Lorsque vous commencez votre carrière en programmation, creuser dans le code source des bibliothèques et des frameworks ouverts peut sembler un peu effrayant. Dans cet article, Karl Mungazi partage son expérience sur la façon dont il a surmonté sa peur et a commencé à utiliser le code source pour acquérir des connaissances et développer des compétences. Il utilise également Redux pour montrer comment il «analyse» la bibliothèque.Vous souvenez-vous de votre première immersion dans le code d'une bibliothèque ou d'un framework que vous utilisez souvent? Dans ma vie, ce moment est arrivé à mon premier emploi en tant que développeur front-end il y a trois ans.
Nous venons de réécrire un cadre propriétaire obsolète qui a été utilisé pour créer des cours de formation interactifs. Au tout début du travail de réécriture, nous avons examiné quelques solutions clés en main, notamment Mithril, Inferno, Angular, React, Aurelia, Vue et Polymer. Comme j'étais encore un jeune Padawan (qui venait de passer du journalisme au développement web), j'avais terriblement peur de la complexité de chaque framework et du manque de compréhension de leur fonctionnement.
La compréhension a commencé à venir lorsque j'ai commencé à explorer attentivement le cadre Mithril. Depuis lors, ma connaissance de JavaScript - et de la programmation en général - s'est considérablement renforcée grâce aux heures passées à fouiller dans les internes de la bibliothèque, que j'utilisais quotidiennement au travail et dans mes propres projets. Dans cet article, je vais vous expliquer comment utiliser votre bibliothèque préférée comme tutoriel
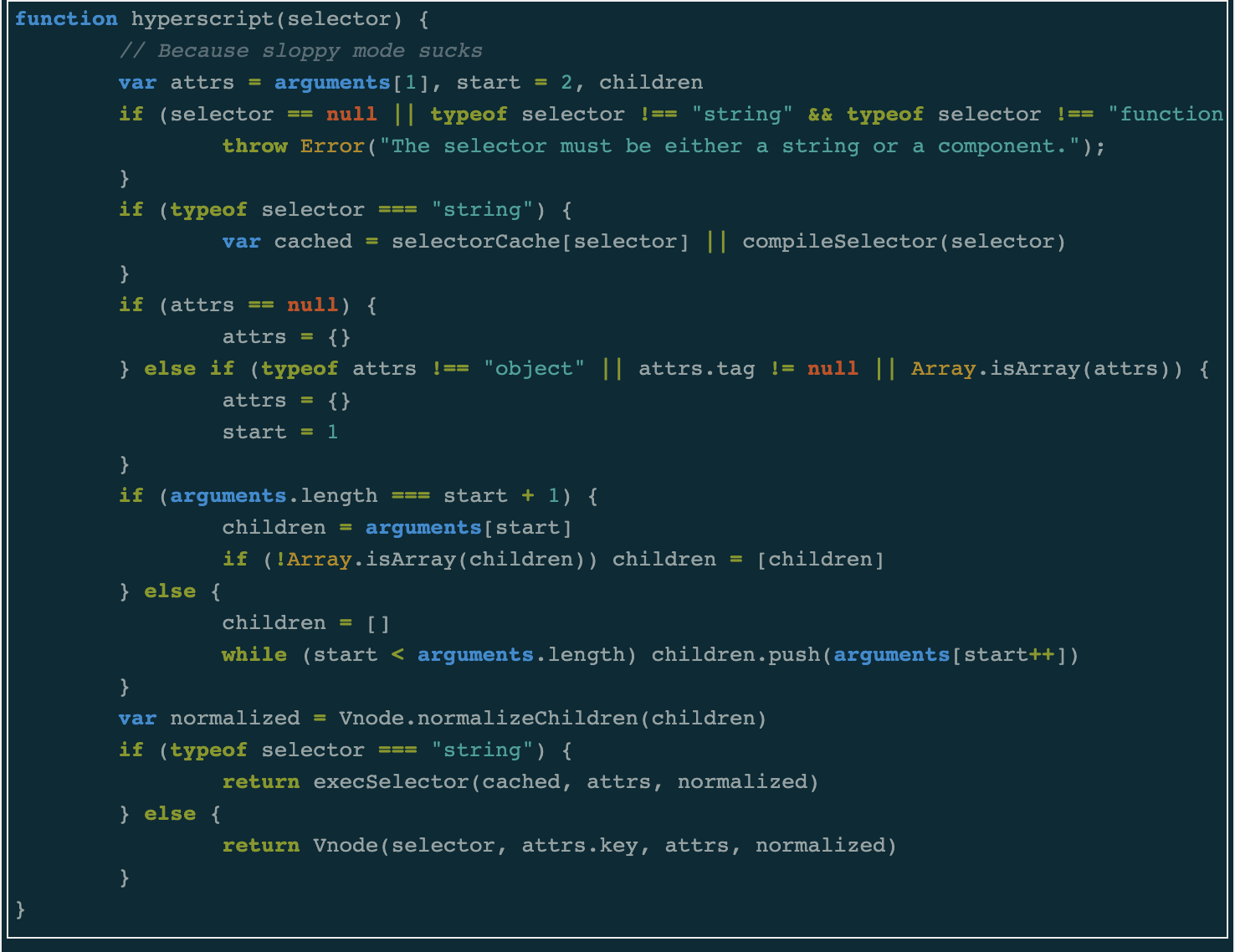 J'ai commencé à lire le code source avec la fonction hyperscript de Mithril
J'ai commencé à lire le code source avec la fonction hyperscript de MithrilAvantages de l'analyse du code source
L'un des principaux avantages de l'analyse du code source est que vous pouvez en apprendre beaucoup. Quand j'ai commencé à analyser le code Mithril, j'avais une très mauvaise idée de ce qu'était le DOM virtuel. Quand j'ai fini, je savais déjà que le DOM virtuel est une technique impliquant la création d'un arbre d'objets décrivant l'interface utilisateur. Cet arbre peut ensuite être converti en éléments DOM à l'aide d'une API DOM telle que document.createElement. Pour mettre à jour, une nouvelle arborescence est créée qui décrit l'état futur de l'interface puis comparée à la version précédente de cette arborescence.
J'ai lu à ce sujet dans de nombreux articles et manuels, mais le plus instructif a été d'observer tout cela en travaillant sur notre application. J'ai également appris à poser les bonnes questions lors de la comparaison des cadres. Au lieu de comparer les notations, par exemple, vous pouvez poser la question «Comment le fonctionnement de ce cadre avec les changements affecte-t-il les performances et la commodité de l'utilisateur final?»
