Si vos versions sont rapides comme l'éclair, automatisées et fiables, vous ne pouvez pas lire cet article.
Auparavant, notre processus de publication était manuel, lent et bogué.
Nous avons échoué le sprint après le sprint, car nous n'avons pas eu le temps de créer et de présenter les fonctionnalités pour la prochaine revue de sprint. Nous détestions nos sorties. Souvent, ils duraient de trois à quatre jours.
Dans cet article, nous décrirons la pratique Stop the Line, qui nous a aidés à nous concentrer sur la résolution des problèmes de pipeline de disposition. En seulement trois mois, nous avons réussi à multiplier par 10 le taux de déploiement. Aujourd'hui, notre déploiement est entièrement automatisé et la libération du monolithe ne prend que 4 à 5 heures.
Arrêtez la ligne. Une pratique inventée par l'équipe
Je me souviens de la façon dont nous avons créé Stop the Line. Dans une rétrospective générale, nous avons discuté de longues sorties qui nous ont empêchés d'atteindre les objectifs de sprint. Un de nos développeurs a suggéré:
- [Sergey] Limitons le volume de sortie. Cela nous aidera à tester, à corriger les bogues et à déployer plus rapidement.
- [Dima] Peut-on introduire une restriction sur les travaux en cours (limite WIP)? Par exemple, dès que nous avons terminé 10 tâches, nous arrêtons le développement.
- [Développeurs] Mais les tâches peuvent être de tailles différentes. Cela ne résoudra pas le problème des versions importantes.
- [I] Introduisons une restriction basée sur la durée de la version, et non sur le nombre de tâches. Nous arrêterons le développement si la sortie prend trop de temps.
Nous avons décidé que si la version durait plus de 48 heures, nous allumions la lumière clignotante et arrêtions le travail de toutes les équipes sur les fonctionnalités commerciales du monolithe. Toutes les équipes travaillant sur le monolithe doivent arrêter le développement et se concentrer sur la diffusion de la version actuelle de la vente ou sur l'élimination des raisons qui ont retardé la publication. Lorsque la version est bloquée, cela n'a aucun sens de créer de nouvelles fonctionnalités, car elles seront toujours à venir. À l'heure actuelle, il est interdit d'écrire du nouveau code, même dans des branches distinctes.
Nous avons également introduit «Stop the Line Board» sur un simple tableau de conférence. Sur celui-ci, nous écrivons des tâches qui aident soit à pousser la version actuelle, soit à éviter les raisons de son retard.
Bien sûr, Stop The Line n'est pas une décision facile, mais cette pratique est une étape importante vers une livraison continue et de véritables DevOps.
Histoire de Dodo IS (Préambule technique)Dodo IS est écrit principalement sur le framework .Net avec une interface utilisateur sur React / Redux, place sur jQuery et entrecoupé d'Angular. Il existe encore des applications pour iOS et Android sur Swift et Kotlin.
L'architecture Dodo IS est un mélange d'un monolithe hérité et d'environ 20 microservices. Nous développons de nouvelles fonctionnalités métier dans des microservices distincts qui sont déployés soit à chaque validation (déploiement continu), soit sur demande, lorsque l'entreprise en a besoin, au moins toutes les cinq minutes (livraison continue).
Mais nous avons encore une grande partie de notre logique métier implémentée dans une architecture monolithique. Le monolithe est le plus difficile à déployer. Il faut du temps pour assembler l'ensemble du système (l'artefact de construction pèse environ 1 Go), exécuter des tests unitaires et d'intégration et effectuer une régression manuelle avant chaque version. La sortie elle-même est également lente. Chaque pays a sa propre copie du monolithe, nous devons donc déployer 12 copies pour 12 pays.
L'intégration continue (CI) est une pratique qui aide les développeurs à maintenir constamment le code en état de marche, à faire croître le produit par petites étapes, à intégrer au moins quotidiennement dans une branche avec le support de la construction CI avec de nombreux autotests.
