Le désir de s'éloigner des tests de régression manuelle est une bonne raison d'introduire des autotests. La question est laquelle? Les développeurs d'interfaces Natalya Stus et Alexei Androsov ont rappelé comment leur équipe a traversé plusieurs itérations et construit des tests frontaux dans Auto.ru basés sur Jest et Puppeteer: tests unitaires, tests pour les composants React individuels, tests d'intégration. Le plus intéressant de cette expérience est le test isolé des composants React dans un navigateur sans Selenium Grid, Java et autres.

Alexey:
- Vous devez d'abord dire un peu ce qu'est Automotive News. Ceci est un site de vente de voitures. Il y a une recherche, un compte personnel, des services automobiles, des pièces détachées, des avis, des concessionnaires et bien plus encore. Auto.ru est un très gros projet, beaucoup de code. Nous écrivons tout le code dans un grand monorepe, car tout est mélangé. Les mêmes personnes effectuent des tâches similaires, par exemple pour les mobiles et les ordinateurs de bureau. Il s'avère que beaucoup de code, et monorepa est vital pour nous. La question est de savoir comment le tester?

Nous avons React et Node.js, qui effectue un rendu côté serveur et demande des données au backend. Reste et petits morceaux sur le BEM.

Natalya:
- Nous avons commencé à penser à l'automatisation. Le cycle de sortie de nos applications individuelles comprenait plusieurs étapes. Tout d'abord, la fonctionnalité est développée par le programmeur dans une branche distincte. Après cela, dans la même branche distincte, la fonctionnalité est testée par des testeurs manuels. Si tout va bien, la tâche incombe au candidat à la libération. Sinon, revenez à l'itération de développement, testez à nouveau. Jusqu'à ce que le testeur dise que tout va bien dans cette fonctionnalité, il ne tombera pas dans la version candidate.
Après avoir assemblé la version candidate, il y a une régression manuelle - pas seulement Auto.ru, mais seulement le package que nous allons rouler. Par exemple, si nous allons déployer le site Web de bureau, il y a alors une régression manuelle du site Web de bureau. Ce sont de nombreux cas de test manuels. Une telle régression a pris environ une journée de travail d'un testeur manuel.
Une fois la régression terminée, une libération se produit. Après cela, la branche de publication fusionne dans le maître. À ce stade, nous pouvons simplement injecter le code maître, que nous avons testé uniquement pour le Web de bureau, et ce code peut casser le Web mobile, par exemple. Ce n'est pas vérifié immédiatement, mais seulement lors de la prochaine régression manuelle - le Web mobile.

