
Bonjour lecteurs d'Habr! Dans un article précédent, nous avons parlé d'un outil simple de tolérance aux catastrophes dans les systèmes de stockage AERODISK ENGINE - sur la réplication. Dans cet article, nous aborderons un sujet plus complexe et intéressant - le cluster de métro, c'est-à-dire un moyen de protection automatisée contre les catastrophes pour deux centres de données, qui permet aux centres de données de fonctionner en mode actif-actif. Nous allons le raconter, le montrer, le casser et le réparer.
Comme d'habitude, au début de la théorie
Un cluster de métro est un cluster espacé sur plusieurs sites au sein d'une ville ou d'un quartier. Le mot «cluster» nous indique clairement que le complexe est automatisé, c'est-à-dire que la commutation des nœuds de cluster en cas de défaillance se produit automatiquement.
C'est là que réside la principale différence entre le cluster de métro et la réplication ordinaire. Automatisation des opérations. C'est-à-dire que dans le cas de certains incidents (panne du centre de données, canaux cassés, etc.), le système de stockage effectuera indépendamment les actions nécessaires afin de maintenir la disponibilité des données. Lors de l'utilisation de réplicas réguliers, ces actions sont effectuées entièrement ou partiellement manuellement par l'administrateur.
À quoi ça sert?
L'objectif principal que les clients poursuivent en utilisant l'une ou l'autre implémentation du cluster de métro est de minimiser le RTO (Recovery Time Objective). Autrement dit, minimisez le temps de récupération des services informatiques après une panne. Si vous utilisez la réplication normale, le temps de récupération sera toujours plus long que le temps de récupération avec le cluster Metro. Pourquoi? Très simple. L'administrateur doit être sur le lieu de travail et basculer la réplication à la main, et le cluster de métro le fait automatiquement.
Si vous n'avez pas d'administrateur dédié en service qui ne dorme pas, ne mange pas, ne fume pas ou ne tombe pas malade et qui regarde l'état de stockage 24 heures par jour, il n'y a aucun moyen de garantir que l'administrateur sera disponible pour un changement manuel en cas de panne.
En conséquence, RTO en l’absence de grappe de métro ou immortel admin niveau 99 Le service en service de l'administrateur sera égal à la somme du temps de commutation de tous les systèmes et de la période maximale après laquelle l'administrateur est garanti de commencer à travailler avec les systèmes de stockage et les systèmes associés.
Ainsi, nous arrivons à la conclusion évidente que le cluster de métro devrait être utilisé si l'exigence de RTO est de minutes, pas d'heures ou de jours, c'est-à-dire lorsque le service informatique doit donner aux entreprises le temps de restaurer l'accès à l'informatique dans le cas de la pire chute du centre de données -services en quelques minutes, voire quelques secondes.
Comment ça marche?
Au niveau inférieur, le cluster metro utilise le mécanisme de réplication synchrone des données, que nous avons décrit dans un article précédent (voir lien ). La réplication étant synchrone, les conditions requises sont appropriées, ou plutôt:
- fibre comme physique, Ethernet 10 gigabits (ou supérieur);
- la distance entre les centres de données ne dépasse pas 40 kilomètres;
- Délai de canal optique entre les centres de données (entre les systèmes de stockage) jusqu'à 5 millisecondes (de manière optimale 2).
Toutes ces exigences sont de nature consultative, c'est-à-dire que le cluster de métro fonctionnera même si ces exigences ne sont pas remplies, mais il faut comprendre que les conséquences du non-respect de ces exigences sont égales au ralentissement des deux systèmes de stockage dans le cluster de métro.
Ainsi, une réplique synchrone est utilisée pour transférer des données entre les systèmes de stockage, et comment les répliques sont automatiquement commutées, et surtout, comment éviter le split-brain? Pour cela, au niveau ci-dessus, une entité supplémentaire est utilisée - l'arbitre.
