
Je m'appelle Eduard Tyantov, je dirige l'équipe de vision par ordinateur du groupe Mail.ru. Au cours de plusieurs années de notre existence, notre équipe a résolu des dizaines de problèmes de vision par ordinateur, et aujourd'hui je vais vous parler des méthodes que nous utilisons pour créer avec succès des modèles d'apprentissage automatique qui fonctionnent sur un large éventail de tâches. Je partagerai des astuces qui peuvent accélérer le modèle à toutes les étapes: définition d'une tâche, préparation des données, formation et déploiement en production.
Vision par ordinateur à Mail.ru
Pour commencer, qu'est-ce que la vision par ordinateur dans Mail.ru et quels projets nous faisons. Nous proposons des solutions dans nos produits, telles que Mail, Mail.ru Cloud (une application pour stocker des photos et des vidéos), Vision (solutions B2B basées sur la vision par ordinateur) et autres. Je vais donner quelques exemples.
Le Cloud (c'est notre premier et principal client) contient 60 milliards de photos. Nous développons diverses fonctionnalités basées sur l'apprentissage automatique pour leur traitement intelligent, par exemple, la reconnaissance faciale et les visites touristiques (
il y a un article séparé à ce sujet ). Toutes les photos des utilisateurs sont exécutées via des modèles de reconnaissance, ce qui vous permet d'organiser une recherche et un regroupement par personnes, tags, villes et pays visités, etc.
Pour Mail, nous avons fait l'OCR - reconnaissance du texte d'une image. Aujourd'hui, je vais vous en dire un peu plus sur lui.
Pour les produits B2B, nous reconnaissons et comptons les personnes dans les files d'attente. Par exemple, il y a une file d'attente pour les remontées mécaniques et vous devez calculer le nombre de personnes qui s'y trouvent. Pour commencer, afin de tester la technologie et le jeu, nous avons déployé un prototype dans la salle à manger du bureau. Il y a plusieurs caisses et, par conséquent, plusieurs files d'attente, et nous, en utilisant plusieurs caméras (une pour chacune des files d'attente), en utilisant le modèle, nous calculons combien de personnes sont dans les files d'attente et combien de minutes approximatives il reste dans chacune d'elles. De cette façon, nous pouvons mieux équilibrer les lignes dans la salle à manger.

Énoncé du problème
Commençons par la partie critique de toute tâche - sa formulation. Presque n'importe quel développement ML prend au moins un mois (c'est au mieux quand vous savez quoi faire), et dans la plupart des cas plusieurs mois. Si la tâche est incorrecte ou inexacte, il y a une grande chance à la fin du travail d'entendre le chef de produit quelque chose dans l'esprit: «Tout va mal. Ce n'est pas bon. Je voulais autre chose. " Pour éviter que cela ne se produise, vous devez prendre certaines mesures. Quelle est la particularité des produits à base de ML? Contrairement à la tâche de développer un site, la tâche d'apprentissage automatique ne peut pas être formalisée avec du texte seul. De plus, en règle générale, il semble à une personne non préparée que tout est déjà évident, et il est simplement nécessaire de tout faire "magnifiquement". Mais quels sont les petits détails, le gestionnaire de tâches ne le sait peut-être même pas, n'y a jamais pensé et ne réfléchira pas avant d'avoir vu le produit final et de dire: «Qu'avez-vous fait?»
Les problèmes
Comprenons par exemple quels problèmes peuvent être. Supposons que vous ayez une tâche de reconnaissance faciale. Vous le recevez, réjouissez-vous et appelez votre mère: "Hourra, une tâche intéressante!" Mais est-il possible de se décomposer directement et de commencer à le faire? Si vous faites cela, alors à la fin, vous pouvez vous attendre à des surprises:
- Il existe différentes nationalités. Par exemple, il n'y avait ni Asiatiques ni personne dans le jeu de données. Votre modèle ne sait donc pas du tout les reconnaître et le produit en a besoin. Ou vice versa, vous avez passé trois mois supplémentaires sur la révision, et le produit n'aura que des Caucasiens, et ce n'était pas nécessaire.
- Il y a des enfants. Pour les pères sans enfant comme moi, tous les enfants sont sur un même visage. Je suis tout à fait d'accord avec le modèle, quand elle envoie tous les enfants dans un cluster - on ne sait vraiment pas en quoi la majorité des enfants diffèrent! ;) Mais les gens qui ont des enfants ont une opinion complètement différente. Habituellement, ce sont aussi vos dirigeants. Ou il y a encore des erreurs de reconnaissance amusantes lorsque la tête de l'enfant est comparée avec succès au coude ou à la tête d'un homme chauve (histoire vraie).
- Que faire des personnages peints n'est généralement pas clair. Dois-je les reconnaître ou non?
Ces aspects de la tâche sont très importants à identifier au début. Par conséquent, vous devez travailler et communiquer avec le gestionnaire dès le début «sur les données». Les explications orales ne peuvent être acceptées. Il est nécessaire de regarder les données. Il est souhaitable de la même distribution sur laquelle le modèle fonctionnera.
Idéalement, au cours de cette discussion, un ensemble de données de test sera obtenu sur lequel vous pourrez enfin exécuter le modèle et vérifier s'il fonctionne comme le gestionnaire le souhaitait. Il est conseillé de donner une partie de l'ensemble de données de test au gestionnaire lui-même, afin que vous n'y ayez aucun accès. Parce que vous pouvez facilement vous recycler sur cet ensemble de test, vous êtes un développeur ML!
Définir une tâche en ML est un travail constant entre un chef de produit et un spécialiste du ML. Même si au début vous définissez bien la tâche, alors que le modèle se développe, de plus en plus de nouveaux problèmes apparaîtront, de nouvelles fonctionnalités que vous apprendrez sur vos données. Tout cela doit être constamment discuté avec le manager. Les bons managers diffusent toujours à leurs équipes ML qu'ils doivent prendre leurs responsabilités et aider le manager à définir les tâches.
Pourquoi L'apprentissage automatique est un domaine assez nouveau. Les gestionnaires n'ont pas (ou ont peu) d'expérience dans la gestion de telles tâches. À quelle fréquence les gens apprennent-ils à résoudre de nouveaux problèmes? Sur les erreurs. Si vous ne voulez pas que votre projet préféré devienne une erreur, vous devez vous impliquer et prendre vos responsabilités, apprendre au chef de produit à définir correctement la tâche, développer des listes de contrôle et des politiques; tout cela aide beaucoup. Chaque fois que je me retire (ou que quelqu'un de mes collègues me tire) quand une nouvelle tâche intéressante arrive, et nous courons pour le faire. Tout ce que je viens de vous dire, je l'oublie moi-même. Par conséquent, il est important d'avoir une sorte de liste de contrôle pour vous vérifier.
Les données
Les données sont super importantes en ML. Pour un apprentissage en profondeur, plus vous alimentez de modèles, mieux c'est. Le graphique bleu montre que les modèles d'apprentissage en profondeur s'améliorent généralement considérablement lorsque des données sont ajoutées.
Et les «anciens» algorithmes (classiques) d'un certain point ne peuvent plus s'améliorer.
