Quiconque travaille avec Redux se heurtera tôt ou tard au problème des actions asynchrones. Mais une application moderne ne peut être développée sans eux. Ce sont des requêtes http vers le backend, et toutes sortes de temporisations / retards. Les créateurs Redux eux-mêmes parlent sans ambiguïté - par défaut, seul le flux de données synchrone est pris en charge, toutes les actions asynchrones doivent être placées dans le middleware.
Bien sûr, cela est trop verbeux et peu pratique, il est donc difficile de trouver un développeur qui utilise uniquement le middleware «natif». Les bibliothèques et les frameworks tels que Thunk, Saga et similaires viennent toujours à la rescousse.
Pour la plupart des tâches, elles suffisent. Mais que se passe-t-il si une logique un peu plus complexe est nécessaire que d'envoyer une demande ou de créer un temporisateur? Voici un petit exemple:
async dispatch => { setTimeout(() => { try { await Promise .all([fetchOne, fetchTwo]) .then(([respOne, respTwo]) => { dispatch({ type: 'SUCCESS', respOne, respTwo }); }); } catch (error) { dispatch({ type: 'FAILED', error }); } }, 2000); }
Il est même pénible de regarder un tel code, mais il est tout simplement impossible de le maintenir et de le développer. Que faire lorsqu'un traitement d'erreur plus sophistiqué est nécessaire? Et si vous avez besoin d'une demande répétée? Et si je veux réutiliser cette fonctionnalité?
Je m'appelle Dmitry Samokhvalov, et dans ce post, je vais vous dire quel est le concept d'Observable et comment le mettre en pratique en collaboration avec Redux, et aussi comparer tout cela avec les capacités de Redux-Saga.
En règle générale, dans de tels cas, prenez redux-saga. OK, nous réécrivons les sagas:
try { yield call(delay, 2000); const [respOne, respTwo] = yield [ call(fetchOne), call(fetchTwo) ]; yield put({ type: 'SUCCESS', respOne, respTwo }); } catch (error) { yield put({ type: 'FAILED', error }); }
Il est devenu sensiblement meilleur - le code est presque linéaire, semble et lit mieux. Mais l'expansion et la réutilisation sont toujours difficiles, car la saga est tout aussi impérative que le thunk.
Il existe une autre approche. C'est exactement l'approche, et pas seulement une autre bibliothèque pour écrire du code asynchrone. On l'appelle Rx (ce sont aussi des observables, des flux réactifs, etc.). Nous allons l'utiliser et réécrire l'exemple sur Observable:
action$ .delay(2000) .switchMap(() => Observable.merge(fetchOne, fetchTwo) .map(([respOne, respTwo]) => ({ type: 'SUCCESS', respOne, respTwo })) .catch(error => ({ type: 'FAILED', error }))
Le code est non seulement devenu plat et a diminué de volume, mais le principe même de la description des actions asynchrones a changé. Maintenant, nous ne travaillons pas directement avec les requêtes, mais effectuons des opérations sur des objets spéciaux appelés Observable.
Il est pratique de représenter Observable comme une fonction qui donne un flux (séquence) de valeurs. Observable a trois états principaux - suivant («donner la valeur suivante»), erreur («une erreur s'est produite») et complet («les valeurs sont terminées, il n'y a plus rien à donner»). À cet égard, c'est un peu comme Promise, mais diffère en ce qu'il est possible d'itérer sur ces valeurs (et c'est l'une des superpuissances observables). Vous pouvez envelopper n'importe quoi dans Observable - timeouts, requêtes http, événements DOM, juste des objets js.