Comment fonctionne l'arbitre et quelle est sa tâche?
L'arbitre est une petite machine virtuelle, ou un cluster matériel, qui doit être exécuté sur la troisième plate-forme (par exemple, au bureau) et fournir un accès au stockage via ICMP et SSH. Après le lancement, l'arbitre doit définir l'adresse IP, puis du côté stockage, indiquer son adresse, ainsi que les adresses des télécommandes qui participent au cluster de métro. Après cela, l'arbitre est prêt à travailler.
L'arbitre surveille en permanence tous les systèmes de stockage du cluster Metro et, si un système de stockage n'est pas disponible, après avoir confirmé qu'il n'est pas disponible auprès d'un autre membre du cluster (l'un des systèmes de stockage «actifs»), il décide de démarrer la procédure de changement de règles de réplication et de mappage.
Un point très important. L'arbitre doit toujours se trouver sur un site différent de ceux sur lesquels se trouve le stockage, c'est-à-dire ni dans le centre de données-1, où se trouve le stockage 1, ni dans le centre de données-2, où le stockage 2 est installé.
Pourquoi? Parce que la seule façon pour un arbitre, à l'aide de l'un des systèmes de stockage survivants, de déterminer sans ambiguïté et précision la chute de l'un des deux sites sur lesquels les systèmes de stockage sont installés. Tout autre moyen de placer un arbitre peut entraîner une scission du cerveau.
Plongez maintenant dans les détails de l'arbitre
L'arbitre exécute plusieurs services qui sont constamment interrogés par tous les contrôleurs de stockage. Si le résultat de l'enquête diffère de la précédente (disponible / inaccessible), il est enregistré dans une petite base de données, qui fonctionne également comme arbitre.
Examinez plus en détail la logique de l'arbitre.
Étape 1. Détermination de l'inaccessibilité. Un signal d'événement concernant la défaillance du système de stockage est l'absence de ping des deux contrôleurs du même système de stockage pendant 5 secondes.
Étape 2. Commencez la procédure de commutation. Après que l'arbitre a compris que l'un des systèmes de stockage n'est pas disponible, il envoie une demande au système de stockage «en direct» afin de s'assurer que le système de stockage «mort» est vraiment mort.
Après avoir reçu une telle commande de l'arbitre, le deuxième système de stockage (en direct) vérifie en outre la disponibilité du premier système de stockage tombé et, sinon, envoie à l'arbitre une confirmation de ses suppositions. Le stockage n'est vraiment pas disponible.
Après avoir reçu une telle confirmation, l'arbitre démarre la procédure à distance pour commuter la réplication et augmenter le mappage sur les répliques qui étaient actives (principales) sur le système de stockage supprimé, et envoie une commande au deuxième système de stockage pour faire ces répliques du secondaire au principal et augmenter le mappage. Eh bien, le deuxième système de stockage, respectivement, effectue ces procédures, après quoi il permet d'accéder aux LUN perdus à partir de lui-même.
Pourquoi ai-je besoin d'une vérification supplémentaire? Pour le quorum. Autrement dit, la plupart du nombre impair (3) total de membres de cluster devrait confirmer la chute d'un des nœuds de cluster. Ce n'est qu'alors que cette décision sera exacte. Ceci est nécessaire afin d'éviter une commutation erronée et, par conséquent, un cerveau divisé.
L'étape 2 dans le temps prend environ 5 à 10 secondes, donc, en tenant compte du temps nécessaire pour déterminer l'inaccessibilité (5 secondes), dans les 10 à 15 secondes après l'accident, les LUN avec stockage abandonné seront automatiquement disponibles pour travailler avec le stockage en direct.
