Il y a quelque temps, lors d'une discussion sur l'une des versions de SObjectizer, on nous a demandé: "Est-il possible de créer une DSL pour décrire un pipeline de traitement de données?" En d'autres termes, est-il possible d'écrire quelque chose comme ça:
A | B | C | D
et obtenir un pipeline de travail où les messages vont de A à B, puis à C, puis à D. Avec le contrôle que B reçoit exactement ce type que A renvoie. Et C reçoit exactement ce type que B renvoie. Et ainsi de suite.
C'était une tâche intéressante avec une solution étonnamment simple. Par exemple, voici à quoi peut ressembler la création d'un pipeline:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
Ou, dans un cas plus complexe (qui sera discuté ci-dessous):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
Dans cet article, nous parlerons de l'implémentation d'un tel pipeline DSL. Nous discuterons principalement des parties liées aux fonctions stage() , broadcast() et operator|() avec plusieurs exemples d'utilisation de modèles C ++. J'espère donc que ce sera intéressant même pour les lecteurs qui ne connaissent pas SObjectizer (si vous n'avez jamais entendu parler de SObjectizer, voici un aperçu de cet outil).
Quelques mots sur la démo utilisée
L'exemple utilisé dans l'article a été influencé par mon expérience ancienne (et plutôt oubliée) dans le domaine SCADA.
L'idée de la démo est le traitement des données lues à partir d'un capteur. Les données sont acquises à partir d'un capteur avec une certaine période, puis ces données doivent être validées (les données incorrectes doivent être ignorées) et converties en certaines valeurs réelles. Par exemple, les données brutes lues sur un capteur peuvent être deux valeurs entières de 8 bits et ces valeurs doivent être converties en un nombre à virgule flottante.
Ensuite, les valeurs valides et converties doivent être archivées, distribuées quelque part (sur différents nœuds pour la visualisation, par exemple), vérifiées pour les "alarmes" (si les valeurs sont hors des limites sûres, cela doit être spécialement géré). Ces opérations sont indépendantes et peuvent être effectuées en parallèle.
Les opérations liées à l'alarme détectée peuvent également être effectuées en parallèle: une "alarme" doit être déclenchée (pour que la partie de SCADA sur le nœud actuel puisse y réagir) et les informations sur "l'alarme" doivent être distribuées ailleurs (par exemple : stocké dans une base de données historique et / ou visualisé sur l'écran de l'opérateur SCADA).
Cette logique peut être exprimée sous forme textuelle de cette façon:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
Ou, sous forme graphique:

C'est un exemple plutôt artificiel, mais il a des choses intéressantes que je veux montrer. Le premier est la présence d'étages parallèles dans un pipeline (l'opération broadcast() existe juste à cause de cela). La seconde est la présence d'un état à certains stades. Par exemple, alarm_detector est une étape avec état.
Capacités de pipeline
Un pipeline est construit à partir d'étapes distinctes. Chaque étape est une fonction ou un foncteur du format suivant:
opt<Out> func(const In &);
ou
void func(const In &);
Les étapes qui renvoient un void ne peuvent être utilisées que comme la dernière étape d'un pipeline.
Les étapes sont liées dans une chaîne. Chaque étape suivante reçoit un objet retourné par l'étape précédente. Si l'étape précédente renvoie une valeur opt<Out> vide, l'étape suivante n'est pas appelée.
Il y a une étape de broadcast spéciale. Il est construit à partir de plusieurs pipelines. Une étape de broadcast reçoit un objet de l'étape précédente et le diffuse à chaque pipeline subsidiaire.
Du point de vue du pipeline, l'étape de broadcast ressemble à une fonction du format suivant:
void func(const In &);
Puisqu'il n'y a pas de valeur de retour de l'étape de broadcast , une étape de broadcast ne peut être que la dernière étape d'un pipeline.
Pourquoi l'étape du pipeline renvoie-t-elle une valeur facultative?
C'est parce qu'il est nécessaire de supprimer certaines valeurs entrantes. Par exemple, l'étape de validate ne renvoie rien si une valeur brute est incorrecte et il n'y a aucun sens à la gérer.
Autre exemple: l'étape alarm_detector ne renvoie rien si la valeur suspecte actuelle ne produit pas de nouveau cas d'alarme.