Les jeux de données ML sont généralement sales. Ils ont été marqués par des gens qui mentent toujours. Les évaluateurs sont souvent inattentifs et font beaucoup d'erreurs. Nous utilisons cette technique: nous prenons les données que nous avons, formons le modèle sur elles, puis à l'aide de ce modèle, nous effaçons les données et répétons le cycle.
Examinons de plus près l'exemple de la même reconnaissance de visage. Disons que nous avons téléchargé les avatars des utilisateurs de VKontakte. Par exemple, nous avons un profil utilisateur avec 4 avatars. Nous détectons les visages qui se trouvent sur les 4 images et parcourons le modèle de reconnaissance des visages. Nous obtenons donc des intégrations de personnes, à l'aide desquelles elles peuvent «coller» des personnes similaires en groupes (cluster). Ensuite, nous sélectionnons le plus grand cluster, en supposant que les avatars de l'utilisateur contiennent principalement son visage. En conséquence, nous pouvons nettoyer toutes les autres faces (qui sont du bruit) de cette façon. Après cela, nous pouvons répéter le cycle à nouveau: sur les données nettoyées, former le modèle et l'utiliser pour nettoyer les données. Vous pouvez répéter plusieurs fois.
Presque toujours pour un tel regroupement, nous utilisons des algorithmes CLink. Il s'agit d'un algorithme de regroupement hiérarchique dans lequel il est très pratique de définir une valeur de seuil pour «coller» des objets similaires (c'est exactement ce qui est requis pour le nettoyage). CLink génère des grappes sphériques. Ceci est important, car nous apprenons souvent l'espace métrique de ces intégrations. L'algorithme a une complexité de O (n
2 ), qui, en principe, est d'env.
Parfois, les données sont si difficiles à obtenir ou à baliser qu'il n'y a plus rien à faire dès que vous commencez à les générer. L'approche générative vous permet de produire une énorme quantité de données. Mais pour cela, vous devez programmer quelque chose. L'exemple le plus simple est l'OCR, la reconnaissance de texte sur les images. Le balisage du texte pour cette tâche est extrêmement coûteux et bruyant: vous devez mettre en surbrillance chaque ligne et chaque mot, signer le texte, etc. Les évaluateurs (personnes de balisage) occuperont une centaine de pages de texte pendant très longtemps, et beaucoup plus est nécessaire pour la formation. Évidemment, vous pouvez d'une manière ou d'une autre générer le texte et le «déplacer» d'une manière ou d'une autre pour que le modèle en tire des leçons.
Nous avons constaté par nous-mêmes que la boîte à outils la meilleure et la plus pratique pour cette tâche est une combinaison de PIL, OpenCV et Numpy. Ils ont tout pour travailler avec du texte. Vous pouvez compliquer l'image avec du texte de toute façon afin que le réseau ne se reconstitue pas pour des exemples simples.

Parfois, nous avons besoin d'objets du monde réel. Par exemple, des marchandises sur les étagères des magasins. L'une de ces images est générée automatiquement. Pensez-vous à gauche ou à droite?

En fait, les deux sont générés. Si vous ne regardez pas les petits détails, vous ne remarquerez pas de différences par rapport à la réalité. Nous le faisons en utilisant Blender (analogique de 3dmax).
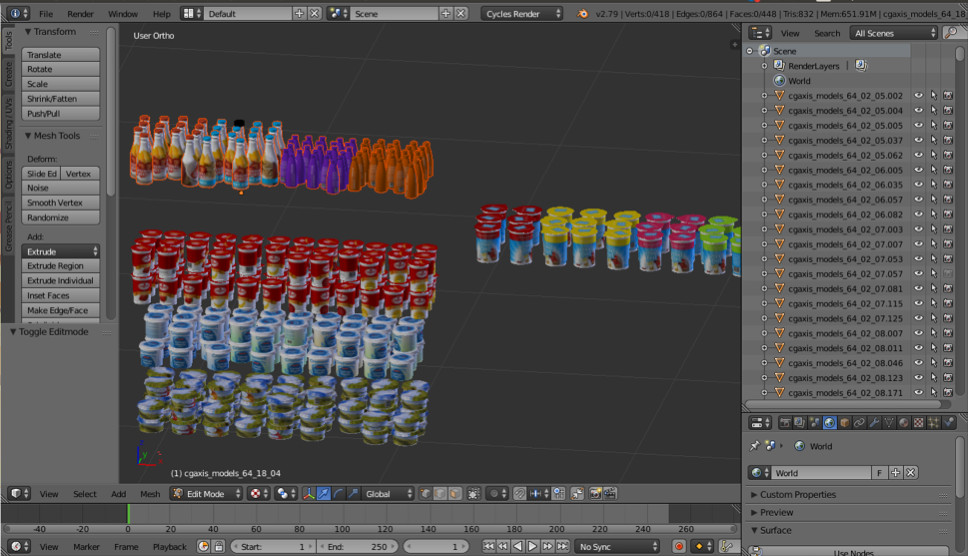
Le principal avantage important est qu'il est open source. Il possède une excellente API Python, qui vous permet de placer directement des objets dans le code, de configurer et de randomiser le processus et enfin d'obtenir un ensemble de données diversifié.
Pour le rendu, le lancer de rayons est utilisé. C'est une procédure assez coûteuse, mais elle produit un résultat d'excellente qualité. La question la plus importante: où trouver des modèles d'objets? En règle générale, ils doivent être achetés. Mais si vous êtes un pauvre étudiant et que vous voulez expérimenter quelque chose, il y a toujours des torrents. Il est clair que pour la production, vous devez acheter ou commander des modèles rendus à quelqu'un.
C'est tout sur les données. Passons à l'apprentissage.
Apprentissage métrique
L'objectif de l'apprentissage métrique est de former le réseau afin qu'il traduise des objets similaires dans des régions similaires dans l'espace métrique d'intégration. Je vais à nouveau donner un exemple avec les vues, ce qui est inhabituel car il s'agit essentiellement d'une tâche de classification, mais pour des dizaines de milliers de classes. Il semblerait, pourquoi ici l'apprentissage métrique, qui, en règle générale, est approprié dans des tâches telles que la reconnaissance faciale? Essayons de le comprendre.
Si vous utilisez des pertes standard lors de la formation d'un problème de classification, par exemple, Softmax, alors les classes dans l'espace métrique sont bien séparées, mais dans l'espace d'intégration, les points des différentes classes peuvent être proches les uns des autres ...

Cela crée des erreurs potentielles lors de la généralisation, comme une légère différence dans les données source peut modifier le résultat de la classification. Nous aimerions vraiment que les points soient plus compacts. Pour cela, différentes techniques d'apprentissage métrique sont utilisées. Par exemple, Center loss, dont l'idée est extrêmement simple: on rassemble simplement des points vers le centre d'apprentissage de chaque classe, qui finit par devenir plus compact.