Lorsque plusieurs équipes travaillent sur le même produit et pratiquent l'IC, le nombre de changements dans la branche générale augmente rapidement. Plus vous accumulez de changements, plus ce changement contiendra des défauts cachés et des problèmes potentiels. C'est pourquoi les équipes préfèrent déployer des modifications fréquemment, ce qui conduit à la pratique de la livraison continue (CD) comme prochaine étape logique après CI.
La pratique du CD vous permet de déployer du code dans prod à tout moment. Cette pratique est basée sur un pipeline de déploiement - un ensemble d'étapes automatiques ou manuelles qui vérifient l'incrémentation d'un produit sur son chemin vers un produit.
Notre pipeline de déploiement ressemble à ceci:
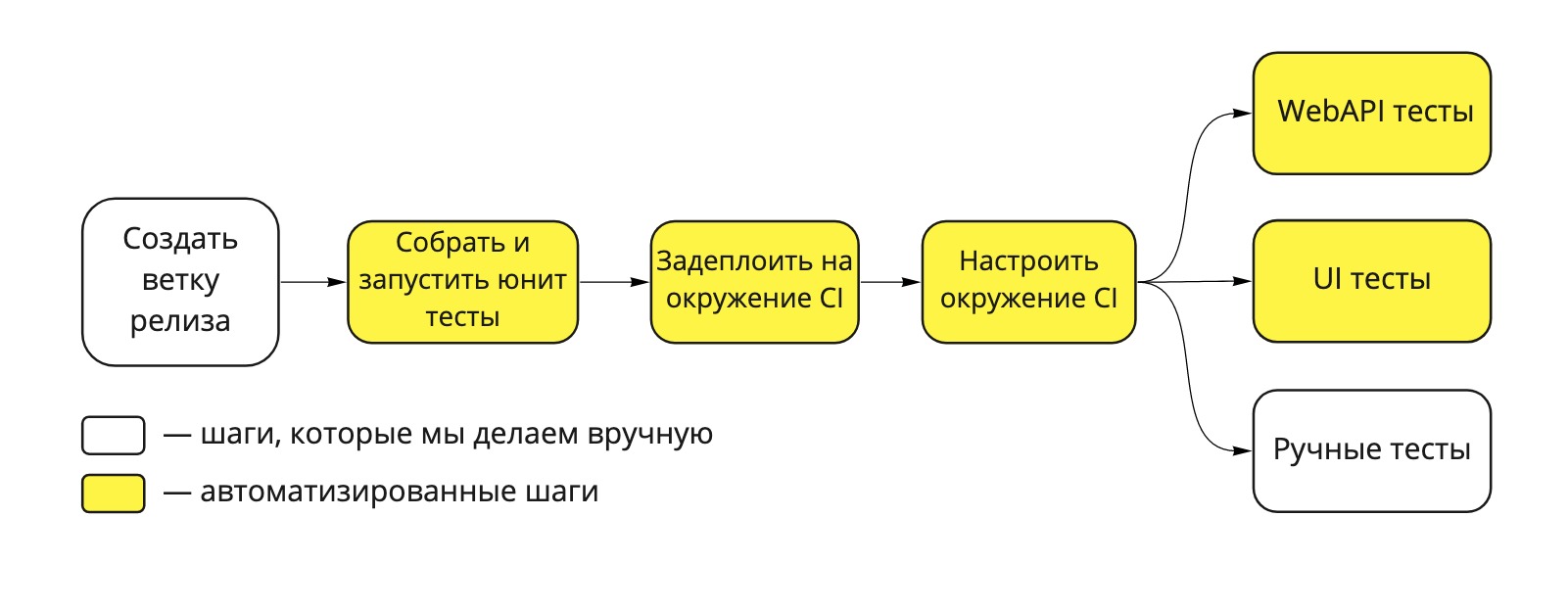
Fig. 1. Pipeline de déploiement Dodo IS
Sortons vite: du problème à la pratique Stop the line adaptée
La douleur des ralentissements. Pourquoi sont-ils si longs? Analyse
Extreme Programming (XP) a une règle d'or: si quelque chose fait mal, faites-le aussi souvent que possible. Nos sorties ont toujours été pénibles. Nous avons passé plusieurs jours pour déployer l'environnement de test, restaurer la base de données, exécuter les tests (généralement plusieurs fois), comprendre pourquoi ils sont tombés, corriger les bogues et, enfin, publier.