Détails d'implémentation
Commençons par les types de données et les fonctions liées à la logique d'application. Dans l'exemple décrit, les types de données suivants sont utilisés pour transmettre des informations d'une étape à une autre:
Une instance de raw_value va à la première étape de notre pipeline. Cette valeur raw_value contient des informations acquises à partir d'un capteur sous la forme d' raw_measure objet mesure raw_measure . Ensuite, raw_value est transformé en valid_raw_value . Puis valid_raw_value transformé en sensor_value avec la valeur réelle d'un capteur sous la forme de calulated_measure . Si une instance de sensor_value contient une valeur suspecte, alors une instance de suspicious_value est produite. Et cette valeur suspicious_value peut être transformée en instance alarm_detected plus tard.
Ou, sous forme graphique:

Maintenant, nous pouvons jeter un oeil à la mise en œuvre de nos étapes de pipeline:
stage_result_t simplement des choses comme stage_result_t , make_result et make_empty , nous en discuterons dans la section suivante.
J'espère que le code de ces étapes est plutôt trivial. La seule partie qui nécessite des explications supplémentaires est la mise en œuvre de l'étape alarm_detector .
Dans cet exemple, une alarme n'est déclenchée que s'il y a au moins deux valeurs suspicious_values dans une fenêtre de temps de 25 ms. Nous devons donc nous rappeler l'heure de la précédente instance suspicious_value au stade alarm_detector . En effet, alarm_detector est implémenté en tant que foncteur avec état avec un opérateur d'appel de fonction.
Les étapes renvoient le type de SObjectizer au lieu de std :: optional
J'ai dit plus tôt que l'étape pouvait renvoyer une valeur facultative. Mais std::optional n'est pas utilisé dans le code, le type différent stage_result_t peut être vu dans l'implémentation des étapes.
C'est parce que certains spécificités de SObjectizer jouent ici leur rôle. Les valeurs retournées seront distribuées sous forme de messages entre les agents de SObjectizer (alias acteurs). Chaque message dans SObjectizer est envoyé en tant qu'objet alloué dynamiquement. Nous avons donc ici une sorte d '"optimisation": au lieu de renvoyer std::optional puis d'allouer un nouvel objet message, nous allouons simplement un objet message et lui retournons un pointeur intelligent.
En fait, stage_result_t n'est qu'un typedef pour l'analogue shared_ptr de SObjectizer:
template< typename M > using stage_result_t = message_holder_t< M >;
Et make_result et make_empty sont que des fonctions d'assistance pour construire stage_result_t avec ou sans valeur réelle à l'intérieur:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
Pour plus de simplicité, il est sûr de dire que l'étape de validation pourrait être exprimée de cette façon:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
Mais, en raison de la spécificité de SObjectizer, nous ne pouvons pas utiliser std::shared_ptr et so_5::message_holder_t type so_5::message_holder_t . Et nous cachons ces éléments spécifiques derrière les stage_result_t , make_result et make_empty .
séparation stage_handler_t et stage_builder_t
Un point important de la mise en œuvre du pipeline est la séparation des concepts de gestionnaire d' étape et de constructeur d'étape . Ceci est fait pour plus de simplicité. La présence de ces concepts m'a permis d'avoir deux étapes dans la définition du pipeline.
À la première étape, un utilisateur décrit les étapes du pipeline. En conséquence, je reçois une instance de stage_t qui contient toutes les étapes du pipeline à l'intérieur.
À la deuxième étape, un ensemble d'agents SObjectizer sous-jacents est créé. Ces agents reçoivent des messages avec les résultats des étapes précédentes et appellent des gestionnaires d'étape réels, puis envoient les résultats aux étapes suivantes.
Mais pour créer cet ensemble d'agents, chaque étape doit avoir un constructeur d'étape . Le générateur de scène peut être vu comme une fabrique qui crée un agent SObjectizer sous-jacent.