Naturellement, l'endroit le plus douloureux de ce processus a été la régression manuelle, qui a pris très longtemps. Tous les testeurs manuels sont naturellement fatigués de faire la même chose tous les jours. Par conséquent, nous avons décidé de tout automatiser. La première solution qui a été exécutée a été les autotests Selenium et Java, rédigés par une équipe distincte. Ce sont des tests de bout en bout, e2e, qui ont testé l'ensemble de l'application. Ils ont écrit environ 5 000 de ces tests. Qu'avons-nous fini avec?
Naturellement, nous avons accéléré la régression. Les tests automatiques réussissent beaucoup plus rapidement qu'un testeur manuel, environ 10 fois plus vite. En conséquence, les actions de routine qu'ils effectuaient chaque jour ont été supprimées des testeurs manuels. Les bogues trouvés des autotests sont plus faciles à reproduire. Relancez simplement ce test ou regardez les étapes qu'il fait - contrairement au testeur manuel, qui dira: "J'ai cliqué sur quelque chose et tout s'est cassé."
Assurer la stabilité du revêtement. Nous exécutons toujours les mêmes tests d'exécution - en revanche, encore une fois, à partir des tests manuels, lorsque le testeur peut considérer que nous n'avons pas touché cet endroit, et je ne le vérifierai pas cette fois. Nous avons ajouté des tests pour comparer les captures d'écran, amélioré la précision des tests de l'interface utilisateur - maintenant, nous vérifions la différence de quelques pixels que le testeur ne verra pas avec ses yeux. Tout cela grâce à des tests de captures d'écran.
Mais il y avait des inconvénients. Le plus grand - pour les tests e2e, nous avons besoin d'un environnement de test entièrement cohérent avec le produit. Il doit toujours être tenu à jour et opérationnel. Cela nécessite presque autant de force que la vente d'un support de stabilité. Naturellement, nous ne pouvons pas toujours nous le permettre. Par conséquent, nous avons souvent eu des situations où l'environnement de test se trouve ou quelque part quelque chose est cassé, et les tests échouent, bien qu'il n'y ait eu aucun problème dans le package le plus avant.
Ces tests sont également développés par une équipe distincte, qui a ses propres tâches, son propre tour dans le tracker de tâches, et les nouvelles fonctionnalités sont couvertes avec un certain retard. Ils ne peuvent pas venir immédiatement après la sortie d'une nouvelle fonctionnalité et y écrire immédiatement des autotests. Les tests étant coûteux et difficiles à écrire et à maintenir, nous ne couvrons pas tous les scénarios avec eux, mais seulement les plus critiques. Dans le même temps, une équipe distincte est nécessaire, et elle aura des outils distincts, une infrastructure distincte qui lui est propre. Et l'analyse des tests tombés est également une tâche non triviale pour les testeurs manuels ou pour les développeurs. Je vais vous montrer quelques exemples.
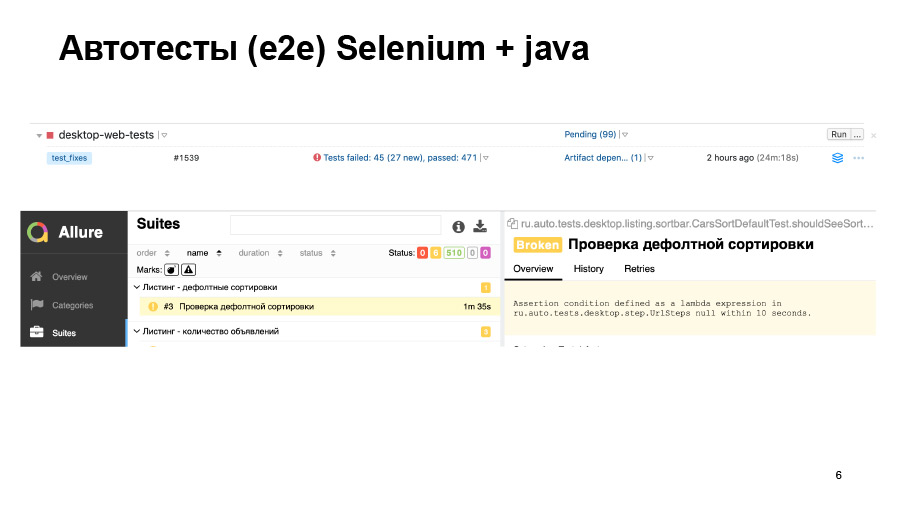
Nous avons effectué des tests. 500 tests réussis, dont certains sont tombés. Nous pouvons voir une telle chose dans le rapport. Ici, le test n'a tout simplement pas commencé, et il n'est pas clair si tout va bien ou non.
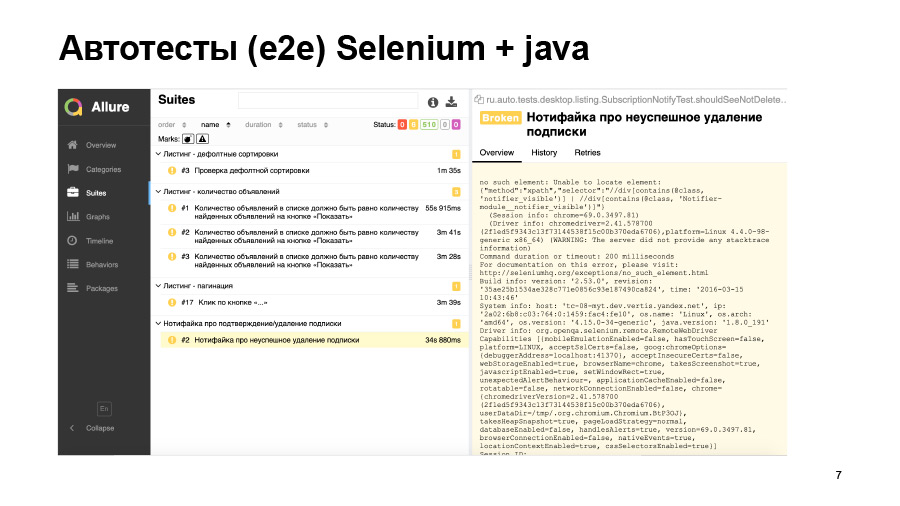
Un autre exemple - le test a commencé, mais s'est écrasé avec une telle erreur. Il n'a trouvé aucun élément sur la page, mais pourquoi - nous ne savons pas. Soit cet élément n'apparaissait tout simplement pas, soit il se trouvait sur la mauvaise page, soit le localisateur avait changé. Tout ce dont vous avez besoin pour vous débarrasser des mains.
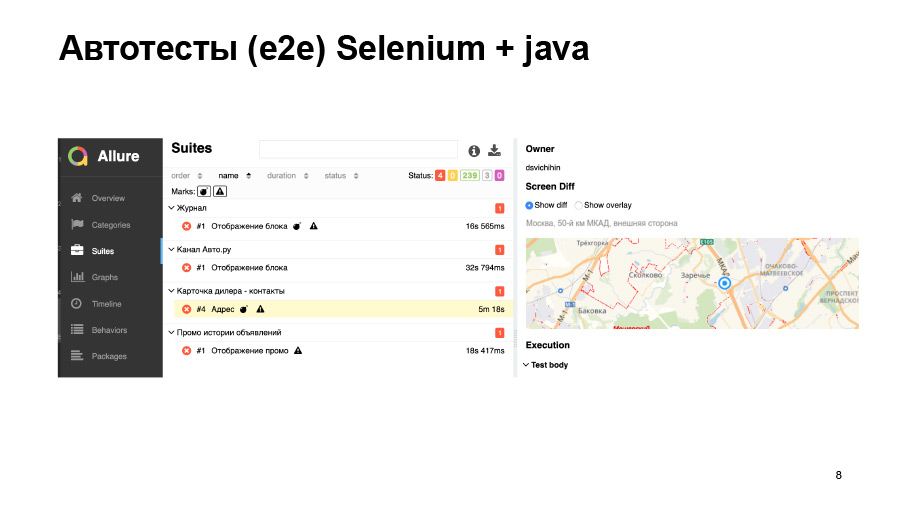
Les tests de capture d'écran ne nous donnent pas toujours une bonne précision. Ici, nous chargeons une sorte de carte, elle a légèrement bougé, notre test est tombé.