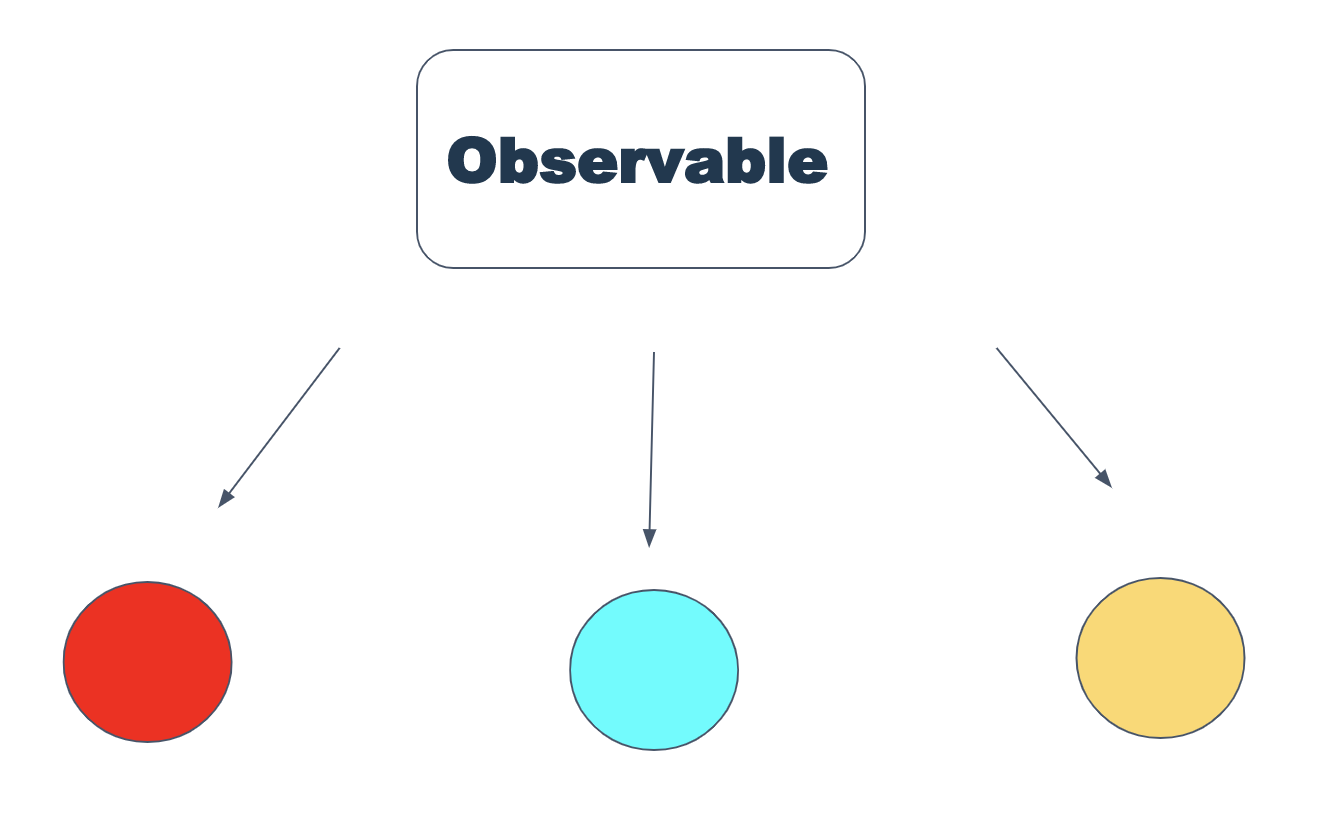
Les deuxièmes superpuissances observables sont les opérateurs. Un opérateur est une fonction qui accepte et renvoie un observable, mais effectue une action sur le flux de valeurs. L'analogie la plus proche est la carte et le filtre de javascript (en passant, ces opérateurs sont en Rx).