Il est clair que pour éviter de déconnecter les hôtes, vous devez également prendre soin du réglage correct des délais d'attente sur les hôtes. Le délai d'expiration recommandé est d'au moins 30 secondes. Cela ne permettra pas à l'hôte de se déconnecter du système de stockage pendant le transfert de charge lors d'un accident et sera en mesure de garantir qu'il n'y a pas d'interruption de l'entrée-sortie.
Une seconde, il s'avère que si tout va bien avec le cluster de métro, pourquoi avez-vous besoin d'une réplication régulière?
En fait, tout n'est pas si simple.
Considérez les avantages et les inconvénients de la grappe de métro
Nous avons donc réalisé que les avantages évidents du cluster de métro par rapport à la réplication conventionnelle sont:
- Automatisation complète offrant un temps de récupération minimum en cas de sinistre;
- Et c'est tout :-).
Et maintenant, attention, contre:
- Le coût de la décision. Bien que le cluster de métro dans les systèmes Aerodisk ne nécessite pas de licence supplémentaire (la même licence est utilisée que pour la réplique), le coût de la solution sera toujours plus élevé que l'utilisation de la réplication synchrone. Il sera nécessaire de mettre en œuvre toutes les exigences pour la réplique synchrone, ainsi que les exigences pour le cluster de métro liées à la commutation supplémentaire et au site supplémentaire (voir Planification du cluster de métro);
- La complexité de la décision. Le cluster de métro est beaucoup plus complexe qu'une réplique régulière et nécessite beaucoup plus d'attention et de travail pour la planification, la configuration et la documentation.
En fin de compte. Le cluster Metro est, bien sûr, une solution très technologique et bonne lorsque vous avez vraiment besoin de fournir un RTO en quelques secondes ou minutes. Mais s'il n'y a pas une telle tâche, et que le RTO en heures est OK pour l'entreprise, alors il ne sert à rien de tirer des moineaux avec le canon. La réplication habituelle des paysans est suffisante, car le cluster métropolitain entraînera des coûts supplémentaires et compliquera l'infrastructure informatique.
Planification du cluster métropolitain
Cette section ne prétend pas être un guide complet pour la conception du cluster de métro, mais ne montre que les principales directions qui devraient être élaborées si vous décidez de construire un tel système. Par conséquent, avec la mise en œuvre réelle du cluster de métro, assurez-vous d'impliquer le fabricant de systèmes de stockage (c'est-à-dire, nous) et d'autres systèmes connexes pour les consultations.
Plateformes
Comme indiqué ci-dessus, un minimum de trois sites est requis pour un cluster de métro. Deux centres de données, où les systèmes de stockage et les systèmes associés fonctionneront, ainsi qu'une troisième plate-forme où l'arbitre fonctionnera.
La distance recommandée entre les centres de données ne dépasse pas 40 kilomètres. De plus grandes distances sont très susceptibles de provoquer des retards supplémentaires, qui dans le cas d'un cluster de métro sont très indésirables. Rappelons que les retards devraient aller jusqu'à 5 millisecondes, bien qu'il soit souhaitable d'en respecter 2.
Il est également recommandé de vérifier les retards pendant le processus de planification. Tout fournisseur plus ou moins adulte qui fournit de la fibre entre les centres de données, un contrôle de qualité peut s'organiser assez rapidement.
En ce qui concerne les retards avant l'arbitre (c'est-à-dire entre la troisième plate-forme et les deux premières), le seuil de retard recommandé est jusqu'à 200 millisecondes, c'est-à-dire qu'une connexion VPN d'entreprise régulière sur Internet convient.
Commutation et mise en réseau
Contrairement à un schéma de réplication, où il suffit d'interconnecter des systèmes de stockage de différents sites, un schéma avec un cluster de métro nécessite de connecter des hôtes aux deux systèmes de stockage sur des sites différents. Pour clarifier la différence, les deux schémas sont répertoriés ci-dessous.
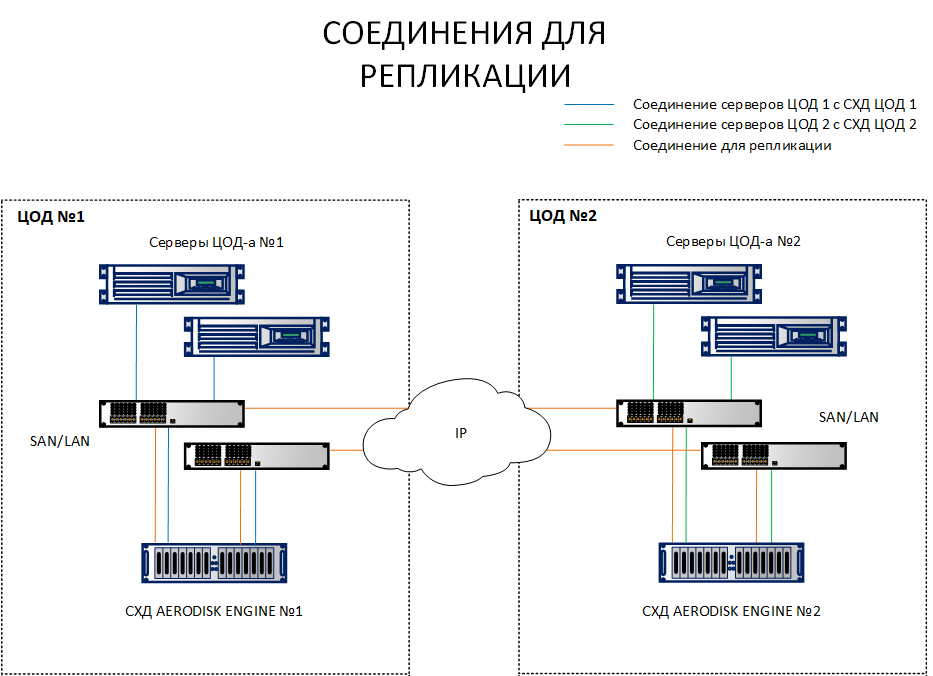