Nous avons essayé de résoudre un certain nombre de ces problèmes. Nous avons commencé à exécuter une partie des tests sur le prod - ceux qui n'affectent pas les données utilisateur ne changent rien dans la base de données. Autrement dit, chez prod, nous avons fabriqué une machine distincte qui se penche sur l'environnement de production. Nous installons simplement un nouveau paquet frontal et y exécutons des tests. Le produit est au moins stable.
Nous avons transféré certains des tests aux mokeys, mais nous avons beaucoup de backends différents, des API différentes, et le verrouillage est une tâche très difficile, en particulier pour 5 000 tests. Pour cela, un service spécial appelé mockritsa a été écrit, il permet de faire assez facilement les mokas nécessaires pour le frontend et est assez facile à les proxy.
Nous avons également dû acheter un tas de fer pour que notre grille d'appareils au sélénium à partir de laquelle ces tests sont lancés soit plus grande afin qu'ils ne tombent pas, car ils ne pouvaient pas augmenter le navigateur et, par conséquent, aller plus vite. Même après avoir essayé de résoudre ces problèmes, nous sommes toujours arrivés à la conclusion que ces tests ne sont pas adaptés à l'IC, ils prennent beaucoup de temps. Nous ne pouvons pas les exécuter à chaque demande de pool. Nous n'allons tout simplement jamais analyser de ces rapports, qui seront générés pour chaque demande de pool.

Par conséquent, pour CI, nous avons besoin de tests rapides et stables qui n'échoueront pas pour des raisons aléatoires. Nous voulons exécuter des tests pour la demande de pool sans bancs d'essai, backends, bases de données, sans cas d'utilisation compliqués.
Nous voulons que ces tests soient écrits simultanément avec le code, et que les résultats des tests indiquent immédiatement dans quel fichier quelque chose s'est mal passé.
Alexey:
- Oui, et nous avons décidé d'essayer tout ce que nous voulons, de tout redresser du début à la fin dans la même infrastructure Jest. Pourquoi avons-nous choisi Jest? Nous avons déjà écrit des tests unitaires sur Jest, nous l'avons aimé. C'est un outil populaire et pris en charge, il contient déjà un tas d'intégrations prêtes à l'emploi: React test render, Enzyme. Tout fonctionne hors de la boîte, rien n'a besoin d'être construit, tout est simple.