Nous avons donc la relation suivante: chaque étape du pipeline produit deux objets: le gestionnaire d'étape qui contient la logique liée à l' étape et le générateur d'étape qui crée un agent SObjectizer sous-jacent pour appeler le gestionnaire d'étape au moment approprié:

Le gestionnaire de scène est représenté de la manière suivante:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
Où handler_traits_t sont définis de la manière suivante:
Le générateur de scène est représenté par juste std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
Types d'assistance lambda_traits_t et callable_traits_t
Étant donné que les étapes peuvent être représentées par des fonctions ou des foncteurs libres (comme des instances de la classe alarm_detector ou des classes générées par le compilateur anonyme représentant des lambdas), nous avons besoin de quelques aides pour détecter les types d'argument de l'étape et la valeur de retour. J'ai utilisé le code suivant à cet effet:
J'espère que ce code sera tout à fait compréhensible pour les lecteurs ayant une bonne connaissance de C ++. Sinon, n'hésitez pas à me demander dans les commentaires, je serai heureux d'expliquer la logique derrière lambda_traits_t et callable_traits_t en détails.
fonctions stage (), broadcast () et opérateur | ()
Maintenant, nous pouvons regarder à l'intérieur des principales fonctions de construction de pipelines. Mais avant cela, il est nécessaire de jeter un œil à la définition d'une classe de modèle stage_t :
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
C'est une structure très simple qui contient juste stage_bulder_t instance stage_bulder_t . Les paramètres du modèle ne sont pas utilisés dans stage_t , alors pourquoi sont-ils présents ici?
Ils sont nécessaires pour la vérification à la compilation de la compatibilité des types entre les étapes du pipeline. Nous verrons cela bientôt.
Regardons la fonction de construction de pipeline la plus simple, la stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
Il reçoit un gestionnaire d'étape réel en tant que paramètre unique. Il peut s'agir d'un pointeur vers une fonction ou une fonction lambda ou un foncteur. Les types d'entrée et de sortie de la scène sont déduits automatiquement en raison de la «magie du modèle» derrière le modèle callable_traits_t .
Une instance de Stage Builder est créée à l'intérieur et cette instance est renvoyée dans un nouvel objet stage_t comme résultat de la fonction stage() . Un gestionnaire de scène réel est capturé par le constructeur de scènes lambda, il sera ensuite utilisé pour la construction d'un agent SObjectizer sous-jacent (nous en parlerons dans la section suivante).
La prochaine fonction à examiner est l' operator|() qui concatène deux étapes ensemble et renvoie une nouvelle étape:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
La façon la plus simple d'expliquer la logique de l' operator|() est d'essayer de dessiner une image. Supposons que nous avons l'expression:
stage(A) | stage(B) | stage(C) | stage(B)
Cette expression sera transformée de cette façon:

Là, nous pouvons également voir comment fonctionne la vérification de type à la compilation: la définition de l' operator|() nécessite que le type de sortie du premier étage soit l'entrée du deuxième étage. Si ce n'est pas le cas, le code ne sera pas compilé.
Et maintenant, nous pouvons jeter un œil à la fonction de construction de pipeline la plus complexe, la broadcast() . La fonction elle-même est assez simple:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
La principale différence entre une scène ordinaire et une scène de diffusion est que la scène de diffusion doit contenir un vecteur de constructeurs de scènes subsidiaires. Nous devons donc créer ce vecteur et le transmettre au générateur de scène principal de la diffusion. Pour cette raison, nous pouvons voir un appel à collect_sink_builders dans la liste de capture d'un lambda à l'intérieur de la fonction broadcast() :
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
Si nous examinons collect_sink_builder nous verrons le code suivant:
La vérification de type à la compilation fonctionne ici aussi: c'est parce qu'un appel à move_sink_builder_to explicitement paramétré par le type 'In'. Cela signifie qu'un appel sous la forme collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) entraînera une erreur de compilation car le compilateur interdit un appel move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) .
Je peux également noter que parce que le nombre de pipelines subsidiaires pour broadcast() est connu au moment de la compilation, nous pouvons utiliser std::array au lieu de std::vector et pouvons éviter certaines allocations de mémoire. Mais std::vector est utilisé ici juste pour plus de simplicité.