Un autre avantage est le développement d'une compréhension d'une bonne architecture d'application. Malgré le fait que la plupart des projets open-source sont généralement plus ou moins similaires dans leur structure à leurs référentiels, ils ont encore des différences. La structure de Mithril est très plate et si vous connaissez bien son API, vous pouvez faire des hypothèses assez réalistes sur le code dans les dossiers de rendu, de routeur et de demande. La structure de React, en revanche, reflète sa nouvelle architecture. Les développeurs ont séparé le module responsable de la mise à jour de l'interface utilisateur (react-reconciler) du module responsable du rendu des éléments DOM (react-dom).
L'un des avantages de cette séparation pour les développeurs est qu'ils peuvent écrire leurs
propres rendus à l' aide de crochets dans le react-reconciler. Parcel, le générateur de modules que j'ai récemment étudié, possède également un dossier de packages, tout comme React. Le module clé s'appelle parcel-bundler, il contient du code qui est responsable de la création des assemblages, du fonctionnement du serveur de mise à jour de module (serveur de module à chaud) et de l'outil de ligne de commande.
 L'analyse du code source vous amène bientôt à lire les spécifications JavaScript.
L'analyse du code source vous amène bientôt à lire les spécifications JavaScript.Un autre avantage, qui a été une grande surprise pour moi, est qu'il vous facilite la lecture des spécifications JavaScript officielles. La première fois que je me suis tourné vers elle lorsque j'essayais de comprendre quelle était la différence entre lancer une erreur et lancer une nouvelle erreur (spoiler -
rien ). J'ai posé cette question parce que Mithril a utilisé throw error dans l'implémentation de la fonction m et je me suis demandé pourquoi c'était mieux que de lancer une nouvelle erreur. Ensuite, j'ai aussi appris que les opérateurs && et ||
ne renvoie pas nécessairement des valeurs booléennes , j'ai trouvé les
règles par lesquelles l'opérateur de comparaison non stricte == «résout» les valeurs et la
raison pour laquelle Object.prototype.toString.call ({}) renvoie «[Object Object]».
Comment analyser le code source
Il existe de nombreuses façons d'analyser le code source. Le moyen le plus simple me semble le suivant: sélectionnez une méthode dans votre bibliothèque et décrivez ce qui se passe lorsque vous l'appelez. Il ne vaut pas la peine de décrire chaque étape, il vous suffit d'essayer de comprendre ses principes généraux et sa structure.