Comme vous pouvez le voir sur le diagramme, les hôtes du site 1 regardent à la fois SHD1 et SHD 2. De plus, au contraire, les hôtes de la plate-forme 2 regardent SHD 2 et SHD1. Autrement dit, chaque hôte voit les deux systèmes de stockage. Il s'agit d'une condition préalable au fonctionnement du cluster de métro.
Bien sûr, il n'est pas nécessaire de tirer chaque hôte avec un cordon optique vers un centre de données différent, aucun port ni lacet ne suffira. Toutes ces connexions doivent être établies via des commutateurs Ethernet 10G + ou FibreChannel 8G + (FC uniquement pour la connexion des hôtes et le stockage pour IO, le canal de réplication n'est actuellement disponible que sur IP (Ethernet 10G +).
Maintenant, quelques mots sur la topologie du réseau. Un point important est la configuration correcte des sous-réseaux. Vous devez immédiatement identifier plusieurs sous-réseaux pour les types de trafic suivants:
- Sous-réseau de réplication sur lequel les données entre les systèmes de stockage seront synchronisées. Il peut y en avoir plusieurs, dans ce cas cela n'a pas d'importance, tout dépend de la topologie de réseau actuelle (déjà implémentée). S'il y en a deux, alors évidemment le routage entre eux doit être configuré;
- Sous-réseaux de stockage via lesquels les hôtes accéderont aux ressources de stockage (s'il s'agit d'iSCSI). Il devrait y avoir un tel sous-réseau dans chaque centre de données;
- Contrôle des sous-réseaux, c'est-à-dire trois sous-réseaux routables sur trois sites à partir desquels la gestion du stockage est effectuée, et il existe également un arbitre.
Nous ne considérons pas les sous-réseaux pour accéder aux ressources hôtes ici, car ils dépendent fortement des tâches.
La séparation de différents trafics en différents sous-réseaux est extrêmement importante (il est particulièrement important de séparer la réplique des E / S), car si vous mélangez tout le trafic en un sous-réseau «épais», ce trafic sera impossible à gérer et, dans les conditions de deux centres de données, il peut toujours provoquer des différences options de collision réseau. Nous ne nous pencherons pas beaucoup sur ce problème dans le cadre de cet article, car vous pouvez en savoir plus sur la planification d'un réseau étiré entre les centres de données sur les ressources des fabricants d'équipements de réseau, où il est décrit en détail.
Configuration des arbitres
L'arbitre doit fournir l'accès à toutes les interfaces de gestion du stockage via les protocoles ICMP et SSH. Vous devez également tenir compte de la tolérance aux pannes de l'arbitre. Il y a une nuance.
La tolérance aux pannes de l'arbitre est très souhaitable, mais facultative. Et que se passe-t-il si l'arbitre se bloque au mauvais moment?
- Le fonctionnement du cluster de métro en mode normal ne changera pas, car arbtir n'affecte en rien le fonctionnement du cluster de métro en mode normal (sa tâche est de basculer en temps voulu la charge entre les centres de données)
- De plus, si l'arbitre pour une raison ou une autre tombe et "réveille" l'accident dans le centre de données, aucun changement ne se produira, car il n'y aura personne pour donner les commandes nécessaires pour commuter et organiser un quorum. Dans ce cas, le cluster métropolitain se transformera en un schéma de réplication régulier, qui devra être commuté à la main lors d'une catastrophe, ce qui affectera le RTO.
Qu'est-ce qui en découle? Si vous avez vraiment besoin d'assurer un RTO minimum, vous devez vous assurer de la tolérance aux pannes de l'arbitre. Il y a deux options pour cela:
- Exécutez une machine virtuelle avec un arbitre sur un hyperviseur de basculement, car tous les hyperviseurs adultes prennent en charge le basculement;
- Si sur le troisième site (dans un bureau conditionnel)
la paresse de mettre un cluster normal Comme il n'y a pas de cluster d'hyperviseur existant, nous avons fourni une version matérielle de l'arbitre, qui est faite dans une boîte 2U, dans laquelle deux serveurs x-86 ordinaires fonctionnent et qui peuvent survivre à une défaillance locale.
Nous recommandons fortement que l'arbitre soit tolérant aux pannes malgré le fait que le cluster de métro n'en a pas besoin en mode normal. Mais la théorie et la pratique montrent que si vous construisez une infrastructure vraiment fiable et résistante aux catastrophes, il est préférable de la jouer en toute sécurité. Il est préférable de vous protéger, vous et votre entreprise, de la "loi de la méchanceté", c'est-à-dire de la défaillance de l'arbitre et de l'un des sites où se trouve le système de stockage.
Architecture de la solution
Compte tenu des exigences ci-dessus, nous obtenons l'architecture de solution générale suivante.