Relation entre les étapes et les agents / mbox de SObjectizer
L'idée derrière la mise en œuvre du pipeline est la création d'un agent distinct pour chaque étape du pipeline. Un agent reçoit un message entrant, le transmet au gestionnaire d'étape correspondant, analyse le résultat et, si le résultat n'est pas vide, envoie le résultat sous forme de message entrant à l'étape suivante. Il peut être illustré par le diagramme de séquence suivant:

Certaines choses liées à SObjectizer doivent être discutées, au moins brièvement. Si vous n'êtes pas intéressé par ces détails, vous pouvez ignorer les sections ci-dessous et aller directement à la conclusion.
Coop est un groupe d'agents pour travailler ensemble
Les agents sont introduits dans SObjectizer non pas individuellement mais dans des groupes nommés coops. Une coopérative est un groupe d'agents qui devraient travailler ensemble et il est inutile de continuer le travail si l'un des agents du groupe est absent.
Ainsi, l'introduction d'agents dans SObjectizer ressemble à la création d'une instance coop, remplissant cette instance avec les agents appropriés, puis enregistrant la coopérative dans SObjectizer.
Pour cette raison, le premier argument pour un constructeur de scène est une référence à une nouvelle coopérative. Cette coopérative est créée dans la fonction make_pipeline() (discutée ci-dessous), puis elle est remplie par les constructeurs d'étapes puis enregistrée (à nouveau dans la fonction make_pipeline() ).
Boîtes de messages
SObjectizer implémente plusieurs modèles liés à la concurrence. Le modèle d'acteur n'est que l'un d'entre eux. De ce fait, SObjectizer peut différer considérablement des autres frameworks d'acteurs. L'une des différences est le schéma d'adressage des messages.
Les messages dans SObjectizer ne s'adressent pas aux acteurs, mais aux boîtes de message (mbox). Les acteurs doivent s'abonner aux messages d'une mbox. Si un acteur était abonné à un type de message particulier à partir d'une mbox, il recevrait des messages de ce type:
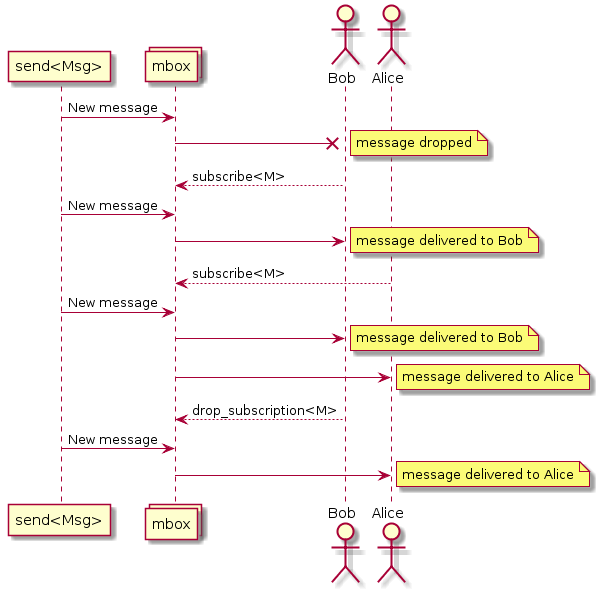
Ce fait est crucial car il est nécessaire d'envoyer des messages d'une étape à l'autre. Cela signifie que chaque étape doit avoir sa mbox et que la mbox doit être connue pour l'étape précédente.
Chaque acteur (alias agent) dans SObjectizer a la mbox directe . Cette mbox n'est associée qu'à l'agent propriétaire et ne peut être utilisée par aucun autre agent. Les mbox directs des agents créés pour les étapes seront utilisés pour l'interaction des étapes.
La fonctionnalité spécifique de ce SObjectizer dicte certains détails d'implémentation du pipeline.
Le premier est le fait que le constructeur de scènes dispose du prototype suivant:
mbox_t builder(coop_t &, mbox_t);
Cela signifie que le générateur d'étape reçoit une mbox de l'étape suivante et doit créer un nouvel agent qui enverra les résultats de l'étape à cette mbox. Une mbox du nouvel agent doit être retournée par le générateur de scène . Cette mbox sera utilisée pour la création d'un agent pour l'étape précédente.
Le second est le fait que les agents des étapes sont créés dans l'ordre de réserve. Cela signifie que si nous avons un pipeline:
stage(A) | stage(B) | stage(C)
Un agent pour l'étape C sera d'abord créé, puis sa mbox sera utilisée pour la création d'un agent pour l'étape B, puis la mbox de l'agent de l'étape B sera utilisée pour la création d'un agent pour l'étape A.