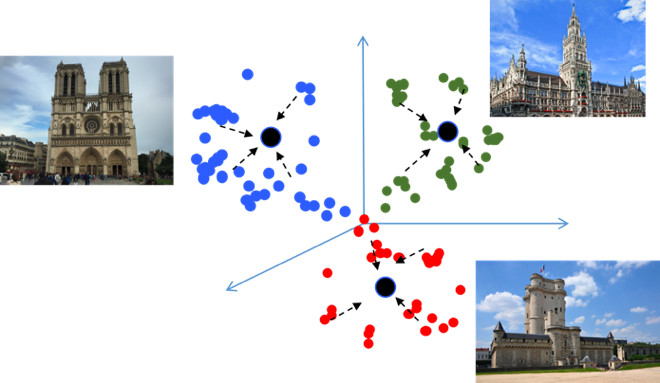
La perte de centre est programmée littéralement sur 10 lignes en Python, elle fonctionne très rapidement, et surtout, elle améliore la qualité de la classification, car la compacité conduit à une meilleure capacité de généralisation.
Softmax angulaire
Nous avons essayé de nombreuses méthodes d'apprentissage métriques différentes et sommes parvenus à la conclusion qu'Angular Softmax produit les meilleurs résultats. Dans la communauté des chercheurs, il est également considéré comme étant à la pointe de la technologie.
Regardons un exemple de reconnaissance faciale. Ici, nous avons deux personnes. Si vous utilisez le Softmax standard, un plan de division sera dessiné entre eux - basé sur deux vecteurs de poids. Si nous faisons la norme d'intégration 1, alors les points se situeront sur le cercle, c'est-à-dire sur la sphère dans le cas à n dimensions (image à droite).
Ensuite, vous pouvez voir que l'angle entre elles est déjà responsable de la séparation des classes, et il peut être optimisé. Mais cela ne suffit pas. Si nous continuons à optimiser l'angle, la tâche ne changera pas en fait, car nous l'avons simplement reformulé en d'autres termes. Je me souviens que notre objectif est de rendre les grappes plus compactes.
Il est en quelque sorte nécessaire d'exiger un angle plus grand entre les classes - pour compliquer la tâche du réseau neuronal. Par exemple, de telle manière qu'elle pense que l'angle entre les points d'une classe est plus grand qu'en réalité, de sorte qu'elle essaie de les comprimer de plus en plus. Ceci est réalisé en introduisant le paramètre m, qui contrôle la différence dans les cosinus des angles.
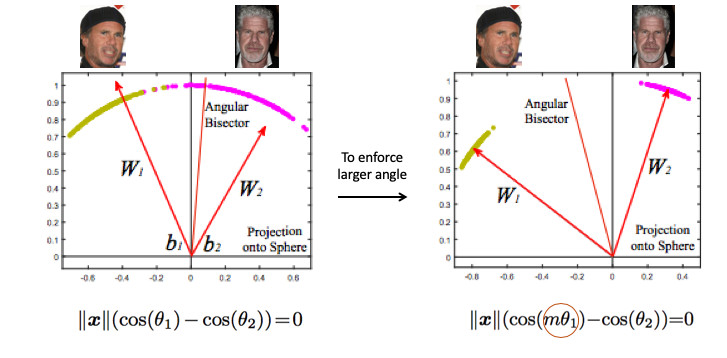
Il existe plusieurs options pour Angular Softmax. Ils jouent tous avec le fait que multipliez par m cet angle ou ajoutez, ou multipliez et ajoutez. État de l'art - ArcFace.
En fait, celui-ci est assez facile à intégrer dans la classification des pipelines.
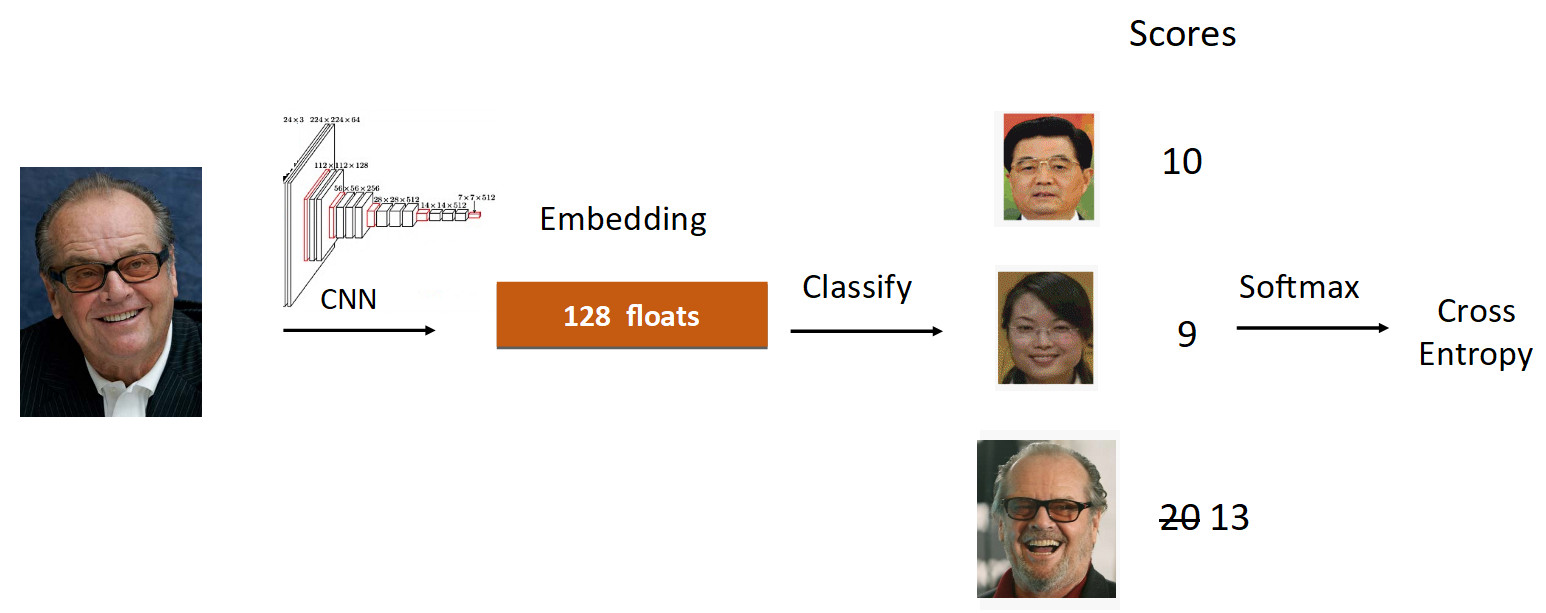
Prenons l'exemple de Jack Nicholson. Nous exécutons sa photo à travers la grille dans le processus d'apprentissage. Nous obtenons l'intégration, nous parcourons la couche linéaire pour la classification et nous obtenons des scores à la sortie, qui reflètent le degré d'appartenance à la classe. Dans ce cas, la photographie de Nicholson a une vitesse de 20, la plus grande. De plus, selon la formule d'ArcFace, nous réduisons la vitesse de 20 à 13 (fait uniquement pour la classe de vérité terrain), compliquant la tâche pour le réseau neuronal. Ensuite, nous faisons tout comme d'habitude: Softmax + Cross Entropy.