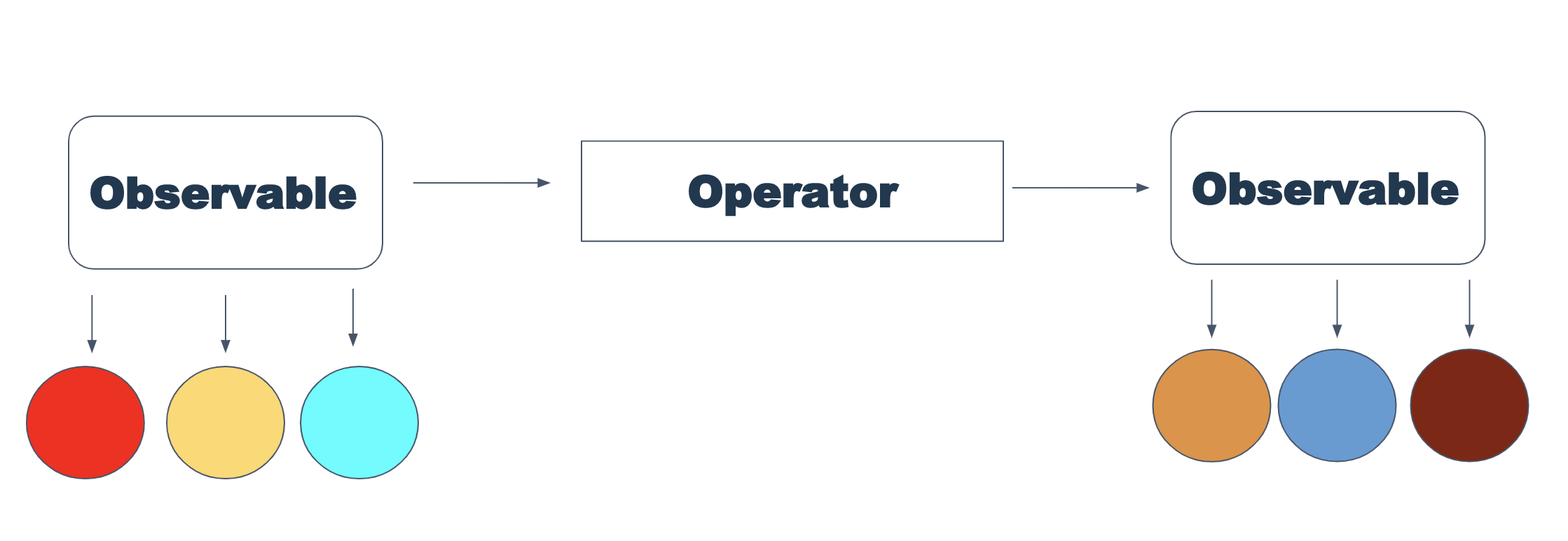
Les plus utiles pour moi personnellement étaient les opérateurs zip, forkJoin et flatMap. En utilisant leur exemple, il est plus facile d'expliquer le travail des opérateurs.
L'opérateur zip fonctionne très simplement - il prend quelques Observable (pas plus de 9) et retourne dans un tableau les valeurs qu'ils émettent.
const first = fromEvent("mousedown"); const second = fromEvent("mouseup"); zip(first, second) .subscribe(e => console.log(`${e[0].x} ${e[1].x}`));