Le sprint dure 2 semaines et la libération roule pendant trois jours. Pour pouvoir le publier avant Sprint Review vendredi, vous devriez commencer la sortie lundi d'une bonne manière. Cela signifie que nous travaillons sur l'objectif de sprinter seulement 50% du temps. Et si nous pouvions sortir tous les jours, alors la période de travail productive augmenterait à 80-90%.
Notre libération moyenne prenait généralement de deux à trois jours. Dans un premier temps, six équipes ont travaillé sur le code dans la branche générale du développement (et avec la croissance de l'entreprise, le nombre d'équipes est passé à neuf). Juste avant la sortie, nous avons brunché la branche release. Pendant que cette branche est testée et régressée, les équipes continuent de se développer dans la branche générale de développement. Avant que la branche de publication n'atteigne les ventes, les équipes écriront beaucoup de code.
Plus il y a de changements dans l'incrément, plus il est probable que les changements effectués par différentes équipes s'influencent mutuellement, ce qui signifie que plus l'incrément doit être testé avec soin et plus il faudra de temps pour le libérer. Il s'agit d'un cycle auto-renforçant (voir Fig. 2). Plus il y a de changements dans la version (version «cheval»), plus le temps de régression est long. Plus le temps de régression est long, plus le temps s'écoule entre les versions et plus l'équipe effectue de changements avant la prochaine version. Nous l'appelions «les chevaux donnent naissance aux chevaux». Le diagramme CLD suivant (diagramme de boucle causale) illustre cette relation:
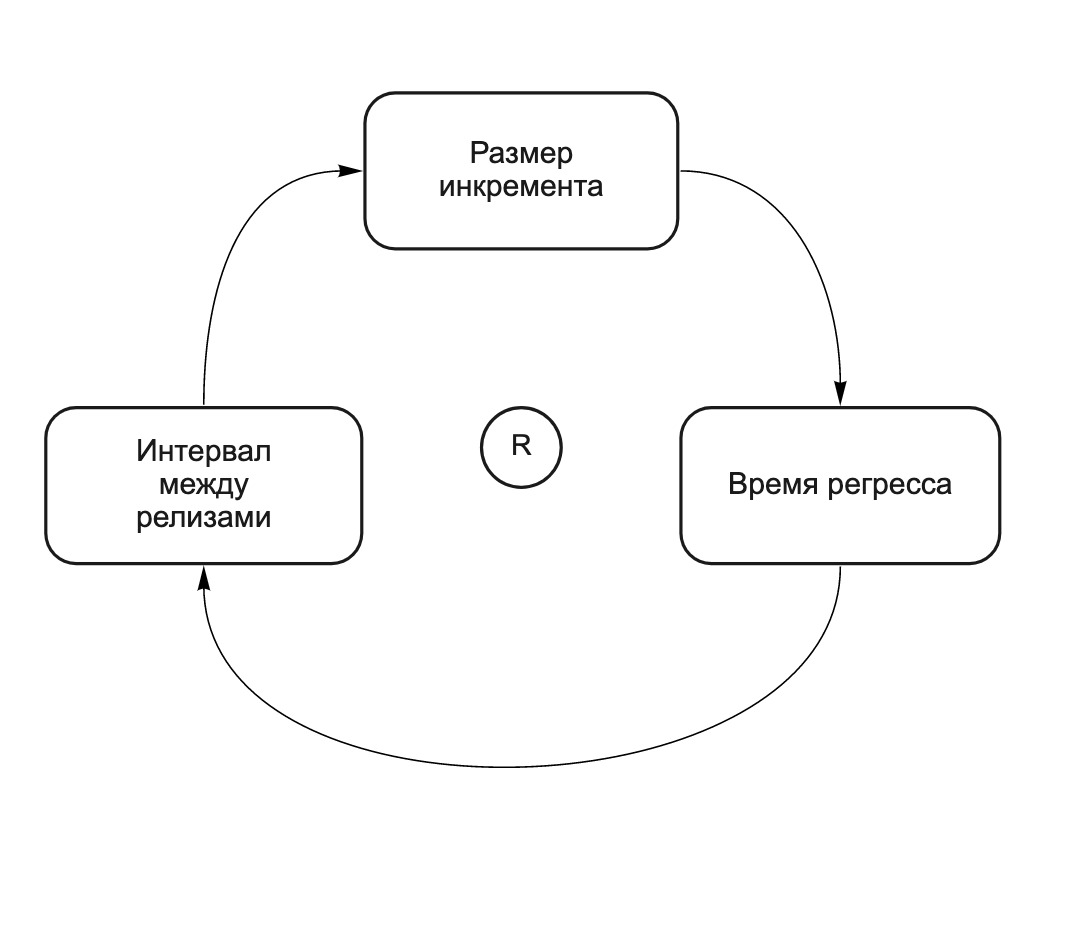
Fig. 2. Diagramme CLD: de longues versions conduisent à des versions encore plus longues
Automatisation de la régression avec la commande QA
Les étapes qui composent une version- Réglage de l'environnement. Nous restaurons la base de vente (675 Go), chiffrons les données personnelles et nettoyons les files d'attente RabbitMQ. Le chiffrement des données est une opération très longue et prend environ 1 heure.