Et Jest a personnellement gagné pour moi en ce que, contrairement à tout moka, il est difficile de tirer l'effet secondaire d'une sorte de test tiers dans votre jambe si j'oublie de le nettoyer ou autre chose. Dans moka, cela se fait une ou deux fois, mais dans Jest, c'est difficile à faire: il est constamment lancé dans des threads séparés. C'est possible, mais difficile. Et pour e2e sorti Puppeteer, nous avons également décidé de l'essayer. Voilà ce que nous avons.

Natalya:
«Je vais également commencer par un exemple de tests unitaires.» Lorsque nous écrivons des tests simplement pour une fonction, il n'y a pas de problèmes particuliers. Nous appelons cette fonction, passons quelques arguments, comparons ce qui s'est passé avec ce qui aurait dû se produire.
Si nous parlons de composants React, alors tout devient un peu plus compliqué. Nous devons en quelque sorte les rendre. Il existe un moteur de rendu de test React, mais il n'est pas très pratique pour les tests unitaires, car il ne nous permettra pas de tester les composants de manière isolée. Il rendra le composant complètement à la fin, à la mise en page.
Et je veux montrer comment avec Enzyme, il est possible d'écrire des tests unitaires pour les composants React en utilisant un exemple d'un tel composant où nous avons un certain MyComponent. Il obtient une sorte d'accessoire, il a une sorte de logique. Ensuite, il retourne le composant Foo, qui, à son tour, retournera le composant bar, qui déjà dans le composant bar nous renvoie, en fait, la mise en page.

Nous pouvons utiliser un outil Enzyme comme le rendu peu profond. C'est exactement ce dont nous avons besoin pour tester le composant MyComponent de manière isolée. Et ces tests ne dépendront pas de ce que les composants foo et bar contiendront en eux-mêmes. Nous allons juste tester la logique du composant MyComponent.
Jest a une telle chose comme Snapshot, et ils peuvent également nous aider ici. «Attendez-vous à quelque chose toMatchSnapshot» va créer une telle structure pour nous, juste un fichier texte qui stocke, en fait, ce à quoi nous nous attendions, ce que nous obtenons, et ce fichier est écrit la première fois que nous exécutons de tels tests. Avec d'autres exécutions des tests, ce qui est obtenu sera comparé au standard contenu dans le fichier MyComponent.test.js.snap.
Ici, nous voyons juste que tout le rendu, il retourne exactement ce que la méthode de rendu de MyComponent retourne, et ce que foo est, en général, cela ne fait rien. Nous pouvons écrire ces deux tests pour nos deux cas, pour nos deux cas pour le composant MyComponent.

En principe, nous pouvons tester la même chose sans instantané, en vérifiant simplement les scripts dont nous avons besoin, par exemple, en vérifiant quel accessoire est passé au composant foo. Mais cette approche a un inconvénient. Si nous ajoutons un autre élément à MyComponent, notre nouveau test, cela ne s'affiche en aucune façon.

Par conséquent, après tout, les tests d'instantanés sont ceux qui nous montreront presque tous les changements à l'intérieur du composant. Mais si nous écrivons les deux tests sur Snapshot, puis que nous apportons les mêmes modifications dans le composant, nous verrons que les deux tests tomberont. En principe, les résultats de ces tests déchus nous diront la même chose, que nous y avons ajouté une sorte de «bonjour».

Et cela est également redondant, par conséquent, je pense qu'il est préférable d'utiliser un test de capture instantanée pour la même structure. Vérifiez le reste de la logique différemment, sans Snapshot, car Snapshot, ils ne sont pas très indicatifs. Lorsque vous voyez un instantané, vous voyez simplement que quelque chose a été rendu, mais la logique que vous avez testée ici n'est pas claire. Ceci est totalement inapproprié pour TDD si vous souhaitez l'utiliser. Et cela ne fonctionnera pas comme la documentation. Autrement dit, lorsque vous allez regarder ce composant, vous verrez que oui, Snapshot correspond à quelque chose, mais quel type de logique était là n'est pas très clair.