En général, le travail de zip peut être représenté par le schéma:
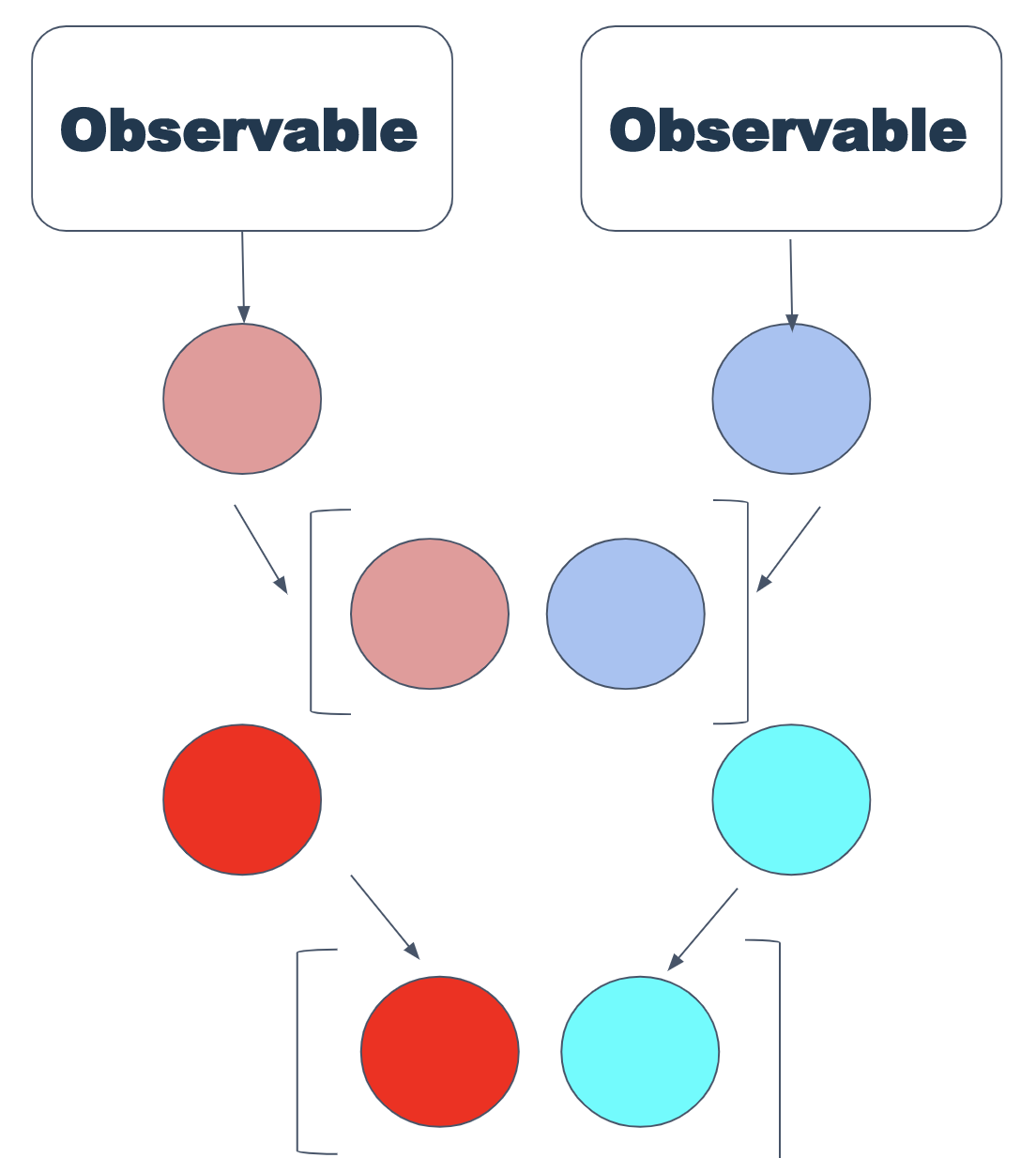
Zip est utilisé si vous avez plusieurs observables et que vous devez en recevoir systématiquement des valeurs (malgré le fait qu'elles peuvent être émises à différents intervalles, de manière synchrone ou non). Il est très utile lorsque vous travaillez avec des événements DOM.
L'instruction forkJoin est similaire à zip à une exception près - elle ne renvoie que les dernières valeurs de chaque observable.
