérivative aura une forme caractéristique des phénomènes que nous attendons. Il convient de noter que, par exemple, l'ondelette db38 peut se rapprocher d'un signal de polynôme de degré 37. Cela étend la classification des signaux, par exemple, pour identifier les dysfonctionnements des équipements en fonction des signaux des capteurs de vibrations.
Étant donné que le signal après le filtre avec l'ondelette de Daubechies forme une série temporelle utilisant des coefficients d'approximation et de décomposition comme caractéristiques de la série, on peut déterminer le degré de proximité de ces séries, ce qui simplifie considérablement leur recherche et leur classificationFiltre de Kalman pour éliminer le bruit haute fréquence
Le filtre de Kalman est largement utilisé pour filtrer le bruit dans divers systèmes dynamiques. Considérons un système dynamique avec un vecteur d'état x.
x=F cdotx+w(Q)où F est la matrice de transition
w (Q) est un processus aléatoire (bruit) avec une attente mathématique nulle et une matrice de covariance Q.
Nous observerons les transitions d'état du système avec une erreur de mesure connue à chaque instant. L'élimination du bruit à l'aide de la méthode de Kalman se compose de deux étapes - extrapolation et correction, cela ressemble à ceci.
Définissez les paramètres du système:
Matrice Q de covariance de bruit (covariance de bruit de processus).
H est la matrice d'observation (mesure).
R - covariance du bruit d'observation (covariance du bruit de mesure).
P = Q est la valeur initiale de la matrice de covariance pour le vecteur d'état.
z (t) est l'état observé du système.
x = z (0) est la valeur initiale de l'état du système.
Pour chaque observation z, nous calculerons l'état filtré x
et pour cela, nous effectuons les étapes suivantes.
• étape 1: extrapolation
1. extrapolation (prédiction) de l'état du système
x=F cdotx2. calculer la matrice de covariance pour le vecteur d'état extrapolé
F=F cdotP cdotFT+Q• étape 2: correction
1. calculer le vecteur d'erreur, l'écart de l'observation par rapport à l'état attendu
y=z−H cdotx2. calculer la matrice de covariance pour le vecteur de déviation (vecteur d'erreur)
S=H cdotP cdotHT+R3. calculer les gains de Kalman
K=P cdotH cdotHT cdotS−14. correction de l'estimation du vecteur d'état
x=x+K cdoty5. nous corrigeons la matrice de covariance pour estimer le vecteur d'état du système
P=(I−K cdotH) cdotPListe pour l'implémentation de l'algorithme from scipy import* from pylab import* import pandas as pd def kalman_filter( z, F = eye(2), # (transitionMatrix) Q = eye(2)*3e-3, # (processNoiseCov) H = eye(2), # (measurement) R = eye(2)*3e-1 # (measurementNoiseCov) ): n = z.shape[0]
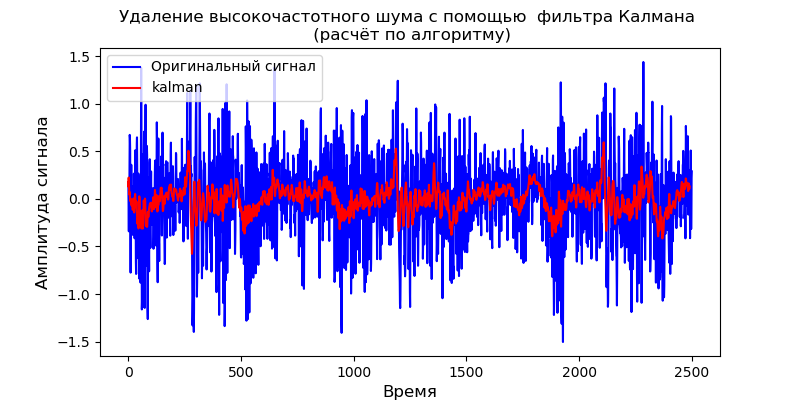
Pour le modèle dynamique donné, vous pouvez utiliser la bibliothèque pyKalman:
Annonce from pykalman import KalmanFilter import pandas as pd from pylab import * import scaleogram as scg filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values measurements =signal kf = KalmanFilter(transition_matrices=[1] ,



Le filtre de Kalman élimine bien le bruit haute fréquence, cependant, il ne permet pas de changer la forme du signal de sortie.