De la même manière, nous écrirons des tests unitaires sur le composant foo, sur le composant bar, par exemple, Snapshot.

Nous bénéficions d'une couverture à 100% pour ces trois composants. Nous pensons avoir tout vérifié, nous sommes bien faits.
Mais disons que nous avons changé quelque chose dans le composant bar, y avons ajouté de nouveaux accessoires, et nous avons eu un test pour le composant bar, évidemment. Nous avons corrigé le test et les trois tests réussissent avec nous.

Mais en fait, si nous collectons toute cette histoire, alors rien ne fonctionnera, car MyComponent ne se réunira pas avec une telle erreur. Nous ne transmettons pas réellement l'hélice qu'il attend au composant barre. Par conséquent, nous parlons du fait que dans ce cas, nous avons également besoin de tests d'intégration qui vérifieront, notamment si nous appelons correctement son composant enfant à partir de notre composant.

En ayant de tels composants et en modifiant l'un d'entre eux, vous voyez immédiatement quels changements dans ce composant ont affecté.
Quelles opportunités avons-nous dans Enzyme pour effectuer des tests d'intégration? Le rendu superficiel lui-même renvoie une telle structure. Il a une méthode de plongée, s'il est appelé sur un composant React, il échouera. En conséquence, en l'appelant sur le composant foo, nous obtenons ce que le composant foo rend, c'est bar, si nous refaisons la plongée, nous obtiendrons, en fait, la disposition que le composant bar nous renvoie. Ce ne sera qu'un test d'intégration.

Ou vous pouvez tout rendre à la fois en utilisant la méthode de montage, qui implémente le rendu DOM complet. Mais je ne conseille pas de faire cela, car ce sera un instantané très difficile. Et, en règle générale, vous n'avez pas besoin de vérifier complètement la structure entière. Il vous suffit de vérifier l'intégration entre les composants parent et enfant dans chaque cas.

Et pour MyComponent, nous ajoutons un test d'intégration, donc dans le premier test j'ajoute juste de la plongée, et il s'avère que nous avons testé non seulement la logique du composant lui-même, mais aussi son intégration avec le composant foo. La même chose, nous ajoutons le test d'intégration pour le composant foo qu'il appelle correctement le composant bar, puis nous vérifions toute cette chaîne, et nous sommes sûrs qu'aucun changement ne nous cassera, en fait, le rendu de MyComponent

Un autre exemple, déjà issu d'un vrai projet. Juste brièvement ce que Jest et Enzyme peuvent faire d'autre. Jest peut faire du moki. Vous pouvez, si vous utilisez une fonction externe dans votre composant, vous pouvez le verrouiller. Par exemple, dans cet exemple, nous appelons une sorte d'api, bien sûr, nous ne voulons pas aller à une api dans le test unitaire, donc nous essuyons simplement la fonction getResource avec un objet jest.fn. En fait, la fonction de simulation. Ensuite, nous pouvons vérifier si elle a été appelée ou non, combien de fois elle a été appelée, avec quels arguments. Tout cela vous permet de faire Jest.

Dans le rendu superficiel, vous pouvez passer le stockage à un composant. Si vous avez besoin d'un magasin, vous pouvez simplement le transférer là-bas, et cela fonctionnera.

Vous pouvez également modifier l'état et l'accessoire dans un composant déjà rendu.

Vous pouvez appeler la méthode de simulation sur certains composants. Il appelle simplement le gestionnaire. Par exemple, si vous simulez un clic, il appellera onClick pour le composant bouton ici. Tout cela peut être lu, bien sûr, dans la documentation sur Enzyme, beaucoup de pièces utiles. Ce ne sont que quelques exemples d'un vrai projet.

Alexey:
- Nous arrivons à la question la plus intéressante. Nous pouvons tester Jest, nous pouvons écrire des tests unitaires, vérifier les composants, vérifier quels éléments répondent incorrectement à un clic. Nous pouvons vérifier leur html. Maintenant, nous devons vérifier la disposition du composant, css.

Et il est conseillé de le faire pour que le principe du test ne diffère en rien de celui que j'ai décrit précédemment. Si je vérifie html, j'ai appelé rendu peu profond, il m'a fallu et rendu html. Je veux vérifier css, appeler simplement une sorte de rendu et vérifier - sans rien lever, sans configurer d'outils.