Au total, la couche linéaire habituelle est remplacée par la couche ArcFace, qui n'est pas écrite en 10, mais en 20 lignes, mais donne d'excellents résultats et un minimum de surcharge pour la mise en œuvre. Par conséquent, ArcFace est meilleur que la plupart des autres méthodes pour la plupart des tâches. Il s'intègre parfaitement aux tâches de classification et améliore la qualité.
Transfert d'apprentissage
La deuxième chose dont je voulais parler est l'apprentissage par transfert - en utilisant un réseau pré-formé sur une tâche similaire pour se recycler sur une nouvelle tâche. Ainsi, les connaissances sont transférées d'une tâche à l'autre.
Nous avons fait notre recherche d'images. L'essence de la tâche est de produire des sémantiquement similaires à partir de la base de données dans l'image (requête).

Il est logique de prendre un réseau qui a déjà étudié un grand nombre d'images - sur des ensembles de données ImageNet ou OpenImages, dans lesquels il y a des millions d'images, et de s'entraîner sur nos données.
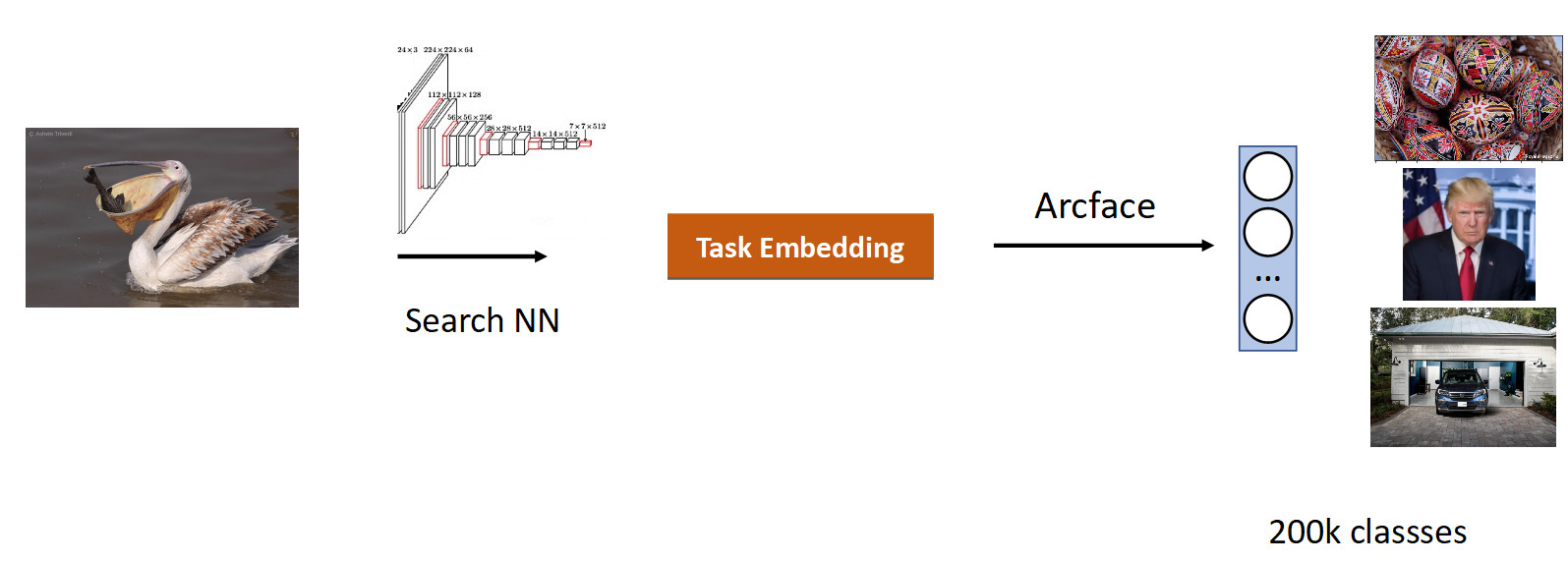
Nous avons collecté des données pour cette tâche sur la base de la similitude des images et des clics des utilisateurs et obtenu 200 000 cours. Après une formation avec ArFace, nous avons obtenu le résultat suivant.

Dans l'image ci-dessus, nous voyons que pour le pélican demandé, les moineaux sont également entrés dans le problème. C'est-à-dire l'intégration s'est avérée sémantiquement vraie - c'est un oiseau, mais racialement infidèle. Le plus ennuyeux est que le modèle original avec lequel nous nous sommes recyclés connaissait ces classes et les distinguait parfaitement. Nous voyons ici l'effet commun à tous les réseaux de neurones, appelé l'oubli catastrophique. C'est-à-dire que pendant le recyclage, le réseau oublie la tâche précédente, parfois même complètement. C'est exactement ce qui empêche dans cette tâche d'obtenir une meilleure qualité.
Distillation des connaissances
Ceci est traité en utilisant une technique appelée distillation des connaissances, lorsqu'un réseau en enseigne un autre et «lui transfère ses connaissances». A quoi cela ressemble (pipeline de formation complet dans l'image ci-dessous).