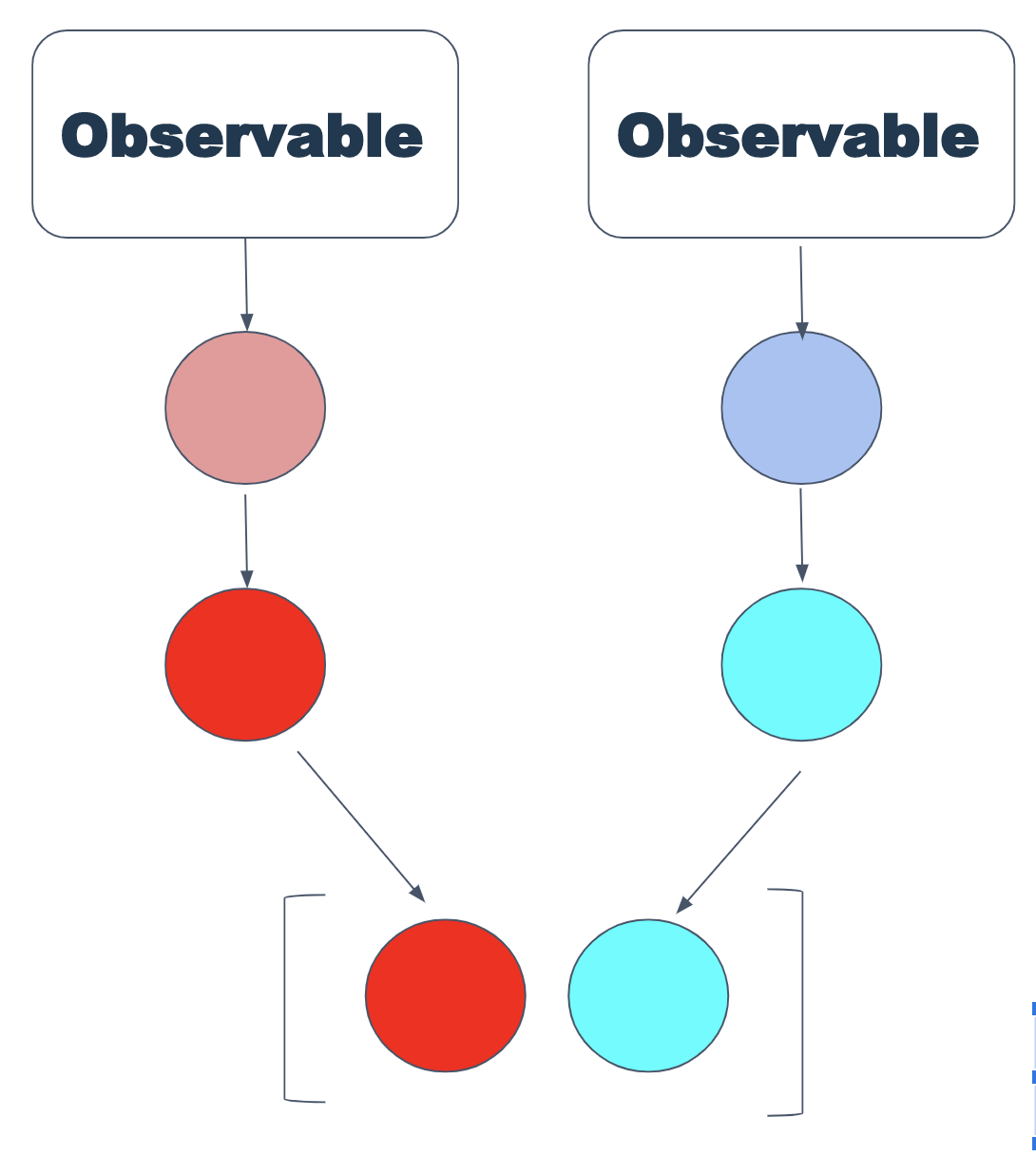
En conséquence, il est raisonnable de l'utiliser lorsque seules des valeurs finies du flux sont nécessaires.