Méthode moyenne mobile
En déterminant la direction principale des changements dans une séquence fortement oscillante, le problème se pose de l'aplanir en utilisant la méthode de la moyenne mobile. Cela peut être les lectures du capteur de niveau de carburant dans la voiture ou, comme dans notre cas, les données des capteurs haute fréquence concernant la dégradation accélérée des roulements. Le problème peut être considéré comme la restauration d'une séquence r à laquelle le bruit s'est superposé.
Moyenne mobile simple pour court - SMA (moyenne mobile simple). Pour calculer la valeur actuelle du filtre
ri nous faisons simplement la moyenne des n éléments précédents de la séquence, de sorte que le filtre commence à fonctionner avec l'élément de séquence n.
ri= frac1n cdot sumnj=1y(i−j);i>nAnnonce <source lang="python">from scipy import * import pandas as pd from pylab import * import pywt import scaleogram as scg def get_ave_values(xvalues, yvalues, n = 6): signal_length = len(xvalues) if signal_length % n == 0: padding_length = 0 else: padding_length = n - signal_length//n % n xarr = array(xvalues) yarr = array(yvalues) xarr.resize(signal_length//n, n) yarr.resize(signal_length//n, n) xarr_reshaped = xarr.reshape((-1,n)) yarr_reshaped = yarr.reshape((-1,n)) x_ave = xarr_reshaped[:,0] y_ave = nanmean(yarr_reshaped, axis=1) return x_ave, y_ave def plot_signal_plus_average(time, signal, average_over = 5): fig, ax = subplots(figsize=(8, 4)) time_ave, signal_ave = get_ave_values(time, signal, average_over) ax.plot(time_ave, signal_ave,"b", label = ' (n={})'.format(5)) ax.set_xlim([time[0], time[-1]]) ax.set_ylabel(' ', fontsize=12) ax.set_title(' SMA', fontsize=14) ax.set_xlabel('', fontsize=12) ax.legend() return signal_ave filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) df_nino = df[4].values N = df_nino.shape[0] time = arange(0, N) signal = df_nino signal_ave=plot_signal_plus_average(time, signal) wavelet = 'cmor1-0.5' ax = ax = scg.cws(signal, scales=arange(1,40), wavelet=wavelet, figsize=(8, 4),cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT %s \n( )'%filename) ax = ax = scg.cws(signal_ave, scales=arange(1,40), wavelet=wavelet, figsize=(8, 4), cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT %s \n( )'%filename) show()


Comme il ressort du scalogramme, la méthode SMA ne nettoie pas le signal du bruit haute fréquence,
comme mentionné ci-dessus est utilisé pour le lissage.
Conclusions:
- En utilisant le module scalogramme, des scalogrammes en ondelettes CWT de trois signaux de capteur de vibration d'essai ont été obtenus pour différentes conditions d'essai pour des roulements du même type. Selon les données du scalogramme, un signal présentant des signes clairement exprimés de dégradation tardive a été sélectionné. Ce signal a été utilisé pour démontrer le fonctionnement des filtres dans tous les exemples donnés.
- Les méthodes de la bibliothèque PyWavelets pour la déconstruction DWT et la restauration du signal du capteur de vibration utilisant les modules pywt.dwt (), pywt.idwt () et le module pywt.wavedec () pour un niveau d'ondelettes donné sont considérées.
- Les exemples illustrent les fonctionnalités d'application du module pywt.threshol () pour filtrer les coefficients de détail DWT, qui sont responsables de la partie haute fréquence du spectre à l'aide de fonctions de seuil pour une valeur de seuil donnée.
- Les effets de l'ondelette DWT anti-dérivative sur la forme d'un signal débarrassé du bruit sont considérés.
- On obtient un modèle de filtre de Kalman pour un milieu dynamique, le modèle est testé sur le signal de test du capteur de vibration. Le tracé d'élimination du bruit est le même que celui obtenu à l'aide du module pyKalman. La nature du graphique coïncide avec le scalogramme.
- .