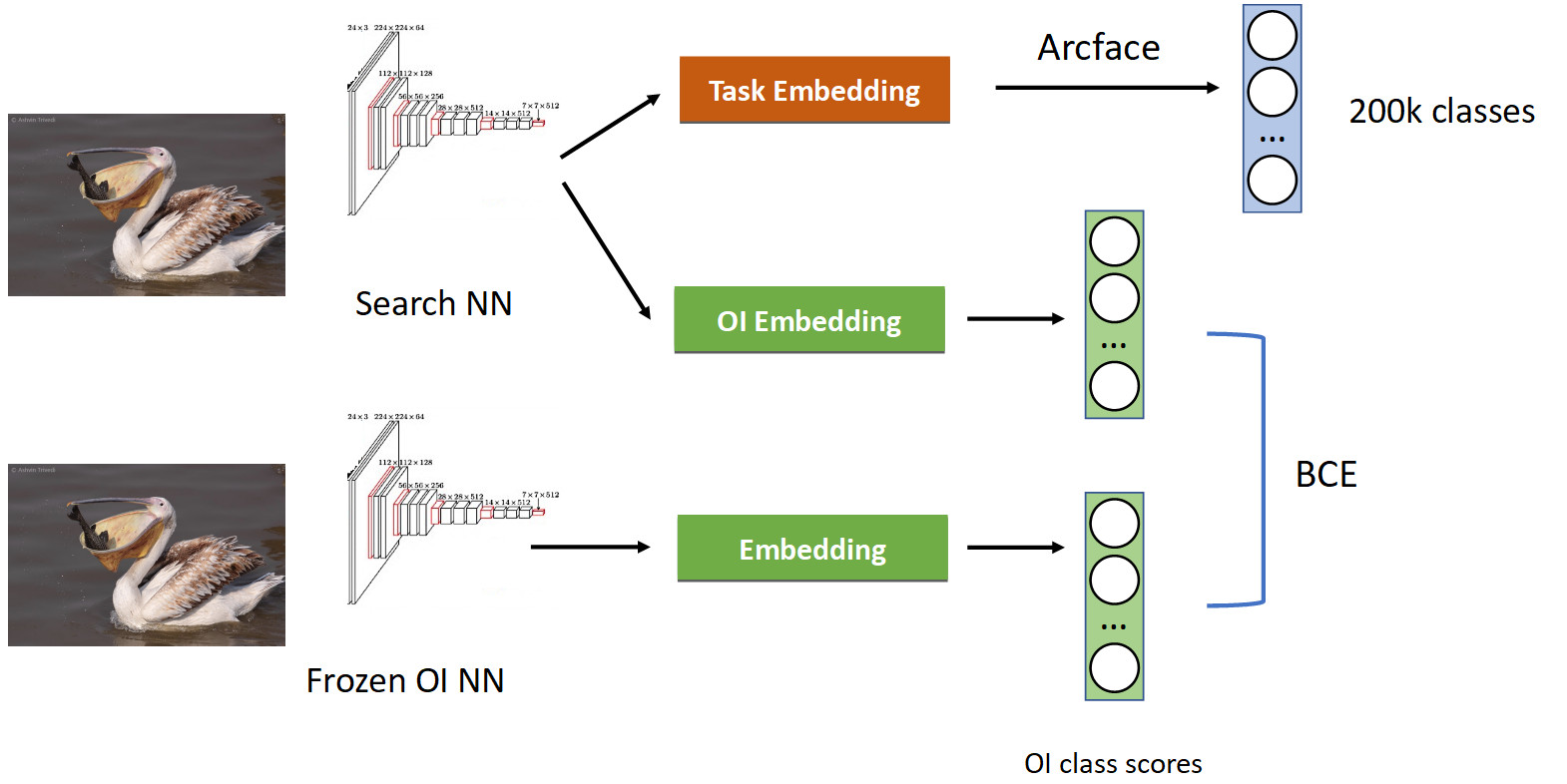
Nous avons déjà un pipeline de classification familier avec Arcface. Rappelons que nous avons un réseau avec lequel nous sommes prétendus. Nous l'avons gelé et calculons simplement ses plongées dans toutes les photos dans lesquelles nous apprenons notre réseau, et obtenons les classes des classes OpenImages: pélicans, moineaux, voitures, personnes, etc. ... Nous bougeons du réseau neuronal formé d'origine et apprenons une autre intégration pour les classes OpenImages, qui produit des scores similaires. Avec BCE, nous faisons en sorte que le réseau produise une distribution similaire de ces scores. Ainsi, d'une part, nous apprenons une nouvelle tâche (en haut de l'image), mais nous faisons aussi en sorte que le réseau n'oublie pas ses racines (en bas) - rappelez-vous les classes qu'il connaissait. Si vous équilibrez correctement les gradients dans une proportion conditionnelle de 50/50, cela laissera tous les pélicans en haut et jettera tous les moineaux à partir de là.

Lorsque nous l'avons appliqué, nous avons obtenu un pourcentage complet dans le mAP. C'est beaucoup.
Donc, si votre réseau oublie la tâche précédente, traitez en utilisant la distillation des connaissances - cela fonctionne très bien.
Têtes supplémentaires
L'idée de base est très simple. Encore une fois sur l'exemple de la reconnaissance faciale. Nous avons un ensemble de personnes dans l'ensemble de données. Mais souvent, dans les jeux de données, il existe d'autres caractéristiques du visage. Par exemple, quel âge, quelle couleur des yeux, etc. Tout cela peut être ajouté comme un ajout supplémentaire. signal: apprenez à chaque tête à prédire ces données. Ainsi, notre réseau reçoit un signal plus diversifié et, par conséquent, il peut être préférable d'apprendre la tâche principale.
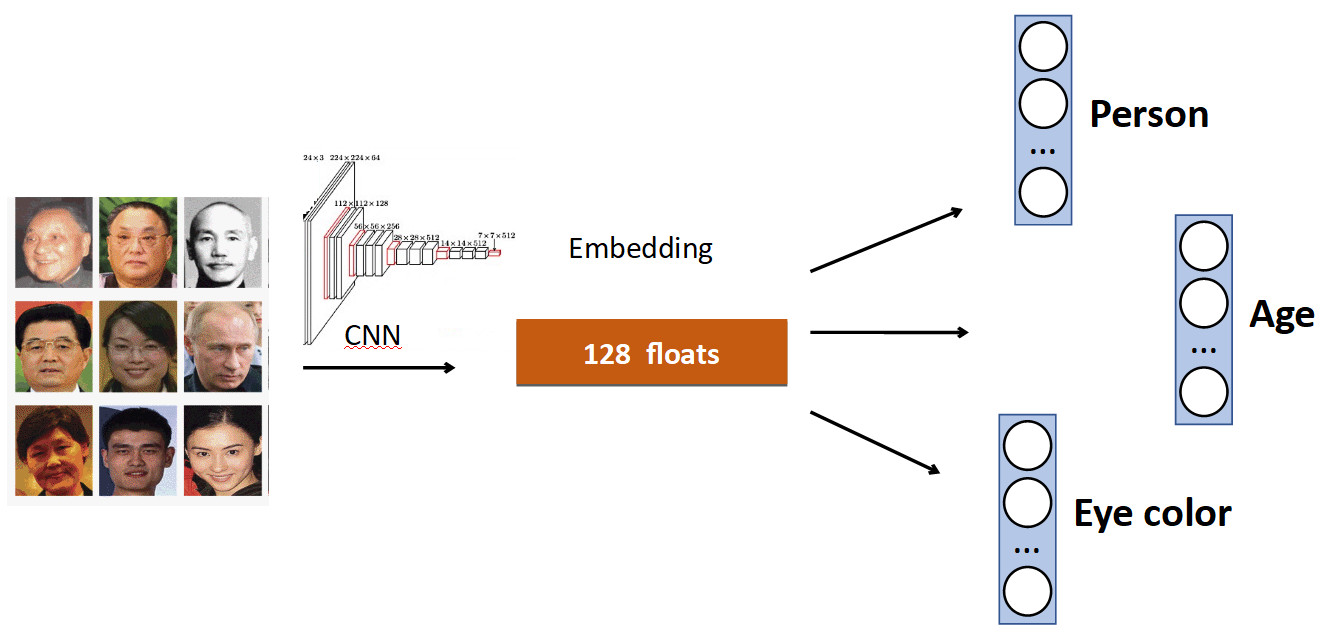
Un autre exemple: la détection de file d'attente.

Souvent, dans les ensembles de données avec des personnes, en plus du corps, il y a un marquage séparé de la position de la tête, qui, évidemment, peut être utilisé. Par conséquent, nous avons ajouté au réseau la prédiction de la zone de délimitation de la personne et la prédiction de la zone de délimitation de la tête, et nous avons obtenu une augmentation de 0,5% de la précision (mAP), ce qui est décent. Et surtout - gratuit en termes de performances, car en production, la tête supplémentaire est «déconnectée».

OCR
Un cas plus complexe et intéressant est l'OCR, déjà mentionné ci-dessus. Le pipeline standard est comme ça.