Les LUN doivent être répartis uniformément sur deux sites pour éviter une congestion importante. En même temps, lors du dimensionnement dans les deux centres de données, il est nécessaire de prévoir non seulement un double volume (qui est nécessaire pour stocker les données simultanément sur deux systèmes de stockage), mais également des performances doubles en IOPS et en Mo / s, afin d'éviter la dégradation des applications en cas de défaillance de l'un des centres de données - ov.
Séparément, nous notons qu'avec une approche appropriée du dimensionnement (c'est-à-dire, à condition que nous ayons fourni les limites supérieures appropriées pour les IOPS et les Mo / s, ainsi que les ressources CPU et RAM nécessaires), si l'un des systèmes de stockage tombe en panne dans le cluster de métro, il n'y aura pas de baisse sérieuse des performances travail temporaire sur un système de stockage.
Cela est dû au fait que dans les conditions de deux sites simultanément, le travail de réplication synchrone «dévore» la moitié des performances d'écriture, car chaque transaction doit être écrite sur deux systèmes de stockage (similaire à RAID-1/10). Ainsi, si l'un des systèmes de stockage tombe en panne, l'effet de la réplication temporairement (jusqu'à ce que le système de stockage défaillant augmente) disparaît et nous obtenons une double augmentation des performances d'écriture. Après le redémarrage des LUN du système de stockage défaillant sur un système de stockage fonctionnel, cette double augmentation disparaît en raison de la charge des LUN d'un autre système de stockage, et nous revenons au même niveau de performances que nous avions avant la «baisse», mais uniquement dans le cadre d'une seule plateforme.
Avec l'aide d'un dimensionnement compétent, il est possible de fournir des conditions dans lesquelles les utilisateurs ne ressentiront pas du tout la défaillance d'un système de stockage complet. Mais encore une fois, cela nécessite un dimensionnement très soigné, pour lequel, incidemment, vous pouvez nous contacter gratuitement :-).
Configuration du cluster Metro
La configuration d'un cluster Metro est très similaire à la configuration d'une réplication régulière, que nous avons décrite dans un article précédent . Par conséquent, nous nous concentrons uniquement sur les différences. Nous avons installé un stand basé sur l'architecture ci-dessus dans le laboratoire dans la version minimale uniquement: deux systèmes de stockage connectés par Ethernet 10G entre eux, deux commutateurs 10G et un hôte qui examine les 10 ports de stockage via les commutateurs des deux systèmes de stockage. L'arbitre s'exécute sur une machine virtuelle.