Il convient également de noter que l' operator|() ne crée pas d'agents:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
L' operator|() crée un générateur qui n'appelle que d'autres générateurs mais n'introduit pas d'agents supplémentaires. Donc pour le cas:
stage(A) | stage(B)
seuls deux agents seront créés (pour A-stage et B-stage) puis ils seront liés ensemble dans le générateur de scène créé par l' operator|() .
Il n'y a pas d'agent pour la mise en œuvre de broadcast()
Une façon évidente de mettre en œuvre une étape de diffusion consiste à créer un agent spécial qui recevra un message entrant, puis à renvoyer ce message à une liste de mbox de destination. Cette méthode a été utilisée dans la première implémentation du pipeline DSL décrit.
Mais notre projet compagnon, so5extra , a maintenant une variante spéciale de mbox: en diffuser une. Cette mbox fait exactement ce qui est requis ici: elle prend un nouveau message et le livre à un ensemble de mbox de destination.
Pour cette raison, il n'est pas nécessaire de créer un agent de diffusion distinct, nous pouvons simplement utiliser la diffusion mbox de so5extra:
Implémentation de stage-agent
Maintenant, nous pouvons jeter un oeil à la mise en œuvre de l'agent de scène:
C'est plutôt trivial si vous comprenez les bases du SObjectizer. Sinon ce sera assez difficile à expliquer en quelques mots (alors n'hésitez pas à poser des questions dans les commentaires).
L'implémentation principale de l'agent a_stage_point_t crée un abonnement à un message de type In. Lorsqu'un message de ce type arrive, le gestionnaire d'étape est appelé. Si le gestionnaire d'étape renvoie un résultat réel, le résultat est envoyé à l'étape suivante (si cette étape existe).
Il existe également une version de a_stage_point_t pour le cas où l'étape correspondante est l'étape terminale et il ne peut pas y avoir l'étape suivante.
L'implémentation de a_stage_point_t peut sembler un peu compliqué mais croyez-moi, c'est l'un des agents les plus simples que j'ai écrits.
Fonction make_pipeline ()
Il est temps de discuter de la dernière fonction de construction de pipeline, la make_pipeline() :
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
Il n'y a pas de magie ni de surprise ici. Nous avons juste besoin de créer une nouvelle coopérative pour les agents sous-jacents du pipeline, de remplir cette coopérative avec des agents en appelant un constructeur de niveau supérieur, puis d'enregistrer cette coopérative dans SObjectizer. C'est tout.
Le résultat de make_pipeline() est la mbox de l'étape la plus à gauche (la première) du pipeline. Cette mbox doit être utilisée pour envoyer des messages au pipeline.
La simulation et ses expériences
Nous avons donc maintenant des types de données et des fonctions pour notre logique d'application et les outils pour enchaîner ces fonctions dans un pipeline de traitement des données. Faisons-le et voyons un résultat:
int main() {
Si nous exécutons cet exemple, nous verrons la sortie suivante:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
Ça marche.
Mais il semble que les étapes de notre pipeline fonctionnent séquentiellement, l'une après l'autre, n'est-ce pas?
Oui, ça l'est. En effet, tous les agents de pipeline sont liés au répartiteur par défaut de SObjectizer. Et ce répartiteur utilise un seul thread de travail pour le traitement des messages de tous les agents.
Mais cela peut être facilement changé. make_pipeline() simplement un argument supplémentaire à l' make_pipeline() de make_pipeline() :
Cela crée un nouveau pool de threads et lie tous les agents de pipeline à ce pool. Chaque agent sera servi par la piscine indépendamment des autres agents.
Si nous exécutons l'exemple modifié, nous pouvons voir quelque chose comme ça:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
Nous pouvons donc voir que les différentes étapes du pipeline fonctionnent en parallèle.
Mais est-il possible d'aller plus loin et d'avoir la possibilité de lier des étapes à différents répartiteurs?
Oui, c'est possible, mais nous devons implémenter une autre surcharge pour la fonction stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
Cette version de stage() accepte non seulement un gestionnaire de stage mais aussi un classeur de répartiteur. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS. The source code for that example can be found in that repository .