Récemment, j'ai analysé ReactDOM.render de cette façon et j'ai beaucoup appris sur React Fiber et certaines des difficultés de sa mise en œuvre. Heureusement, React est très populaire et la présence d'un grand nombre d'articles sur le même sujet par d'autres développeurs a accéléré le processus.
Cette plongée dans le code m'a également présenté le concept de
planification coopérative , la méthode
window.requestIdleCallback et un
exemple en direct
d'une liste liée (React traite les mises à jour en les envoyant à la file d'attente, qui est une liste de mises à jour prioritaire liée). Dans le processus, il serait bien de créer une application simple en utilisant la bibliothèque. Cela facilite le débogage car vous n'avez pas à gérer la trace de pile des autres bibliothèques.
Si je ne fais pas d'examen détaillé, j'ouvrirai le dossier node_modules dans le projet sur lequel je travaille ou jetterai un œil à GitHub. Je le fais toujours lorsque je rencontre un bug ou une fonctionnalité intéressante. Lors de la lecture du code sur GitHub, assurez-vous qu'il s'agit de la dernière version. Le code de la dernière version est visible en cliquant sur le bouton de changement de branche et en sélectionnant "tags". Les changements dans les bibliothèques et les frameworks sont en cours, il est donc peu probable que vous souhaitiez analyser quelque chose qui pourrait ne pas être dans la prochaine version.
Une version plus superficielle de l'apprentissage du code source est ce que j'appelle un «aperçu rapide». D'une certaine manière, j'ai installé express.js, ouvert le dossier node_modules et parcouru les dépendances. Si README ne m'a pas donné d'explication satisfaisante, j'ai lu la source. Cela m'a conduit à des découvertes intéressantes:
- Express utilise deux modules pour fusionner des objets, et le fonctionnement de ces modules est très différent. merge-descriptors n'ajoute que les propriétés trouvées dans l'objet source, et ajoute également des propriétés non énumérables, tandis que utils-merge passe en revue les propriétés énumérées de l'objet et de sa chaîne de prototypes entière. merge-descriptors utilise Object.getOwnPropertyNames () et Object.getOwnPropertyDescriptor (), et utils-merge utilise for..in;
- Le module setprototypeof fournit une option multiplateforme pour spécifier le prototype de l'objet créé (instancié);
- escape-html est un module d'échappement de chaîne de 78 lignes, après quoi le contenu peut être inséré en HTML;
Bien que ces découvertes ne soient probablement pas utiles tout de suite, une compréhension générale des dépendances de votre bibliothèque ou de votre framework est très utile.
Les outils de navigateur de débogage sont vos meilleurs amis lors du débogage de code sur le frontend. Entre autres choses, ils vous permettent d'arrêter le programme à tout moment et de vérifier en même temps son état, de sauter la fonction, ou d'y entrer ou de le quitter. En code minifié, ce n'est pas possible - c'est pourquoi je décompresse ce code et le mets dans le fichier correspondant dans le dossier node_modules.
 Utilisez le débogueur comme application utile. Faites une hypothèse, puis testez-la.
Utilisez le débogueur comme application utile. Faites une hypothèse, puis testez-la.Étude de cas: fonction de connexion dans Redux
React-Redux est une bibliothèque pour gérer l'état des applications React. Lorsque je travaille avec des bibliothèques populaires comme celle-ci, je commence par rechercher des articles sur leur utilisation. En préparant cet exemple, j'ai passé en revue cet
article . C'est un autre avantage de l'apprentissage du code source - il vous amène à des articles informatifs comme celui-ci qui améliorent votre réflexion et votre compréhension.
Connect est une fonction react-redux qui relie le composant react et le magasin redux d'une application. Comment? Selon la
documentation, elle fait ce qui suit:
"... retourne une nouvelle classe de composants liés, qui est un wrapper du composant qui lui est transmis."
Après avoir lu ceci, je pose les questions suivantes:
- Est-ce que je connais des modèles ou des concepts où les fonctions renvoient des paramètres d'entrée avec des fonctionnalités supplémentaires?
- Si oui, comment dois-je l'utiliser sur la base de la description de la documentation?
Habituellement, l'étape suivante consiste à créer une application primitive à l'aide de la fonction de connexion. Néanmoins, dans cette situation, j'ai utilisé une nouvelle application sur React, sur laquelle nous avons travaillé, car je voulais comprendre connect dans le contexte d'une application qui arriverait très probablement bientôt en production.