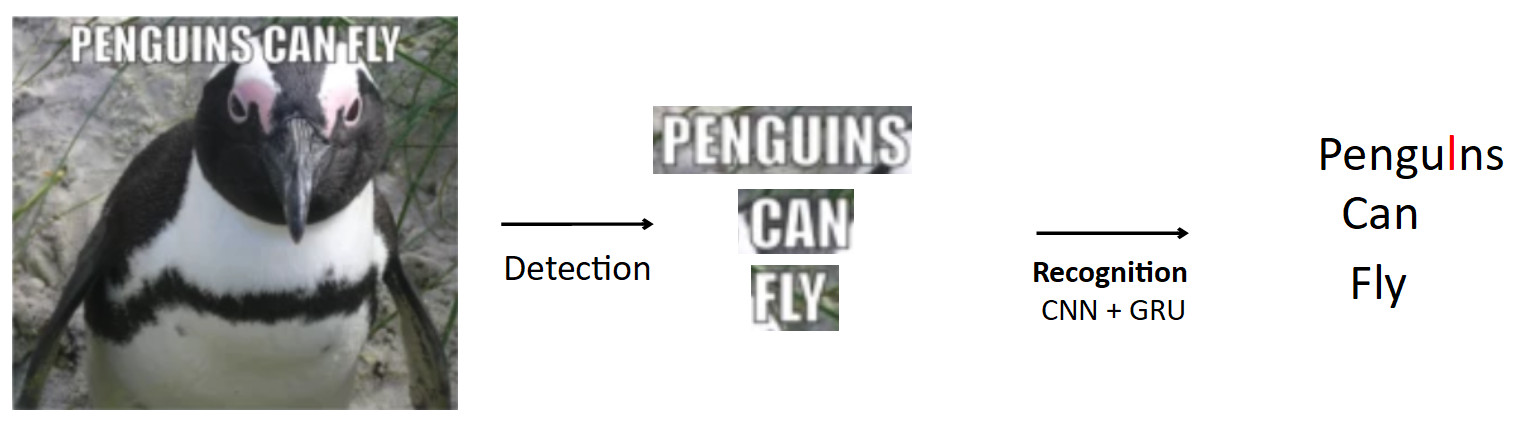
Qu'il y ait une affiche avec un pingouin, le texte est écrit dessus. En utilisant le modèle de détection, nous mettons en évidence ce texte. De plus, nous alimentons ce texte à l'entrée du modèle de reconnaissance, qui produit le texte reconnu. Disons que notre réseau est erroné et au lieu de «i» dans le mot pingouins prédit «l». Il s'agit en fait d'un problème très courant dans l'OCR lorsque le réseau confond des caractères similaires. La question est de savoir comment éviter cela - traduire les pingouins en pingouins? Lorsqu'une personne regarde cet exemple, il est évident pour lui que c'est une erreur, car il a une connaissance de la structure de la langue. Par conséquent, les connaissances sur la distribution des caractères et des mots dans la langue doivent être intégrées dans le modèle.
Nous avons utilisé pour cela une chose appelée BPE (codage par paire d'octets). Il s'agit d'un algorithme de compression qui a été généralement inventé dans les années 90 non pas pour l'apprentissage automatique, mais maintenant il est très populaire et est utilisé dans l'apprentissage en profondeur. La signification de l'algorithme est que les sous-séquences fréquentes dans le texte sont remplacées par de nouveaux caractères. Supposons que nous ayons la chaîne "aaabdaaabac" et que nous voulons obtenir un BPE pour cela. Nous constatons que la paire de caractères «aa» est la plus fréquente dans notre mot. Nous le remplaçons par un nouveau caractère «Z», nous obtenons la chaîne «ZabdZabac». Nous répétons l'itération: nous voyons que ab est la sous-séquence la plus fréquente, remplacez-la par "Y", nous obtenons la chaîne "ZYdZYac". Maintenant, «ZY» est la sous-séquence la plus fréquente, nous la remplaçons par «X», nous obtenons «XdXac». Ainsi, nous codons certaines dépendances statistiques dans la distribution du texte. Si nous rencontrons un mot dans lequel il y a des sous-séquences très «étranges» (rares pour le corps enseignant), alors ce mot est suspect.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYComment tout cela s'inscrit dans la reconnaissance.
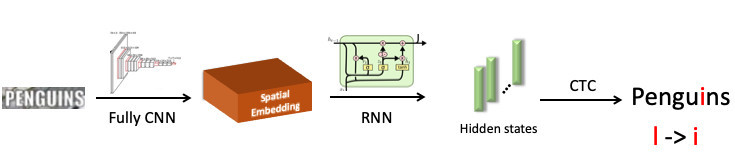
Nous avons mis en évidence le mot «pingouin», l'avons envoyé au réseau neuronal convolutif, qui a produit une intégration spatiale (un vecteur de longueur fixe, par exemple 512). Ce vecteur code les informations de symboles spatiaux. Ensuite, nous utilisons un réseau de récurrence (UPD: en fait, nous utilisons déjà le modèle Transformer), il donne des états cachés (barres vertes), dans chacun desquels la distribution de probabilité est cousue - qui, selon le modèle, le symbole est représenté à une position spécifique. Ensuite, en utilisant CTC-Loss, nous déroulons ces états et obtenons notre prédiction pour le mot entier, mais avec une erreur: L à la place de i.