Lors de la configuration des adresses IP virtuelles (VIP) pour une réplique, sélectionnez le type VIP pour le cluster de métro.

Nous avons créé deux liens de réplication pour deux LUN et les avons répartis sur deux systèmes de stockage: LUN TEST Primary sur SHD1 (liaison METRO), LUN TEST2 Primary sur SHD2 (liaison METRO2).

Pour eux, nous avons mis en place deux cibles identiques (dans notre cas iSCSI, mais FC est également supporté, la logique de réglage est la même).
SHD1:

SHD2:

Pour les connexions de réplication, ils ont effectué des mappages sur chaque système de stockage.
SHD1:

SHD2:

Multipath configuré et présenté à l'hôte.


Configurer l'arbitre
Vous n'avez rien à faire de spécial avec l'arbitre lui-même, il vous suffit de l'activer sur la troisième plate-forme, de lui attribuer une IP et de configurer l'accès à celui-ci via ICMP et SSH. La configuration elle-même est effectuée à partir des systèmes de stockage eux-mêmes. Dans ce cas, il suffit de configurer l'arbitre une fois sur l'un des contrôleurs de stockage du cluster Metro, ces paramètres seront distribués automatiquement à tous les contrôleurs.
Dans la section Réplication à distance >> Metrocluster (sur n'importe quel contrôleur) >> bouton Configurer.
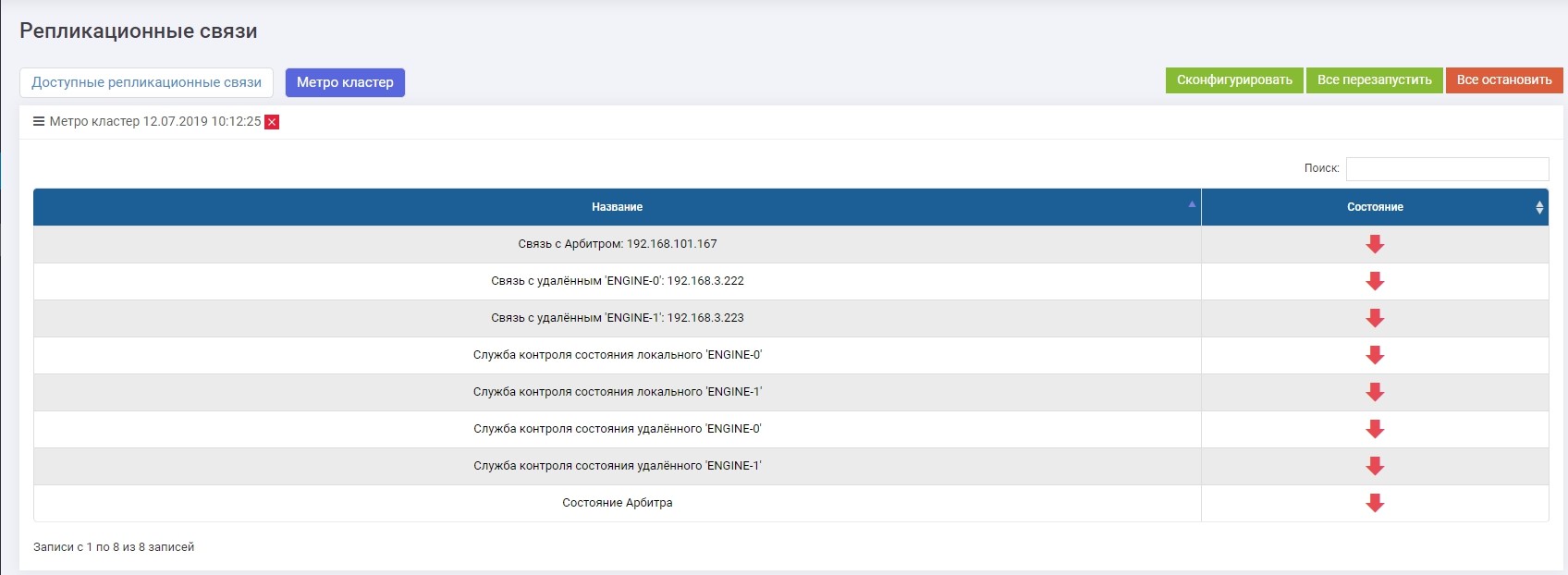
Nous introduisons l'IP de l'arbitre, ainsi que les interfaces de contrôle des deux contrôleurs du système de stockage distant.

Après cela, vous devez activer tous les services (le bouton "Tout redémarrer"). En cas de reconfiguration future, les services doivent être redémarrés pour que les paramètres prennent effet.

Vérifiez que tous les services sont en cours d'exécution.

Ceci termine la configuration du cluster de métro.
Test de collision