Le composant sur lequel je me suis concentré ressemble à ceci:
class MarketContainer extends Component {
Il s'agit d'un composant de conteneur qui sert de wrapper pour les quatre plus petits composants associés. L'une des premières choses que vous trouvez dans le
fichier qui connecte les exportations est le commentaire «connect est la façade de connectAdvanced». Déjà à ce stade, nous pouvons apprendre quelque chose: nous avons l'occasion d'observer le motif de la «façade» en action. À la fin du fichier, nous voyons connect exporter un appel à la fonction createConnect. Ses paramètres sont un ensemble de valeurs par défaut qui sont déstructurées comme suit:
export function createConnect({ connectHOC = connectAdvanced, mapStateToPropsFactories = defaultMapStateToPropsFactories, mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories, mergePropsFactories = defaultMergePropsFactories, selectorFactory = defaultSelectorFactory } = {})
Et nous avons encore un moment instructif: l'exportation de la fonction appelée et la déstructuration des arguments de la fonction par défaut. La restructuration est instructive pour nous car le code pourrait être écrit comme ceci:
export function createConnect({ connectHOC = connectAdvanced, mapStateToPropsFactories = defaultMapStateToPropsFactories, mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories, mergePropsFactories = defaultMergePropsFactories, selectorFactory = defaultSelectorFactory })
En conséquence, nous obtiendrions une erreur - Uncaught TypeError: Impossible de détruire la propriété 'connectHOC' de 'undefined' ou 'null'. Cela se produirait car la fonction n'a pas de valeur d'argument par défaut.
Remarque: pour mieux comprendre la restructuration des arguments, vous pouvez lire l'article de David Walsh . Certains points peuvent sembler anodins, selon votre connaissance de la langue - vous pouvez alors vous concentrer sur les points que vous ne connaissez pas.La fonction createConnect elle-même ne fait rien. Il renvoie simplement la fonction de connexion que j'ai utilisée ici:
export default connect(null, mapDispatchToProps)(MarketContainer)
Il prend quatre arguments facultatifs et les trois premiers passent par la fonction de
correspondance , ce qui permet de déterminer leur comportement en fonction des arguments passés, ainsi que de leur type. Il s'avère que puisque le deuxième argument passé pour correspondre est l'une des trois fonctions importées dans connect, je dois choisir où aller ensuite.
Il y a aussi quelque chose à apprendre de la
fonction proxy utilisée pour encapsuler le premier argument dans connect, si ces arguments sont des fonctions; à partir de l'utilitaire
isPlainObject utilisé pour vérifier des objets simples ou du module d'
avertissement , qui montre comment vous pouvez créer un débogueur qui rompra toutes les erreurs. Après la fonction match, nous passons à connectHOC, la fonction qui prend notre composant react et l'associe à redux. Il existe un autre appel de fonction qui renvoie
wrapWithConnect - une fonction qui gère en fait la liaison du composant au référentiel.
En regardant l'implémentation connectHOC, je peux deviner pourquoi les détails de l'implémentation connect devraient être cachés. C'est essentiellement le cœur de react-redux et contient une logique qui ne devrait pas être accessible via connect. Même si nous nous attardons sur cela, puis plus tard, si nous devons creuser plus profondément, nous aurons déjà le matériel source avec une explication détaillée du code.
Résumer
L'apprentissage du code source est très compliqué au début. Mais, comme tout le reste, cela devient plus facile avec le temps. Sa tâche n'est pas de tout comprendre, mais de faire ressortir quelque chose d'utile pour lui - une compréhension commune et de nouvelles connaissances. Il est très important d'être prudent tout au long du processus et de se plonger dans les détails.
Par exemple, j'ai trouvé la fonction isPlainObject intéressante car elle utilise ceci si (typeof obj! == 'object' || obj === null) renvoie false pour garantir que l'argument passé est un objet simple. Quand j'ai lu ce code pour la première fois, j'ai pensé, pourquoi ne pas simplement utiliser Object.prototype.toString.call (opts)! == '[object object]', ce qui réduirait le code et séparerait les objets de leurs sous-types comme Date. Mais déjà dans la ligne suivante, il est clair que même si soudainement (soudainement!) Un développeur utilisant connect retourne un objet Date, par exemple, en vérifiant Object.getPrototypeOf (obj) === null peut gérer cela.
Un autre point inattendu dans isPlainObject à cet endroit:
while (Object.getPrototypeOf(baseProto) !== null) { baseProto = Object.getPrototypeOf(baseProto) }
Trouver une réponse sur Google m'a conduit à
ce fil sur StackOverflow, et à
ce commentaire sur Redux de GitHub, qui explique comment ce code gère les situations où, par exemple, un objet est transféré à partir d'un iFrame.
-
D'abord décidé de traduire l'article. Je serais reconnaissant pour des éclaircissements, des conseils et des recommandations