- Exécutez des tests automatiques. Certains tests d'interface utilisateur sont instables, nous sommes donc obligés de les exécuter plusieurs fois jusqu'à ce qu'ils réussissent. La correction des tests de clignotement nécessite beaucoup d'attention et de discipline.
- Tests d'acceptation manuels. Certaines équipes préfèrent faire l'acceptation finale avant que le code ne passe à prod. Cela peut prendre plusieurs heures. S'ils trouvent des bugs, nous donnons aux équipes deux heures pour les corriger, sinon ils doivent annuler leurs modifications.
- Déployer sur prod. Étant donné que nous avons des copies distinctes de Dodo IS pour chaque pays, le processus de déploiement prend un certain temps. Une fois le déploiement terminé dans le premier pays, nous examinons les journaux pendant un certain temps, recherchons les erreurs, puis poursuivons le déploiement dans d'autres pays. L'ensemble du processus prend généralement environ deux heures, mais parfois cela peut prendre plus de temps, surtout si vous devez annuler la version.
Au début, nous avons décidé de nous débarrasser des tests de régression manuelle, mais le chemin à parcourir a été long et difficile. Il y a deux ans, la régression manuelle Dodo IS a duré une semaine entière. Ensuite, nous avons eu toute une équipe de testeurs manuels qui ont testé les mêmes fonctionnalités dans 10 pays semaine après semaine. Vous n'envierez pas un tel travail.
En juin 2017, nous avons formé l'équipe QA. L'objectif principal de l'équipe était d'automatiser la régression des opérations commerciales les plus importantes: réception des commandes et fabrication des produits. Dès que nous avons eu suffisamment de tests pour commencer à nous faire confiance, nous avons complètement abandonné les tests manuels. Mais cela ne s'est produit qu'un an et demi après le début de l'automatisation de la régression. Après cela, nous avons dissous l'équipe QA et l'équipe QA a rejoint les équipes de développement.