L'opérateur flatMap est un peu plus compliqué. Il prend un observable en entrée et renvoie un nouvel observable, et mappe les valeurs de celui-ci au nouvel observable, en utilisant soit une fonction de sélection, soit un autre observable. Cela peut sembler déroutant, mais le diagramme est assez simple:
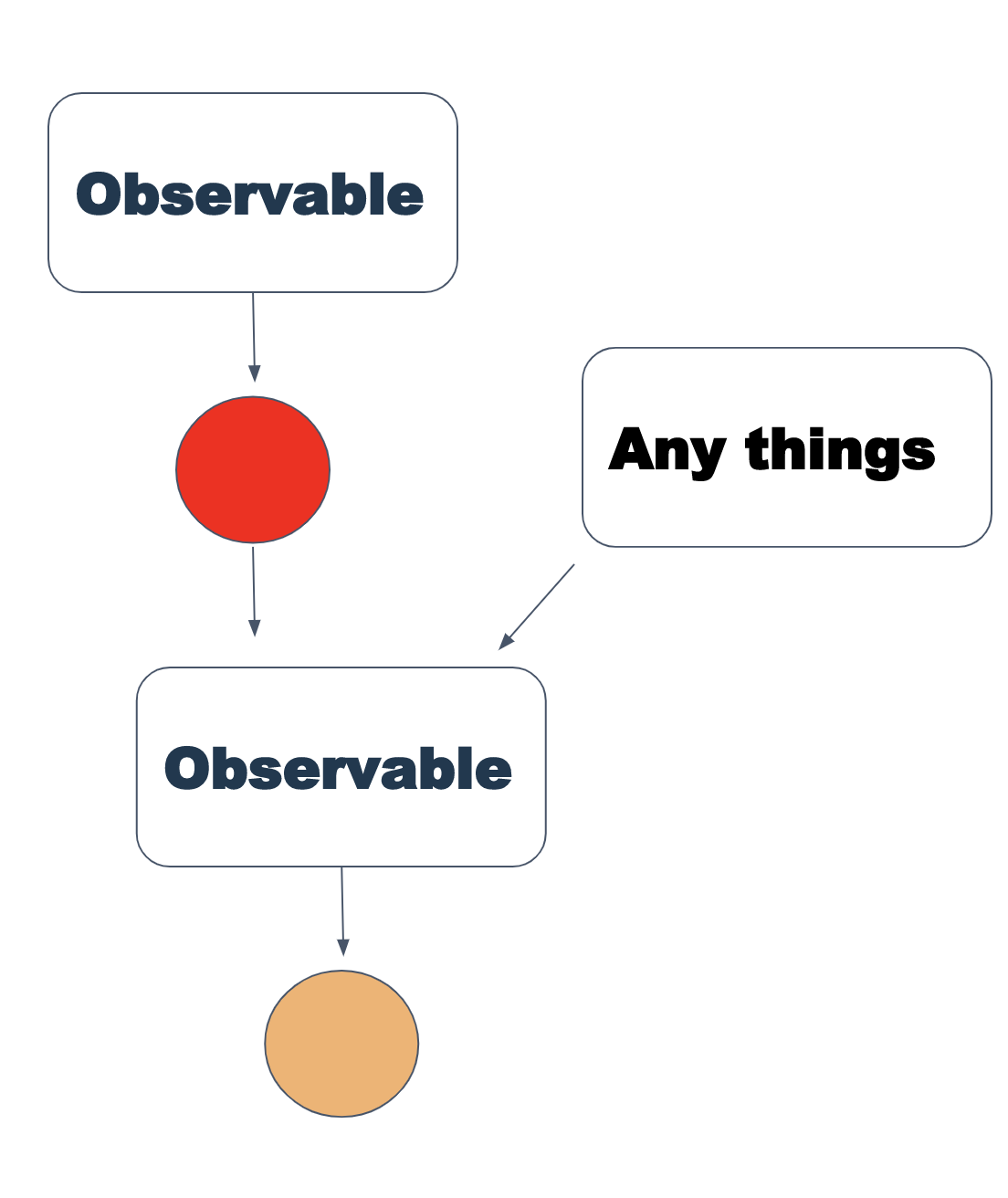
Encore plus clair dans le code:
const observable = of("Hello"); const promise = value => new Promise(resolve => resolve(`${value} World`); observable .flatMap(value => promise(value)) .subscribe(result => console.log(result));
Le plus souvent, flatMap est utilisé dans les demandes d'arrière-plan, avec switchMap et concatMap.