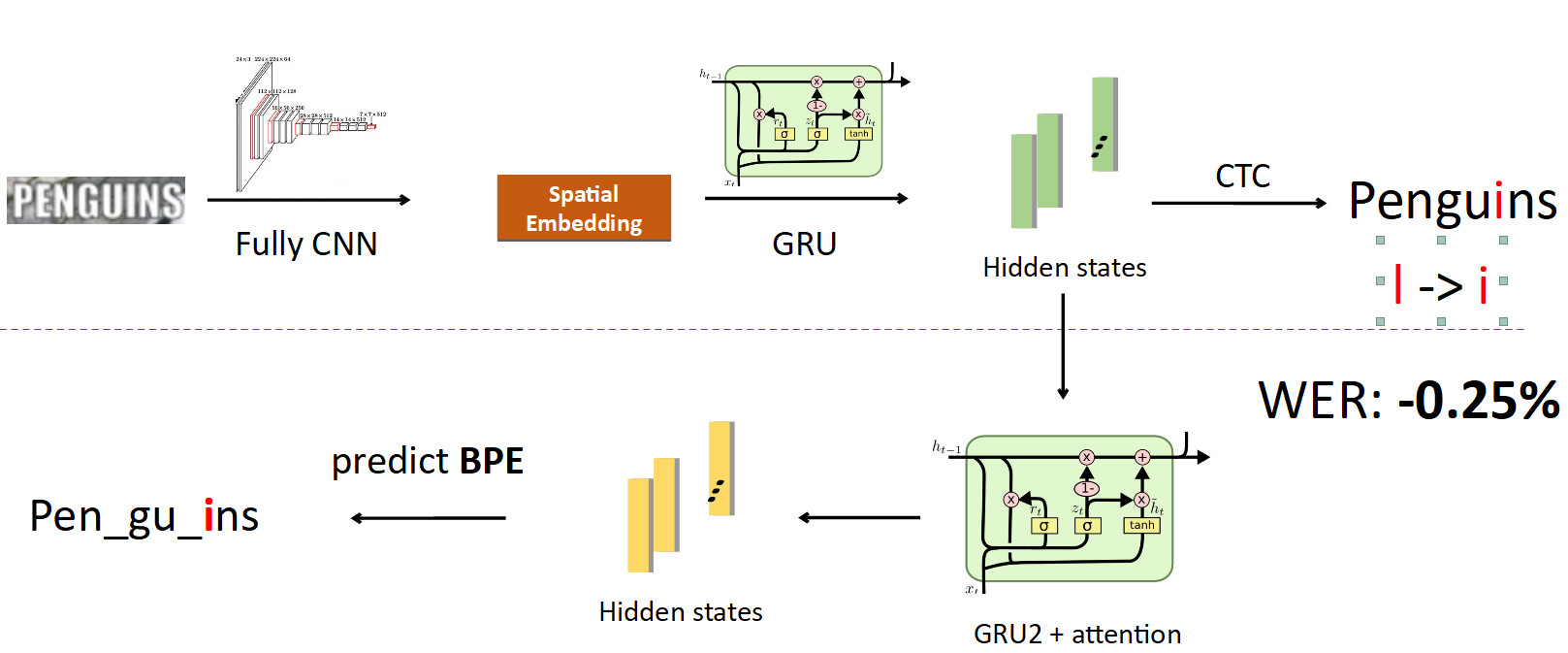
Intégration de BPE dans le pipeline. Nous voulons éviter de prédire des caractères individuels à des mots, nous nous éloignons donc des états dans lesquels les informations sur les caractères sont cousues et définissons un autre réseau récursif sur eux; elle prédit BPE. Dans le cas de l'erreur décrite ci-dessus, 3 BPE sont obtenus: "peng", "ul", "ns". Cela diffère considérablement de la séquence correcte pour le mot pingouins, c'est-à-dire stylo, gu, ins. Si vous regardez cela du point de vue de la formation des modèles, alors, dans une prédiction caractère par mot, le réseau a fait une erreur dans une seule lettre sur huit (erreur de 12,5%); et en termes d'EBP, elle s'est trompée à 100% en prédisant les 3 EPI de manière incorrecte. C'est un signal beaucoup plus important pour le réseau que quelque chose s'est mal passé et que vous devez corriger votre comportement. Lorsque nous avons implémenté cela, nous avons pu corriger des erreurs de ce type et réduire le taux d'erreur sur les mots de 0,25% - c'est beaucoup. Cette tête supplémentaire est supprimée lors de l'inférence, remplissant son rôle dans la formation.
FP16
La dernière chose que je voulais dire sur la formation était FP16. Il est arrivé historiquement que les réseaux soient formés sur le GPU en précision d'unité, c'est-à-dire FP32. Mais cela est redondant, en particulier pour l'inférence, où la demi-précision (FP16) est suffisante sans perte de qualité. Cependant, ce n'est pas le cas avec la formation.
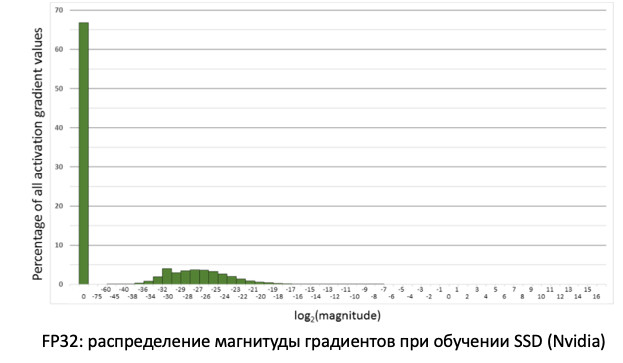
Si nous regardons la distribution des gradients, des informations qui mettent à jour nos poids lors de la propagation des erreurs, nous verrons qu'il y a un énorme pic à zéro. Et en général, beaucoup de valeurs sont proches de zéro. Si nous transférons simplement tous les poids sur FP16, il s'avère que nous avons coupé le côté gauche dans la région de zéro (à partir de la ligne rouge).
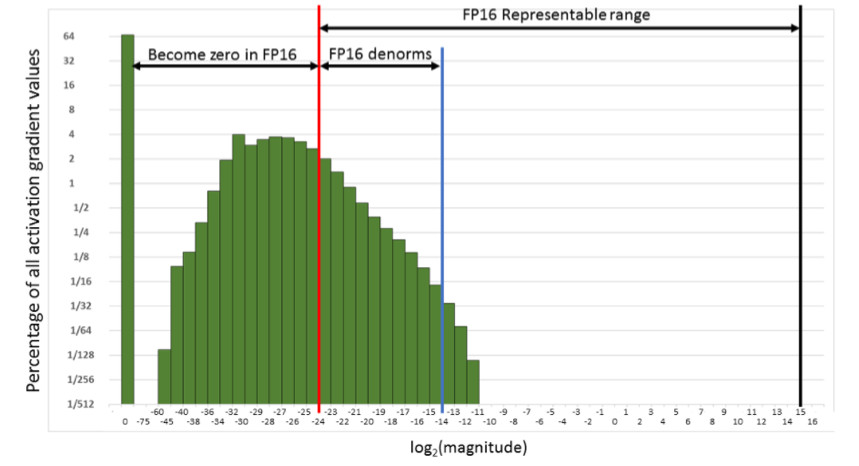
Autrement dit, nous allons réinitialiser un très grand nombre de gradients. Et la bonne partie, dans la plage de travail FP16, n'est pas du tout utilisée. Par conséquent, si vous vous entraînez le front sur FP16, le processus est susceptible de se disperser (le graphique gris dans l'image ci-dessous).
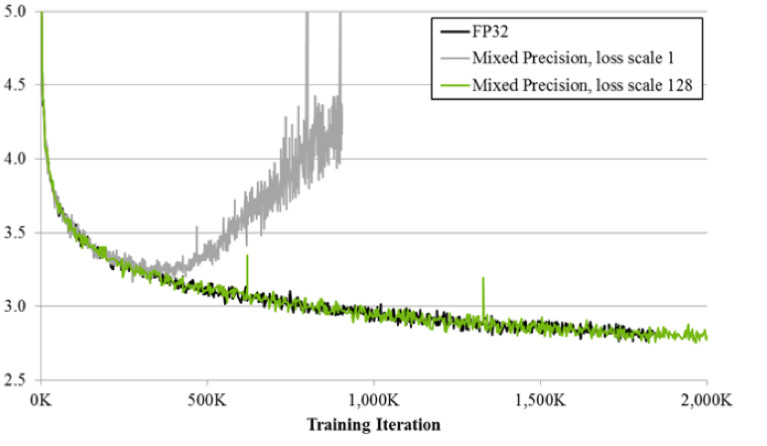
Si vous vous entraînez en utilisant la technique de précision mixte, le résultat est presque identique à FP32. La précision mixte met en œuvre deux astuces.