Cependant, les tests d'interface présentent des inconvénients importants. Puisqu'elles dépendent des données réelles de la base de données, ces données doivent être configurées. Un test peut corrompre les données d'un autre test. Le test peut échouer non seulement en raison d'une rupture de la logique, mais également en raison d'un réseau lent ou de données obsolètes dans le cache. Nous avons dû déployer beaucoup d'efforts pour nous débarrasser des tests clignotants et les rendre fiables et reproductibles.
Une étape pour arrêter la ligne. #IReleaseEveryDay Initiative
Nous avons créé une communauté aux vues similaires à #IReleaseEveryDay et réfléchi à la manière d'accélérer le pipeline de déploiement. Les premières actions ont été les suivantes:
- nous avons considérablement réduit l'ensemble des tests d'interface utilisateur en supprimant les tests répétés et inutiles. Cela a réduit le temps de test de plusieurs dizaines de minutes;
- Nous avons considérablement réduit le temps de configuration de l'environnement en raison de la récupération préliminaire de la base de données et du chiffrement des données. Par exemple, nous créons maintenant une copie de sauvegarde de la base de données la nuit, et dès que la version commence, nous basculons l'environnement de test vers la base de données de sauvegarde en quelques secondes.
Grâce aux solutions ci-dessus, nous avons réduit le temps de sortie moyen, mais il était toujours très long. Il est temps de changer le système.
Et si ...
Nous avons introduit la règle selon laquelle si la version dure plus de 48 heures, nous allumons la lumière clignotante et arrêtons le travail de toutes les équipes sur les fonctionnalités commerciales du monolithe. Toutes les équipes travaillant sur le monolithe doivent arrêter le développement et se concentrer sur le roulement de la version actuelle à la vente ou éliminer les raisons qui ont retardé la sortie.
Lorsque la version est bloquée, cela n'a aucun sens de créer de nouvelles fonctionnalités, car elles seront toujours à venir. À l'heure actuelle, il est interdit d'écrire du nouveau code, même dans des branches distinctes. Ce principe est décrit dans l'article de livraison continue de Martin Fowler: «En cas de problème avec la mise en page, votre équipe doit prioriser la résolution de ces problèmes ci-dessus en travaillant sur de nouvelles fonctionnalités.»
Entourage clignotant
Pendant Stop the line, un clignotant orange s'allume dans le bureau. Quiconque vient au troisième étage, où travaillent les développeurs de Dodo IS, voit ce signal visuel. Nous avons décidé de ne pas rendre nos développeurs fous avec le son d'une sirène et n'avons laissé qu'une lumière clignotante agaçante. Ainsi conçu. Comment pouvons-nous nous sentir à l'aise lorsqu'une libération est en difficulté?

Fig. 3. Blinker Stop the Line
Résistance d'équipe et petit sabotage
Au début, Stop the Line aimait toutes les équipes, car c'était amusant. Tout le monde était heureux comme les enfants et a présenté des photos de nos lumières de secours. Mais quand ça brûle 3-4 jours d'affilée, ça ne devient pas drôle. Un jour, l'une des équipes a enfreint les règles et téléchargé le code dans la branche de développement pendant Stop the Line afin de sauvegarder son objectif de sprint. Il est plus facile d'enfreindre une règle si cela vous empêche de travailler. Il s'agit d'un moyen rapide et sale d'effectuer une fonction métier, en ignorant un problème système.
En tant que Scrum Master, je ne pouvais pas supporter les violations des règles, j'ai donc soulevé cette question dans une rétrospective générale. Nous avons eu une conversation difficile. La plupart des équipes ont convenu que les règles s'appliquent à tout le monde. Nous avons convenu que chaque équipe doit respecter les règles, même si elle n'est pas d'accord avec elles. Et en même temps sur la façon dont vous pouvez changer les règles sans attendre la prochaine rétrospective.
Qu'est-ce qui n'a pas fonctionné comme prévu?