Comment puis-je utiliser Rx dans Redux? Il existe une merveilleuse bibliothèque redux-observable pour cela. Son architecture ressemble à ceci:

Tous les opérateurs et actions observables sur ceux-ci se présentent sous la forme d'un middleware spécial appelé epic. Chaque épopée prend une action en entrée, l'enveloppe dans un observable et doit retourner une action, également en observable. Vous ne pouvez pas retourner une action régulière, cela crée une boucle sans fin. Écrivons une petite épopée qui fait une demande à l'API.
const fetchEpic = action$ => action$ .ofType('FETCH_INFO') .map(() => ({ type: 'FETCH_START' })) .flatMap(() => Observable .from(apiRequest) .map(data => ({ type: 'FETCH_SUCCESS', data })) .catch(error => ({ type: 'FETCH_ERROR', error })) )
Il est impossible de le faire sans comparer redux-observable et redux-saga. Il semble à beaucoup qu'ils sont proches en termes de fonctionnalités et de capacités, mais ce n'est pas du tout le cas. Les sagas sont un outil absolument impératif, essentiellement un ensemble de méthodes pour travailler avec les effets secondaires. Observable est un style fondamentalement différent d'écriture de code asynchrone, si vous voulez, une philosophie différente.
J'ai écrit plusieurs exemples pour illustrer les possibilités et l'approche de résolution des problèmes.
Supposons que nous devons implémenter un temporisateur qui s'arrêtera par action. Voici à quoi cela ressemble dans les sagas:
while(true) { const timer = yield race({ stopped: take('STOP'), tick: call(wait, 1000) }) if (!timer.stopped) { yield put(actions.tick()) } else { break } }
Utilisez maintenant Rx:
interval(1000) .takeUntil(action$.ofType('STOP'))
Supposons qu'il existe une tâche pour implémenter une demande avec annulation dans les sagas:
function* fetchSaga() { yield call(fetchUser); } while (yield take('FETCH')) { const fetchSaga = yield fork(fetchSaga); yield take('FETCH_CANCEL'); yield cancel(fetchSaga); }
Tout est plus simple sur Rx:
switchMap(() => fetchUser()) .takeUntil(action$.ofType('FETCH_CANCEL'))
Enfin, mon préféré. Mettre en œuvre une demande d'API, en cas d'échec ne pas faire plus de 5 demandes répétées avec un délai de 2 secondes. Voici ce que nous avons dans les sagas:
for (let i = 0; i < 5; i++) { try { const apiResponse = yield call(apiRequest); return apiResponse; } catch (err) { if(i < 4) { yield delay(2000); } } } throw new Error(); }
Que se passe-t-il sur Rx:
.retryWhen(errors => errors .delay(1000) .take(5))
Si vous résumez les avantages et les inconvénients de la saga, vous obtenez l'image suivante:

Les sagas sont faciles à apprendre et très populaires, donc dans la communauté, vous pouvez trouver des recettes pour presque toutes les occasions. Malheureusement, le style impératif empêche l'utilisation des sagas de manière vraiment flexible.
Rx a une situation complètement différente:

Il peut sembler que Rx est un marteau magique et une balle d'argent. Ce n'est malheureusement pas le cas. Le seuil pour entrer Rx est beaucoup plus élevé, il est donc plus difficile d'initier une nouvelle personne à un projet qui utilise activement Rx.
De plus, lorsque vous travaillez avec Observable, il est particulièrement important d'être prudent et de toujours bien comprendre ce qui se passe. Sinon, vous risquez de tomber sur des erreurs non évidentes ou un comportement non défini.
action$ .ofType('DELETE') .switchMap(() => Observable .fromPromise(deleteRequest) .map(() => ({ type: 'DELETE_SUCCESS'})))
Une fois que j'ai écrit une épopée qui a fait un travail assez simple - avec chaque action de type 'SUPPRIMER', une méthode API a été appelée pour supprimer l'élément. Cependant, il y a eu des problèmes lors des tests. Le testeur s'est plaint d'un comportement étrange - parfois, lorsque vous avez cliqué sur le bouton Supprimer, rien ne s'est produit. Il s'est avéré que l'opérateur switchMap prend en charge l'exécution d'un seul observable à la fois, une sorte de protection contre les conditions de concurrence.
En conséquence, je vais donner quelques recommandations que je suis et exhorter tous ceux qui commencent à travailler avec Rx à suivre:
- Soyez prudent.
- Consultez la documentation.
- Vérifiez dans le bac à sable.
- Écrivez des tests.
- Ne tirez pas sur les moineaux avec le canon.