Premièrement: nous multiplions simplement la perte par une constante, par exemple 128. Ainsi, nous mettons à l'échelle tous les gradients et déplaçons leurs valeurs de zéro à la plage de travail FP16. Deuxièmement: nous stockons la version principale de la balance FP32, qui est utilisée uniquement pour la mise à jour, et dans les opérations de calcul des réseaux de passes avant et arrière, seule la FP16 est utilisée.
Nous utilisons Pytorch pour former des réseaux. NVIDIA a fait un assemblage spécial pour cela avec le soi-disant APEX, qui met en œuvre la logique décrite ci-dessus. Il a deux modes. La première est la précision mixte automatique. Consultez le code ci-dessous pour voir à quel point il est facile à utiliser.

Littéralement, deux lignes sont ajoutées au code de formation pour envelopper la perte et la procédure d'initialisation du modèle et des optimiseurs. Que fait AMP? Il singe patch'it toutes les fonctions. Que se passe-t-il exactement? Par exemple, il voit qu'il y a une fonction de convolution, et elle reçoit un profit du FP16. Il le remplace ensuite par le sien, qui est d'abord converti en FP16, puis effectue une opération de convolution. AMP fait donc pour toutes les fonctions qui peuvent être utilisées sur le réseau. Pour certains, ce n'est pas le cas. il n'y aura pas d'accélération. Pour la plupart des tâches, cette méthode convient.
Deuxième option: optimiseur FP16 pour les fans de contrôle complet. Convient si vous souhaitez vous-même spécifier quels calques seront dans FP16 et lesquels dans FP32. Mais il a un certain nombre de limites et de difficultés. Ça ne commence pas par un demi-coup de pied (au moins on a dû transpirer pour le démarrer). FP_optimizer ne fonctionne également qu'avec Adam, et même alors uniquement avec cet Adam, qui est dans APEX (oui, ils ont leur propre Adam dans le référentiel, qui a une interface complètement différente de Paytorch).
Nous avons fait une comparaison lors de l'apprentissage sur les cartes Tesla T4.
Chez Inference, nous avons deux fois l'accélération attendue. En formation, nous voyons que le framework Apex fournit une accélération de 20% avec un FP16 relativement simple. En conséquence, nous obtenons un entraînement qui est deux fois plus rapide et consomme 2 fois moins de mémoire, et la qualité de l'entraînement ne souffre en aucune façon. Freebie.
Inférence
Parce que Puisque nous utilisons PyTorch, la question est de savoir de toute urgence comment le déployer en production.
Il y a 3 options pour le faire (et nous les avons toutes utilisées).
- ONNX -> Caffe2
- ONNX -> TensorRT
- Et plus récemment Pytorch C ++
Regardons chacun d'eux.
ONNX et Caffe2
ONNX est apparu il y a 1,5 ans. Il s'agit d'un cadre spécial pour convertir des modèles entre différents cadres. Et Caffe2 est un framework adjacent à Pytorch, tous deux en cours de développement sur Facebook. Historiquement, Pytorch se développe beaucoup plus rapidement que Caffe2. Caffe2 est en retard sur Pytorch en termes de fonctionnalités, donc tous les modèles que vous avez formés à Pytorch ne peuvent pas être convertis en Caffe2. Souvent, vous devez réapprendre avec d'autres couches. Par exemple, dans Caffe2, il n'y a pas d'opération standard telle que le suréchantillonnage avec l'interpolation du plus proche voisin. En conséquence, nous sommes arrivés à la conclusion que pour chaque modèle, nous avons obtenu une image de docker spéciale, dans laquelle nous clouons les versions du cadre avec des clous pour éviter les écarts lors de leurs futures mises à jour, de sorte que lorsque l'une des versions est à nouveau mise à jour, nous ne perdons pas de temps sur leur compatibilité . Tout cela n'est pas très pratique et allonge le processus de déploiement.
Tensor rt
Il existe également Tensor RT, un framework NVIDIA qui optimise l'architecture réseau pour accélérer l'inférence. Nous avons fait nos mesures (sur la carte Tesla T4).
Si vous regardez les graphiques, vous pouvez voir que la transition de FP32 à FP16 donne une accélération 2x sur Pytorch, tandis que TensorRT en même temps donne autant 4x. Une différence très significative. Nous l'avons testé sur Tesla T4, qui a des noyaux de tenseurs qui utilisent très bien les calculs FP16, ce qui est évidemment excellent dans TensorRT. Par conséquent, s'il existe un modèle très chargé fonctionnant sur des dizaines de cartes graphiques, il existe tous les facteurs de motivation pour essayer Tensor RT.
Cependant, lorsque vous travaillez avec TensorRT, il y a encore plus de douleur que dans Caffe2: les couches y sont encore moins prises en charge. Malheureusement, chaque fois que nous utilisons ce framework, nous devons souffrir un peu pour convertir le modèle. Mais pour les modèles lourdement chargés, vous devez le faire. ;) Je note que sur les cartes sans noyaux tensoriels une telle augmentation massive n'est pas observée.
Pytorch C ++
Et le dernier est Pytorch C ++. Il y a six mois, les développeurs de Pytorch ont réalisé la douleur des personnes qui utilisent leur framework et ont publié le
tutoriel TorchScript , qui vous permet de suivre et de sérialiser le modèle Python dans un graphique statique sans gestes inutiles (JIT). Il a été publié en décembre 2018, nous avons immédiatement commencé à l'utiliser, avons immédiatement
détecté quelques bugs de performance et attendu plusieurs mois la fixation de
Chintala . Mais maintenant, c'est une technologie assez stable, et nous l'utilisons activement pour tous les modèles. La seule chose est le manque de documentation, qui est activement complétée. Bien sûr, vous pouvez toujours consulter les fichiers * .h, mais pour les personnes qui ne connaissent pas les avantages, c'est difficile. Mais alors, le travail est vraiment identique avec Python. En C ++, le j-code est exécuté sur un interpréteur Python minimal, qui garantit pratiquement l'identité de C ++ avec Python.
Conclusions
- L'énoncé du problème est super important. Vous devez communiquer avec les chefs de produit sur les données. Avant de commencer à effectuer la tâche, il est conseillé d'avoir un ensemble de tests prêt à l'emploi sur lequel nous mesurons les métriques finales avant l'étape de mise en œuvre.
- Nous nettoyons les données nous-mêmes à l'aide du clustering. Nous obtenons le modèle sur les données source, nettoyons les données à l'aide du clustering CLink et répétons le processus jusqu'à la convergence.
- Apprentissage métrique: même la classification aide. État de l'art - ArcFace, qui est facile à intégrer dans le processus d'apprentissage.
- Si vous transférez l'apprentissage à partir d'un réseau pré-formé, afin que le réseau n'oublie pas l'ancienne tâche, utilisez la distillation des connaissances.
- Il est également utile d'utiliser plusieurs têtes de réseau qui utiliseront différents signaux des données pour améliorer la tâche principale.
- Pour FP16, vous devez utiliser les assemblys Apex de NVIDIA, Pytorch.
- Et par déduction, il est pratique d'utiliser Pytorch C ++.