Initialement, les développeurs ne se sont pas concentrés sur la résolution des problèmes système avec le pipelint de déploiement. Lorsque la version est restée bloquée, au lieu d'aider à éliminer les causes du retard, ils ont préféré développer des microservices qui n'étaient pas soumis à la règle Stop the Line. Les microservices sont bons, mais les problèmes du monolithe ne se résoudront pas d'eux-mêmes. Afin de résoudre ces problèmes, nous avons introduit l'arriéré Stop The Line.
Certaines solutions étaient des solutions rapides qui masquaient les problèmes plutôt que de les résoudre. Par exemple, de nombreux tests ont été réparés en augmentant les délais d'attente ou en ajoutant des retraits. L'un de ces tests a duré 21 minutes. Le test a recherché le dernier employé créé dans une table sans index. Au lieu de corriger la logique de la demande, le programmeur a ajouté 3 nouvelles tentatives. En conséquence, le test lent est devenu encore plus lent. Lorsque Stop The Line est venu avec une équipe de propriétaires qui se concentrait sur les problèmes de test, au cours des trois prochains sprints, ils ont réussi à accélérer nos tests 2-3 fois.
Comment s'est comporté le comportement des équipes après avoir pratiqué Stop the Line?
Auparavant, une seule équipe avait des problèmes avec une version - une équipe qui la supportait. Les équipes ont essayé de se débarrasser de ce devoir désagréable dès que possible, au lieu d'investir dans des améliorations à long terme. Par exemple, si les tests sur l'environnement de test sont tombés, ils peuvent être redémarrés localement et si les tests réussissent, poursuivez la publication. Avec l'introduction de Stop The Line, les équipes ont désormais le temps de stabiliser les tests. Nous avons réécrit le code de préparation des tests, remplacé certains tests d'interface utilisateur par des tests d'API et supprimé les délais d'attente inutiles. Désormais, presque tous les tests réussissent rapidement et dans n'importe quel environnement.
Auparavant, les équipes ne s'engageaient pas systématiquement dans la dette technique. Nous avons maintenant un arriéré d'améliorations techniques que nous analysons pendant Stop the Line. Par exemple, nous avons réécrit les tests sur .Net Core, ce qui nous a permis de les exécuter dans Docker. L'exécution de tests dans Docker nous a permis d'utiliser la grille de sélénium pour paralléliser les tests et réduire davantage leur temps d'exécution.
Auparavant, les équipes comptaient sur une équipe d'AQ pour les tests et une équipe d'infrastructure pour le déploiement. Maintenant, il n'y a personne sur qui compter sauf eux-mêmes. Les équipes elles-mêmes testent et publient le code en production. Ce sont des DevOps authentiques, pas de faux.
L'évolution de la méthode Stop the line
Dans une rétrospective générale du sprint, nous examinons les expériences. Au cours des prochaines rétrospectives, nous avons apporté de nombreuses modifications aux règles Stop the Line, par exemple:
- Canal de libération. Toutes les informations sur la version actuelle se trouvent sur un canal Slack distinct. La chaîne a toutes les équipes dont les changements sont inclus dans la version. Sur cette chaîne, le releaseman demande de l'aide.
- Release Magazine. Le responsable de la libération consigne ses actions. Cela aide à trouver les raisons du retard dans la publication et à découvrir des modèles.
- La règle des cinq minutes. Dans les cinq minutes suivant l'annonce de Stop the Line, les représentants de l'équipe se rassemblent autour de la lumière d'urgence.
- Arriéré Arrêtez la ligne. Il y a un tableau de conférence sur le mur avec le carnet de commandes Stop The Line - une liste de tâches que les équipes peuvent effectuer pendant que la ligne s'arrête.