J'ai commencé à le chercher, et à peu près partout la même réponse a été donnée à tout cela appelé Puppeteer, ou grille de sélénium. Vous ouvrez un onglet, vous allez sur une page html, prenez une capture d'écran et comparez-la avec l'option précédente. Si cela n'a pas changé, alors tout va bien.
La question est, qu'est-ce que le HTML de page si je veux juste vérifier un composant isolément? Il est souhaitable - dans différentes conditions.

Je ne veux pas écrire un tas de ces pages HTML pour chaque composant, pour chaque état. Avito a une bonne course. Roma Dvornov a publié un article sur Habré, et lui, soit dit en passant, a prononcé un discours. Qu'ont-ils fait? Ils prennent des composants, assemblent du HTML via un rendu standard. Ensuite, à l'aide de plugins et de toutes sortes d'astuces, ils collectent tous les actifs qu'ils ont - photos, css. Insérez le tout en html, et ils obtiennent juste le bon html.

Et puis ils ont levé un serveur spécial, y envoient du HTML, il le rend et retourne un résultat. Un article très intéressant, cependant, vous pouvez en tirer beaucoup d'idées intéressantes.

Ce que je n'aime pas là-bas. L'assemblage d'un composant est différent de sa mise en production. Par exemple, nous avons un webpack, et là, il va être collecté par une sorte d'actifs babel, il est retiré différemment là-bas. Je ne peux pas garantir que j'ai testé ce que je vais télécharger maintenant.
Et encore une fois, un service distinct pour les captures d'écran. Je veux le faire plus facilement. Et il y avait, en fait, l'idée que, collectons-le exactement de la même manière que nous le collecterons. Et essayez d'utiliser quelque chose comme Docker, car c'est une telle chose, il peut être placé sur un ordinateur, localement, ce sera simple, isolé, ne touchera à rien, tout va bien.

Mais ce problème est avec la page html, il reste le même qu'il est vraiment. Et une idée est née. Vous avez un tel webpack.conf simplifié, et à partir de là il y a un EntryPoint pour le client js. Les modules sont décrits, comment les assembler, le fichier de sortie, tous les plugins que vous avez décrits, tout est configuré, tout va bien.

Et si j'aime ça? Il ira dans ma composante et la collectera de manière isolée. Et il y aura exactement un composant. Si j'y ajoute un webpack html, cela me donnera également du html, et ces actifs seront collectés là-bas, et cette chose, cependant, peut déjà être testée automatiquement.
Et j'étais sur le point d'écrire tout cela, mais j'ai trouvé ça.

Jest-puppeteer-React, un jeune plugin. Et j'ai commencé à y contribuer activement. Si vous voulez soudainement l'essayer, vous pouvez, par exemple, venir me voir, je peux en quelque sorte vous aider. En fait, le projet n'est pas le mien.
Vous écrivez un fichier normal en tant que test.js, et ces fichiers doivent être écrits un peu séparément pour aider à les trouver, afin de ne pas compiler tout le projet pour vous, mais de compiler uniquement les composants nécessaires. En fait, vous prenez la configuration webpack. Et les points d'entrée changent dans ces fichiers browser.js, c'est-à-dire exactement ce que nous voulons tester va être emballé en html, et avec l'aide de Puppeteer, il vous prendra des captures d'écran.

Que peut-il faire? , jest-image-snapshot. . , , js, media-query, , .
headless-, , , , , headless-, Chrome . web-, , , , .
Docker. . . , Docker, . . Docker , , , Linux, - , - . Docker , .

? , . , . before-after, , . , . , Chrome, Firefox. .
. pixelmatch. , looksame, «», . , .

— . , , . , : - , — Enzyme. Redux store . . viewport, , . , , .

. , . ? , .

: 5-10 . Selenium . , , , . .

Puppeteer, e2e-. , e2e- — , Selenium.
:
— , Selenium Java , . - JS Puppeteer, , .
, . , , .

— Selenium Java, — JS Puppeteer. . 18 . , , Java. , , Java Selenium.

:
— ? . , html-, css . e2e. . , .

, , . . , , — , . , . - , , : , .
, , . git hook, -, . green master — , , , . Je vous remercie