Le crash test dans notre cas sera assez simple et rapide, puisque la fonctionnalité de réplication (commutation, cohérence, etc.) a été envisagée dans un article précédent . Par conséquent, pour tester la fiabilité d'un cluster de métro, il nous suffit de vérifier l'automatisation de la détection des accidents, la commutation et l'absence de pertes d'enregistrement (arrêts d'E / S).
Pour ce faire, nous émulons la défaillance complète de l'un des systèmes de stockage en arrêtant physiquement ses deux contrôleurs, en démarrant la copie préliminaire d'un gros fichier sur le LUN, qui doit être activé sur l'autre système de stockage.

Désactivez un stockage. Sur le deuxième système de stockage, nous voyons des alertes et des messages dans les journaux que la connexion avec le système voisin a disparu. Si vous avez configuré des alertes pour la surveillance SMTP ou SNMP, l'administrateur recevra les alertes appropriées.

Exactement 10 secondes plus tard (vu dans les deux captures d'écran), le lien de réplication METRO (celui qui était principal sur le système de stockage en panne) est automatiquement devenu principal sur le système de stockage en cours d'exécution. En utilisant le mappage existant, LUN TEST est resté disponible pour l'hôte, l'enregistrement s'est affaissé un peu (dans les 10% promis), mais n'a pas cassé.


Le test s'est terminé avec succès.
Pour résumer
L'implémentation actuelle du métrocluster dans les systèmes de stockage AERODISK Engine de la série N permet de résoudre complètement les problèmes où il est nécessaire d'éliminer ou de minimiser les temps d'arrêt des services informatiques et d'assurer leur fonctionnement 24/7/365 avec un minimum de main-d'œuvre.
, , , … , , . , , , .
, .