- Ne pas prendre en compte le dernier vendredi du sprint. Il est injuste de comparer deux versions, par exemple, une qui a commencé lundi et une autre qui a commencé vendredi. La première équipe peut passer deux jours complets à soutenir la version, et lors de la deuxième version, il y aura de nombreux événements vendredi (Sprint Review, Team Retrospective, General Retrospective) et lundi prochain (General et Team Sprint Planning), donc l'équipe du vendredi a moins de temps pour libérer le support. La sortie de vendredi sera arrêtée plus probablement que lundi. Par conséquent, nous avons décidé d'exclure le dernier vendredi du sprint de l'équation.
- Élimination de la dette technique. Après quelques mois, les équipes ont décidé que pendant l'arrêt, elles pourraient travailler sur la dette technique, et pas seulement sur l'accélération du pipeline de déploiement.
- Propriétaire Stop the Line. L'un des développeurs s'est porté volontaire pour devenir propriétaire de Stop The Line. Il est profondément plongé dans les raisons du retard dans les sorties et gère le backlog Stop the Line. Lorsque la ligne s'arrête, le propriétaire peut attirer n'importe quelle équipe pour travailler sur les éléments du carnet de commandes Stop the Line.
- Post mortem. Le propriétaire de Stop the Line détient un post mortem après chaque arrêt.
Coût des pertes
En raison de Stop the Line, nous n'avons pas atteint plusieurs objectifs de sprint. Les représentants des entreprises n'étaient pas trop satisfaits de nos progrès et ont posé beaucoup de questions lors du Sprint Review. Suivant le principe de transparence, nous avons parlé de ce qu'est Stop the Line et pourquoi vous devriez attendre quelques sprints supplémentaires. À chaque Sprint Review, nous avons montré aux équipes et aux parties prenantes combien d'argent nous avons perdu en raison de Stop the Line. Le coût est calculé comme le salaire total des équipes de développement pendant les temps d'arrêt.
• Novembre - 2 106 000 p.
• Décembre - 503 504 p.
• janvier - 1 219 767 p.
• Février - 2 002 278 p.
• mars - 0 p.
• Avril - 0 p.
• Mai - 361 138 p.
Cette transparence crée une pression saine et motive les équipes à résoudre immédiatement les problèmes de pipeline de déploiement. En regardant ces chiffres, nos équipes comprennent que rien n'est gratuit et chaque Stop the Line nous rapporte un joli sou.
Résultats
En fait, la pratique Stop the Line convertit un cycle d'auto-renforcement (Fig. 2) en deux cycles d'équilibrage (Fig. 4). Stop the Line nous aide à nous concentrer sur l'amélioration du pipeline de déploiement lorsqu'il devient trop lent. En seulement 4 sprints, nous:
- Suppression de 12 versions stables
- Temps de construction réduit de 30%
- Tests UI et API stabilisés. Maintenant, ils transmettent tous les environnements et même localement.
- Débarrassez-vous des tests clignotants
- J'ai commencé à faire confiance à nos tests.
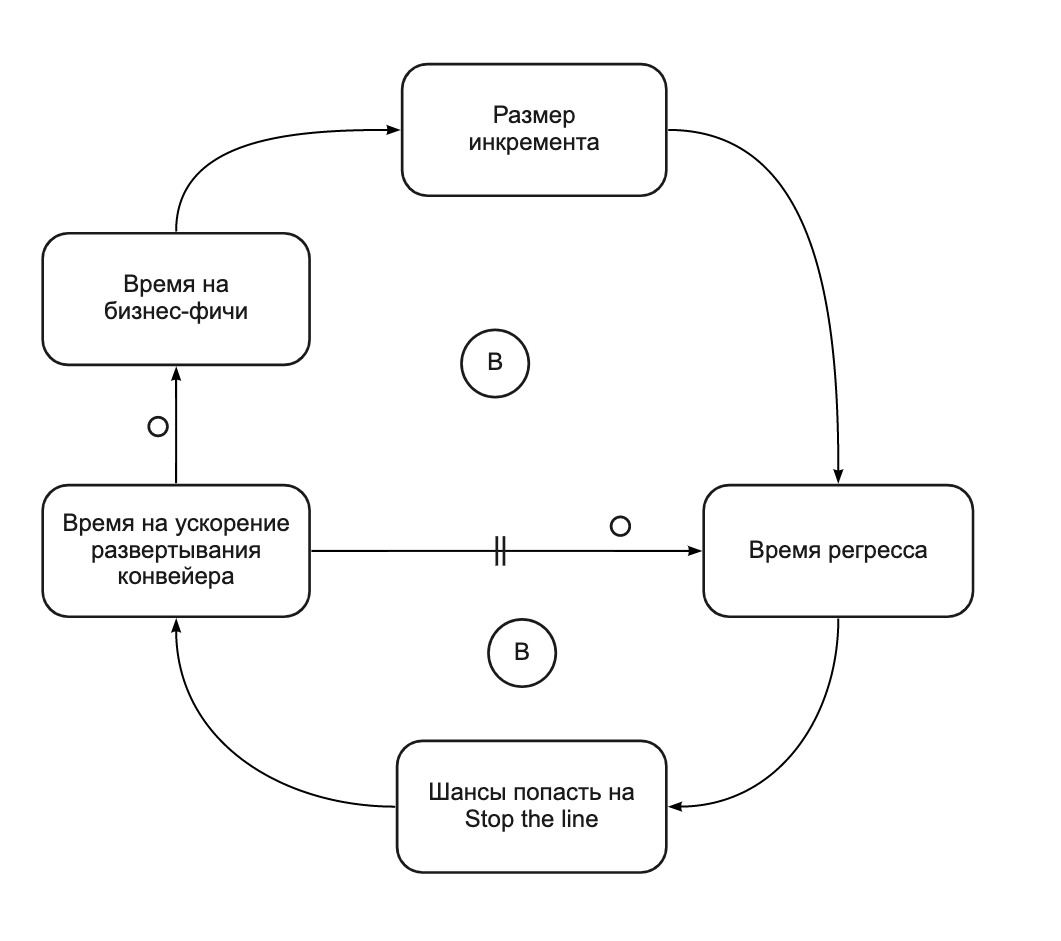
Fig. 4. Graphique CLD: Stop the Line soldes release time
Conclusions des Scrum Masters
Stop The Line est un excellent exemple d'une solution puissante inventée par les équipes de développement elles-mêmes. Scrum Master ne peut pas simplement prendre et apporter aux équipes une nouvelle pratique brillante. La pratique ne fonctionnera que si les équipes elles-mêmes l'ont proposé. Cela nécessite des conditions favorables: une atmosphère de confiance et une culture d'expérimentation.
Certes, la confiance et le soutien de l'entreprise sont nécessaires, ce qui n'est possible qu'en toute transparence. La rétroaction, comme une rétrospective générale et régulière avec tous les représentants de l'équipe, aide à inventer, mettre en œuvre et modifier de nouvelles pratiques.
Au fil du temps, la pratique de Stop the Line devrait se tuer. Plus nous arrêtons la ligne, plus nous investissons dans le pipeline de déploiement, plus la publication devient stable et rapide, moins il y a de raison d'arrêter. Au final, la ligne ne s'arrêtera jamais, sauf si nous décidons d'abaisser le seuil, par exemple de 48 à 24 heures. Mais, grâce à cette pratique, nous avons considérablement amélioré la procédure de libération. Les équipes ont acquis une expérience non seulement dans le développement, mais aussi dans la livraison rapide de valeur aux produits. Ce sont de véritables DevOps.
Et ensuite? Je ne sais pas. Peut-être abandonnerons-nous bientôt cette pratique. Les équipes décideront. Mais il est évident que nous continuerons à évoluer vers la livraison continue et le DevOps. Un jour, mon rêve de libérer un monolithe plusieurs fois par jour deviendra réalité.